Python爬虫实战之爬取电影网站全部视频(四)
前几天在群里看到一个朋友说想抓取一个影视网站 把所有的资源弄下来 自己开一个玩玩 但是没有抓到关键数据 然后把网址发了出来 我上去分析了一番 然后使用python写了一个多线程的 但是因为视频文件太多 没有全部都下载下来
| https://91mjw.com/ 爬取网址 |
前面的文章中有介绍这个开发者工具怎么使用 这里就不多啰嗦了 直接开始正题,如果不清楚这个开发者工具怎么使用的请看第一篇和第二篇都有介绍
首先第一步 获得整站所有的视频连接

这里我们选择了第一个图片 可以看到他的结构组成
在这个article中 就是当前第一个电影的一些信息

展开之后 可以看到 第一个a 中是href 下面的h2中是标题 这样这个电影的两个重要的信息我们就获得到了。接下来就是获取当前页面中所有的href和h2
![]()
这里显示一共是63个 但是我们在主页上数了一下 一共是9排 每排6个 也就是只有54个 但是为什么会出来63个呢
那我们把第62个打开看一下
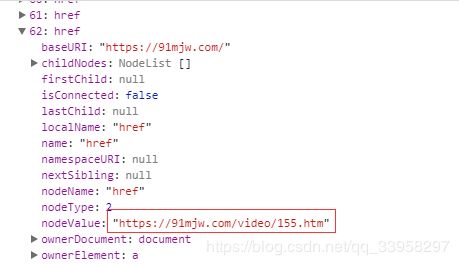
可以看到这个地址 然后去主页搜一下 这个地址
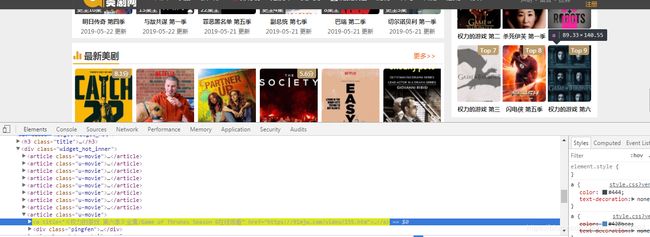
发现在右边有个箭头
原来他是把右边的9个都算上了
那这样就搞明白了 一共63个是没错的
这里整理一下:
url: //article[@class='u-movie']/a/@href
title : //article[@class='u-movie']/a/h2/text()
第二步 是进入选择的电影的页面 去获得视频的链接
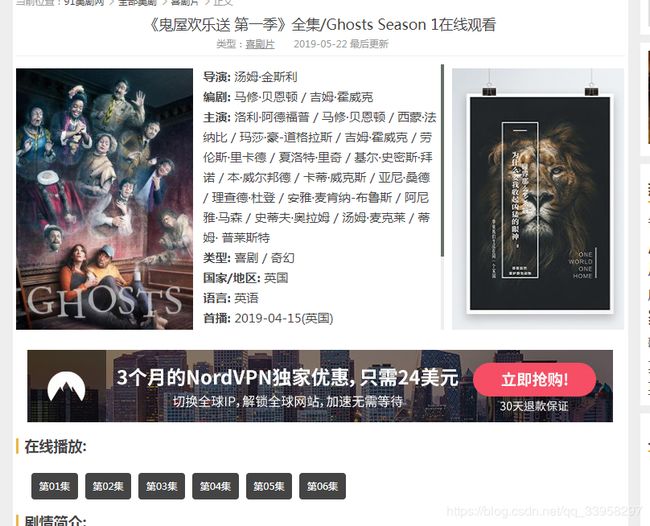
这里我们进入了第一个视频 可以看到下面有集数 那么如果要爬取他所有的集数的话也很容易的
只需要把他的所有的集数连接都获取到就可以全部爬取

