BigGAN、BiGAN、BigBiGAN简单介绍
介绍
上一篇文章在介绍GAN的评价标准的时候提到了 BigGAN 在Inception Score上取得了巨大的进步,而最近 DeepMind 又基于 BiGAN 提出了 BigBiGAN,它在 ImageNet 上的无监督表示学习和无条件图像生成方面都取得了极为优秀的成绩。
本文主要对BigGAN和BiGAN的思想进行简单介绍,BigBiGAN 在结构上并没有对 BiGAN 做什么改变,原理也基本一致,只是将 D 的结构改进了一下,同时使用了 BigGAN 的生成器和判别器结构以及 BigGAN 的大规模训练方法以及一些训练技巧。
BiGAN
VAE和GAN都是常见的生成式模型,对于VAE结构:image1输入到encoder中,产生输出vector,这个vector再输入到decoder中产生image2,然后最小化重构误差||image1-image2||;对于GAN:优化目标是判别器D的输出,而输入是真实图片和随机采样噪声经过G生成的虚假图片。
而BiGAN则结合编解码器结构和判别器结构提出了一种新的优化思路:
- 输入image x(x是数据集中的真实图片),经过编码器E得到E(x)
- 从某个分布(如高斯分布、均匀分布等)中采样随机噪声z,经过解码器G得到G(z)
- 通过上述两步,我们可以得到一系列(x, E(x))和(G(z), z),前者是Encoder产生的,后者是Generator产生的,将这些结果输入到Discriminator中,让它判断是E还是G产生的;如果D不能准确判断,那么就成功了。

优化步骤和一般GAN类似,如下图:

从上面的分析可以看出,BiGAN 在 GAN 的基础上加入了一个将数据映射到隐特征空间的 Encoder,同时对 D 做了相应的改进。D 的输入变成了两个数据对(G(z),z)和(x, E(x)),其中 G(z)和 E(x)分别代表 G 和 E 的输出,x 代表原始数据,z 表示随机潜变量。
此时 G 与 E 的联合概率可以表示为:
编码器的联合 (概率) 分布 q(x, z)=q(z|x)q(x)
解码器的联合 (概率) 分布 p(x, z)=p(x|z)p(z)
G,E 和 D 的博弈可以理解为——G 和 E 希望能够欺骗 D,让 D 无法分辨这两个数据对的来源。最终的模型希望 x = G(E(x)),z = E(G(z))(双向)。如果 D 认为这个数据对来自 G,则输出 1,若是来自 E,则输出 0。因此,其目标函数也和基础的GAN类似,如下图:

这个式子和 GAN 的目标函数区别仅在于 D(x) 变成了 D(x, Gz(x)), D(G(z)) 变成了 D(Gx(z), z)。论文中也对这个目标函数是否能实现 x = G(E(x)),z = E(G(z))做了证明,这一目标的数学含义可以说是两个联合概率相等,即当 BiGAN 的训练完成, 上文提到的两个联合分布(q(x, z) 与 p(x, z))匹配,这也就意味着所有的边缘分布和条件分布都匹配了。比如可以认为条件概率 q(z|x) 匹配了后验概率 p(x|z)。
具体公式推导可以看论文:Adversarial Feature Learning
(还有另一篇Adversarially Learned Inference (ALI)和BiGAN的思想差不多,这两篇论文同时被 ICLR2017 收录)
总之,BiGAN 使得 GAN 具有了学习有意义的特征表示的能力。原始 GAN 中,D 接收样本作为输入, 并将其习得的中间表示作为相关任务的特征表示, 没有其他的机制。它对于生成数据与真实数据的语义上有意义的特征并不十分清晰。当 G 生成了真实数据时,D 只能预测生成数据(图片)的真实性,但是无法学习有意义的中间表示。BiGAN 就是希望让 GAN 能够具备表征学习能力。
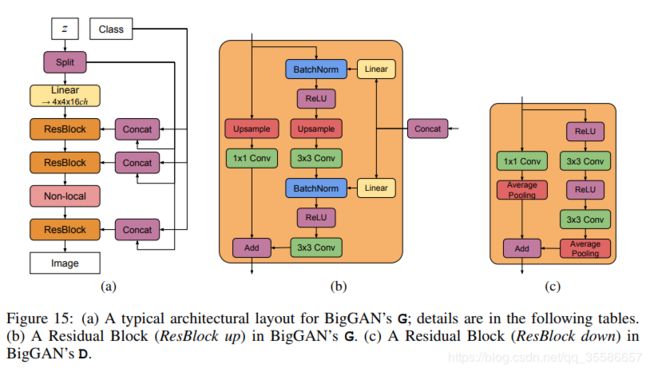
BigGAN
DeepMind带来的Large Scale GAN Training for High Fidelity Natural Image Synthesis,从名字上来看它的突出特点就是Large Scale:Batch_size达到了2048,而网络的参数更是多达16亿,生成512x512像素的图片,需要的是512块谷歌TPU,并且训练时间会持续24到48个小时。(据估算,如果每个TPU每个小时需要200瓦的电量,那么在该实验中,每个TPU将耗费2450到4915度电,相当于一个普通美国家庭大约半年内的用电量。看来,普通人和机器学习高手的差距,可能不仅仅是几个算法之间的差距那么简单了……)
当然,要想在这么大规模的训练中,保证网络的收敛以及生成图片的效果,需要使用到很多trick。
论文中提到的主要贡献有三点:
- 证明了大规模的训练能给GAN带来巨大提升,介绍了两个简单的,一般的体系结构更改使得提高网络的性能;
- 提出了一种简单的采样技术——truncation trick(截断技巧),允许对样本多样性和保真度之间的权衡进行明确、细粒度的控制;
- 发现了大规模GAN特有的不稳定性,并根据经验对其进行了表征。 通过分析,我们证明了新技术和现有技术的结合可以减少这些不稳定性,但完全的训练稳定性只能以极高的性能成本实现。
BigGAN 是在 SAGAN 的基础结构上实现的,同样采用 Hinge Loss、BatchNorm 和 Spectral Norm(谱范数正则)和一些其它技巧。在 SAGAN 的基础上,BigGAN 在设计上做到了 Batch size 的增大、“截断技巧”和模型稳定性的控制。
(Self-Attention Generative Adversarial Networks(SAGAN):卷积网络的局部感受野的限制,如果要生成大范围相关(Long-range dependency)的区域,要多层卷积层才能很好地解决。如果采用全连接层来获取全局信息,未免参数量太大计算量太大,因此引入了Attention机制,实现一种能够利用全局信息的方法。之后的博客应该会再介绍具体细节)
SAGAN 中的 Batch size 为 256,作者做了测试,简单地增加Batch size的大小就可以提高不少效果:

个人认为Batch size的增加使得在BN操作的时候,融合了更多样本的特征,会使得生成的图片多样性更好。除了Batch size,文章在每层的通道数也做了相应的增加,当通道增加 50%,大约两倍于两个模型中的参数数量,这会导致 IS 进一步提高 21%。当然,增加Batch size和通道数都会使得网络的训练不稳定,因此作者也使用了很多加快收敛的技巧。
BigGAN 在先验分布 z 的嵌入上做了改进,普遍的 GAN 都是将 z 作为输入直接嵌入生成网络,而 BigGAN 将噪声向量 z 送到 G 的多个层而不仅仅是初始层。文章认为潜在空间 z 可以直接影响不同分辨率和层次结构级别的特征,如下图:
截断技巧:
所谓的“截断技巧”就是在对从先验分布 z 采样的过程中,通过设置阈值的方式来截断 z 的采样,超出范围的值被舍弃并且重新采样以落入该范围内。这个阈值可以根据生成质量指标 IS 和 FID 决定。
实验证明:随着阈值的下降生成的质量会越来越好,但是由于阈值的下降、采样的范围变窄,就会造成生成上取向单一化,造成生成的多样性不足的问题。往往 IS 可以反应图像的生成质量,FID 则会更假注重生成的多样性。如下图:

随着截断的阈值下降,生成的质量在提高,但是生成也趋近于单一化。所以根据实验的生成要求,权衡生成质量和生成多样性是一个抉择,往往阈值的下降会带来 IS 的一路上涨,但是 FID 会先变好后一路变差。
还有在一些较大的模型不适合截断,在嵌入截断噪声时会产生饱和伪影,如上图 (b) 所示,为了抵消这种情况,文章通过将 G 调节为平滑来强制执行截断的适应性,以便 z 的整个空间将映射到良好的输出样本,并采用正交正则化解决该问题,具体公式还没有太理解,感兴趣的可以去看原文。
为了保证网络的稳定性,在训练G和D的时候还借助于数学推导,对参数等做了很多限制,比如Spectral Norm等方法。
总之,BigGAN其实是提供了一种大规模训练GAN的方法,并且针对具体训练过程中可能存在的不稳定性提出了一些应对技巧。但是不得不说,从结果来看,这种方法对于GAN的效果提升是巨大的。
BigBiGAN
bidirectional GAN (BiGAN)的核心就是Bi(双向):在原始的GAN架构里,生成器是个前馈过程,将随机噪声分布中取样的潜变量,映射到生成的数据 (假图) 上面。而BiGAN中的编码器把真实数据 (真图) 映射到潜变量上,这样就有了两种不同方向的映射,成了双向GAN。但是,BiGAN的生成器是DCGAN的结构,生成不了高质量的图像,这样导致另一个方向上编码器学到的特征映射也会受影响。BigGAN弥补了DCGAN的不足,因此BigGAN与BiGAN结合便有了Large Scale Adversarial Representation Learning (BigBiGAN)。
论文中提到的主要贡献有四点:
- 在ImageNet上,BigBiGAN(带BigGAN的BiGAN生成器)达到了无监督表征学习的最新技术水平
- 为BigBiGAN提出了一个更稳定的联合判别器
- 对模型设计的选择进行了全面的实证分析和消融实验
- 表明了表征学习目标还有助于无条件图像生成,并展示无条件ImageNet生成的最新结果
下面是网络的结构图:

和BiGAN相似,BigBiGAN也是将编码器和解码器各自对应的数据对送入判别器中,但是设计了一个新的联合判别器,由三个模块组成:F、H和J。其中F只接收假图片 x ^ \hat{x} x^ 和真图片 x x x,H只接受噪声 z ^ \hat{z} z^ 和编码结果 z z z,其作用就是传统GAN中的判别器,F判断输入图片是否为真;H判断输入特征编码是否来自真实图片,因此F是 ConvNet 而H是 MLP 结构。模块J负责联合F和H的输出,整个网络的损失函数如下:

消融实验(ablation study): 取消掉一些模块后性能有没有影响。根据奥卡姆剃刀法则,简单和复杂的方法能达到一样的效果,那么简单的方法更可靠。比如你提出了某某结构,但是要想确定这个结构是否有利于最终的效果,那就要将去掉该结构的网络与加上该结构的网络所得到的结果进行对比,这就是ablation study。
作者对BigBiGAN的结构做了很多消融实验,比如:
潜在分布的选择,正态分布,均匀分布以及其它的实现方法;
一元损失项的添加(结构图中的sx和sz),只有z一元项和没有一元项的IS和FID性能要比只有x一元项和两者都有的性能差,结果表明x一元项对生成性能有很大的正面影响;
生成器的参数量,参数量大的生成器效果更好,而好的图像生成器模型能提高表征学习能力;
生成器和编码器不对称结构,编码器采用较高分辨率的图片,而生成器生成分辨率稍低的图片;
编码器的结构,网络宽度增加会提高效果;
解耦编码器和生成器的优化,将二者的优化器分离,并发现简单地使用10倍的编码器学习速率可以显着加速训练并改善最终表征学习结果。
下面是各种消融实验的对比图:

表征学习效果: 为了证明其表征学习能力,作者也将 BigBiGAN 的最佳组合(上表中的最后两行)在 ImageNet 上就准确率与最近效果较好的自我监督方法进行了比较。其中 BN+CReLU 是在 AvePool 的结果 a 的基础上,先进行 h = BatchNorm(a) 操作,并将 [ReLU(h), ReLU(-h)] 作为最终特征输出,这种输出方法也叫 CReLU。其中 BatchNorm() 表示无参数 Batch Normalization,所以这个新加的操作并不会增加计算成本;而 CReLU 的加入则让结果变得更加全面,从而获得更好的输出结果。具体结果如下表所示:

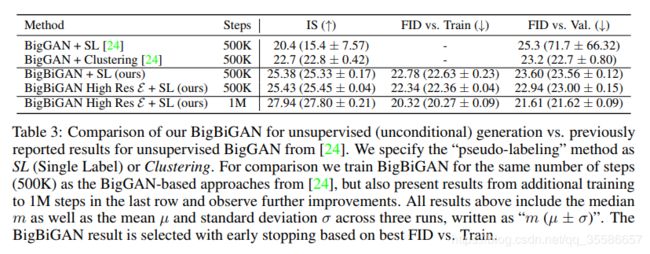
最后,作者回归 GAN 最原始的任务——图像生成,将其与BigGAN的方法进行了对比。下表第一行中的 SL 表示 single label 方法,产生的是一种单混和标签;而 Clustering 表示标签是由 Clustering 获得的,是一种伪标签。最后,因为在 500K 步后,BigBiGAN High Res + SL 的效果还有提升,所以最后一行也加入了 1M 步后的结果。详细结果见下表。
总结
BiGAN通过双向的思想,赋予了潜变量更加深刻的含义,使得编码器能够学习到有意义的中间特征表示,从而用于表征学习,但受限于DCGAN中生成器的效果,中间特征表示的学习效果并不理想。BigGAN借助于大规模的学习和训练方法,在生成图片的效果上取得了巨大的进步,自然就有了BigBiGAN的出现。BigBiGAN 提出了联合判别器的结构,但作为一种完全基于 Generative Model 的方法,无监督表征学习的准确率上比监督学习的方法还是要差很多的。未来是否能如同半监督学习一样,结合 Generative Model 与监督学习产出一种新的更高效且准确率也很高的方法?这可能是下一步需要研究的方向。
主要参考的博客有:https://blog.csdn.net/c9Yv2cf9I06K2A9E/article/details/83026880
https://blog.csdn.net/dQCFKyQDXYm3F8rB0/article/details/95258966
https://www.jiqizhixin.com/articles/2019-07-24-6