java使用freemarker模板导出word(docx格式;流形式输入输出)
前言:好久没有更文了,最近又再做关于导出word文档项目。其实网上很多有关导出的博文,多数是大同小异的,但是还远远不能满足我的需求。之前写过一篇导出word的文章,那个还不太成熟,随着业务的增加,肯定有了不小的变化,所以今天这篇文章索性就叫续集吧,希望可以帮到大家!
上一篇写的是有关doc格式的。具体详情请访问:点击打开链接,在这里说明一下上篇存在的一些问题:
1、记得上篇说到获取模板的时候,是通过new File("url")的形式来获取的;其实我是不推荐这种方式的,除非是你们的需求就是这样要求的;我在导出的过程中,模板(testword.ftl)是以Blob大型文件存在mysql中的,然后我可以以流的形式获取到这个模板,包括导出过程中,任意涉及到文件的输入输出的时候,尽量的都要使用流来操作;下面我贴一下代码:
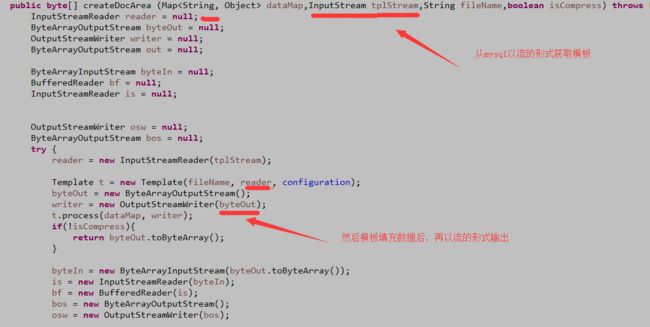
我想你百度了很多导出的文章,应该大多数都是以下面这种形式获取的吧:
System.out.println("---进入createDocArea---");
this.configuration.setDirectoryForTemplateLoading(new File("/template/"));//第二种模板路径
Template t = null;
File outFile = null;
byte[] bFile = null;
try {
t = this.configuration.getTemplate(fileName,"UTF-8");
} catch (Exception e) {
e.printStackTrace();
return null;
}
outFile = new File(outFilePath);
Writer w = null;
FileOutputStream fos = null;
try {
fos = new FileOutputStream(outFile);
OutputStreamWriter osw = new OutputStreamWriter(fos,"UTF-8");
w = new BufferedWriter(osw);
} catch (Exception e) {
e.printStackTrace();
return null;
} 输入和输出都是以File的形式;这不是我想要的;我要的是,以流的形式获取,以流的形式导出,然后转换成字节存到数据库中,比如mongo;还是那句话,看你需求。
2、第二个问题就是,写导出很痛苦的,我以为最后成功的导出xxx.doc后就万事大吉了,结果有一天客户说,手机应用wps打开这个文档是乱码;其实并不是乱码,之前说过,word文档本身就是一个.xml文件,你导出来以后,虽然命名为.doc,单实质还是一个xml,所以手机wps会以xml文件格式打开,然后你会看到里面的代码,客户当然认为那是乱码。我从网上查了一下,只要导出.docx格式就可以了,如果哪个网友找到了其他的方法请告诉我;所以今天这篇文章主要是来讲如何导出docx格式word的。
导出docx格式的word文档
