Python爬虫数据提取方式——使用bs4提取数据
爬虫网络请求方式:urllib(模块), requests(库), scrapy, pyspider(框架)
爬虫数据提取方式:正则表达式, bs4, lxml, xpath, css
测试HTML代码:
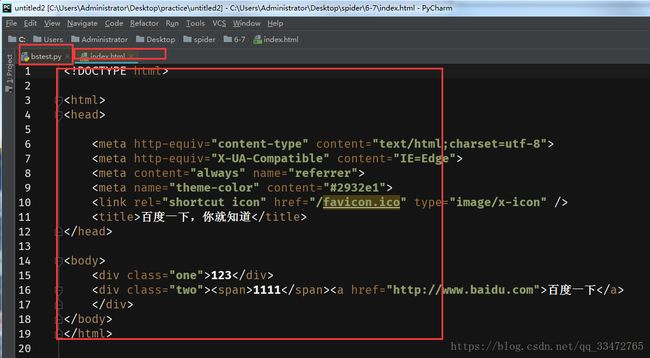
首先导入
from bs4 import BeautifulSoup序列化HTML代码
# 参数1:序列化的html源代码字符串,将其序列化成一个文档树对象。
# 参数2:将采用 lxml 这个解析库来序列化 html 源代码html = BeautifulSoup(open('index.html', encoding='utf-8'), 'lxml')开始查找标签和属性
获得HTML的title和a标签
print(html.title)
print(html.a)获取一个标签的所有(或一个)属性
#示例标签a: {'href': '/', 'id': 'result_logo', 'onmousedown': "return c({'fm':'tab','tab':'logo'})"}
print(html.a.attrs)
print(html.a.get('id'))
获取多个标签,需要遍历文档树
print(html.head.contents)
# print(html.head.contents)是list_iterator object
for ch in html.head.children:
print(ch)
查找后代(desceants)标签
# descendants(后代)
print(html.head.descendants)print(html.select('.two')[0].get_text())根据标签名查找一组元素:find_all()
res = html.find_all('a')
print(res)查找一个元素:find()
find(name, attrs, recursive, text, **wargs) # recursive 递归的,循环的
这些参数相当于过滤器一样可以进行筛选处理。不同的参数过滤可以应用到以下情况:
- 查找标签,基于name参数
- 查找文本,基于text参数
- 基于正则表达式的查找
- 查找标签的属性,基于attrs参数
- 基于函数的查找
#可以传递任何标签的名字来查找到它第一次出现的地方。找到后,find函数返回一个BeautifulSoup的标签对象。 producer_entries = soup.find('ul') print(type(producer_entries)) 输出结果:
#直接字符串的话,查找的是标签。如果想要查找文本的话,则需要用到text参数。如下所示:
producer_string = soup.find(text = 'plants')
print(plants_string)select支持所有的CSS选择器语法:select()
res = html.select('.one')[0]
print(res.get_text())
print(res.get('class'))
res = html.select('.two')[0]
print(res)
print('----',res.next_sibling)
#next_sibling:下一个兄弟标签