编译原理——词法分析程序
前言:这是我学习编译原理,课程实验的内容,课程早已结束,现整理发表。
一、实验任务
- 阅读已有编译器的经典词法分析源程序;
- 用C或JAVA语言编写一门语言的词法分析器。
二、实验内容
-
阅读已有编译器的经典词法分析源程序。
选择一个编译器,如:TINY或PL/0,其它编译器也可(需自备源代码)。阅读词法分析源程序,理解词法分析程序的构造方法——状态图代码化。尤其要求对相关函数与重要变量的作用与功能进行稍微详细的描述。若能加上学习心得则更好。 -
根据该语言的关键词和识别的词法单元以及注释等,确定关键字表,画出所有词法单元和注释对应的DFA图。
-
仿照前面学习的词法分析器,编写选定语言的词法分析器。
-
准备2~3个测试用例,要求包含正例和反例,测试编译结果。
三、词法分析
tiny词法解析
- tiny的记号
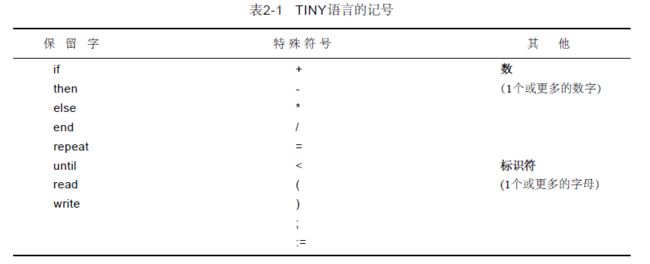
可以看出,tiny语言的记号很少,毕竟只是简单的语言。但一开始时想——这些怎么存的,又是怎么判断的,我一开始也是很懵逼的,记得我当时也是花了一下午看了tiny的词法分析源码和实验给的文档,才弄懂该怎么写,然后回到宿舍一晚上就在tiny的基础上改写完了。<( ̄︶ ̄)>
简单的说,记号就是一个语言的分类,当你读取字符串的时候,你总得识别出这一段字符串是什么,是什么类型的,所以你按某个规则读完玩一段字符,你就该判断这段字符是什么,是否有错,怎么归类,而记号就是你用来归类的标准。
- 状态转换
然后既然有了类型,那怎么判断类型呢?用DFA转换图。
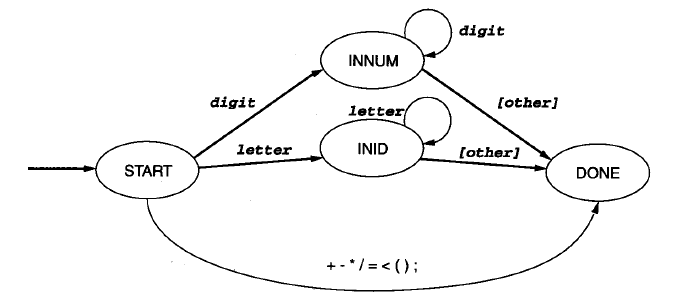
这个转换如很简单,START 开始状态,INNUM 数字,INID 字符串,+-*/=<(); 特殊符号,DONE 状态,从开始状态根据又一次 读取第一个字符,根据读取的字符转换状态,进入某个状态后,当读取的下一个字符不符合当前状态的类型,就不读取字符,而读取完的这段字符串,当是某个类型。判断完这段字符串,又一次 重复操作,直到读取所有字符。
把需要判断的状态都加上时,就成了tiny的词法分析转换图。
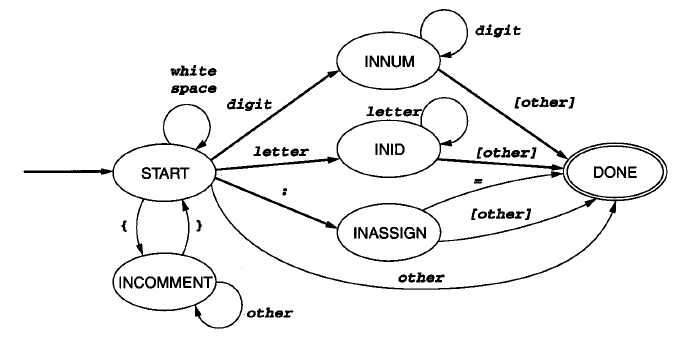
四、程序设计
我写的词法分析其实就是在tiny基础上稍加修改而已,词法设计这部分大致相同。
记号
保留字:
cin while then cout end
特殊字符:
= + - * / ( ) ; >> <<
注释:
{这是注释}
转换表
参照上面
代码解析
- 宏定义最大匹配字符变量的长度为40
保留字为5个
#define MAXTOKENLEN 40
#define MAXRESERVED 5
- 定义一个枚举类型,用于表示dfa的状态集
typedef enum { //DFA状态集
START,
INCOMMENT,
INNUM,
INID,
ININ,
INOUT,
DONE
} stateType;
- 定义个枚举类型,表示根据输入的字符串匹配到的字符串类型。
typedef enum { //用于匹配的类型,判断输入
/* 异常状态 */
ENDFILE,
ERROR,
/* 保留字 */
CIN,
COUT,
WHILE,
THEN,
END,
/* DFA状态 */
ID,
NUM,
/* 特殊符号 */
IN,
OUT,
EQ,
PLUS,
MINUS,
TIMES,
OVER,
LPAREN,
RPAREN,
SEMI
} tokenType;
- 定义一个结构体,用于根据匹配到的保留字输出保留字。
static struct //保留字结构体,用于输出
{
const char *str;