我也是在网上找的,大家可以百度搜一下,也是一大堆,我只是在基础上改良了一下。你说的没错,还是以流的形式输入输出。
普及一下,原来.docx格式的word竟然是一个压缩文件,再一次颠覆了我的世界观;不信你可以试着用压缩工具打开一下.docx并解压,你会发现很有趣的东西:
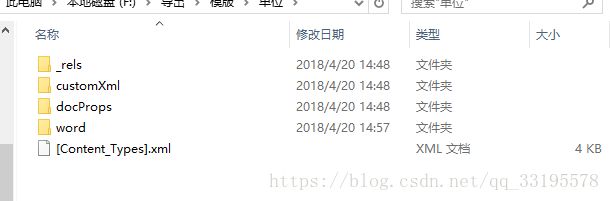
这就是解压出来的目录,然后你再点击word进去:
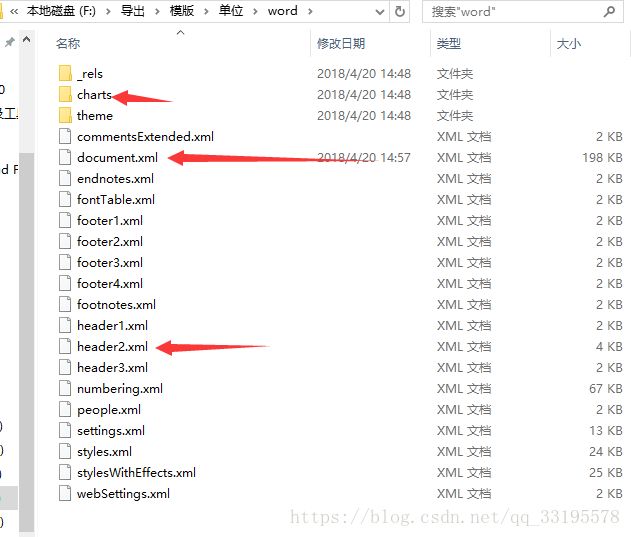
其实一个word里面有文字,有表格,有图表,有页眉。。。等等,他是把每个部分都单独拿出来了,所以你写完以后会发现,耦合性很低,修改模板的时候比较容易,因为每一部分都是分开的,你只需要修改需要的那一部分就可以了,出错率比较低;关键能满足用户的需求,用手机wps可以打开看。
先说一下这个原理:大家可以看到里面那个document.xml 这个文件就是你文档里的所有文字包括表格,所以你拿到数据以后,只需要把这个模板填充一下数据就行,具体这么往模板里填充,请看这儿点击打开链接;然后你填充完数据以后只需要把这个填充好的document.xml给替换掉就可以了;然后大家也看到charts文件夹里的东西了,那个如果你有图表的话,再把那个制作成模板,填充数据,再替换就可以了,跟document是一样的做法,包括下面那个header.xml那个是页眉上的模板。所以大家如果想写哪一块儿,这里面都有,找到对应的替换掉就可以了。
那么问题来了,我怎样来替换这个填充好的模板?如果我要填充的模板多了,怎么做?
一、你首先准备一个word.docx,里面的格式你要事先准备好:

准备好以后,把这个解压,如果你只需要document.xml一个文件,那么你只需要拿出来这一个就行了,然后把document.xml里面的格式给整理一下,不会的看这儿点击打开链接;一切弄好以后,现在你手里有两个:word.docx和document.xml两个文件;我把这两个都存在了mysql中,导出的时候都以流的形式取出来;
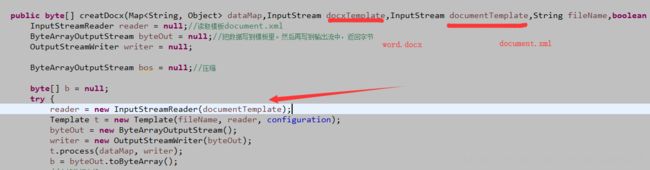
还按以前的方法,把document.xml给填充上数据(这个不用转成document.ftl);
现在你手里有word.docx(流的形式,已经从数据库拿过来了)和document.xml(有数据的,并且以流的形式输出了,可以输出字节,这样,你拿的就是有数据的字节byte[])
接下来就是把这个有数据的document.xml给替换到word.docx里面;已经说了word是一个压缩文件,所以替换过程肯定需要解压的,然后替换完了,再压缩回去;那么就用到了两个流:ZipInputStream和ZipOutputStream,顾名思义,一个是解压的,一个是压缩的;
如果你从网上找,会看到类似这样的代码:

其中srcFile就是word.docx,因为你要把这个解压出来,然后替换里面新的,然后替换完以后再输出本地;

其中那个destFile就是你替换完以后,把新生成的word给写到磁盘上了;
然后我需要做的就是把这种输入输出的格式,换成以流的形式输入,替换完以后再以流的形式输出,这样的过程,你根本不需要往本地磁盘操作文件,从库里取出,经过流,再存到库里,这是中心思想;
那怎么把document.xml流文件取出呢?
