Python3—scrapyd服务部署爬虫项目
Python3—scrapyd服务部署爬虫项目
注意:Python2.7和Python3的配置不同,注意区分!!
目录
Python3—scrapyd服务部署爬虫项目
一、需要安装scrapyd==2.0 scrapyd-client==2.0a1
二、启动scrapyd服务
三、配置爬虫项目(scrapy.cfg文件中配置)
四、开始向scrapyd中部署项目
4.1、新打开cmd窗口执行命令!
4.2、进入scrapy:workon scrapy的名字
4.3、进入需要部署的项目根目录:cd 根目录地址
4.4、通过scrapyd-deploy命令测试scrapyd-deploy是否可用。
4.5、查看当前可用于部署到scrapyd服务中的爬虫有哪些。
4.6、命令scrapy list用来查看当前项目中,可用的爬虫。
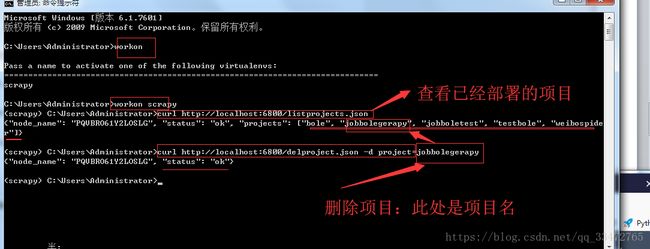
4.7、列举scrapyd服务中已经部署的爬虫项目:
4.8、上传项目(重点):
4.9、查询当前项目中的爬虫个数
4.10、启动爬虫
4.11、关闭(取消)爬虫
4.12、打包爬虫项目到scrapyd服务(打包后)——同4.8(文档多做了一步!!!)
4.13、注意浏览器中查看(scrapyd提供了一个查看界面!)
4.14、其他操作api(删除项目),查看官方文档
一、需要安装scrapyd==2.0 scrapyd-client==2.0a1
命令:pip install scrapyd==1.2.0 pip install scrapyd-client==1.2.0a1
注意:如何查询最新版本 ==后面输入一个没有的版本运行,会报错同时会提示不同的版本!!
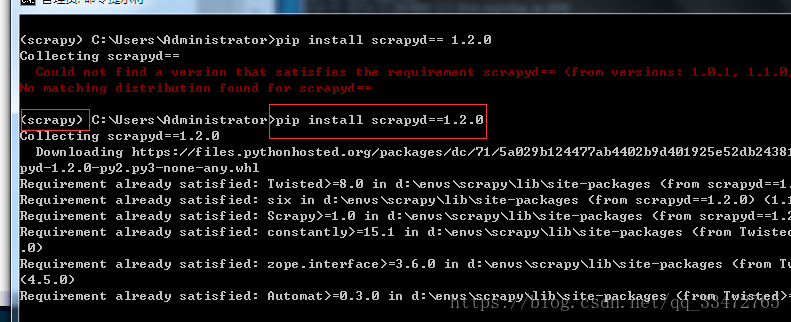
运行安装后,查看:
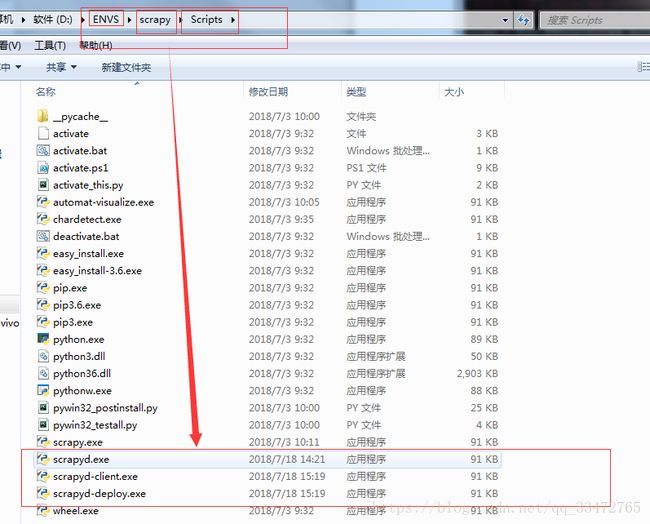
二、启动scrapyd服务
启动后不要关闭,要基于scrapyd服务来运行后面的部署和爬虫。(后面的命令新打开cmd窗口!!)

