一年二年面试java可能问到的问题
对于一年经验 会问到什么问题呢 根据在qq群里大神聊天 所记录一下 !
数据库问题
--内连接
SELECT Students.ID,Students.Name,Majors.Name AS MajorName
FROM Students INNER JOIN Majors ON Students.MajorID = Majors.ID
--左连接
SELECT Students.ID,Students.Name,Majors.Name AS MajorName
FROM Students LEFT JOIN Majors ON Students.MajorID = Majors.ID
--右连接
SELECT Students.ID,Students.Name,Majors.Name AS MajorName
FROM Students RIGHT JOIN Majors ON Students.MajorID = Majors.ID
--全连接
SELECT Students.ID,Students.Name,Majors.Name AS MajorName
FROM Students FULL JOIN Majors ON Students.MajorID = Majors.ID
--交叉连接
SELECT Students.ID,Students.Name,Majors.Name AS MajorName
FROM Students CROSS JOIN Majors WHERE Students.MajorID = Majors.ID
那么 对于三张表是怎么连接的呢
两张表连接的 on 或者 where 之后 再连接 比如
ON Students.MajorID = Majors.ID left join table3 t on t.id=majors.id
三张表的优化 是如何优化
2 SQL中存储过程和函数的区别
本质上没区别 函数:只能返回一个变量的限制。而存储过程可以返回多个。而函数是可以嵌入在sql中使用的,可以在
select中调用,而存储过程不行。执行的本质都一样。
对于存储过程来说可以返回参数,而函数只能返回值或者表对象。
存储过程一般是作为一个独立的部分来执行(EXEC执行),而函数可以作为查询语句的一个部分来调用
(SELECT调用),由于函数可以返回一个表对象,因此它可以在查询语句中位于FROM关键字的后面。
3 更新查询 :在一张表 数据 更新 另一张表
update tablename set xx =(select xx from tablenameb )
4 mysql与nosql有什么区别
即非关系型数据库(nosql)和关系型数据库(mysql)
非关系型数据库 目前最火的 是 Redis、Memchache、MongoDb
关系型数据库 : mysql , orcale ,sql server
他们具体的区别 可分为 如下 几部分
存储方式: 关系型数据库 是表格式的,因此存储在表的行和列中。关联协作存储,提取数据很方便。非关系型数据库 是大块的组合在一起。通常存储在数据集中,就像文档、键值对或者图结构。
存储结构:关系型数据库对应的是结构化数据,数据表都预先定义了结构(列的定义),虽然预定义结构带来了可靠性和稳定性,但是修改这些数据比较困难。Nosql数据库基于动态结构,使用与非结构化数据。因为Nosql数据库是动态结构,可以很容易适应数据类型和结构的变化。
存储规范 : 关系型数据库的数据存储为了更高的规范性,把数据分割为最小的关系表以避免重复,获得精简的空间利用。虽然管理起来很清晰,但是单个操作设计到多张表的时候,数据管理就显得有点麻烦。而Nosql数据存储在平面数据集中,数据经常可能会重复。单个数据库很少被分隔开,而是存储成了一个整体,这样整块数据更加便于读写
查询方式 :关系型数据库通过结构化查询语言来操作数据库(就是我们通常说的SQL)。SQL支持数据库CURD操作的功能非常强大,是业界的标准用法。而Nosql查询以块为单元操作数据,使用的是非结构化查询语言(UnQl),它是没有标准的。关系型数据库表中主键的概念对应Nosql中存储文档的ID。关系型数据库使用预定义优化方式(比如索引)来加快查询操作,而Nosql更简单更精确的数据访问模式。
事务 : 关系型数据库遵循ACID规则(原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)),而Nosql数据库遵循BASE原则(基本可用(Basically Availble)、软/柔性事务(Soft-state )、最终一致性(Eventual Consistency))。由于关系型数据库的数据强一致性,所以对事务的支持很好。关系型数据库支持对事务原子性细粒度控制,并且易于回滚事务。而Nosql数据库是在CAP(一致性、可用性、分区容忍度)中任选两项,因为基于节点的分布式系统中,很难全部满足,所以对事务的支持不是很好,虽然也可以使用事务,但是并不是Nosql的闪光点。
性能 : 关系型数据库为了维护数据的一致性付出了巨大的代价,读写性能比较差。在面对高并发读写性能非常差,面对海量数据的时候效率非常低。而Nosql存储的格式都是key-value类型的,并且存储在内存中,非常容易存储,而且对于数据的 一致性是 弱要求。Nosql无需sql的解析,提高了读写性能。
mysql有几种引擎,有什么区别
Mysql在V5.1之前默认存储引擎是MyISAM;在此之后默认存储引擎是InnoDB
主要是MyISAM和InnoDB两个引擎,主要的区别如下
1、innodb 支持事务,这一点非常重要,事务是一种高级的处理方式,如果在一些增删中如果那个出错可以换源回滚,myisam不支持事务
2、myisam适合查询以及插入为主的应用,Innodb适合频繁的修改以及设计到安全性能较高的应用
3、innodb适合外键,mysiam不适合外键
4、mysql中默认的mysiam引擎,如如果要是用innodb需要制定
