python爬虫学习(3)增加访问量,自我安慰系列~
当我写出标题的时候,这篇博文就开始被我用做测试了。
(源码)Github:https://github.com/OSinoooO/CSDN_readingCount_increase
昨天晚上看着自己写的博文,太低级了都没有人看呐 (┬_┬)
突发奇想要不给自己增加一下阅读量,自我安慰一下?ヽ(-`Д´-)ノ
想到就做,于是就开始了我的测试:
先弄清楚阅读量增加的机制
我打开自己的博文,阅读数+1,这么简单???
然后刷新页面,阅读数不变 - -
后退一个页面在进测试博文, 阅读数不变 - -
重新输入网址, 阅读数不变 - -
但是过一会重新打开博文, 阅读数+1 o_O
我就想大概是对同一ip有什么简单的判断机制吧,那我就换ip试试
每次使用不同的代理访问博文,阅读数+1 o(∩_∩)o
还是很简单的嘛...
然后思路就出来了:切换不同的ip来批量访问页面增加阅读量。
代码实现
有了思路就好办了,就是需要获取一些代理ip进行批量访问。
代理ip可以从一些免费的IP代理网站获取,比如西刺... (穷屌丝一枚 o(︶︿︶)o )
当然最好是通过代理池获取,网上应该有很多。
刚好最近我的代理池也弄好了,源码托管GIthub,有点low,有需要自取:
https://github.com/OSinoooO/ProxyPool
开始写代码...
初始化
import requests
from bs4 import BeautifulSoup
from threading import Thread
# 目标网站
TARGET_URL = 'https://blog.csdn.net/qq_31998745/article/details/81323443'
# 代理API接口
PROXY_URL = 'http://localhost:5000/random'
# 请求头
HEADERS = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.119 Safari/537.36'
}
# 计数
COUNT = 0
获取代理
def get_proxy(proxy_url):
"""
代理ip获取
:param proxy_url: 代理API接口
:return: 代理ip
"""
try:
response = requests.get(proxy_url)
if response.status_code == 200:
return response.text
except ConnectionError:
return None这里以我自己的代理池为例,代理池开启后,会在本地提供代理API接口,网址为:“http://localhost:5000/random”,直接提取即可。
有个小提示:在开启代理池之前,可以把代理检测模块的检测地址换成"https://www.csdn.net"。这样帅选出来的代理ip可用率会大大提高。
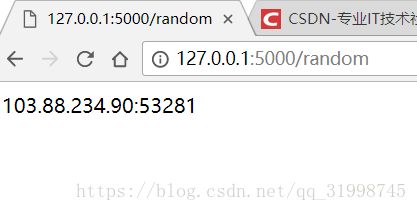
请求目标
def start_requests(url, proxy):
"""
使用代理请求目标网址
:param url: 目标网址
:param proxy: 代理ip
"""
global COUNT
proxies = {
'http':'http://' + proxy,
'https':'https://' + proxy,
}
try:
# 使用requests请求,参数包含代理,请求头和超时限制(10s)
response = requests.get(url, proxies=proxies, headers=HEADERS,timeout=10)
# BeautifulSoup解析器对象创建
soup = BeautifulSoup(response.text, 'lxml')
# 定位阅读量元素并输出
read_count = soup.find_all('span', class_='read-count')[0]
print(read_count)
except:
print('加载未成功...')
finally:
# 每连接一次,不管连接是否成功,计数器+1
COUNT += 1
print('已尝试次数:', COUNT)代码很简单,不难理解。
多线程运行
def run(url, proxy_url):
"""
多线程运行
:param url: 目标网址
:param proxy_url: 代理API接口
:return:
"""
threads = []
# 同时开启8个线程运行,可修改
for i in range(8):
proxy = get_proxy(proxy_url)
threads.append(Thread(target=start_requests, args=(url, proxy)))
for t in threads:
t.start()
for t in threads:
t.join()为了提高运行效率,这里开启了8个线程来运行请求目标的函数。如果不用多线程的话,只能每次请求一个ip,要等这个请求成功或者超时才能发送下一个请求。这里我们一次可以发送8个请求,当然这个书可以改,但并不是越多越好。
当然也可以通过多进程、协程、进程池、线程池的方法发送请求,目前我......就不丢人了 (*^__^*)
运行代码
if __name__ == '__main__':
while True:
run(TARGET_URL, PROXY_URL)加一个死循环,或者可以写一个for来限制循环次数:for i in range(10) # 算上8线程的话,发出80次请求后循环终止
成果
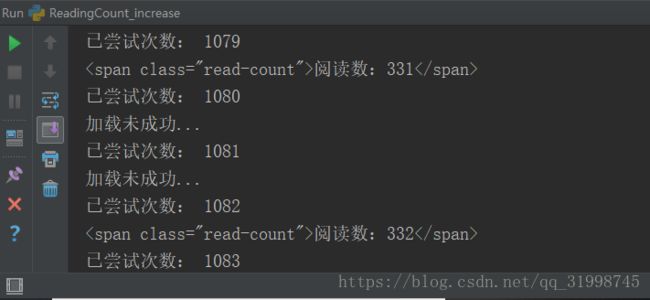

可以看出我的代理可用率在30%左右吧 O__O "… 这些还都是筛选过的代理,看在免费的面子上我忍了...