Mysql索引结构的实现
什么是索引
索引(Index)是帮助数据库高效获取数据的数据结构。索引是在基于数据库表创建的,它包含一个表中某些列的值以及记录对应的地址,并且把这些值存储在一个数据结构中。最常见的就是使用哈希表、B+树作为索引。
Mysql索引的数据结构:B+Tree
一般来说,索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储在磁盘上。这样的话,索引查找过程中就要产生磁盘I/O的消耗,所以评价一个索引的优劣的重要指标就是I/O的操作次数。
由于存储介质的特性,磁盘本身存取就比主存慢很多,再加上机械运动耗费,磁盘的存取速度往往是主存的几百分分之一,因此为了提高效率,要尽量减少磁盘I/O。为了达到这个目的,磁盘往往不是严格按需读取,而是每次都会预读,即使只需要一个字节,磁盘也会从这个位置开始,顺序向后读取一定长度的数据放入内存。这样做的理论依据是计算机科学中著名的局部性原理:当一个数据被用到时,其附近的数据也通常会马上被使用。
程序运行期间所需要的数据通常比较集中。
由于磁盘顺序读取的效率很高(不需要寻道时间,只需很少的旋转时间),因此对于具有局部性的程序来说,预读可以提高I/O效率。
预读的长度一般为页(page)的整倍数。页是计算机管理存储器的逻辑块,硬件及操作系统往往将主存和磁盘存储区分割为连续的大小相等的块,每个存储块称为一页(在许多操作系统中,页的大小通常为4k),主存和磁盘以页为单位交换数据。当程序要读取的数据不在主存中时,会触发一个缺页异常,此时系统会向磁盘发出读盘信号,磁盘会找到数据的起始位置并向后连续读取一页或几页载入内存中,然后异常返回,程序继续运行。
数据库系统巧妙利用了磁盘预读原理,将一个节点的大小设为等于一个页,这样每个节点只需要一次I/O就可以完全载入。在实现B- Tree为了达到这个目的,实际中还需要使用如下技巧:
每次新建节点时,直接申请一个页的空间,这样就保证一个节点物理上也存储在一个页里,加之计算机存储分配都是按页对齐的,就实现了一个node只需一次I/O。
B-Tree中一次检索最多需要h-1次I/O(根节点常驻内存),渐进复杂度为O(h)=O(logmN)。一般实际应用中,m是非常大的数字,通常超过100,因此h非常小(通常不超过3)。Mysql索引的数据结构之所以选择B+树而不是B树,是因为它内节点不存储data,这样一个节点就可以存储更多的key。
Mysql两个存储引擎MyISAM和InnoDB的索引区别:
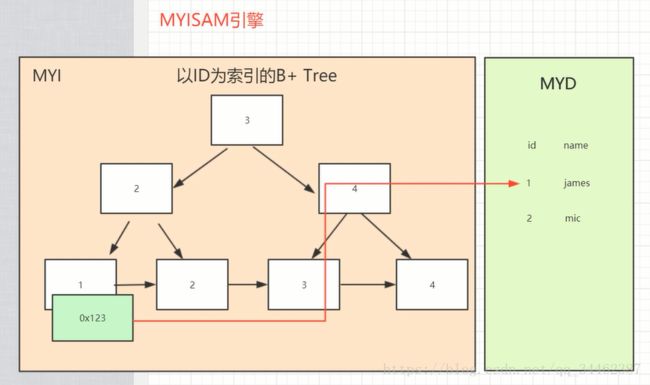

一是主索引的区别,InnoDB的数据文件本身就是索引文件。而MyISAM的索引和数据是分开的。
二是辅助索引的区别:InnoDB的辅助索引data域存储相应记录主键的值而不是地址。而MyISAM的辅助索引和主索引没有多大区别。
MySQL中MyISAM与InnoDB区别及选择
| InnoDB | MyISAM |
| 支持事务处理 | 不支持事务,回滚将造成不完全回滚,不具有原子性 |
| 支持外键 | 不支持外键 |
| 支持行锁 | 支持全文搜索 |
| 不保存表的具体行数,扫描表来计算有多少行 | 保存表的具体行数,不带where时,直接返回保存的行数 |
| DELETE 表时,是一行一行的删除 | DELETE 表时,先drop表,然后重建表 |
| InnoDB中必须包含AUTO_INCREMENT类型字段的索引 | MyISAM中可以使AUTO_INCREMENT类型字段建立联合索引 |
| 表格很难被压缩 | 表格可以被压缩 |