5、innodb不支持富文本
6、InnoDB 中不保存表的行数,如 select count(*) from table 时,InnoDB;需要
扫描一遍整个表来计算有多少行,但是 MyISAM 只要简单的读出保存好的行数即
可。注意的是,当 count(*)语句包含 where 条件时 MyISAM 也需要扫描整个表;
7、对于自增长的字段,InnoDB 中必须包含只有该字段的索引,但是在 MyISAM
表中可以和其他字段一起建立联合索引;
8、清空整个表时,InnoDB 是一行一行的删除,效率非常慢。MyISAM 则会重
建表;
9、InnoDB 支持行锁(某些情况下还是锁整表,如 update table set a=1 where
user like ‘%lee%’
mysql 事务的四大特性(ACID):
1.原子性(atomicity):一个事务必须视为一个不可分割的最小工作单元,整个事务中的所有操作要么全部提交成功,要么全部失败回滚,对于一个事务来说,不可能只执行其中的一部分操作,这就是事务的原子性。
2.一致性(consistency):数据库总数从一个一致性的状态转换到另一个一致性的状态。
3.隔离性(isolation):一个事务所做的修改在最终提交以前,对其他事务是不可见的。
4.持久性(durability):一旦事务提交,则其所做的修改就会永久保存到数据库中。此时即使系统崩溃,修改的数据也不会丢失。
乐观锁和悲观锁的区别
悲观锁
总是假设最坏的情况,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会阻塞直到它拿到锁(共享资源每次只给一个线程使用,其它线程阻塞,用完后再把资源转让给其它线程)。传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。Java中synchronized和ReentrantLock等独占锁就是悲观锁思想的实现。
乐观锁
总是假设最好的情况,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号机制和CAS算法实现。乐观锁适用于多读的应用类型,这样可以提高吞吐量,像数据库提供的类似于write_condition机制,其实都是提供的乐观锁。在Java中java.util.concurrent.atomic包下面的原子变量类就是使用了乐观锁的一种实现方式CAS实现的。
从上面对两种锁的介绍,我们知道两种锁各有优缺点,不可认为一种好于另一种,像乐观锁适用于写比较少的情况下(多读场景),即冲突真的很少发生的时候,这样可以省去了锁的开销,加大了系统的整个吞吐量。但如果是多写的情况,一般会经常产生冲突,这就会导致上层应用会不断的进行retry,这样反倒是降低了性能,所以一般多写的场景下用悲观锁就比较合适。
行级锁和表级锁的区别
表级:引擎 MyISAM , 理解为锁住整个表,可以同时读,写不行
行级:引擎 INNODB , 单独的一行记录加锁
表级,直接锁定整张表,在你锁定期间,其它进程无法对该表进行写操作。如果你是写锁,则其它进程则读也不允许
行级,,仅对指定的记录进行加锁,这样其它进程还是可以对同一个表中的其它记录进行操作。
如何优化mysql
MySQL各组件之间如何协同工作的架构图:

前端知识
1 javascript中怎样选中一个checkbox,设置它无效的方式。
首先是在html设置无效
只要设置disable 就是无效
document.getElementById("check").disabled='x'//必须设置值 值无所谓2 form表单 的input可以设置readonly和disable区别。
readonly=''' 控件外观不会变
disable 颜色变为灰色
3 javascript变量范围有什么不同,全局变量和局部变量。
1 使用var声明变量,在方法内部是局部变量,在方法外部是全局变量
2. 没有使用var声明的变量,在方法内部或外部都是全局变量 但如果是在方法内部声明,在方法外部使用之前需要先调用,告知系统声明了全局变量后方可在方法外部使用。
4 基本数据类型:
字符串 String
数字 Number
布尔Boolean
复合数据类型:
数组 Array
对象 Object
特殊数据类型:
Null 空对象
Undefined 未定义
5 jquery的append与appendTo区别。
append 向每个匹配的元素内部追加内容。
appendTo 把所有匹配的元素追加到指定的元素元素集合中。
用法示例:
HTML代码为I love china
把标签b追加到p元素中,写法为$("b").appendTo("p");
结果为:
I love china
6 CSS盒子模型
一个盒子中主要的属性就5个:width、height、padding、border、margin。如下:
- width和height:内容的宽度、高度(不是盒子的宽度、高度)。
- padding:内边距。
- border:边框。
- margin:外边距。
7 浏览器常用对象
window对象
History对象:history对象记录了用户曾经浏览过的页面(URL),并可以实现浏览器前进与后退相似导航的功能。
Location对象:location用于获取或设置窗体的URL,并且可以用于解析URL。
java基础
线程的问题
1 Java中多线程同步是什么?
同步能控制对共享资源的访问。如果没有同步,当一个Java线程在修改一个共享变量时,另外一个线程正在使用或者更新同一个变量,这样容易导致程序出现错误的结果。
2、同步和异步的区别和联系
同步就是一件事,一件事情一件事的做。
异步就是,做一件事情,不影响做其他事情。
3、其实 在现在 很简单的一些功能 或许 人人都能实现 但是 遇到高并发 怎么解决 几百 几千 几万 个人 同时登录怎么办 会奔溃吗 为什么出现奔溃 怎样处理
首先要了解高并发的的瓶颈在哪里?
