java实现----sql解析器
更新中!!!!!!
首先我们项目要编写一个小型的dbms。所以我负责编写的sql解析的部分。
所以本文只是记录我学习和编写sql解析器的过程。
----------------------------------------------------------------------------------------------------------------------------------------------
----------------------------------------------------------------------------------------------------------------------------------------------
1.第一阶段:
如果我采用导航模式,可以使用一些split()语句,把sql语句分解出框架部分和内容部分。(这是分析了几个语句的典型模式,采用)“,”和“(”分开的)。针对不同的sql语句,典型的几个select,create,insert,delete都是可以处理的。当然授权,显示都是可以的。但是问题是我必须先让用户选择要执行的步骤是什么,需要用导航,和mysql这种直接输入sql语句,自己去识别的不同。
这个在GitHub中有代码可以参考的。是一个同学的课程设计。我参考了下,他大概思路就是我刚刚说的。
----------------------------------------------------------------------------------------------------------------------------------------------
----------------------------------------------------------------------------------------------------------------------------------------------
2.第二阶段(我就是借鉴他的代码,然后我重新写一个sql_parse)
我们要自己识别,sql语句。所以我网上参考了这个文章。
但是他也明确说,他这个思路是处理单句的sql语句,针对子查询应该是不适用的。
链接:http://www.cnblogs.com/pelephone/articles/sql-parse-single-word.html
他的思路是:
1.预处理。把所有的输入的sql语句,变成标准的形式。处理掉回车,多余的空格部分和特殊字符。规范了大小写。
2.分割成片段:分块+切割;
分块:如何分块?要知道怎么分块,什么是start,body,end;
切割:如何切割?用正则表达式;(具体代码在最后,现在就是知道他的思路是什么)
但是我不知道什么是正则表达式以及它的使用规则也不知道,可以参考:https://www.cnblogs.com/darkterror/p/6474211.html
(而且,如果这么分块到后面是可行并且方便的话,那么编写正则表达式就是一个问题,正则表达式的编写正确将决定分块是否正确)
下面是一个例子,告诉你可以怎么分块:select举例;

----------------------------------------------------------------------------------------------------------------------------------
----------------------------------------------------------------------------------------------------------------------------------------------
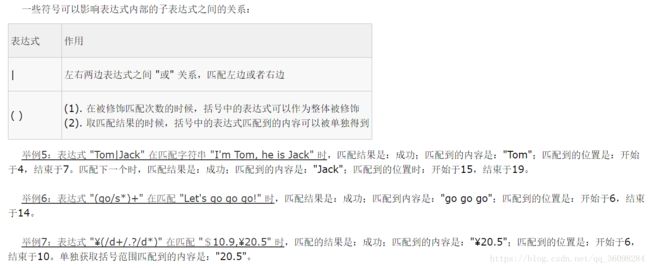
正则表达式的符号使用规则:
https://www.cnblogs.com/darkterror/p/6474211.html
正则表达式中:()和 | 的作用;
----------------------------------------------------------------------------------------------------------------------------------
----------------------------------------------------------------------------------------------------------------------------------------------
3.根据提取中的各个块,我们要其中的body部分。然后对其中的body进行处理,然后给底层传参就可以了。
在没看代码的时候我有两个问题:
第一,如何把一个sql分块成不同的部分;
第二,怎么提取body中的各个有效部分;
下面的代码将依次解答这个问题,并且会粘贴最核心的代码与分析过程;
----------------------------------------------------------------------------------------------------------------------------------------------
----------------------------------------------------------------------------------------------------------------------------------------------
如何把一个sql分块成不同的部分?
分析:segmentRegExp为自己写的正则表达式(用于切割);循环是从sql的第一个位置开始遍历的,一次增加一个index,用segmentRegExp去匹配shortSql,matcher.find()返回的结果是boolean,如果找到了匹配的结果,就进入while中进行赋值;我们的正则表达式是(start)(body)(end)三个不部分的,因此我们的matcher.group(int<=3).
(这是他代码的解决部分,针对这部分我进行了升级和简化。代码再后面)
Pattern pattern=Pattern.compile(segmentRegExp,Pattern.CASE_INSENSITIVE);
for(int i=0;i<=sql.length();i++){
String shortSql=sql.substring(0, i);
//System.out.println(shortSql);
Matcher matcher=pattern.matcher(shortSql);
while(matcher.find()){
start=matcher.group(1);// 片段起始标志start
body=matcher.group(2);// 片段主体body
end=matcher.group(3);// 片段结束标志end
parseBody();
return;
}
}
注意:
1.为什么要从最开始去遍历?
