相关滤波跟踪·CSK算法梳理(巨详(啰)细(嗦))
从MOSSE到CSK算是了解相关滤波跟踪的必经之路了。CSK在MOSSE模型的基础上增加了正则项以避免过拟合,提出了分类器的概念,同时引入了循环矩阵和核函数提高运算速率。
答应我,看CSK或者KCF之前,请一定先去看一下SVM(支持向量机)!
顺便指路我学习SVM的整理(https://blog.csdn.net/qq_32763701/article/details/83859575),如果你看了这个,请跳转算法部分开始看
为什么引入循环矩阵?
很多文章里解释引入循环矩阵是为了利用循环矩阵的特性达到密集采样(dense sampling)和转到频域提高运算效率的目的,但循环矩阵具体是如何达到这一目的我姑且写一下我的理解。
我们回忆一下MOSSE算法里求相关性的操作是通过在怀疑区域里滑动卷积得到的,如果是要求密集采样(而不是随机采样)的话,要求卷积模板在这一区域从第一个像素滑动到最后一个像素,在这一区域产生大量候选窗(这些候选窗重合度还很大),最终目标匹配得到最后的输出结果。这一过程明显计算量巨大,影响跟踪速度。
所以作者引进循环矩阵这个好工具:

第一行为实际采集的目标特征,其他行表示周期性地把最后的矢量依次往前移产生的虚拟目标特征。因为整个循环矩阵都是由 n × 1 n\times 1 n×1 v e c t o r vector vector u ^ \hat{u} u^演变而来,所以循环矩阵不需要空间专门去保存它。这一操作的具体效果作者在15年的KCF算法里做了更直观地解释:

直接利用循环矩阵去和滤波器点乘(后面会解释)很直观地省略了卷积模板在检测区域内滑动的过程,简化了对重合度高的候选窗的运算,提高了速度。
也可以理解为滤波器模板在频域内与样本特征边缘求相关时边界循环补充的结构。
(解释见(https://blog.csdn.net/qq_17783559/article/details/82321239))

另一方面,如上图所示,循环矩阵对像素的移动产生了目标发生上下位移的结果,可以理解为在这一帧里样本数增加了。更多的样本数意味着训练的结果更准确。
此外,循环矩阵傅里叶对角化特性也是引入循环矩阵重要的原因之一。
根据循环矩阵的特点,存在 u ⊗ v = C ( u ) v = F − 1 ( F ( u ) ⊙ F ( v ) ) u\otimes v=C\left ( u \right )v=F^{-1}\left ( F\left ( u \right )\odot F\left ( v \right )\right ) u⊗v=C(u)v=F−1(F(u)⊙F(v))
利用这一特性证明循环矩阵的和、点积、求逆都是循环矩阵,在频域利用这一特性大大提高了运算速率。
(证明见(https://blog.csdn.net/shenxiaolu1984/article/details/50884830))
为什么引入核函数?
核函数是模式识别里的一个技巧。我们知道在低维空间中线性不可分的模式可以映射到高维空间实现线性可分,比如:(参考(https://blog.csdn.net/qq_32763701/article/details/83859575))
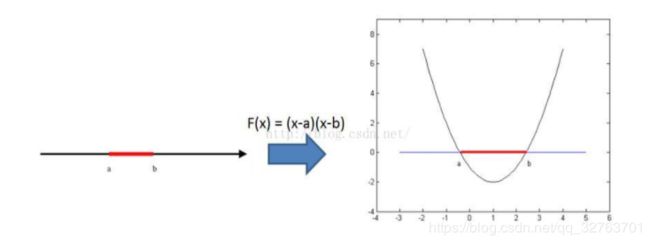
其中红线和黑线分别表示两类数据,在二维空间里线性不可分,映射到高维空间后利用二次函数(曲线)实现了可分。
但问题在于,虽然在高维空间实现了线性可分,但一是映射关系难以求解,二是在高维空间运算时,容易导致维数灾难,维数越大,计算量也指数增大。
引入核函数的目的是利用在原空间的核函数的值表示高维空间的向量的內积,简化计算。
在CSK算法的证明中,在将输入函数 x \mathbf{x} x映射到高维空间后,出现高位空间内的內积项 < φ ( x ) , φ ( x ′ ) > <\varphi \left ( \mathbf{x} \right ),\varphi \left ( \mathbf{x'} \right )> <φ(x),φ(x′)>。