这里可以看到他一共是6级 全部都是通过play这个js函数来实现的跳转
那么我们进入play这个函数里看一下 他是如何操作的
我们发现 这个play函数就在下面 而且操作也比较简单 就是很简单的网址组装
如果决定不了这个网址 或者怕组装错误 也没事 可以直接点击第一集进去 看他的地址就知道了
![]()
当我们点击第一集进入后发现 他只是在主页的地址后面加上/vplay/ MTM4MC0xLTA=.html
正好也就是那个函数中组装上的地址
那这样就简单了 我们只要获取他所有的id就自己去构造一下这个请求参数就可以了
所有的集数的地址都在这里了
![]()
整理一下:
url: //div[@class='vlink']/a/@id
第三步 下载视频
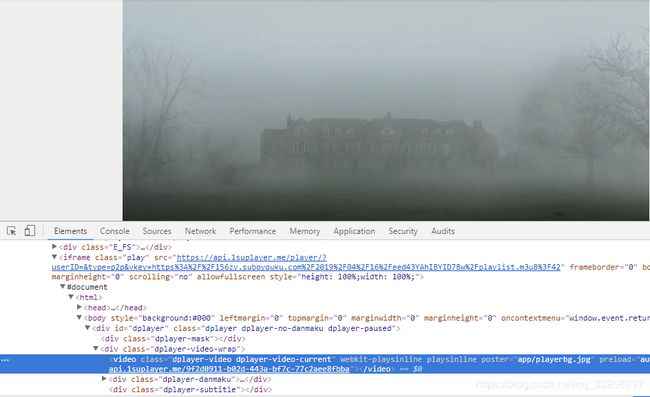
当我们在左边那个小箭头点击之后 会定位到这里
这里的video可以得知是一个播放器标签
这里标签 必须有一个src 也就是播放地址
在这张图上可以看到 在上方iframe 中有一个src
但是这个src在源码中却看不到 可以自己右键查看源文件 来搜索这一段就知道了
而且有过网页开发经验的人都知道 如果在标签中有src那么浏览器就会去访问src中的地址,所以我们转到network中可以查看到他访问的这个地址 看他返回什么 再继续操作

我们可以看到 这里就是那个src中访问的地址 我们点击这个地址进去 点击preview 向下翻可以看到如下图:
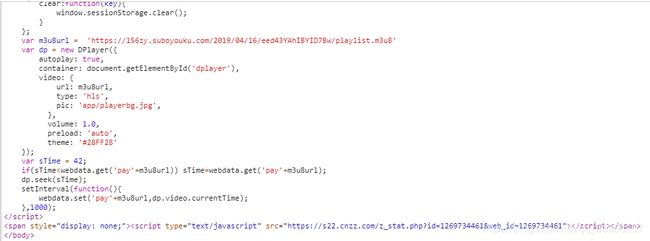
这里 我们明确的可以看到这里有一个new Dplayer 这个dplayer是一个视频播放器库
在百度上可以查到相关的使用方法 ,这个Dplayer中的video中url就是播放的地址。
这里的url可以明确看到 其实就是iframe中src的后半截地址
可能有的人说 这个地址好像不太一样 其实是一样的 只是src中的地址进行了url编码 所以才感觉不一样 只要url解码后 就完全一样了
这里给出解码后的地址:
https://api.1suplayer.me/player/?userID=&type=p2p&vkey=https://156zy.suboyouku.com/2019/04/16/eed43YAhIBYID7Bw/playlist.m3u8?42
这里可以看到 视频播放的地址就是这个vkey=后面的值
其实这里的操作的目的 主要就是为了播放这个视频而已 而且我们看这个地址的后缀是m3u8 说明这个视频使用的以ts后缀的播放格式 也是现在最流行的播放格式
那么到这里 我们就分析完了 这个下载地址
第四步 下载视频 保存到本地
上面我们已经分析完了这个下载地址 但是不知道这个里面是啥
我们用浏览器去访问以下 看看出来的是啥
当我们输入https://156zy.suboyouku.com/2019/04/16/eed43YAhIBYID7Bw/playlist.m3u8 这个地址后 会出来一个下载地址 下载了一个文件
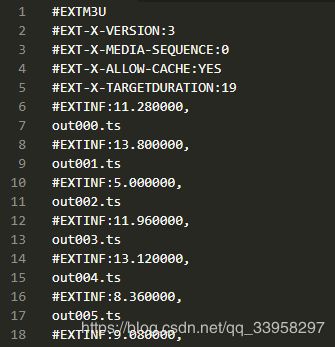
可以看到 这文件里 好像有很多文件名一样的东西
我为什么这样说呢 我们回到network中 其实可以看到里面的前几个文件 如果没有暂停播放的话 应该可以看到更多

