开源数据库CockroachDB(三)
上一篇:开源数据库CockroachDB(二)
转载自:CockroachDB中国社区
二十一、SQL
集群的每个节点均可接受SQL连接。CockroachDB支持PostgreSQL协议,用户可以复用PostgreSQL客户端driver。同时,支持两种连接方式:一种是使用SSL加密连接,通过证书认证客户端,建议在非加密(不安全)环境下使用;另一种是基于密码验证的连接。
每个连接关联一个SQL Session,该Session维护了服务器端状态。与其他SQL数据库一样,在Session的整个生命周期,客户端可以通过SQL语句设置是否开启显性事务、查询或者设置Session参数。
二十二、语法支持
CockroachDB支持许多PostgreSQL协议的SQL语法,但仍有很多区别:
- CockroachDB基于MVCC实现了事务的一致性,因此只支持SNAPSHOT和SERIALIZABLE两种隔离级别。其他传统的SQL隔离级别均被内部映射到SNAPSHOT或SERIALIZABLE。
- CockroachDB实现了自己的SQL类型体系,与PostgreSQL相比,它仅支持了有限的隐式类型转换。基本原则是保持实现简单和高效,通过观察得出结论:
- 客户端中大多数SQL代码都是自动生成的且数据类型明确;
- 异构数据库的SQL代码迁移到CockroachDB,则需修改调整。
二十三、SQL架构
每个节点上均有一个pgwire服务端进程(goroutine)处理客户端连接,接收传入的命令和返回响应结果如查询和语句结果。该pgwire进程还管理pgwire层面的预处理语句,绑定预处理参数并执行。
同时,SQL连接状态由一个Session对象和一个Planner对象(每个连接对应一个Planner对象)维护,Planner对象协调Session,当前SQL事务状态和底层KV存储的执行。
当接收到查询或语句(直接或者间接通过预处理语句生成的执行命令)时,pgwire进程将SQL文本发送到与连接相关联的Planner对象。然后,SQL代码被转化成SQL查询计划树,树中每个节点对应一种数据操作,例如:join,index join,scan,group等
目前,查询计划嵌入了执行时的run-time状态。SQL查询计划生成后,每个节点对象以“Generator”的方式,执行操作:每个节点Start其子节点,每个子节点像Generator一样把结果集返回给父节点,父节点处理后再返回到其上一级节点。
Planner把查询计划最顶层节点生成的数据,通过pgwire返回给客户端。
二十四、SQL模型和KV之间的数据映射
在CockroachDB中,每张表均有一个主键(如果建表时没有指定主键,则会自动生成隐式主键)。在底层KV存储中,每行数据的Key前缀由表标识符和该行数据的主键组成。
在底层KV存储中,表中非主键列或Column Family则被编码为Value,列标识符或Column Family标识符则作为后缀被追加到Key中。
例子:
- 在mydb数据库中创建一个表customers,表中包含主键字段name和普通字段address和URL。在KV存储中的schema如下:

(表格的右侧数值和左侧简化后的Schema Key结构仅为举例说明)每个数据库、表和字段名均被映射成一个自动生成的标识符,以便重命名。
下面是表格中的一行数据:

每一个Key均由表前缀“/51/42”、主键前缀“/Apple”、列或Column Family前缀(“/66,/69”)组成。Value则从SQL语句获取并编码而成。Key的高效存储由底层RocksDB引擎通过前缀压缩的方式来保障。
最后,对于SQL索引,则由索引列组成KV的Key,而Value值则保存被索引行的Key前缀。