private void outDoc(ByteArrayOutputStream bos,InputStream is,byte[] b){
ZipInputStreamZipEntrySource zipFile;
try {
zipFile = new ZipInputStreamZipEntrySource(new ZipInputStream(is));
Enumeration zipEntrys = zipFile.getEntries();
ZipOutputStream zipout = new ZipOutputStream(bos);
ByteArrayInputStream byteIn = null;
while(zipEntrys.hasMoreElements()) {
ZipEntry next = zipEntrys.nextElement();
InputStream _is = zipFile.getInputStream(next);
//把输入流的文件传到输出流中 如果是word/document.xml由我们输入
zipout.putNextEntry(new ZipEntry(next.toString()));
if("word/document.xml".equals(next.toString())){
byteIn = new ByteArrayInputStream(b);
int c;
while ((c = byteIn.read()) != -1) {
zipout.write(c);
}
byteIn.close();
}else {
int c;
while ((c = _is.read()) != -1) {
zipout.write(c);
}
_is.close();
}
}
zipout.close();
} catch (IOException e) {
e.printStackTrace();
}
}其中,参数bos是我要把新的word输出到流里面,is就是以流形式的word.xml,byte[] b 是已经填充好的document.xml 我把他转成字节了;里面的代码我就不解释了,就是一个解压的过程,然后把解压文件判断一下,如果是document.xml那么就把他替换掉,如果不是,就原样压缩回去;
这里需要注意的是:

一定要一个字节一个字节的往流里写,如果你定义的是:byte[] b = new byte[1024];
如果已一次1024的字节往里写,最后导出来的word是有错误的,因为每次取1024个,假如word里面的数不够1024个字节了,那么他就会把空的给输出去,所以,一定要一个一个的输出。
二、如果你文档里面还有图表charts之类的,你可以这样做:
你一开始不是把word个解压出来了吗?然后保持原格式
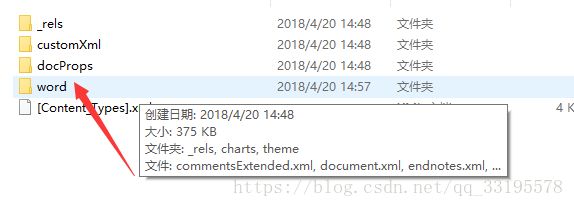
把这个word文件夹单独拿出来,然后里面保持原路径,需要哪个文件就留下哪个文件;
然后你可以把以map的形式把需要的文件以路径为key,把具体文件以value的形式存到map里;
比如:document.xml
Map map = new HashMap<>;
map.put("word/document.xml",documentTemplate)
documentTemplate就是document.xml 流文件;
这样你填充数据的时候,循环往里填充,替换文件的时候,根据这个key来判断,是否是一样的路径,是的话,就替换。基本上思路就是这样的;至于这个多个文件你一开始的时候你怎么存到数据库,你可以把他压缩一下存到数据库,填充数据的时候再解压出来;
到这儿基本就完了,把文件输出到ByteArrayOutputStream里,你就可以把它转成字节存到数据库了。下载的时候把这个字节写出就行了。
用这种方式导出还有一个好处就是,你会发现,同样一个word。导出doc格式的文件大小要比docx格式的文件大小大的多,所以还是推荐用这种;
写的也不多,很多细节没写,因为网上都有,最主要的还是传达的流思想吧,希望可以帮到大家,如果哪儿没看明白的,可以问我,大家可以一起探讨一下;
文章我就不检查了,请忽略里面的错别字,或者错误的代码,要领略思想,看重点,哈哈