我参考的文章的解释是:因为如果直接用sql与我们的正则表达式segmentRegExp匹配的话,那么他属于贪婪匹配,他会尽可能的往后找,就是找到where后还会继续往后找,看有没有 on | having | groups+by | orders+by | ENDOFSQL等。所以他找到的结果不会在我们想要的where处停止。因此需要从sql的第一个字符处去遍历,这样找到where处就停止了。
但是我测试了他给的代码,结果是并不会停止。就像下面我的图片一样,所以我就去查了正则表达式关于贪婪和不贪婪的问题,我发现他贪婪不是因为我们【|||】中的“|”导致的,而是因为包含重复限定符的时候才会出现贪婪的情况,可是|不算重复的限定符吧?而下面的几个字符才算是重复的限定字符吧?(这也是我的一个疑问。有知道的朋友请留言告知,谢谢!)因此问题应该出在了前面的(.+)上面。
然后我的解决办法是,使用+?符号。(开始我以为只是?的作用)但是后来我查了下,+?是重复一次或者多次,但是是尽可能的少,因此他就可以匹配到where就结束了。
同时,我个人认为,如果加了+?就可以解决贪婪的问题,那么我们是不是不需要在从头开始遍历了,只需要直接匹配就可以了,我改完全部的代码,会回头解释这个问题的。
经过我的测试,完全不用从头遍历,加一个?就会解决贪婪遍历的问题,代码在最后。

2.什么时候会进入到while循环中,也就是matcher.find()什么时候为true?
如果我的正则表达式是(start)(body)(end)那么只有当这三个部分全部被匹配一次的时候,才返回true。如果只匹配了一个start部分是不会显示匹配成功的。
例如:
sql:select name from table_name where id=2 order by name;
segmentRegExp: "(from)(.+)( where | on | having | groups+by | orders+by | ENDOFSQL)"
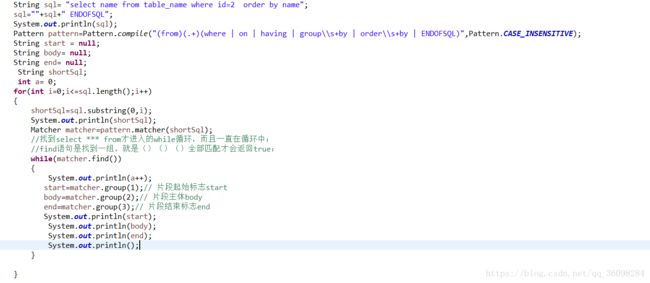
输出结果为:结果是从查到where后就进入到了while循环;
……………………省略…………………………

如果让匹配停止在where就不进行了。我的处理代码和输出结果:
segments.add(new SqlSegment("(from)(.+?)( where | having | group\\s+by | order\\s+by | ENDOFSQL)","(,|s+lefts+joins+|s+rights+joins+|s+inners+joins+)"));
![]()
输出代码是:他会停止在where部分。
输出的分别为,sql语句;start部分;body部分;end部分;

参考:https://blog.csdn.net/wzygis/article/details/43339241
代码优化:

public void parse(String sql)
{
//进行测试(测试分块程序是否正确,该代码为正确的,现要测试一共分块了几次,结果都为什么?
//-----------------------------------------------------------------------------------------------------------
// System.out.println();
// System.out.println("开始对sql进行分块");
// System.out.println("分块");
//-----------------------------------------------------------------------------------------------------------
Pattern pattern=Pattern.compile(segmentRegExp,Pattern.CASE_INSENSITIVE);
Matcher matcher=pattern.matcher(sql);
while(matcher.find())
{
start=matcher.group(1);
body=matcher.group(2);
end=matcher.group(3);
// System.out.println(start);
// System.out.println(body);
// System.out.println(end);
// System.out.println();
parseBody();
}
}
---------------------------------------------------------------------------------------------------------------------------------------------
----------------------------------------------------------------------------------------------------------------------------------------------
matcher.group()介绍:

输出结果:

参考:https://www.cnblogs.com/jsStudyjj/p/6145623.html
----------------------------------------------------------------------------------------------------------------------------------------------
----------------------------------------------------------------------------------------------------------------------------------------------
提取出的body部分怎么处理呢?