核函数要实现的就是令 k ( x , x ′ ) = < φ ( x ) , φ ( x ′ ) > k\left ( \boldsymbol{x},\boldsymbol{x'} \right )=<\varphi \left ( \mathbf{x} \right ),\varphi \left ( \mathbf{x'} \right )> k(x,x′)=<φ(x),φ(x′)>,把高维空间的內积转换为原空间的核函数值。
算法:核化的最小二乘法(KRLS)
首先我们回忆一下MOSSE算法的基本模型
min H ∗ ∑ i ∣ F i ⋅ H ∗ − G i ∣ 2 \min_{H^*}\sum_{i}\left | F_{i}\cdot H^*-G_{i} \right |^{2} minH∗∑i∣Fi⋅H∗−Gi∣2
其中 F i F_{i} Fi是输入图像特征, H ∗ H^* H∗是滤波器, G i G_{i} Gi表示响应,具体推导过程见前一篇文章。相关滤波跟踪·MOSSE算法的梳理
CSK算法在MOSSE模型的基础上将相关用分类器运算表示,并做了一些修改
min w ∑ i L ( y i , f ( x i ) ) + λ ∥ w ∥ 2 \min_{w}\sum_{i}L\left ( y_{i},f\left ( \mathbf{x_{i} }\right ) \right )+\lambda \left \|\mathbf{w} \right \|^2 minw∑iL(yi,f(xi))+λ∥w∥2
嘛,虽然看起来各种不像,但其实化开以后本质还是一样的。
接下来进入推导过程。
一点小tips
首先,我们最好先弄懂几个小数学知识:
1. A A A是一个列向量, ∥ A ∥ 2 = A T ⋅ A \left \| A \right \|^2=A^T\cdot A ∥A∥2=AT⋅A
2. A A A, B B B均为列向量, A T ⋅ B = < A , B > A^T\cdot B =<A,B> AT⋅B=<A,B>
3. S = ∑ i = 1 n a i b i = a 1 b 1 + a 2 b 2 + ⋯ + a n b n S=\sum_{i=1}^na_{i}b_{i}=a_{1}b_{1}+a_{2}b_{2}+\cdots +a_{n}b_{n} S=i=1∑naibi=a1b1+a2b2+⋯+anbn
如果 A = [ a 1 a 2 ⋮ a n ] A=\begin{bmatrix} a{1}\\ a_{2}\\ \vdots \\ a_{n} \end{bmatrix} A=⎣⎢⎢⎢⎡a1a2⋮an⎦⎥⎥⎥⎤, B = [ b 1 b 2 ⋮ b n ] B=\begin{bmatrix} b{1}\\ b_{2}\\ \vdots \\ b_{n} \end{bmatrix} B=⎣⎢⎢⎢⎡b1b2⋮bn⎦⎥⎥⎥⎤,则 S = A T ⋅ B S=A^T\cdot B S=AT⋅B
如果 A = [ a 1 a 2 ⋮ a n ] A=\begin{bmatrix} a{1}\\ a_{2}\\ \vdots \\ a_{n} \end{bmatrix} A=⎣⎢⎢⎢⎡a1a2⋮an⎦⎥⎥⎥⎤, B = [ b 1 b 2 ⋯ b n ] B=\begin{bmatrix} b_{1} & b_{2}& \cdots & &b_{n} \end{bmatrix} B=[b1b2⋯bn],则 S = B ⋅ A S=B\cdot A S=B⋅A(行向量在前)
掌握了上述3个小技巧以后我们就可以继续勇敢地前进了!
继续*1
不管样本 X i X_{i} Xi是不是线性可分,将它映射到高维空间后, φ ( X i ) \varphi(X_{i}) φ(Xi)就线性可分了,也可以用线性分类器就行目标和背景的分类了。(顺便一说,下文推导中,凡是大写都是矩阵,小写都是矩阵中的元素,可能会和原文符号有所不同;还有, i i i对应的是第 i i i个样本! i i i对应的是第 i i i个样本! i i i对应的是第 i i i个样本!)