tokenType tok;
} reservedWords[MAXRESERVED] = {
{"cin", CIN},
{"while", WHILE},
{"then", THEN},
{"cout", COUT},
{"end", END}};
- 定义一个返回值为bool类型的函数,判断输入字符是否为字母。
bool isLetter(char c) //是否为字符
{
if ((c >= 'a' && c <= 'z') || (c >= 'A' && c <= 'Z'))
{
return true;
}
else
{
return false;
}
}
- 判断匹配的字符串是否为保留字。
static tokenType reservedLookup(char *s)
{
for (int i = 0; i < MAXRESERVED; i++)
if (!strcmp(s, reservedWords[i].str))
return reservedWords[i].tok;
return ID;
}
- 根据匹配到的字符类型输出字符串。
void printToken(tokenType token, const char tokenString[]); //输出函数
- 匹配字符串的函数。
void getToken(string ss); // 词法分析
五、实验测试
- 输入
{sdfs
adf}
cin >>{sdfsadf} x;
{sdfsadf}
cin>>y;
while (cin>>z) then{sdfsadf}
x=x z y;
cout << x;
end;
- 输出
1:{sdfs
2:adf}
3:cin >>{sdfsadf} x;
3: reserved word:cin
3: >>
3: ID, name= x
3: ;
4:{sdfsadf}
5:cin>>y;
5: reserved word:cin
5: >>
5: ID, name= y
5: ;
6:while (cin>>z) then{sdfsadf}
6: reserved word:while
6: (
6: reserved word:cin
6: >>
6: ID, name= z
6: )
6: reserved word:then
7:x=x z y;
7: ID, name= x
7: =
7: ID, name= x
7: ID, name= z
7: ID, name= y
7: ;
8:cout << x;
8: reserved word:cout
8: <<
8: ID, name= x
8: ;
9:end;
9: reserved word:end
9: ;
六、实验总结
实际上刚写这篇博客的时候我有点虚,因为不怎么记得tiny的语法分析怎么回事了,只能硬着头皮有看了下实验文档,然后才慢慢回想起来。然后就是你们看到的博客了。
当时我确实是花了下午2,3个小时看这实验的文档的,看实验文档,看tiny源代码,慢慢理解究竟是怎样的,然后规划自己要改成什么样的,实验内容那部分我删改了些,有部分内容要求是我们确定了我们的语言后,就鼓励我们自己定义一门语言,我当时就是想写们专门计算数学的语言,也就才有了这样的输入。
然后事实上,并不好写,尤其是要写整个前端的情况下,越发的力不从心,我后面的实验深刻理解到了这一点,然后没有坚持写出自己的语言,事实上也没有一个同学写出自己的语言的整个前端,不是tiny就是pl改的。
还有,我也是在这里入了枚举和结构体的坑,然后有次实验代码疯狂用了结构体,搞得结构很复杂,总之,如果你们还看我后面实验的的代码,你就知道什么叫做丧心病狂了。。。
七、资料下载
具体代码见mathLex