二十五、Distributed SQL
Dist-SQL是在2016年第三季度开发的一个新的执行框架,其目的是分布式地处理SQL查询。更多细节可以参考《Distributed SQL RFC》;本章节只做概要性的描述。
选择分布式处理有以下几个原因:
- 远端过滤:当需要查询特定条件的数据时,相比于将某些Range中查询到的所有的Key返回网关节点集中过滤数据,我们更希望的是在远程节点或者租约持有节点上做相应的数据过滤,节省网络和相关处理的开销
- 对于类似UPDATE…WHERE和DELETE…WHERE这种语句,我们希望直接在持有相应数据的节点上处理。(而不是通过网络在网关节点接收结果,然后再执行UPDATE或DELETE,产生额外的开销)
- 并行SQL计算:当需要大量的计算时,我们希望将其分布到多个节点,它能够根据所涉及的数据量大小进行弹性扩展。这适用于JOIN、聚合和排序等操作。
Dist-SQL实现方式最初主要受Sawzaul项目启发(在谷歌,Rob Pike et al. 提出了用“shell”(高级语言解释器)来简化MapReduce的使用)。它清楚地区分本地处理(处理限量数据)和分布式计算(从概念结构的有限集合中抽象出来)。
为了更好地理解SQL语句的分布式执行过程,我们引入了几个概念:
- 逻辑计划 – 与SQL章节中提到的planNode tree描述类似,代表了数据流在计算阶段的抽象(非分布式计算)。
- 物理计划 – 从概念上说,就是将逻辑计划树的执行节点映射到CockroachDB运行节点。根据集群拓扑结构,逻辑计划节点被复制和特例化。物理计划的各执行节点被调度到整个集群中执行。
二十六、逻辑计划
逻辑计划是由一组Aggregator组成的。每个Aggregator接受一个行输入流(或者JOIN的多个输入流),然后生成一个行输出流。输入和输出流都有确定的模式。流是一个逻辑概念,不一定映射到实际计算中的单个数据流。当逻辑计划被转换为物理计划时,Aggregator可能被分布式化;为了标识Aggregator可被分布式并行处理,可在Aggregator上定义一个Grouping操作,对把流经它的数据进行分组,从而区分出哪些数据行需要在相同节点做处理(此机制保证满足一定条件的数据行只在同一个节点上处理)。此概念对需要从部分数据集中输出结果的Aggregator来说很有用,比如SQL聚合函数。不需要Grouping的Aggregator比较特殊,虽然不需要聚合多个数据片,但可能会过滤、转换或重新排序个别数据片。
没有输入的Table Reader Aggregator被用作数据源;Table Reader可被设置成只输出某些需要的列。一个没有输出的Final Aggregator被用于缓存查询/语句的执行结果。
为了保证查询结果的有序性,一些Aggregator(final,limit)要求输入流(具有相应升降序要求的字段列表)也必须有序。一些Aggregator(如Table Reader)可以保证输出流的有序性,称为保序性。所有聚合器都有一个关联的顺序特征函数ord(input_order) -> output_order,它将input_order(输入流的顺序)映射到output_order(输出流的顺序),也就是说,如果输入流中的行是根据input_order排序的,那么输出流中的行将按照output_order排序。
Table Reader的有序性保证以及特征函数可在逻辑计划中传播排序信息。当存在不匹配(聚合器具有与有序性保证不匹配的排序要求)的情况时,我们插入一个排序聚合器。
二十七、Aggregator分类
- TABLE READER是一个特殊的Aggregator,没有输入流。它包含了表或者索引的读取范围以及schema。同其它Aggregator一样,TABLE READER可以配置一个可编程的输出过滤器。