就是根据正则表达式把body部分分开,分开的部分放在List中。我把start添加到bodyPiece中是因为,我要判断类似select这种语句后面是否有where这种可选语句,有的话有什么,因此我需要保留start部分,然后传给后面。
代码部分:

/** *//**
* 解析body部分
*
*/
private void parseBody()
{
//System.out.println("分body");
List ls=new ArrayList();
Pattern p = Pattern.compile(bodySplitPattern,Pattern.CASE_INSENSITIVE);
// 先清除掉前后空格
body=body.trim();
Matcher m = p.matcher(body);
StringBuffer sb = new StringBuffer();
boolean result = m.find();
//---------------------------------------------------------------------------------------------------------------------------
//测试下group(0)是什么,他怎么进行替换的?
// if(result)
// {
// System.out.println(m.group(0));
// }
//---------------------------------------------------------------------------------------------------------------------------
while (result)
{
m.appendReplacement(sb,Crlf);
result = m.find();
}
m.appendTail(sb);
//---------------------------------------------------------------------------------------------------------------------------
// System.out.println(sb.toString());
//---------------------------------------------------------------------------------------------------------------------------
// 再按空格断行
ls.add(start);
String[] arr=sb.toString().split("[|]");
int arrLength=arr.length;
for(int i=0;i 下面粘贴代码:
这是目录:
SqlSegment.java
package com.sitinspring.common.sqlparser.single;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/** *//**
* Sql语句片段
* @since 2018-4-4
*/
public class SqlSegment {
private static final String Crlf = "|";
@SuppressWarnings("unused")
private static final String FourSpace = " ";
/** *//**
* Sql语句片段开头部分
*/
private String start;
/** *//**
* Sql语句片段中间部分
*/
private String body;
/** *//**
* Sql语句片段结束部分
*/
private String end;
/** *//**
* 用于分割中间部分的正则表达式
*/
private String bodySplitPattern;
/** *//**
* 表示片段的正则表达式
*/
private String segmentRegExp;
/** *//**
* 分割后的Body小片段
*/
private List bodyPieces;
/** *//**
* 构造函数
* @param segmentRegExp 表示这个Sql片段的正则表达式
* @param bodySplitPattern 用于分割body的正则表达式
*/
public SqlSegment(String segmentRegExp,String bodySplitPattern)
{
start="";
body="";
end="";
this.segmentRegExp=segmentRegExp;
this.bodySplitPattern=bodySplitPattern;
this.bodyPieces = new ArrayList();
}
/** *//**
* 从sql中查找符合segmentRegExp的部分,并赋值到start,body,end等三个属性中
* @param sql
*/
public void parse(String sql)
{
//进行测试(测试分块程序是否正确,该代码为正确的,现要测试一共分块了几次,结果都为什么?
//-----------------------------------------------------------------------------------------------------------
// System.out.println();
// System.out.println("开始对sql进行分块");
// System.out.println("分块");
//-----------------------------------------------------------------------------------------------------------
Pattern pattern=Pattern.compile(segmentRegExp,Pattern.CASE_INSENSITIVE);
Matcher matcher=pattern.matcher(sql);
while(matcher.find())
{
start=matcher.group(1);
body=matcher.group(2);
end=matcher.group(3);
// System.out.println(start);
// System.out.println(body);
// System.out.println(end);
// System.out.println();
parseBody();
}
//根本不需要通过遍历sql来检测分块部分。
// for(int i=0;i<=sql.length();i++)
// {
// String shortSql=sql.substring(0, i);
// //System.out.println(shortSql);
// Matcher matcher=pattern.matcher(shortSql);
// while(matcher.find())
// {
// start=matcher.group(1);
// body=matcher.group(2);
// end=matcher.group(3);
////-----------------------------------------------------------------------------------------------------------
//// System.out.println(start);
//// System.out.println(body);
//// System.out.println(end);
//// System.out.println();
////-----------------------------------------------------------------------------------------------------------
//
// //调用解析body部分
// parseBody();
//
//
// }
//
// }
}
/** *//**
* 解析body部分
*
*/
private void parseBody()
{
//System.out.println("分body");
List ls=new ArrayList();
Pattern p = Pattern.compile(bodySplitPattern,Pattern.CASE_INSENSITIVE);
// 先清除掉前后空格
body=body.trim();
Matcher m = p.matcher(body);
StringBuffer sb = new StringBuffer();
boolean result = m.find();
//---------------------------------------------------------------------------------------------------------------------------
//测试下group(0)是什么,他怎么进行替换的?
