
最近在看sharding-jdbc相关的资料,此篇文章是对其中涉及的分布式ID生成算法做一个总结。
先抛开sharding-jdbc的实现策略,我们来介绍一下几种常见的分布式ID生成算法。
UUID
这个是最简单的生成算法。
优点:本地生成,无网络消耗,性能很高,基本不会有瓶颈。
缺点:因为UUID太长,所以不利于存储。在MySQL的InnoDB引擎中,主键会做聚集索引,会加重数据库的负担。生成的ID无序,没有趋势递增性。其次是安全问题:基于MAC地址生成UUID的算法可能会造成MAC地址泄露。
数据库生成
利用MySQL数据库进行ID生成。每次需要生成ID的时候,去访问一次MySQL数据库,取得上次的ID值再加1即可。
上面这种方案可能会遇到瓶颈问题,每次生成ID都要访问数据库。我们可以改进为每次访问数据库不只取一条数据,而取出一批数据,数据库只记录一次最大ID,等服务将这批ID分发完之后再从数据库重新取出一批ID进行分发。这样可以降低访问数据库的次数。
即使优化过得方案MySQL也是单点,会有高可用问题,假如MySQL挂掉的话整个ID生成服务就不可用。解决方案是使用数据库集群,然后每个数据库实例设置固定步长,例如DB0从1开始步长为5,则生成的ID为1,6,11,DB1从2开始步长为5,生成的ID为2,7,12。
Twitter snowflake
这种方案是一种以划分命名空间来生成ID的一种算法,把64-bit分别划分成多段,分开来标示机器、时间等,在snowflake中的64-bit分别表示如下图所示:

前41位表示时间,中间10位表示机器序号,序列号用来记录同毫秒内产生的不同id。12位(bit)可以表示的最大正整数是2^{12}-1 = 4095,即可以用0、1、2、3、....4094这4095个数字,来表示同一机器同一时间截(毫秒)内产生的4095个ID序号。
Java中64bit的整数是long类型,所以在Java中SnowFlake算法生成的id是用long来存储的。
优点:
毫秒数在高位,自增序列在低位,整个ID都是趋势递增的。
不依赖数据库等第三方系统。
可以根据自身业务特性分配bit位,非常灵活。
缺点:
依赖机器时钟,如果机器上时钟回拨,会导致ID重复或者服务会处于不可用状态。
Leaf:美团分布式ID生成服务
Leaf是美团自主研发的分布式ID生成算法,目前已开源。
Leaf有两种模式
第一种是预分发模式:
该模式使用数据库生成ID,可以看做是上面提到的数据库方案的升级版,它可以在DB之上挂N个Server,每个Server启动时,都会去DB拿固定长度的ID List。因为ID是由内存分发,所以也可以做到很高效。Leaf每次去DB拿固定长度的ID List,然后把最大的ID持久化下来。该模式使用的表结构如下。
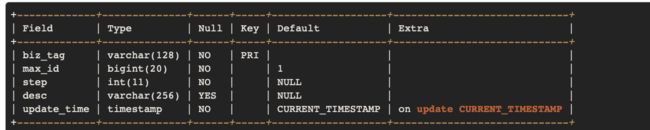
biz_tag用来区分业务,max_id表示该biz_tag目前所被分配的ID号段的最大值,step表示每次分配的号段长度。原来获取ID每次都需要写数据库,现在只需要把step设置得足够大,比如1000。那么只有当1000个号被消耗完了之后才会去重新读写一次数据库。仅仅存储一批ID中最大的那一个,读写数据库的频率从1减小到了1/step。假设有,2个Leaf实例连接同一个数据库时,步长设为1000,
Leaf Server 1:从DB加载号段[1,1000]。
Leaf Server 2:从DB加载号段[1001,2000]。
某一个Client获取到的ID序列可能是:1,1001,2001,2,1002,2002……也可能是:1,2,1001,2001,2002,2003,3,4……
该方案有两个问题:1.在更新DB的时候会出现耗时尖刺,系统最大耗时取决于更新DB号段的时间。2.当更新DB号段的时候,如果DB宕机或者发生主从切换,会导致一段时间的服务不可用。
