node.js 教你写爬虫(附上gbk,gb2312中文乱码的解决方法)
好久没有更新博客了,现在前端web越来越火了,各种前端技术也层出不穷,不过有一些趋势是可以肯定的,前端现在越来越模块化,mvvm框架让前端用户只需要关注数据的变化,也让web端从webpage转为功能更为复杂的webapps了,后端技术也不单单是php,java的天下,node.js的出现让前端开发人员也能独立开发一个小网站.
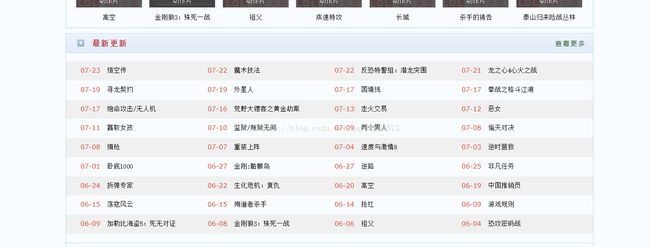
好了言归正传,今天我来教大家用node.js写爬虫,先说一下需求:昨天突然想看电影,于是逛了一下电影天堂,发现里面有不少新的电影的下载链接,如下图:
如上两张图所示,主页的链接里面进详情页,里面有迅雷的下载链接,于是我就想能不能将最新的电影的电影名,描述,还有下载链接一下从网站扒下来,
这样就可以每次想看电影的时候不要一个一个点。
好了,开始说技术。
什么是爬虫:
我觉得用最简单的话来说:就是把你手动打开窗口,输入数据等等操作用程序代替。用程序替你获取你想要的信息。
方法一
node.js里面有一个内置模块:http模块,可以发送get请求:
http.get(url, function(res){}) url就是你要访问的链接,我们可以通过http的这个模块可以帮你访问你想访问的网页,于是乎,要是能通过他获取到整个网页的源代码然后再经过一系列的操作不就能得到所要的到数据,ok话不多说,开干:
这个时候我们输出结果的结果就是网页的html代码,如下图var http=require('http'); http.get('http://www.loldytt.com/Dongzuodianying/WKC/',function(res){ var length=0; var arr=[]; res.on("data",function(chunk){ arr.push(chunk); length+=chunk.length; }); res.on("end",function(){ var data=Buffer.concat(arr,length); console.log(data.toString()); }) });
我们可以看到代码中为中文的字符为乱码,所以我们就需要进行转码,node.js内置模块是没有转码工具的,这个时候我们就要用第三方中间件iconv-lite(windows), iconv(ios)来进行转码,转码后代码如下图:
这个时候我们再跑一遍,var http=require('http'); var iconv = require('iconv-lite'); http.get('http://www.loldytt.com/Dongzuodianying/WKC/',function(res){ var length=0; var arr=[]; res.on("data",function(chunk){ arr.push(chunk); length+=chunk.length; }); res.on("end",function(){ var data=Buffer.concat(arr,length); var change_data = iconv.decode(data,'gb2312'); console.log(change_data .toString()); }) });
你会发现乱码的html代码正常了,这都归功于我们的一句代码var change_data = iconv.decode(data,'gb2312'); 这个时候可能你会奇怪我怎么知道这个页面的编码是gbk,还是gb2312还是utf-8,这个可以在代码的头部去观察,如下图
charset等于的就是该网页的编码,ok,这个时候我们终于获取了网页的全部内容,那么我们怎么才能获取到想要的数据呢,这个时候就不得不提一个第三方中间件:cheerio,它可以从一坨html的片断中构建DOM结构,然后提供像jquery一样的css选择器查询。请注意是能向jquery一样,这样通过jquery的选择器我们就能方便的获取我们想要的数据:代码如下:
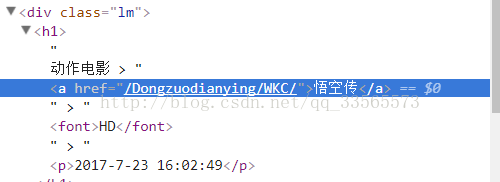
var $=cheerio.load(change_data.toString());是初始化插件,将string的代码串变成dom结构,我们通过F12可以得到网页电影名称是:var http=require('http'); var iconv = require('iconv-lite'); var cheerio = require('cheerio'); http.get('http://www.loldytt.com/Dongzuodianying/WKC/',function(res){ var length=0; var arr=[]; res.on("data",function(chunk){ arr.push(chunk); length+=chunk.length; }); res.on("end",function(){ var data=Buffer.concat(arr,length); var change_data = iconv.decode(data,'gb2312'); var $=cheerio.load(change_data.toString()); console.log($('.lm a').text()); }) });
所以通过$('.lm a').text()我们就获取到了网页的名字,是不是好简单又好神奇。
方法二:
但是说http模块有些缺陷,就是他不能读取https,通过ssl加密的网页,这个时候我们就可以同第三方中间件request模块
代码如下,ok就不多说了直接上代码:
var request=require('request'); var iconv = require('iconv-lite'); var cheerio = require('cheerio'); request.get({url:'http://www.loldytt.com/Dongzuodianying/WKC/',encoding:null},function(err,response,body){ var buf = iconv.decode(body, 'gb2312'); var $=cheerio.load(buf); console.log($('.lm a').text()); });
至此,简单爬虫就写完了,是不是好简单,最后再上我扒最新电影的代码,也就多加了几层调用,两种方法我都用了,代码如下图所示:var http = require("http"); var iconv = require('iconv-lite'); var cheerio = require('cheerio'); var Stream = require('stream'); var request=require('request'); var fs = require('fs'); var url = 'http://www.loldytt.com/Kehuandianying/'; var path=require('path'); var number=0; var init_number=5497114; var flag=0; //getData(url); request.get({url:url,encoding:null},function(err,response,body){ var buf = iconv.decode(body, 'gb2312'); var $=cheerio.load(buf); $('.new_nav a').each(function(index, el) { if(index!=0){ getData($(this).attr('href')); } }); }); function getData(url){ http.get(url, function(res){ var arrBuf = []; var bufLength = 0; res.on("data", function(chunk){ arrBuf.push(chunk); bufLength += chunk.length; // console.log(1); }) .on("end", function(){ var chunkAll = Buffer.concat(arrBuf, bufLength); var strJson = iconv.decode(chunkAll,'gb2312'); var $=cheerio.load(strJson); var arr=[]; $('.gengxin a').each(function(index, el) { if(index!=0) { request.get({url:$(this).attr('href'),encoding:null},function(err,response,body){ var buf = iconv.decode(body, 'gb2312'); var $=cheerio.load(buf); //request($('.vipicbg').attr('src')).pipe(fs.createWriteStream('./images/'+flag+''+index+'.jpg')); var movie_description='电影描述: '+$('.neirong p').text(); var movie_url='下载链接: '+$('#jishu #li1_0 a').attr('href'); var movie_name='电影名称: '+$('.lm a').text(); var total_movie='\n'+movie_name+'\n'+movie_description+'\n'+movie_url+'\n'; //var ws=fs.createWriteStream(path.join(__dirname,'./txt','first.txt')); var buff=new Buffer(total_movie); fs.appendFile(path.join(__dirname,'./txt','first.txt'),buff,function(){ console.log('写入完毕'); }); }); } }); flag++; }); }); }
再附最后通过爬虫得到的数据(部分):
ok,爬虫就介绍完了,接下来我打算写一张node.js建一个blog系统,涉及node.js mysql jade的一些实战介绍,希望喜欢的朋友可以关注我一下。