// if(result)
// {
// System.out.println(m.group(0));
// }
//---------------------------------------------------------------------------------------------------------------------------
while (result)
{
m.appendReplacement(sb,Crlf);
result = m.find();
}
m.appendTail(sb);
//---------------------------------------------------------------------------------------------------------------------------
// System.out.println(sb.toString());
//---------------------------------------------------------------------------------------------------------------------------
// 再按空格断行
ls.add(start);
String[] arr=sb.toString().split("[|]");
int arrLength=arr.length;
for(int i=0;i getBodyPieces() {
return bodyPieces;
}
public void setBodyPieces(List bodyPieces) {
this.bodyPieces = bodyPieces;
}
} BaseSingleSqlParser:package com.sitinspring.common.sqlparser.single;
import java.util.ArrayList;
import java.util.List;
public abstract class BaseSingleSqlParser {
//原始Sql语句
protected String originalSql;
//Sql语句片段
protected List segments;
/** *//**
* 构造函数,传入原始Sql语句,进行劈分。
* @param originalSql
*/
public BaseSingleSqlParser(String originalSql)
{
//System.out.println("调用了BaseSingleSqlParser的构造函数");
this.originalSql=originalSql;
segments=new ArrayList();
initializeSegments();
//splitSql2Segment();
}
/** *//**
* 初始化segments,强制子类实现
*
*/
protected abstract void initializeSegments();
/** *//**
* 将originalSql劈分成一个个片段
*
* @return */
protected List> splitSql2Segment()
{
List> list=new ArrayList>();
//System.out.println("调用了BaseSingleSqlParser的splitSql2Segment方法,用于分割sql为不同的模块");
for(SqlSegment sqlSegment:segments) // int[] aaa = 1,2,3; int a:aaa
{
sqlSegment.parse(originalSql);
list.add(sqlSegment.getBodyPieces());
}
return list;
}
/** *//**
* 得到解析完毕的Sql语句
* @return
*/
public String getParsedSql()
{
StringBuffer sb=new StringBuffer();
for(SqlSegment sqlSegment:segments)
{
sb.append(sqlSegment.getParsedSqlSegment()+"n");
}
String retval=sb.toString().replaceAll("n+", "n");
return retval;
}
}
SingleSqlParserFactory:
package com.sitinspring.common.sqlparser.single;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
//test-success
// throws Exception
public class SingleSqlParserFactory
{
public static List> generateParser(String sql)
{
BaseSingleSqlParser tmp = null;
if(contains(sql,"(insert into)(.+)(select)(.+)(from)(.+)"))
{
System.out.println("insert_select");
tmp = new InsertSelectSqlParser(sql);
//return tmp.splitSql2Segment();
}
else if(contains(sql,"(select)(.+)(from)(.+)"))
{
System.out.println("select");
tmp = new SelectSqlParser(sql);
//System.out.println("初始化SelectSqlParser结束");
}
else if(contains(sql,"(delete from)(.+)"))
{
System.out.println("delete");
tmp = new DeleteSqlParser(sql);
//return new DeleteSqlParser(sql);
}
else if(contains(sql,"(update)(.+)(set)(.+)"))
{
System.out.println("update");
tmp = new UpdateSqlParser(sql);
//return new UpdateSqlParser(sql);
}
else if(contains(sql,"(insert into)(.+)(values)(.+)"))
{
System.out.println("insert");
tmp = new InsertSqlParser(sql);
//return new InsertSqlParser(sql);
}
else if(contains(sql,"(create table)(.+)"))
{
System.out.println("create table");
// return new InsertSqlParser(sql);
}
else if(contains(sql,"(create database)(.+)"))
{
System.out.println("create database");
// return new InsertSqlParser(sql);
}
else if(contains(sql,"(show databases)"))
{
System.out.println("show databases");
// return new InsertSqlParser(sql);
}
else if(contains(sql,"(use)(.+)"))
{
System.out.println("use");
// return new InsertSqlParser(sql);