- Join 在两个流上执行连接操作,并且满足在特定字段上的等式约束。聚合器按照等式约束字段对数据进行分组。
- JOIN READER 根据输入流上指定的Key进行点查。可以通过执行(可能是远程的)KV读或者设置远程操作流来实现。
- SET OPERATION 可处理多个输入并对这些输入流执行集合算术运算(union,difference)
AGGREGATOR 即SQL语义上的聚合操作。通过group key对数据进行分组,并且计算每个分组的聚合值。AGGREGATOR可以配置一个或多个聚合函数:
- SUM
- COUNT
- COUNT DISTINCT
- DISTINCT
也可在group key或者聚合结果上执行过滤操作(甚至可以对中间结果进行过滤)。
- SORT 可依据指定的排序列对输入排序。由于SORT是一个无分组的聚合器,因此它可以被任意地分配给数据生产者。这意味着它不会产生一个全局排序,而只保证物理输出流内部的有序。全局排序可以通过分组处理器(例如LIMIT或者FINAL)的输入同步器来实现。
- LIMIT是一个单一分组聚合器,当读到一定量数据行后终止。
- FINAL是一个在网关节点收集查询结果的单一分组聚合器。该聚合器被关联到客户端的pgwire connection。
二十八、物理计划
在物理计划规划阶段,逻辑计划将会被转换成物理计划。详情请参阅Distributed SQL RFC相应章节。总的来说,在物理计划中每一个聚合器被转化为一个或多个Processor,根据数据分布状况分配Processor – 依据Range数量将TABLE READERS划分为多个实例 – 每个实例被规划至相关Range的租约持有者上。从这时候起,后续的Processor通常要么与它们的输入一起使用,要么被规划为单例(通常是在入口节点上)执行。
二十九、Processors
当把一个逻辑计划变成一个物理计划时,计划树的执行节点转变成Processor。Processor通常由三个部分组成:

Input Synchronizer将多个输入流合并成一个。类型包括:
- 单一输入(跳过)
- 非同步:接收来自所有输入流的数据行(数据流可能是任意交织的)。
- 有序:输入物理流是有序的(即逻辑流也是有序的);Synchronizer也需要保证合并后的数据流有序。
Data Processor实现了数据转换或聚合逻辑(以及在某些情况下执行的KV操作)
Output Router将Data Processor的输出分成多个输出流;类型包括:
- 单一输出(跳过)
- 镜像:每一行都复制到所有输出流
- 哈希:根据哈希函数将数据行输出到对应输出流。
- 通过range:路由器配置了Range信息(与某个表相关)并且能够将数据行输出到相关Range租约持有者所在节点(通常对于JoinReader 节点(把索引值传递给相应主键所在节点)和 INSERT(把新的数据行传递给即将成为租约持有的节点)有用)
下面举例说明来自《 Distributed SQL RFC》:
TABLE Orders (OId INT PRIMARY KEY, CId INT, Value DECIMAL, Date DATE)
SELECT CID, SUM(VALUE) FROM Orders
WHERE DATE > 2015
GROUP BY CID
ORDER BY 1 – SUM(Value)
生成以下逻辑计划:
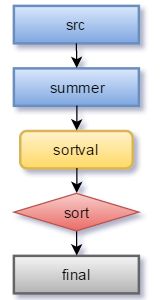
以上的逻辑计划可以转换为以下其中一种物理计划:
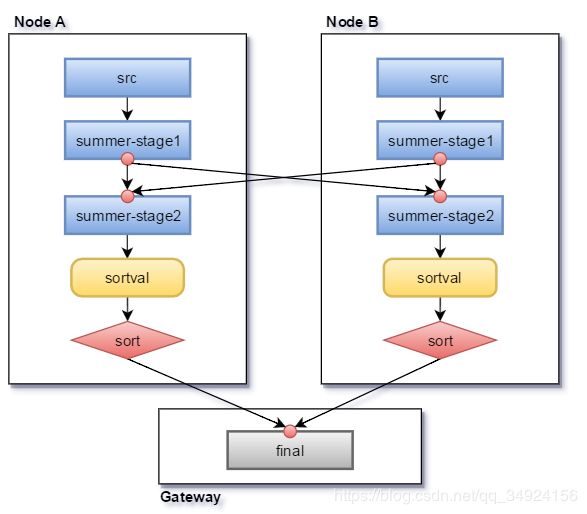
或者:
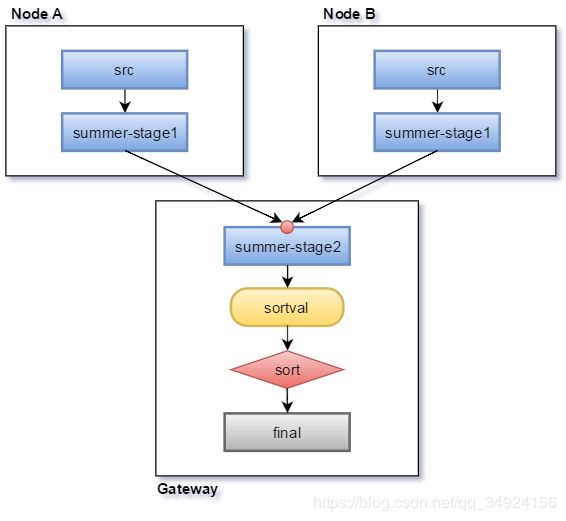