| 跨平台可直接拷贝使用 | 跨平台不可直接拷贝使用 |
总结:
在大数据量,高并发量的互联网业务场景下,对于MyISAM和InnoDB
-
有where条件,count(*)两个存储引擎性能差不多
-
不要使用全文索引,应当使用《索引外置》的设计方案
-
事务影响性能,强一致性要求才使用事务
-
不用外键,由应用程序来保证完整性
-
不命中索引,InnoDB也不能用行锁
InnoDB是非常适合互联网业务的存储引擎,其多版本并发控制(Multi Version Concurrency Control, MVCC),快照读(Snapshot Read)机制,能够通过读取回滚段(rollback segment)中数据的历史版本,在事务读取记录的时候不用加锁,以支持超高的并发。MyISAM相对简单所以在效率上要优于InnoDB。如果系统读多,写少,对原子性要求低的情况下,MyISAM是最好的选择。且MyISAM恢复速度快。可直接用备份覆盖恢复。如果系统读少,写多的时候,尤其是并发写入高的时候,InnoDB就是首选了。
两种类型都有自己优缺点,选择那个完全要看自己的实际选择。
InnoDB 四种事务隔离级别
InnoDB默认是可重复读的(REPEATABLE READ)
修改全局默认的事务级别,在my.inf文件的[mysqld]节里类似如下设置该选项(不推荐)
transaction-isolation = {READ-UNCOMMITTED | READ-COMMITTED | REPEATABLE-READ | SERIALIZABLE}四种隔离级别说明
| 隔离级别 | 脏读(Dirty Read) | 不可重复读(NonRepeatable Read) | 幻读(Phantom Read) |
|---|---|---|---|
| 未提交读(Read uncommitted) | 可能 | 可能 | 可能 |
| 已提交读(Read committed) | 不可能 | 可能 | 可能 |
| 可重复读(Repeatable read) | 不可能 | 不可能 | 可能 |
| 可串行化(SERIALIZABLE) | 不可能 | 不可能 | 不可能 |
脏读 :一个事务读取到另一事务未提交的更新数据
不可重复读 : 在同一事务中,多次读取同一数据返回的结果有所不同
幻读 :一个事务读到另一个事务已提交的insert数据
1.脏读
A事务读取B事务尚未提交的更改数据,并在这个数据的基础上进行操作,这时候如果事务B回滚,那么A事务读到的数据是不被承认的。例如常见的取款事务和转账事务: 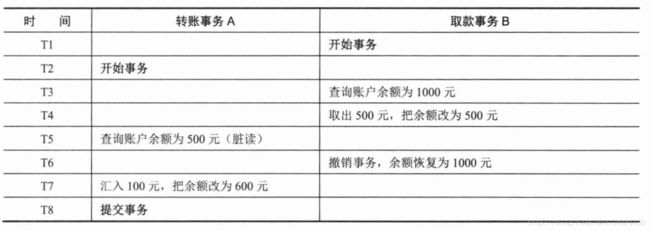
2.不可重复读
不可重复读是指A事务读取了B事务已经提交的更改数据。假如A在取款事务的过程中,B往该账户转账100,A两次读取的余额发生不一致。
3.幻读
A事务读取B事务提交的新增数据,会引发幻读问题。幻读一般发生在计算统计数据的事务中,例如银行系统在同一个事务中两次统计存款账户的总金额,在两次统计中,刚好新增了一个存款账户,存入了100,这时候两次统计的总金额不一致。 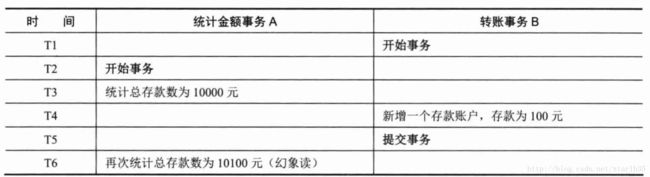
注意:不可重复读和幻读的区别是:前者是指读到了已经提交的事务的更改数据(修改或删除),后者是指读到了其他已经提交事务的新增数据。对于这两种问题解决采用不同的办法,防止读到更改数据,只需对操作的数据添加行级锁,防止操作中的数据发生变化;二防止读到新增数据,往往需要添加表级锁,将整张表锁定,防止新增数据(oracle采用多版本数据的方式实现)。