为了解决这两个问题,Leaf进行了优化。
双Buffer优化
采用了异步更新的策略,同时通过双Buffer的方式,保证无论何时DB出现问题,都能有一个Buffer的号段可以正常对外提供服务,只要DB在一个Buffer的下发的周期内恢复,就不会影响整个Leaf的可用性。原理是Leaf服务内部有两个号段缓存区segment。当前号段已下发10%时,如果下一个号段未更新,则另启一个更新线程去更新下一个号段。当前号段全部下发完后,如果下个号段准备好了则切换到下个号段为当前segment接着下发,循环往复。
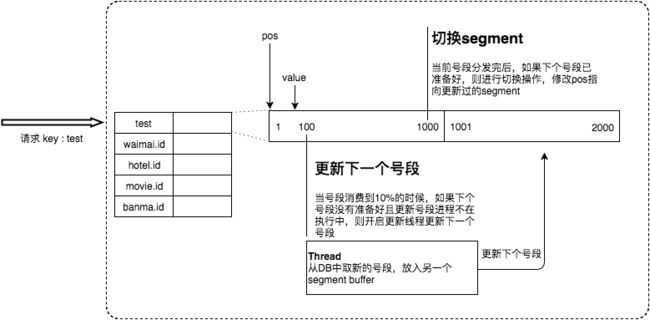
该方案可以生成趋势递增的ID,同时ID号是可计算的,不适用于订单ID生成场景,比如在两天中午12点分别下单,通过订单id号相减就能大致计算出公司一天的订单量。
第二种模式Leaf-snowflake
类snowflake方案,使用zookeeper进行snowflake中机器编号bit位的分配。
Leaf-snowflake是按照下面几个步骤启动的:1.启动Leaf-snowflake服务,连接Zookeeper,在leaf_forever父节点下检查自己是否已经注册过(是否有该顺序子节点)。2.如果有注册过直接取回自己的workerID(zk顺序节点生成的int类型ID号),启动服务。3.如果没有注册过,就在该父节点下面创建一个持久顺序节点,创建成功后取回顺序号当做自己的workerID号,启动服务。同时对Zookeeper生成机器号做了弱依赖处理,即使Zookeeper有问题,也不会影响服务。Leaf在第一次从Zookeeper拿取workerID后,会在本机文件系统上缓存一个workerID文件。即使ZooKeeper出现问题,同时恰好机器也在重启,也能保证服务的正常运行。
Leaf也解决了时钟回拨可能导致ID重复的问题。采用的是重试(开启了NTP同步的机器)加报警的方案。对于如何判断时间是否发生回拨,采用的是综合对比其余Leaf节点的系统时间来判断自身系统时间是否准确。具体做法是服务启动时首先检查自己是否写过ZooKeeper leaf_forever节点:若写过,则用自身系统时间与leaf_forever/${self}节点记录时间做比较,若小于leaf_forever/${self}时间则认为机器时间发生了大步长回拨,服务启动失败并报警。若未写过,证明是新服务节点,直接创建持久节点leaf_forever/${self}并写入自身系统时间,接下来综合对比其余Leaf节点的系统时间来判断自身系统时间是否准确,具体做法是取leaf_temporary下的所有临时节点(所有运行中的Leaf-snowflake节点)的服务IP:Port,然后通过RPC请求得到所有节点的系统时间,计算sum(time)/nodeSize。若abs( 系统时间-sum(time)/nodeSize ) < 阈值,认为当前系统时间准确,正常启动服务,同时写临时节点leaf_temporary/${self} 维持租约。否则认为本机系统时间发生大步长偏移,启动失败并报警。每隔一段时间(3s)上报自身系统时间写入leaf_forever/${self}。
百度UidGenerator
百度开源的类SnowFlake算法。同Leaf一样,也提供两种模式。
第一种就是标准的snowflake算法的实现。
第二种是带缓存的snowflake。主要通过RingBuffer来实现。最初接触RingBuffer是在Distruptor中,前者是该框架的核心,说起来比较复杂,以后会专门写一下Distruptor中的RingBuffer。这里就暂时留个坑,等写好RingBuffer后再来补上。