三十、执行框架
物理计划一旦生成,系统将该执行计划分发到多个节点执行。每个节点负责调度本地的Data Processor 和 Input Synchronizer。节点之间可以通过流式接口将Output Router和Input Synchronizer连接起来。
三十一、生成逻辑计划:ScheduleFlows RPC
分布式执行过程:Gateway向执行计划的参与节点发送请求,参与节点负责各自的子计划的调度和执行(on-the-fly flow除外,详情见Dist-SQL设计文档)。一个节点可能负责多个独立的DAG任务——称之为“Flow”。一个Flow包含它所负责的物理计划执行节点的执行顺序,执行节点间的连接(Input Synchronizer 和 Output Router),以及该Flow上层节点输入流和下层节点输出流的标识符。一个节点可能负责调度执行多个异构Flow。通常情况下,当一个节点持有同一个表多个Range的租约,而且这些Range在同一个查询中被访问时,节点将会在本地运行一个TableReader,读取所有Range组成的Span。
因此,节点实现了ScheduleFlows RPC机制来管理Flow,为每个Flow设置输入和输出的Mailbox,并创建本地Processor执行Flow。_Mailboxes
三十二、Flow的本地调度
一个节点同时调度多个不同Processor最简单的方法是并发执行:每一个Data Processor,Synchronizer和Router分别在独立的goroutine中运行,通过Channel机制通信。这些Channel自带缓冲,用于协调生产者和消费者。
三十三、邮箱机制
不同节点上的Flow通过gRPC相互通信。为了能让生产者和消费者异步启动,ScheduleFlows为所有的输入和输出Flow创建命名的Mailbox。Mailbox可以将部分元组缓存至内部消息队列直到gRPC连接建立。当gRPC连接建立后,gRPC流控机制被用来协调生产者和消费者。消费者通过StreamMailbox RPC请求建立gRPC Stream,并携带相应的Mailbox ID(该ID在ScheduleFlows中也会用到)。
使用Mailbox执行简单查询示意图:

三十四、一个复杂例子:日常促销
为了方便理解上述的处理逻辑,我们画了一个相对复杂查询的物理计划示意图。这个查询的关键是帮助分析日常促销,定位去年花了1000美元以上的客户。我们向表DailyPromotion执行插入数据,其中每行记录代表一个客户及其最近的订单总额。
TABLE DailyPromotion (
Email TEXT,
Name TEXT,
OrderCount INT
)
TABLE Customers (
CustomerID INT PRIMARY KEY,
Email TEXT,
Name TEXT
)
TABLE Orders (
CustomerID INT,
Date DATETIME,
Value INT,
PRIMARY KEY (CustomerID, Date),
INDEX date (Date)
)
INSERT INTO DailyPromotion
(SELECT c.Email, c.Name, os.OrderCount FROM
Customers AS c
INNER JOIN
(SELECT CustomerID, COUNT(*) as OrderCount FROM Orders
WHERE Date >= ‘2015-01-01’
GROUP BY CustomerID HAVING SUM(Value) >= 1000) AS os
ON c.CustomerID = os.CustomerID)
可能的物理计划如下:
