python爬虫——正方教务系统成绩查询
python爬虫——正方教务系统成绩查询
前阵子刚刚学完python基础,于是开始着手python爬虫学习
目标:利用python模拟登陆,进入学校正方教务系统,并获取成绩数据放回到自己的HTML页面。
首先,先进入学校教务网,可以看到登录所需基本信息有:用户名,密码,验证码,登录身份,登录
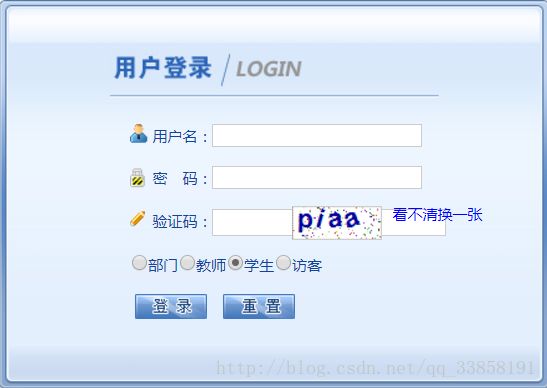
由于是初学者,且正方教务系统有一个网址http://218.94.104.201:85/default6.aspx可以免验证码登录,于是选择从此网址入手。
在Google浏览器中利用开发者工具(F12可直接打开),不仅可以查看HTML相关源代码,还可以抓到登录时从客户端发送的相关数据,利用这些数据就可以模拟登陆进入正方教务系统

有了登录相关信息以后我们就可以利用cookie实现模拟登陆。(Cookie,指某些网站为了辨别用户身份、进行session跟踪而储存在用户本地终端上的数据,通常经过加密。)登录之后,对页面进行解析,并提取相关数据代码如下:
#!/usr/bin/env python
#!coding:utf8
import cookielib
import urllib2
import urllib
from bs4 import BeautifulSoup
from urllib import quote
import json
import cgi,cgitb
import urllib2
class pysj:
def __init__(self):
#获取ajax传过来的值
form=cgi.FieldStorage()
xh=form.getvalue('user_name')
psw=form.getvalue('pwd')
print "Content-type: text/html"
print
#get Cookie
cookie = cookielib.CookieJar()##声明一个MozillaCookieJar的类对象保存cookie
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookie))#利用urllib2.HTTPCookieProcessor(cookie)来构造opener
user_agent = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36'
opener.addheaders.append( ('Host', 'yjsgl.fzu.edu.cn') )
opener.addheaders.append( ('User-Agent', user_agent) )
opener.addheaders.append( ('Accept', 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8') )
opener.addheaders.append( ('Accept-Language', 'zh-CN,zh;q=0.8') )
opener.addheaders.append( ('Accept-Encoding', 'gzip, deflate') )
opener.addheaders.append( ('Connection', 'keep-alive') )
opener.addheaders.append( ('Referer', 'http://218.94.104.201:85/default6.aspx') )
#logindata
postdata = urllib.urlencode({
'__VIEWSTATE':'dDwtMTQxNDAwNjgwODt0PDtsPGk8MD47PjtsPHQ8O2w8aTwyMT47aTwyMz47aTwyNT47aTwyNz47PjtsPHQ8cDxsPGlubmVyaHRtbDs+O2w8Oz4+Ozs+O3Q8cDxsPGlubmVyaHRtbDs+O2w8Oz4+Ozs+O3Q8cDxsPGlubmVyaHRtbDs+O2w8Oz4+Ozs+O3Q8cDxsPGlubmVyaHRtbDs+O2w8Oz4+Ozs+Oz4+Oz4+Oz59envE1UwQehRVvzVOfsZyW7fzvQ==',
'tnameXw':'yhdl',
'tbtnsXw':'yhdl|xwxsdl',
'txtYhm':xh,
'txtMm':psw,
'rblJs':'学生',
'btnDl':' 登录'
})
# Login
loginUrl="http://218.94.104.201:85/default6.aspx"
#下载器urllib2下载
myRequest = urllib2.Request(loginUrl, postdata)
loginPage = opener.open(myRequest).read()#opener返回的一个应答对象response
#解析器BeautifulSoup
soup=BeautifulSoup(loginPage,'html.parser',from_encoding='utf-8')
#获取信息并进行转码