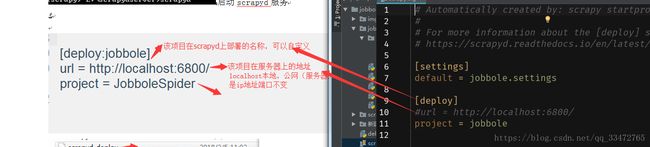
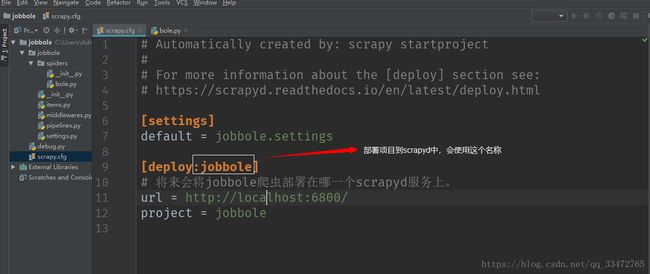
三、配置爬虫项目(scrapy.cfg文件中配置)
四、开始向scrapyd中部署项目
4.1、新打开cmd窗口执行命令!
4.2、进入scrapy:workon scrapy的名字
4.3、进入需要部署的项目根目录:cd 根目录地址
4.4、通过scrapyd-deploy命令测试scrapyd-deploy是否可用。
命令:scrapyd-deploy
![]()

4.5、查看当前可用于部署到scrapyd服务中的爬虫有哪些。
命令:scrapyd-deploy -l
参数1: [deploy: jobbole]
参数2: scrapy.cfg文中中的url



4.6、命令scrapy list用来查看当前项目中,可用的爬虫。
命令:scrapy list
![]()

可能会报错:

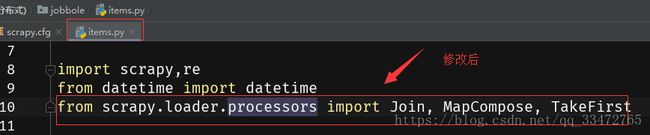
4.7、列举scrapyd服务中已经部署的爬虫项目:
命令:curl http://localhost:6800/listprojects.json
两种情况:没有项目 , 有项目


注意:cmd运行时可能会报错——curl不是内部文件..,解决方式网址:
https://www.cnblogs.com/zhuzhenwei918/p/6781314.html(依照操作下载解压缩到相应的位置如下图,配置就OK!)
![]()
4.8、上传项目(重点):
命令:scrapyd-deploy jobbole –p bole
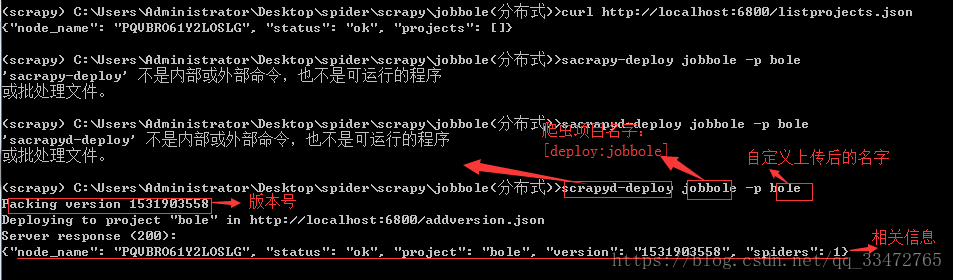
注意:区分两个名字;自定义上传后的名字是后面主要使用的!
status: 上传至scrapyd的状态
project: 上传的项目名称
version: 此次上传项目的版本号,因为项目可以多次打包上传,每次上传都会有不同的版本号
spiders: 该项目中包含的爬虫个数
4.9、查询当前项目中的爬虫个数
命令:curl http://localhost:6800/listspiders.json?project=bole

注意:结果中的名字是一个爬虫文件有多个爬虫项目name=’ ’中的名字!!
4.10、启动爬虫
命令:curl http://localhost:6800/schedule.json -d project=bole -d spider=bole


4.11、关闭(取消)爬虫
命令:curl http://localhost:6800/cancel.json -d project=bole -d job=53cf9f428a6911e88b11005056c00008


上述几步可能会有一个错误如下图(尝试下面的解决办法!!):
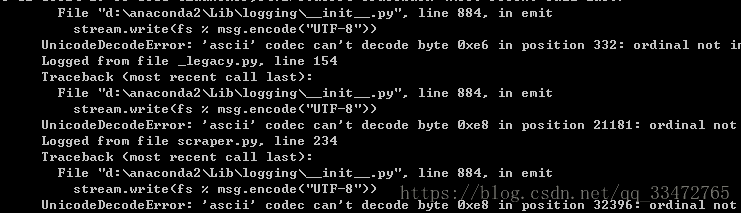
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
4.12、打包爬虫项目到scrapyd服务(打包后)——同4.8(文档多做了一步!!!)
命令:scrapyd-deploy jobbole -p testbole
注意:jobbole是[deploy:jobbole]
testbole是自定义的

4.13、注意浏览器中查看(scrapyd提供了一个查看界面!)
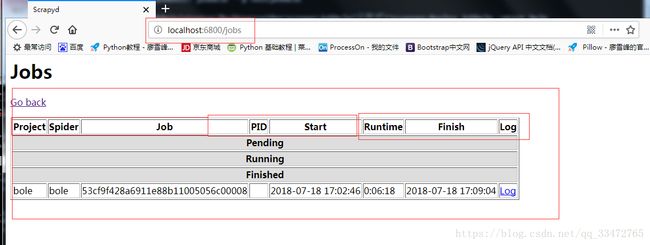
4.14、其他操作api(删除项目),查看官方文档
地址:https://scrapyd.readthedocs.io/en/latest/api.html#