Importance Weighted Adversarial Nets for Partial Domain Adaptation
个人对论文的见解,本人初涉机器学习,有错误的地方还请指正。谢谢!
论文地址:https://arxiv.org/abs/1803.09210
参考博文:https://blog.csdn.net/c9Yv2cf9I06K2A9E/article/details/79911316
参考博文:https://blog.csdn.net/ltochange/article/details/78773476(领域自适应简述)
note:领域学习、迁移学习、自适应差别
自适应学习(最浅):是学知识,相同知识的转换,你懂的宋体的‘3’怎么认,所以你也可以认得到楷体的‘3’.
迁移学习:学方法,学一个大概分类方法。可以应用在别的分类上(不是相同知识(自适应),也不会零样本(领域学习))
领域学习(最深):学的是能力,你能认得到猫,要加上从文本知识可以认得到老虎(文本+图片)。认老虎也叫“零样本学习”。
三种不同的领域自适应方法(来源于参考的第2篇博文,不懂对不对):
1)样本自适应,对源域样本进行加权重采样,从而逼近目标域的分布。(论文应该是这种)
2)特征层面自适应,将源域和目标域投影到公共特征子空间。
3)模型层面自适应,对源域误差函数进行修改,考虑目标域的误差。
一、论文工作
提出了一种加权对抗网络的无监督域适应,针对目标域类别标签少或者无类别标签。
我们目前接触过的绝大部分迁移学习问题情景都是:源域和目标域的特征空间与类别空间一致,只是数据的分布不一致,如何进行迁移。也就是说,源域和目标域要是几类,都是几类。
然而现实不实用,现实中target label<
二、论文方法
工作流程主要是:特征提取(F部分),权重获取(D部分),领域适应(D0部分)。
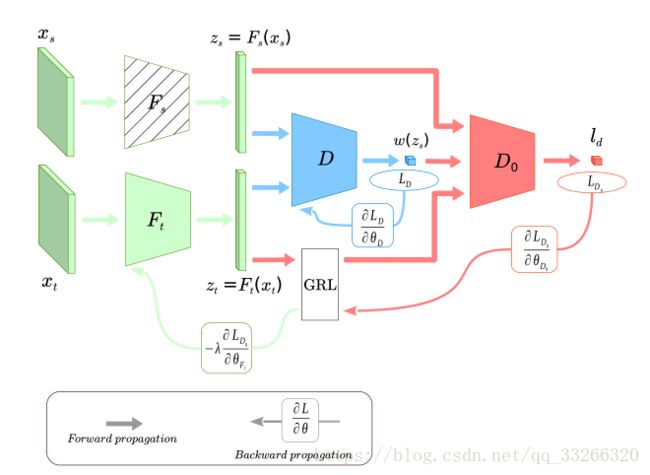
2.1、特征提取
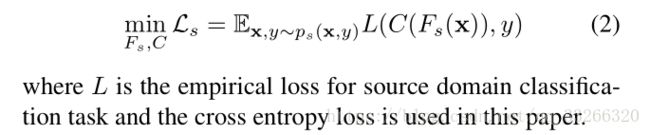
通过source data的类别来提取特征。这是论文的预训练部分。
2.2、权重获取
此部分是该论文的核心创新点。主要思路是,由 Fs 和 Ft 产生的源域和目标域特征 Zs 和 Zt,通过一个领域分类器 D,判别样本是来自于源域还是目标域。

这个 D 是一个二类分类器,如果 D=1(Ps(Z)==1,Pt(Z)==0),显然表示样本来自源域;否则,样本则来自目标域。
也就是说,D(Z)越大,只跟源领域相关跟目标领域无关的可能性越大(异常类outlier),相反,源领域和目标领域的共享类的D*(Z)应该是很小的。所以我们可以得到权重公式:
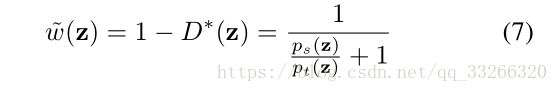
也就是说共享类的权重大,只跟源领域相关跟目标领域无关的权重小。
这是第一个分类器的任务。
2.3、领域适应
加入权重以后,优化目标变成了:
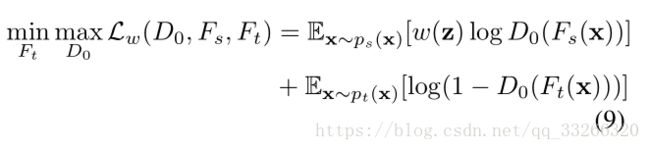
D(源)=1,D(目标)=0,通过这最大最小化。使得源和目标自适应,不分彼此。
作者还加了一个熵最小化项用于对目标域的样本属性进行约束
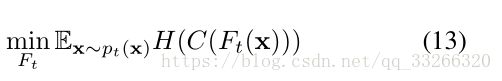
最小化熵(熵越小,数据越不混乱),目的是让目标域的类别少。
现在,总的步骤就是:
特征提取: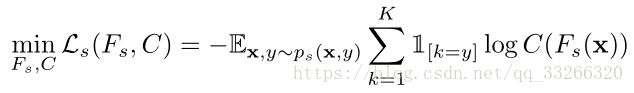
权重获取: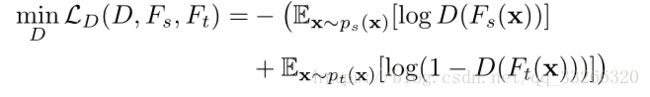
领域适应: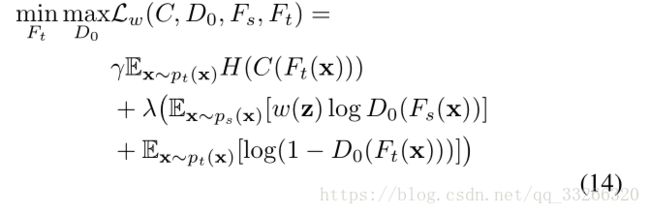
3、实验分析
RevGrad:域分类器+正则化
RTN:减少域迁移通过RTN
ADDA-grl:论文的未加权版本
SAN:在target label多的时候效果好。label多,参数也多。
其他不写了。。。反正实验分析就是说这个方法是多么好。。。