Python数据处理(二)——美国人的生日
本篇文章的目的:以美国人的生日统计分析为例,熟练统计分组的操作,基本的数据可视化图形绘制;涉及到Python 中的numpy、pandas和matplotlib库,包括:df.pivot_table()、plt.ylabel()、np.percentile()、df.query()等函数。本篇也涉及到用Sigma -clippin去除异常值,时间格式的转换等。
数据来源:https://github.com/jakevdp/data-CDCbirths/
数据说明:读入births.csv文件,共14610条记录;5个字段,分别是:年代,月份,性别和出生人数
1.读入数据,显示基本数据情况
导入需要的Python库,读入数据,显示数据情况
%matplotlib inline
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib as mpl
birth = pd.read_csv(r'data-CDCbirths-master/births.csv')
birth.head() #显示前5行数据,tail()表示显示后5行数据
len(birth) #显示数据总行数显示结果如下:

2.统计年代情况,观察每年美国人男女总人数的增长情况
步骤:计算年代(原始数据中没有)并形成新的字段—》统计各年代的男女比例—》按性别分组,统计每一年的男女出生总人数—》绘制统计图
使用函数:df.pivot_table(values=None, index=None, columns=None, aggfunc='mean', fill_value=None, margins=False, dropna=True, margins_name='All')
部分参数说明:values:数值,用于分组计算的数值;index:索引,结果显示索引,按索引分组;
columns:分组的列,分组结果会单独显示列; aggfunc:计算函数,函数使用会加引号。
(一)计算年代和统计各年代的男女比例。使用到numpy的通用函数;数据框求和函数:df.sum(axis=0/1),默认为0,0表示按列求和,1表示按行求和,等同于np.sum(df, axis=0/1)
代码如下:
birth['decade'] = 10 * (birth['year'] // 10) #计算年代,其中10年为一个年代
#按年代和性别进行分组,对出生人数进行求和;索引为年代,列为性别。
sta = birth.pivot_table('births', index='decade', columns='gender', aggfunc='sum')
sta_sum = pd.DataFrame(sta.sum(axis=1)) #按行计算每个年代的总人数
print(sta)
np.divide(sta, sta_sum) #np.divide()通用函数,相当于sta/sta_sum结果显示:

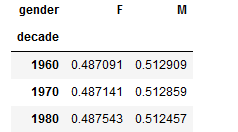
结论:该数据中包含3个年代,20世纪60-80年代;出生人数随年代呈上升趋势;其中各年代的男性出生率高于女性出生率,为2%左右;且男性出生率占比有下降趋势,反之女性出生率占比有上升趋势,但数据量较少,这种变化趋势的可信度不高。
(二)由于年代的统计数据较少,所以对每年男女出生人数进行统计并绘制成图形。代码如下:
birth.pivot_table('births', index='year', columns='gender', aggfunc='sum').plot()
plt.ylabel('total births per year')显示结果:

结论:该变化趋势同上面结论一致。可以通过计算每年男女占比来绘制图形,观察男女出生率占比的变化趋势,验证上述猜测结果。
(三)本次在一个画布中绘制两个图形使用到matplotlib模块,具体函数使用原理不做解释
代码:
sta1 = birth.pivot_table('births', index='year', columns='gender', aggfunc='sum')
calu = np.divide(sta1, pd.DataFrame(sta1.sum(axis=1))) #计算比例形成一个新的数据框
#在一个画布上,创建两个图形
fig, ax = plt.subplots(2)
ax[0].plot(calu.index, calu.M) #绘制第一个图像
ax[1].plot(calu.index, calu.F) #绘制第二个图像显示结果:

结论:该图形能看出男性出生率占比随年代增加呈下降趋势,女性出生率占比呈上升趋势,与年代统计结果猜测一致。
3.筛选有效出生率数据
采用Sigma -clippin消除法,去除异常值。
原理:按照正态分布标准差划定范围;
计算方式:取下四分之一分位数、中位数和上四分之一分位数,即25%、50%和75%;计算样本均值的稳定性估计,公式为:
![]() 样本均值的稳定性估计 = 0.74 * (上1/4分位数 - 下1/4分位数)
样本均值的稳定性估计 = 0.74 * (上1/4分位数 - 下1/4分位数)
其中0.74是指标准正态分布的分位数间距。
本篇文章对Sigma -clippin消除法的解释来源于自己的理解,如有错误,请选择性观看。
代码:
quartiles = np.percentile(birth['births'], [25, 50, 75]) #分位数
mu = quartiles[1]
sig = 0.74*(quartiles[2] - quartiles[0])
birth = birth.query('(births > @mu - 5 * @sig) & (births < @mu + 5 * @sig)') #筛选有效生日日期
birth.day = birth.day.astype(int) #格式转换4.计算星期,绘制一周各个年代的变化趋势图
首先将单独的年月日字段转为日期格式:“年-月-日”,使用函数pd.datetime(),具体参数说明可以通过官网查看或是在IPython环境下,输入命令pd.to_datetime?查看;介绍一下如何生成从某一时间段增长的日期。
代码如下:
#测试
datetime = pd.to_datetime(range(50), unit='D',
origin=pd.Timestamp('2013-01-01')) #生成从某一年开始增长的日期
rng = np.random.RandomState(120)
tes1 = pd.DataFrame({'datetime':datetime, 'val':rng.rand(50)})
tes1.head()
tes1.index = pd.to_datetime(tes1.datetime)
tes1.index.day #可使用day.year,month查看日期的年月日显示结果:
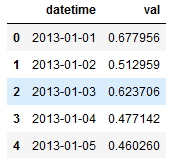