name=soup.find('span', id='xhxm').get_text()
name=name[:-2]
if not isinstance(name,unicode): #检查编码是否为unicode
obj = unicode(name,'utf-8')
name=''.join(obj).encode('utf-8')
else:
name=''.join(name).encode('utf-8')
name=quote(name,'utf-8')
#跳转到成绩查询页面
loginUrl2="http://218.94.104.201:85/xscj.aspx?xh="+xh+"&xm="+name+"&gnmkdm=N121605"
myRequest1=urllib2.Request(loginUrl2)
loginPage1 = opener.open(myRequest1).read()
soup=BeautifulSoup(loginPage1,'html.parser',from_encoding='utf-8')
#获取成绩查询所需信息并进行查询
viewstate=soup.find('input')['value']
data = urllib.urlencode({
"__VIEWSTATE":viewstate,
'ddlXN':'',
'ddlXQ':'',
'txtQSCJ':'0',
'txtZZCJ':'100',
'Button2':'在校学习成绩查询'
})
myRequest2=urllib2.Request(loginUrl2,data)
loginPage2= opener.open(myRequest2).read()
soup=BeautifulSoup(loginPage2,'html.parser',from_encoding='utf-8')
#获取成绩数据
cj=soup.find('table',id="Table1")
print cj
cjb=soup.find('table',id="DataGrid1")
print cjb
pysj()这里再编写一个HTML页面,利用ajax来传递登录用户和密码,并将爬取的数据返回,展示再HTML页面上,ajax代码如下
<script>
function saveUserInfo()
{
//获取接受返回信息层
var msg = document.getElementById("msg");
//接收表单的URL地址
var url = "/cgi-bin/sjlogin.py";
//需要POST的值,把每个变量都通过&来联接
var postStr = "user_name="+ document.getElementById("username").value +"&pwd="+ document.getElementById("pwd").value;
//实例化Ajax
//var ajax = InitAjax();
var ajax = new XMLHttpRequest();
//通过Post方式打开连接
ajax.open("POST", url, true);
//定义传输的文件HTTP头信息
ajax.setRequestHeader("Content-Type","application/x-www-form-urlencoded");
//发送POST数据
ajax.send(postStr);
//获取执行状态
ajax.onreadystatechange = function()
{
//如果执行状态成功,那么就把返回信息写到指定的层里
if (ajax.readyState == 4 && ajax.status == 200)
{
document.getElementById("container").style.visibility="hidden"
msg.innerHTML = ajax.responseText;
//msg.innerHTML = ajax.return;
}
}
}
script>要在python之间传递数据还要开启一个服务端口(到文件所在目录 python文件名即可开启服务)代码如下:
#!/usr/bin/env python
#!coding:utf8
from BaseHTTPServer import HTTPServer
from CGIHTTPServer import CGIHTTPRequestHandler
class server:
def __init__(self):
port=8088
httpd=HTTPServer(('',port),CGIHTTPRequestHandler)
print("开启服务,端口号为:"+str(httpd.server_port))
httpd.serve_forever()
server()至此,python爬虫脚本和前端页面就完成了,开启服务,在浏览器里输入url,登录后即可查询成绩
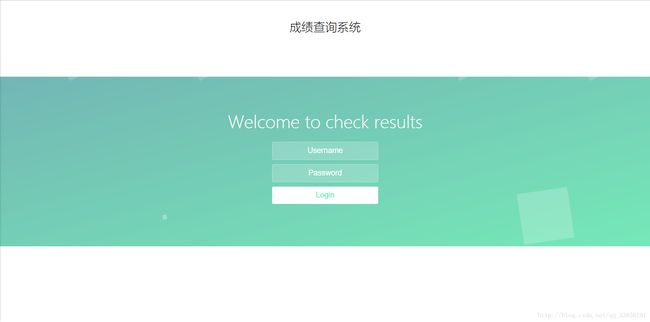
注意:
- 爬虫下载器获取页面代码之后需要对编码进行转码
- 如果上传服务器需要给文件赋予权限
第一次写,不足之处,多多见谅