Python的爬虫学习笔记本(一)爬虫的基本原理
NLP的任务往往需要大量的语料库作为数据集,而尽管现有的许多任务上都有固定的数据集,但还是在很多方面存在着欠缺。为了弥补这个欠缺,网上的大量免费的文本信息就需要通过爬虫爬下来。由此开始了爬虫的学习。
爬虫学习之: 爬虫的基本原理
爬虫:请求网站并提取数据的自动化程序。
- 请求:鼠标点击网页资源;程序实现;
- 提取:资源——HTML代码 - 资源包含在文本中 -> 从文本中提取想要的信息 -> 存成文本/数据库
- 自动化: 循环运行,自动运行
如:
浏览器 - 网页 - 检查 - 得到网页的源代码 - 可以发现可视化的信息都隐藏在源代码中
若想要提取信息,就需要对文字和连接信息进行分析,并提取出来。
思路:使用工具获取源代码,使用信息库整理资源,最终储存信息。
总的来说:
1. 发起请求:通过HTTP库向目标站点发起请求(request),请求可以包含Headers等信息,等待服务器的响应。
2. 获取相应内容: 如果服务器能正常相应,会得到一个Response,Response的内容便是要获取的页面内容,类型可能有HTML,Json字符串,二进制数据等类型。
3. 解析内容: 得到的内容可能是HTML,可以用正则表达式、网页解析库等进行解析,可能是Json格式,可以直接转化为Json对象解析,可能是图片、视频等二进制数,可以保存或者进一步处理。
4. 保存数据:保存成文本或者数据库等格式。
Response & Request
使用浏览器上网时,浏览器向服务器发送请求(request):请求xx页面,看xx信息;服务器经过解析后,返回相应(response)
如:
使用任意浏览器在网站浏览时,摁F12显示出网页源码(选项卡),在选项卡中选择Network选项,刷新就能看到许多链接,这些链接就是浏览器与服务器进行通信时的请求与响应的记录:
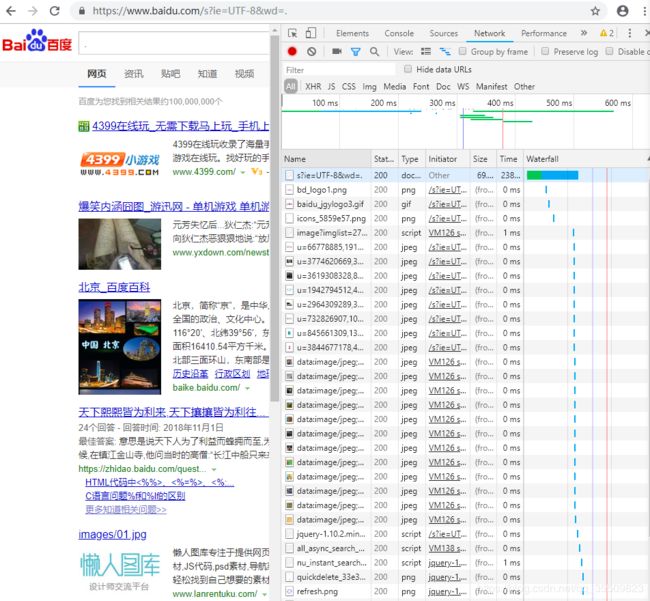
点进任意项,可以看到Request/Response的具体内容,在选项栏中选择Headers就能看到,在第一个的Response中,可以看到page_source源代码:

流程:
- 浏览器发送消息给该网址所在的服务器 —— HTTP request
- 服务器处理后回传消息 —— HTTP response
- 浏览器收到信息后展示
Request包含什么
请求方式: get、post和其他集中不常用的方式; get上图就有
post: 对于登录信息,即为post请求方式; post请求方式有form data的额外信息(Header中可以看到);请求信息被包含到了form data中。
get:百度搜索的信息就是一种get请求,其参数包含在URL中。
即不同之处:请求的参数在哪里(form还是URL);请求的方式:输入(get)/构造表单(form); post更加安全,get更加边界
请求URL: 统一资源定位符;视频、图片、文字都可以用URL表示
在选项的Preview中可以看到传输表示的内容;在filter中可以看到不同类型的信息。在源代码中,最重要的是html标签
请求头:包含比较重要的配置信息:Cookie等。表示:你要请求的内容;cookie;浏览器等配置信息,服务器根据此来判断请求是否合法
请求体:GET中没有任何内容;POST中就是Form data
Response包含什么
响应状态:状态码 - 200OK (正常发送,正常响应);300 (跳转);404 Not Found; 500+ (服务器处理错误)
响应头:键值对形式,包含Set-cookie - 保存cookie,维持会话信息;
响应体:包含网页源代码,包含请求的数据(Preview中可以看到)。
Example:
使用requests库:
import requests
response = requests.get('http://www.baidu.com')
# 完成请求发送,拿到响应
print(response.text)
ç¾åº¦ä¸ä¸ï¼ä½ å°±ç¥é ©2017 Baidu 使ç¨ç¾åº¦åå¿è¯» æè§åé¦ äº¬ICPè¯030173å· 
print(response.headers)
{'Cache-Control': 'private, no-cache, no-store, proxy-revalidate, no-transform', 'Connection': 'Keep-Alive', 'Content-Encoding': 'gzip', 'Content-Type': 'text/html', 'Date': 'Thu, 24 Jan 2019 01:58:22 GMT', 'Last-Modified': 'Mon, 23 Jan 2017 13:27:32 GMT', 'Pragma': 'no-cache', 'Server': 'bfe/1.0.8.18', 'Set-Cookie': 'BDORZ=27315; max-age=86400; domain=.baidu.com; path=/', 'Transfer-Encoding': 'chunked'}
print(response.status_code)
200
# 下面制作一个Headers
headers = {}
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
response = requests.get('http://www.baidu.com', headers=headers)
print(response.status_code)
200
# Header 由网页复制而来

如何爬取数据
抓取怎样的数据:
1. HTML ; Json
2. 视频,图片:
获取图片的例子,如百度
response = requests.get('https://ss0.bdstatic.com/5aV1bjqh_Q23odCf/static/superman/img/logo_top_86d58ae1.png')
# Copy from the Network - Headers
with open('1.png','wb') as f:
# 1.png是文件名, wb是文件格式(二进制)
f.write(response.content)
f.close
3. 只要是能请求到的,都能获取
怎样来解析
1. 直接处理:构造简单,去掉收尾
2. Json解析:如微博
3. 正则表达式
4. BeautifulSoup
5. PyQuery
6. XPath
用来提取网页
抓取到的数据和浏览器的看起来不一样?
request = requests.get('http://m.weibo.com')
print(request.text)request只得到第一个请求的内容,在浏览器加载后面的Js文件之后,它就会改变原先的html。数据都是由后台加载出来的,通过接口的形式传播数据;原生html不包含信息,js包含接口,再获取数据。若再看浏览器的element,得到的是最后请求到的最终代码。
- 所以如何解决Js的渲染问题
1. 分析Ajax请求;返回Json格式的字符串 2.Selenium/WebDriver来解决
example:
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('www.zhihu.com')
driver.page_source通过page_source就能解决Js渲染的问题
3. Splash 模拟渲染 4. PyV8,Ghost.py类似库
如何保存数据
1. 纯文本:Json,Xml等
2. 关系型数据库;非关系型数据库
3. 二进制文件(视频、图片)