所以根据SVM,在高维空间中滤波器(SVM的权重)可以表示为样本的线性组合。
W = α 1 φ ( X 1 ) + α 2 φ ( X 2 ) + ⋯ = ∑ j = 1 n α j φ ( X j ) \begin{aligned} W&=\alpha_{1}\varphi(X_{1})+\alpha_{2}\varphi(X_{2})+\cdots\\&=\sum_{j=1}^n\alpha_{j}\varphi(X_{j})\end{aligned} W=α1φ(X1)+α2φ(X2)+⋯=j=1∑nαjφ(Xj)
所以线性分类器 f ( X i ) = < W , φ ( X i ) > + b = < ∑ j = 1 n α j φ ( X j ) , φ ( X i ) > + b = ∑ j = 1 α j < φ ( X j , φ ( X i ) > + b = ∑ j = 1 n α j κ ( X j , X i ) = ∑ j = 1 n α j κ ( X i , X j ) \begin{aligned} f(X_{i})&=<W,\varphi(X_{i})>+b\\ &=<\sum_{j=1}^n\alpha_{j}\varphi(X_{j}),\varphi(X_{i})>+b\\ &=\sum_{j=1}\alpha_{j}<\varphi(X_{j},\varphi(X_{i})>+b\\ &=\sum_{j=1}^n\alpha_{j}\kappa(X_{j},X_{i})\\ &=\sum_{j=1}^n\alpha_{j}\kappa(X_{i},X_{j}) \end{aligned} f(Xi)=<W,φ(Xi)>+b=<j=1∑nαjφ(Xj),φ(Xi)>+b=j=1∑αj<φ(Xj,φ(Xi)>+b=j=1∑nαjκ(Xj,Xi)=j=1∑nαjκ(Xi,Xj)
其中引入核函数 κ ( X i , X j ) = < φ ( X j , φ ( X i ) > \kappa(X_{i},X_{j})=<\varphi(X_{j},\varphi(X_{i})> κ(Xi,Xj)=<φ(Xj,φ(Xi)>, κ ( X i , X j ) \kappa(X_{i},X_{j}) κ(Xi,Xj)是矩阵 K K K的第i行第j列。
注意到 α = [ α 1 α 2 ⋮ α j ] \boldsymbol{\alpha }=\begin{bmatrix} \alpha_{1}\\ \alpha_{2}\\ \vdots\\ \alpha_{j} \end{bmatrix} α=⎣⎢⎢⎢⎡α1α2⋮αj⎦⎥⎥⎥⎤, K K K的第i行为 K i = [ κ ( X i , X 1 ) κ ( X i , X 1 ) ⋯ κ ( X i , X j ) ] K_{i}=\begin{bmatrix} \kappa(X_{i},X_{1}) & \kappa(X_{i},X_{1}) & \cdots & \kappa(X_{i},X_{j}) \end{bmatrix} Ki=[κ(Xi,X1)κ(Xi,X1)⋯κ(Xi,Xj)]
同学们,请抬头看看tips里的第3项第2类!
所以, f ( X i ) = K i α f(X_{i})=K_{i}\boldsymbol{\alpha} f(Xi)=Kiα,这是一个数啊同学们。
那么再来看一下正则项 1 2 ∥ W ∥ 2 = 1 2 W T W = 1 2 ∑ j = 1 n α j ( φ ( X j ) ) T ⋅ ∑ j = 1 n α j φ ( X j ) = 1 2 ∑ j = 1 n ∑ j = 1 n α j α j ( φ ( X j ) ) T φ ( X j ) = 1 2 ∑ j = 1 n ∑ j = 1 n α j α j < φ ( X j ) , φ ( X j ) > = 1 2 ∑ j = 1 n ∑ j = 1 n α j α j K j j = α 1 2 K 11 + α 1 2 K 11 + ⋯ α n 2 K n n = α T K α \begin{aligned}\frac{1}{2}\left \| W \right \|^2 &=\frac{1}{2}W^TW\\\\ &=\frac{1}{2}\sum_{j=1}^{n}\alpha_{j}(\varphi (X_{j}))^T\cdot \sum_{j=1}^{n}\alpha_{j}\varphi (X_{j})\\\\ &=\frac{1}{2}\sum_{j=1}^{n}\sum_{j=1}^{n}\alpha_{j}\alpha_{j}(\varphi (X_{j}))^T\varphi (X_{j})\\\\ &=\frac{1}{2}\sum_{j=1}^{n}\sum_{j=1}^{n}\alpha_{j}\alpha_{j}<\varphi (X_{j}),\varphi (X_{j})>\\\\ &=\frac{1}{2}\sum_{j=1}^{n}\sum_{j=1}^{n}\alpha_{j}\alpha_{j}K_{jj}\\\\ &=\alpha_{1}^2K_{11}+\alpha_{1}^2K_{11}+\cdots\alpha_{n}^2K_{nn}\\\\ &=\alpha^TK\alpha\end{aligned} 21∥W∥2=21WTW=21j=1∑nαj(φ(Xj))T⋅j=1∑nαjφ(Xj)=21j=1∑nj=1∑nαjαj(φ(Xj))Tφ(Xj)=21j=1∑nj=1∑nαjαj<φ(Xj),φ(Xj)>=21j=1∑nj=1∑nαjαjKjj=α12K11+α12K11+⋯αn2Knn=αTKα
继续*2
所以我们前面觉得不是很明白的从SVM角度写的模型从MOSSE的角度可以理解为
(1) L L L表示最小二乘法的损失函数
L ( Y i , f ( X i ) ) = ( Y i − f ( X i ) ) 2 L\left ( Y_{i},f\left ( X_{i}\right ) \right )=\left ( Y_{i}-f\left ( X_{i} \right ) \right )^2 L(Yi,f(Xi))=(Yi−f(Xi))2
很明显对应MOSSE中的方差。 Y i Y_{i} Yi是SVM中的标签,标记样本属于哪一边。这里作为响应,对应 g i g_{i} gi。
(2)线性分类器 f ( X i ) f\left ( X_{i} \right ) f(Xi) 表示滤波器 W W W和输入图像特征 φ ( X i ) \varphi(X_{i}) φ(Xi)相关的结果,对应 f i ⋅ h f_{i}\cdot h fi⋅h。
(3)模型增加了一个正则项,所以CSK的最小二乘法也被叫做正则最小二乘法,也叫岭回归。正则项增加的目的是为了排除一些循环矩阵变换后变形过度的虚拟样本。
继续*3
原模型转换为
m i n ∑ i = 1 m ( Y i − K i α ) 2 + λ α T K α min\sum_{i=1}^{m}(Y_{i}-K_{i}\boldsymbol{\alpha})^2+\lambda \boldsymbol{\alpha}^TK\boldsymbol{\alpha} mini=1∑m(Yi−Kiα)2+λαTKα
注意 ∑ i = 1 m ( Y i − K i α ) 2 \sum_{i=1}^{m}(Y_{i}-K_{i}\boldsymbol{\alpha})^2 ∑i=1m(Yi−Kiα)2,抬头看看刚才小tips里第三项第一类!
令 Y = [ y 1 y 2 ⋮ y m ] Y=\begin{bmatrix} y_{1}\\ y_{2}\\ \vdots\\ y_{m} \end{bmatrix} Y=⎣⎢⎢⎢⎡y1y2⋮ym⎦⎥⎥⎥⎤, K α = [ K 1 α K 2 α ⋮ K m α ] K\boldsymbol{\alpha}=\begin{bmatrix} K_{1}\boldsymbol{\alpha}\\ K_{2}\boldsymbol{\alpha}\\ \vdots\\ K_{m}\boldsymbol{\alpha} \end{bmatrix} Kα=⎣⎢⎢⎢⎡K1αK2α⋮Kmα⎦⎥⎥⎥⎤(K下标表示第几行)
所以上式可以化为 m i n [ ( Y − K α ) T ( Y − K α ) + λ α T K α ] min[(Y-K\boldsymbol{\alpha})^T(Y-K\boldsymbol{\alpha})+\lambda \boldsymbol{\alpha}^TK\boldsymbol{\alpha}] min[(Y−Kα)T(Y−Kα)+λαTKα]
因为对 α \alpha α没有约束条件,因此直接通过求导得到 α \alpha α最小值。(已知 K ! = 0 K!=0 K!=0)
∂ ∂ α m i n [ ( Y − K α ) T ( Y − K α ) + λ α T K α ] = m i n ( Y − K α ) T ( − K ) + λ α T K = m i n ( K α − Y ) + λ α T = 0 \begin{aligned} &\frac{\partial }{\partial \boldsymbol{\alpha}}min[(Y-K\boldsymbol{\alpha})^T(Y-K\boldsymbol{\alpha})+\lambda \boldsymbol{\alpha}^TK\boldsymbol{\alpha}]\\\\ &=min(Y-K\boldsymbol{\alpha})^T(-K)+\lambda \boldsymbol{\alpha}^TK\\\\ &=min(K\boldsymbol{\alpha}-Y)+\lambda \boldsymbol{\alpha}^T=0 \end{aligned} ∂α∂min[(Y−Kα)T(Y−Kα)+λαTKα]=min(Y−Kα)T(−K)+λαTK=min(Kα−Y)+λαT=0
得到
( Y − K α ) T = λ α T Y − K α = λ α α = ( λ I + K ) − 1 Y \begin{aligned} (Y-K\boldsymbol{\alpha})^T&=\lambda\boldsymbol{\alpha}^T\\ Y-K\boldsymbol{\alpha}&=\lambda\boldsymbol{\alpha}\\ \boldsymbol{\alpha}&=(\lambda I+K)^{-1}Y \end{aligned} (Y−Kα)TY−Kαα=λαT=λα=(λI+K)−1Y
继续*4
引入循环矩阵,已知循环矩阵的每一行都是上一行最后一列的元素或矢量移动到第一列,所以定义一个位移矩阵 P i P^i Pi
所以密集采样得到循环矩阵 C ( φ ( X ) ) C\left(\varphi(X)\right) C(φ(X)),其中每一行 X i X_{i} Xi表示为 P i X P^iX PiX,定义
k i = K i j = κ ( X i , X j ) = κ ( X , P i X ) k_{i}=K_{ij}=\kappa\left ( X_{i},X_{j} \right )=\kappa\left ( X,P^iX \right ) ki=Kij=κ(Xi,Xj)=κ(X,PiX)
因为采样的结果 φ ( X ) \varphi(X) φ(X)变成循环矩阵 C ( φ ( X ) ) C\left ( \varphi(X)\right) C(φ(X)),所以原来的 K K K也改为 k i k_{i} ki的循环矩阵 C ( k ) C\left (k\right) C(k)简化运算。
设 I = C ( δ ) , δ = [ 1 0 0 . . . 0 ] T I=C\left ( \delta \right ),\delta=\begin{bmatrix} 1 & 0 & 0 &... & 0 \end{bmatrix}^T I=C(δ),δ=[100...0]T
α = ( C ( k ) + λ C ( δ ) ) − 1 Y \boldsymbol{\alpha} =\left ( C\left ( k \right )+\lambda C\left ( \delta \right ) \right )^{-1}Y α=(C(k)+λC(δ))−1Y
循环矩阵的和、点积、求逆都是循环矩阵
α = ( C ( k + λ δ ) ) − 1 Y \boldsymbol{\alpha} =\left ( C\left ( k +\lambda \delta \right ) \right )^{-1}Y α=(C(k+λδ))−1Y
傅里叶线性变换
α = ( C ( F − 1 ( F ( k ) + λ F ( δ ) ) ) ) − 1 Y \boldsymbol{\alpha} =\left ( C\left ( F^{-1}\left( F\left ( k \right ) +\lambda F\left(\delta\right ) \right ) \right )\right )^{-1}Y α=(C(F−1(F(k)+λF(δ))))−1Y
循环矩阵的和、点积、求逆都是循环矩阵
α = C ( F − 1 ( 1 F ( k ) + λ F ( δ ) ) ) Y \boldsymbol{\alpha} = C\left ( F^{-1}\left( \frac{1}{F\left ( k \right ) +\lambda F\left(\delta\right ) }\right ) \right )Y α=C(F−1(F(k)+λF(δ)1))Y
由于
F ( δ ) = 1 F\left(\delta\right )=1 F(δ)=1
所以
α = C ( F − 1 ( 1 F ( k ) + λ ) ) Y \boldsymbol{\alpha} = C\left ( F^{-1}\left( \frac{1}{F\left ( k \right ) +\lambda }\right ) \right )Y α=C(F−1(F(k)+λ1))Y
利用 u ⊗ v = C ( u ) v = F − 1 ( F ( u ) ⊙ F ( v ) ) u\otimes v=C\left ( u \right )v=F^{-1}\left ( F\left ( u \right )\odot F\left ( v \right )\right ) u⊗v=C(u)v=F−1(F(u)⊙F(v))
α = F − 1 ( F ( Y ) F ( k ) + λ ) \boldsymbol{\alpha} = F^{-1}\left( \frac{F\left (Y \right )}{F\left ( k \right ) +\lambda }\right ) α=F−1(F(k)+λF(Y))
利用以上封闭解可以在频域快速得到滤波器 W W W参量 α \boldsymbol{\alpha} α
继续*5
定位用的响应图
Y = F − 1 ( F ( k ) ⊙ F ( α ) ) Y=F^{-1}\left ( F\left ( k \right )\odot F\left ( \alpha \right ) \right ) Y=F−1(F(k)⊙F(α))
本质也是高维空间的相关操作。
推导过程如下:
知道Y是一个列向量,所以
Y = < W , φ ( Z ) > = ∑ α i < φ ( X i ) , φ ( Z ) > = K α Y=<W,\varphi(Z)>=\sum\alpha_{i}<\varphi \left ( X_{i} \right ),\varphi \left ( Z \right )>=K\boldsymbol{\alpha} Y=<W,φ(Z)>=∑αi<φ(Xi),φ(Z)>=Kα
Z是该帧未定位(求相关之前)提取的图像特征,X是该帧二次提取的图像特征,X,Z均可为循环矩阵。
所以
Y = α C ( k ) Y=\boldsymbol{\alpha}C\left ( k \right ) Y=αC(k)
还是用 u ⊗ v = C ( u ) v = F − 1 ( F ( u ) ⊙ F ( v ) ) u\otimes v=C\left ( u \right )v=F^{-1}\left ( F\left ( u \right )\odot F\left ( v \right )\right ) u⊗v=C(u)v=F−1(F(u)⊙F(v))
Y = F − 1 ( F ( α ) ⊙ F ( k ) ) Y=F^{-1}\left ( F\left ( \boldsymbol{\alpha}\right )\odot F\left (k \right ) \right ) Y=F−1(F(α)⊙F(k))
另外,核函数有很多种,本文使用高斯核函数,可以将数据映射到无穷维,也叫做径向基函数(Radial Basis Function 简称 RBF),是某种沿径向对称的标量函数。通常定义为空间中任一点x到某一中心xc之间欧氏距离的单调函数 ,可记作 k(||x-xc||), 其作用往往是局部的,即当x远离xc时函数取值很小。
k = e x p ( − 1 σ 2 ( ∥ x ∥ 2 + ∥ x ′ ∥ 2 − 2 F − 1 ( F ( x ) ⊙ F ( x ′ ) ) ) ) k=exp\left ( -\frac{1}{\sigma ^2} \left ( \left \| x \right \|^2 + \left \| x' \right \|^2 - 2F^{-1}\left ( F\left ( x \right ) \odot F\left ( x' \right ) \right )\right )\right ) k=exp(−σ21(∥x∥2+∥x′∥2−2F−1(F(x)⊙F(x′))))
继续*6
具体的学习更新流程基本和MOSSE一样,我直接改一下MOSSE的流程图,更详细的操作参考相关滤波跟踪·MOSSE算法的梳理
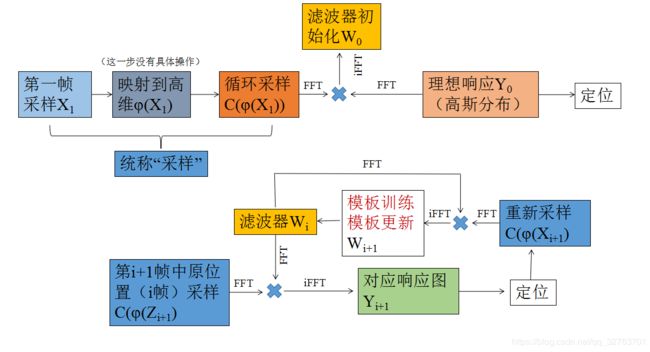
以上,欢迎交流。
[分割线181104]
※问题已解决
[分割线181109]
※重新整理了一遍