HTTP详解--Http请求(四)
HTTP报文
1.用于HTTP协议交互的信息被称为HTTP报文。请求端(客户端)的HTTP报文叫做请求报文,响应端(服务器端)的叫做响应报文。HTTP报文本身是由多行(用CR+LF作换行符)数据构成的字符串文本;
一.浏览器的http请求都发送了什么?
1.说明:一个完整的HTTP请求包括如下内容:
一个请求行、若干请求头、以及实体内容,其中的一些消息头和实体内容都是可选的,消息头和实体内容之间要用空行隔开。
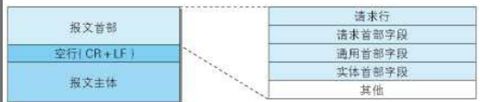
2.报文结构如下图。重要的是报文首部和报文的主体部分,中间的部分主要是要来分割首部和主体的。报文主体并不一定非要出现。

3.请求报文结构
4.一个请求示例
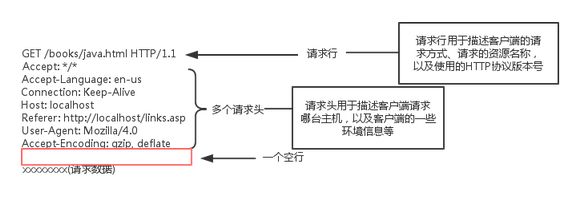
二.请求行详解
1.GET /day09/hello HTTP/1.1 :表示向服务器用GET方式请求day09/hello,使用HTTP:/1.1协议,这是发送请求时,必须要有的;
(1).HTTP1.0和HTTP1.1的区别:
1)在HTTP1.0协议中,客户端与web服务器建立连接后,只能获得一个web资源。
2)HTTP1.1协议,允许客户端与web服务器建立连接后,在一个连接上获取多个web资源。(常用)
2.请求方式(get与post):
(1)常见的请求方式: GET 、 POST、 HEAD、 TRACE、 PUT、 CONNECT 、DELETE
(2)常用的请求方式: GET 和 POST
(3)GET和POST的区别:
1)传输特点:
Get(默认值):是通过URL传递表单值,参数会放在报文头中;
Post:传递的参数值是隐藏到http报文体中,URL中看不到。在浏览器端每次刷新页面,服务器都会提示浏览器要重新传输请求。
另外,只有POST提交的参数会放到实体内容中
2)区别是什么?
1)get是通过地址栏(URI)会跟上参数数据。以?开头,多个参数之间以&分割。而post通过地址栏看不到参数值,适合传递密码;
2)get传递的数据量是有限的,不超过1KB,如果要传递大数据量不能用Get。而post则没有这个限制
3)get浏览器可能会缓存,post一定不会缓存
3)如何通过外在表象判断两者?
只要在地址栏中输入一个网址回车能访问,那么就是GET
4)如果Get和Post两者的请求一致?
那么直接在doGet方法中,添加处理代码。之后在doPost方法中,使用this.doGet()调用相同的处理方式即可。
总之,两者公用一段代码即可
注意:
重写doGet或者doPost的时候,不要保留super.doGet()或者super.doPost()。这两个方法会抛出一个异常。
3.请求资源
URL: 统一资源定位符。http://localhost:8080/day09/testImg.html。只能定位互联网资源。是URI的子集。
URI: 统一资源标记符。/day09/hello。用于标记任何资源。可以是本地文件系统,局域网的资源(//192.168.14.10/myweb/index.html),可以是互联网。
三.请求头详解(Request Headers部分)
说明:请求头中的参数不一定每次请求都存在
| Accept: text/html,image/* |
浏览器接受的数据类型 |
| Accept-Charset: ISO-8859-1 |
浏览器接受的编码格式 |
| Accept-Encoding: gzip,compress |
浏览器接受的数据压缩格式 |
| Accept-Language: en-us,zh |
浏览器接受的语言 |
| Host: www. bing.org:80 |
(必须的)当前请求访问的目标地址(主机:端口) |
| If-Modified-Since: Tue, 11 Jul 2000 18:23:51 GMT |
浏览器最后的缓存时间 |
| Referer: http: //www.bing.org/index.jsp |
当前请求来自于哪里 |
| User-Agent: Mozilla/4.0 (compatible; MSIE 5.5; Windows NT 5.0) |
浏览器类型 |
| Cookie:name=eric |
浏览器保存的cookie信息 |
| Connection: close/Keep-Alive |
浏览器跟服务器连接状态。close: 连接关闭 keep-alive:保存连接。 |
| Date: Tue, 11 Jul 2000 18:23:51 GMT |
请求发出的时间 |
四.范围请求
1.作用:当我们下载尺寸稍大的图片或文件时,如果出现网络中断,可以通过该技术从之前的下载中断处恢复下载;(也就是所谓的"断点续传"功能)
1.1 该功能的实现,需要指定下载的实体范围;
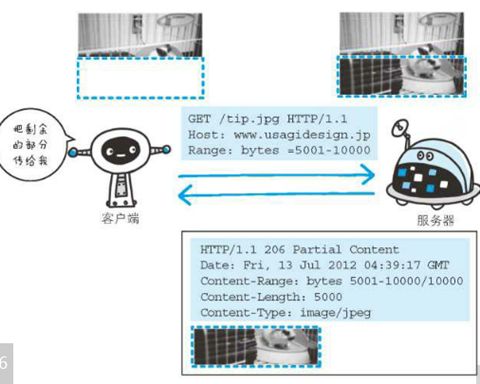
2.Range
(1)执行范围请求需要首字段Range来指定byte范围。Range字段可以通过三种格式设置要传输的字节范围:
(2)例,web服务器有一个资源,比如是a.txt,内容为:
(3)示例代码:
public class RangeDemo {
public static void main(String[] args) throws Exception {
URL url = new URL("http://localhost:8080/day04/a.txt");
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
conn.setRequestProperty("Range", "bytes=5-");
InputStream in = conn.getInputStream();
int len = 0;
byte[] buffer = new byte[1024];
FileOutputStream out = new FileOutputStream("c:\\a.txt", true);
while((len=in.read(buffer)) != -1) {
out.write(buffer, 0, len);
}
in.close();
out.close();
}
}
//运行以上程序,该用户就下载完剩下的数据了。
五.内容协商返回最合适的内容
1.同一个网站可能存在多份相同内容的页面。比如英文版或者中文版的Web页面。
2.当浏览器的默认语言为英文或者中文,访问相同的URI的Web页面时,则会显示对应的英文版或中文版的Web页面,这样的机制被称为"内容协商";
3."内容协商"会以响应资源的语言,字符集,编码方法等作为判断的基准;
4."内容协商"技术有以下3种类型:
4.1服务器驱动协商:由服务器端进行内容协商。以请求的首部字段为参考,在服务器端自动处理。但对用户来说,以浏览器发送的信息作为判定的依据,并不一定能筛选出最优内容;
4.2客户端驱动协商:由客户端进行内容协商的方式。用户从浏览器显示的可选项列表中手动选择。还可以利用JavaScript脚本在Web页面上自动进行上述选择。
4.3透明协商:是服务器驱动和客户端驱动的结合体,是由服务器端和客户端各自进行内容协商的一种方法;
六.伪造报文?
1.因为上面的信息都是浏览器发送给服务器的,所以完全可以通过修改浏览器的报文来发送假的报文给服务器。
2.作为开发人员,一定要明白报文是可以伪造的这一点!