1、可能是服务器网络带宽不够
2.可能web线程连接数不够
3.可能数据库连接查询上不去。
根据不同的情况,解决思路也不同。
-
像第一种情况可以增加网络带宽,DNS域名解析分发多台服务器。
-
负载均衡,前置代理服务器nginx、apache等等
-
数据库查询优化,读写分离,分表等等
在高并发下面需要常常需要处理的内容:
-
尽量使用缓存,包括用户缓存,信息缓存等,多花点内存来做缓存,可以大量减少与数据库的交互,提高性能。
-
用jprofiler等工具找出性能瓶颈,减少额外的开销。
-
优化数据库查询语句,减少直接使用hibernate等工具的直接生成语句(仅耗时较长的查询做优化)。
-
优化数据库结构,多做索引,提高查询效率。
-
统计的功能尽量做缓存,或按每天一统计或定时统计相关报表,避免需要时进行统计的功能。
-
能使用静态页面的地方尽量使用,减少容器的解析(尽量将动态内容生成静态html来显示)。
4 如果有个map 删除指定的key 或者批量删除 或者匹配key包含指定字符串 怎么做

结果如下
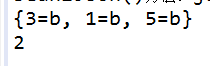
5 如果说 你打开一个页面 用了很长时间 该怎么解决
如果是 静态页面 可能加载的js文件 太多 没有经过压缩 一次性加载太多 造成
如果说 jsp 服务器的问题
如果是 查询数据库 则 可能 连接数据库问题 也可能属于数据库的优化 不用 * 查询指定的 字段 , 不用子查询 ,分表,做索引 分页
6 hashtable 与hashmap 区别
hashtable 底层数组+链表实现,无论key还是value都不能为null,线程安全
hashmap : 底层数组+链表实现,可以存储null键和null值,线程不安全
Tomcat
1 tomcat debug模式启动
在tomcat安装目录下的bin目录下查找setenv.bat, 如果没有找到就新建,然后添加以下内容
set JPDA_OPTS="-agentlib:jdwp=transport=dt_socket, address=11550, server=y, suspend=n"
2 tomcat项目部署路径
在 webapps 文件夹下
redis
1.什么是redis?
Redis 是一个基于内存的高性能key-value 内存数据库。
2.为什么redis需要把所有数据放到内存中?
Redis为了达到最快的读写速度将数据都读到内存中,并通过异步的方式将数据写入磁盘。所以redis具有快速和数据持久化的特征。如果不将数据放在内存中,磁盘I/O速度为严重影响redis的性能。在内存越来越便宜的今天,redis将会越来越受欢迎。
如果设置了最大使用的内存,则数据已有记录数达到内存限值后不能继续插入新值。
3 缓存雪崩
缓存雪崩是由于原有缓存失效(过期),新缓存未到期间。所有请求都去查询数据库,而对数据库CPU和内存造成巨大压力,严重的会造成数据库宕机。从而形成一系列连锁反应,造成整个系统崩溃。
1. 碰到这种情况,一般并发量不是特别多的时候,使用最多的解决方案是加锁排队。
2. 加锁排队只是为了减轻数据库的压力,并没有提高系统吞吐量。假设在高并发下,缓存重建期间key是锁着的,这是过来1000个请求999个都在阻塞的。同样会导致用户等待超时,这是个治标不治本的方法。
还有一个解决办法解决方案是:给每一个缓存数据增加相应的缓存标记,记录缓存的是否失效,如果缓存标记失效,则更新数据缓存。
缓存标记:记录缓存数据是否过期,如果过期会触发通知另外的线程在后台去更新实际key的缓存。
缓存数据:它的过期时间比缓存标记的时间延长1倍,例:标记缓存时间30分钟,数据缓存设置为60分钟。 这样,当缓存标记key过期后,实际缓存还能把旧数据返回给调用端,直到另外的线程在后台更新完成后,才会返回新缓存。
这样做后,就可以一定程度上提高系统吞吐量。
缓存穿透
缓存穿透是指用户查询数据,在数据库没有,自然在缓存中也不会有。这样就导致用户查询的时候,在缓存中找不到,每次都要去数据库再查询一遍,然后返回空。这样请求就绕过缓存直接查数据库,这也是经常提的缓存命中率问题。
解决的办法就是:如果查询数据库也为空,直接设置一个默认值存放到缓存,这样第二次到缓冲中获取就有值了,而不会继续访问数据库,这种办法最简单粗暴。
把空结果,也给缓存起来,这样下次同样的请求就可以直接返回空了,即可以避免当查询的值为空时引起的缓存穿透。同时也可以单独设置个缓存区域存储空值,对要查询的key进行预先校验,然后再放行给后面的正常缓存处理逻辑。
框架知识
遇到我会补充进来的