这样就说明了 我们的路线没有错误 浏览器也是去下载这个文件
那么我们也是去下载这个视频文件
只不过这个网站他做了一件事 就是他把这个下载的视频返回到了视频播放器里 实现了播放 而我们是要下载 那我们直接下载那个m3u8的文件 然后自己去构造这个下载参数就可以了
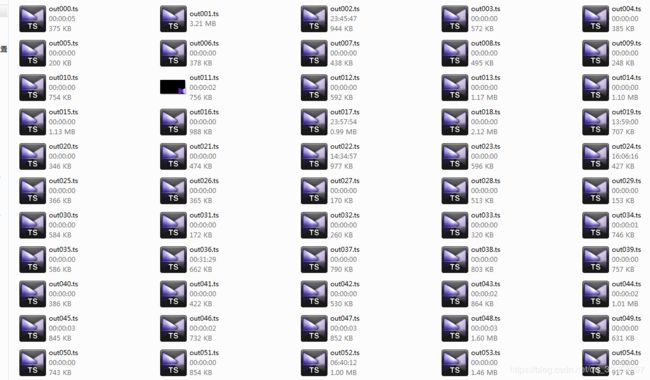
下载完成之后 自己找个ts合成工具合成一下就可以了
第五步 编写代码
用到的第三方模块有 没有的朋友请自己下载一下
1 . requests
2. BeautifulSoup
3. lxml
思路:我一般采用多线程下载,但是因为他这个是m3u8格式的电影,所以他的视频非常小 但是又非常多,多线程来下载同一级的不同位置的ts 所以前面的思路是 先获取当前主页的url然后进入第一个url地址里去下载第一集,第一集开启多线程全部下载完成之后再进入第二集 如此循环即可全部下载完成
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import re,os
import requests
from threading import *
from lxml import etree
import StringIO
import urllib
nMaxThread = 8
connectlock = BoundedSemaphore(nMaxThread)
gHeads = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36"}
def DownloadVideo(savePath,videoUrl):
try:
html = requests.get(videoUrl,headers=gHeads)
if html.status_code == 200:
videoName = videoUrl[videoUrl.rfind("/") +1:]
print("%s download done!"%videoName)
with open(savePath + videoName,"wb") as f:
f.write(html.content)
finally:
connectlock.release()
def GetSeason(url):
html = requests.get(url,headers=gHeads)
if html.status_code == 200:
xmlcontent = etree.HTML(html.text)
subUrlList = xmlcontent.xpath("//div[@class='vlink']/a/@id")
return subUrlList
return []
def GetM3u8(CurSeasonStr):
url = "https://91mjw.com/vplay/" + CurSeasonStr + ".html"
html = requests.get(url,headers=gHeads)
if html.status_code == 200:
html.encoding = "utf-8"
reContent = re.search('vid="(.*?)"',html.text)
return reContent.group(1)
return ""
def ParseM3u8(url):
url = urllib.unquote(url)
urlPrefix = url[:url.rfind("/") + 1]
html = requests.get(url,headers=gHeads)
if html.status_code == 200:
TempBuf = StringIO.StringIO(html.text)
VideoList = [ urlPrefix + i.strip() for i in TempBuf.readlines() if i[0] != "#"]
return VideoList
return []
def GetMainUrlAndNameList():
try:
html = requests.get("https://91mjw.com",headers=gHeads)
if html.status_code == 200:
html.encoding = "utf-8"
xmlcontent = etree.HTML(html.text)
UrlList = xmlcontent.xpath("//article[@class='u-movie']/a/@href")
NameList = xmlcontent.xpath("//article[@class='u-movie']/a/h2/text()")
return UrlList,NameList
except:
return None,None
def main():
UrlList,NameList = GetMainUrlAndNameList()
for i in range(len(UrlList)):
subUrlList = GetSeason(UrlList[i])
for j in range(len(subUrlList)):
VideoUrl = GetM3u8(subUrlList[j])
if VideoUrl:
savePath = "./movie/%s/%d/"%(NameList[i],j + 1)
if not os.path.exists(savePath):
os.makedirs(savePath)
VideoList = ParseM3u8(VideoUrl)
for k in VideoList:
connectlock.acquire()
t = Thread(target=DownloadVideo,args=(savePath,k))
t.start()
if __name__ == '__main__':
main()放个结果: 我没有爬很长时间就爬了一点点 截个图意思一下