观察得到,以"%Y/%m/%d"为索引的格式可以通过df.index.year/month/day 命令得到以该日期格式中的年/月/日
然后dayofweek()函数,该函数会直接将日期计算为星期,最后绘制每个年代在一周之内出生率的变化图。代码如下:
birth.index = pd.to_datetime(birth[['year','month','day']],
format = '%Y/%m/%d')
birth['dayofweek'] = birth.index.dayofweek
#绘制各年代出生率在一周之内的变化趋势图
birth.pivot_table('births', index='dayofweek',
columns='decade', aggfunc='mean').plot()
plt.gca().set_xticklabels(['Mon', 'Tues', 'Wed', 'Thurs', 'Fri', 'Sat', 'Sun']) #设置横坐标标签值
plt.ylabel('mean births by day')结果显示:
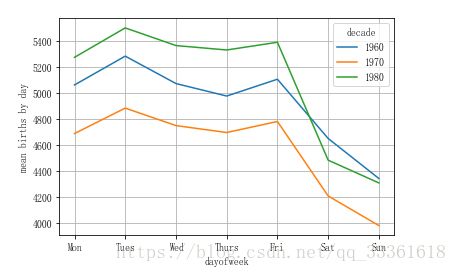
结论:周末出生人数明显低于工作日的出生人数。
扩充:解决matplotlib绘制图像出现中文乱码的情况,原理:修改字体参数。
代码:
from pylab import mpl
#修改字体,解决中文乱码
mpl.rcParams['font.sans-serif'] = ['FangSong']
mpl.rcParams['axes.unicode_minus'] = False5.绘制一年中平均每天出生人数的时间序列图像
按月、日两个维度分别进行分组,虚构年份,和日月组成索引,然后绘制图形
代码:
birth_by_date = birth.pivot_table('births',
[birth.index.month, birth.index.day])
#当aggfunc参数不写时,默认为np.mean(),即默认对分组的值求均值
#虚构年,按日、月组成新的索引
birth_by_date.index = [pd.datetime(2012, month, day)
for (month, day) in birth_by_date.index]
#绘制图像
fig, ax = plt.subplots(figsize=(12, 4)) #设置画布区域大小
birth_by_date.plot(ax=ax)图像显示:

结论:出生人数在一年中某一时间段上有明显的下降,观察该部分日期,发现此时间基本属于美国节假日,医院放假导致接生减少。
也可以详细的绘制此部分的图像。代码:
# Plot the results
fig, ax = plt.subplots(figsize=(8, 6))
birth.groupby(dates)['births'].mean().plot(ax=ax)
# Label the plot
ax.text('2012-1-1', 3950, "New Year's Day")
ax.text('2012-7-4', 4250, "Independence Day", ha='center')
ax.text('2012-9-4', 4850, "Labor Day", ha='center')
ax.text('2012-10-31', 4600, "Halloween", ha='right')
ax.text('2012-11-25', 4450, "Thanksgiving", ha='center')
ax.text('2012-12-25', 3800, "Christmas", ha='right')
ax.set(title='USA births by day of year (1969-1988)',
ylabel='average daily births',
xlim=('2011-12-20','2013-1-10'),
ylim=(3700, 5400));
# Format the x axis with centered month labels
ax.xaxis.set_major_locator(mpl.dates.MonthLocator())
ax.xaxis.set_minor_locator(mpl.dates.MonthLocator(bymonthday=15))
ax.xaxis.set_major_formatter(plt.NullFormatter())
ax.xaxis.set_minor_formatter(mpl.dates.DateFormatter('%h'));图像显示:
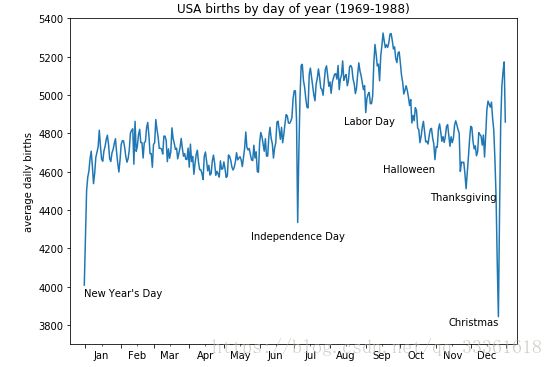
该图形增加了标注,以及图例,为了方便观察,也可以将图中显示的英文替换为相应的中文。