}
else
{
System.out.println("Input errors, please re-enter");
}
//sql=sql.replaceAll("ENDSQL", "");
// throw new Exception(sql.replaceAll("ENDOFSQL", ""));
//return null;
return tmp.splitSql2Segment();
}
/** *//**
* 看word是否在lineText中存在,支持正则表达式
* @param sql:要解析的sql语句
* @param regExp:正则表达式
* @return
*/
private static boolean contains(String sql,String regExp)
{
Pattern pattern=Pattern.compile(regExp,Pattern.CASE_INSENSITIVE);
Matcher matcher=pattern.matcher(sql);
return matcher.find();
}
}
DeleteSqlParser.java:
package com.sitinspring.common.sqlparser.single;
/** *//**
*
* 单句删除语句解析器
*/
//正确
public class DeleteSqlParser extends BaseSingleSqlParser
{
public DeleteSqlParser(String originalSql) {
super(originalSql);
}
//delete from table_name where ();
@Override
protected void initializeSegments() {
//System.out.println("调用了DeleteSqlParser的initializeSegments方法");
segments.add(new SqlSegment("(delete from)(.+)( where | ENDOFSQL)","[,]"));
segments.add(new SqlSegment("(where)(.+)( ENDOFSQL)","(and|or)"));
}
}
UpdateSqlParser.java:
package com.sitinspring.common.sqlparser.single;
//正确
public class UpdateSqlParser extends BaseSingleSqlParser{
public UpdateSqlParser(String originalSql) {
super(originalSql);
}
//update(table_name) set (key = value) where();
@Override
protected void initializeSegments() {
segments.add(new SqlSegment("(update)(.+)(set)","[,]"));
segments.add(new SqlSegment("(set)(.+?)( where | ENDOFSQL)","[,]"));
segments.add(new SqlSegment("(where)(.+)(ENDOFSQL)","(and|or)"));
}
}
SelectSqlParser.java
package com.sitinspring.common.sqlparser.single;
/** *//**
*
* 单句查询语句解析器
*/
//正确
public class SelectSqlParser extends BaseSingleSqlParser{
public SelectSqlParser(String originalSql)
{
super(originalSql);
}
@Override
protected void initializeSegments()
{
System.out.println("调用了SelectSqlParser的initializeSegments方法,用于初始化正则表达式语句");
segments.add(new SqlSegment("(select)(.+)(from)","[,]"));
segments.add(new SqlSegment("(from)(.+?)(where |group\\s+by|having|order\\s+by | ENDOFSQL)","(,|s+lefts+joins+|s+rights+joins+|s+inners+joins+)"));
segments.add(new SqlSegment("(where)(.+?)(group\\s+by |having| order\\s+by | ENDOFSQL)","(and|or)"));
segments.add(new SqlSegment("(group\\s+by)(.+?)(having|order\\s+by| ENDOFSQL)","[,]"));
segments.add(new SqlSegment("(having)(.+?)(order\\s+by| ENDOFSQL)","(and|or)"));
segments.add(new SqlSegment("(order\\s+by)(.+)( ENDOFSQL)","[,]"));
}
}
InsertSelectSqlParser.java
package com.sitinspring.common.sqlparser.single;
/** *//**
*
* 单句查询插入语句解析器
*/
//正确-test
public class InsertSelectSqlParser extends BaseSingleSqlParser {
public InsertSelectSqlParser(String originalSql) {
super(originalSql);
}
//select () from table_name where () order by () having () group by () limit();
@Override
protected void initializeSegments() {
segments.add(new SqlSegment("(insert into)(.+)( select )","[,]"));
segments.add(new SqlSegment("(select)(.+)(from)","[,]"));
segments.add(new SqlSegment("(from)(.+)( where | on | having | groups+by | orders+by | ENDOFSQL)","(,|s+lefts+joins+|s+rights+joins+|s+inners+joins+)"));
segments.add(new SqlSegment("(where|on|having)(.+)( groups+by | orders+by | ENDOFSQL)","(and|or)"));
segments.add(new SqlSegment("(groups+by)(.+)( orders+by| ENDOFSQL)","[,]"));
segments.add(new SqlSegment("(orders+by)(.+)( ENDOFSQL)","[,]"));
}
}
InsertSqlParser.java
package com.sitinspring.common.sqlparser.single;
/** *//**
*
* 单句插入语句解析器
*/
//correct-test
public class InsertSqlParser extends BaseSingleSqlParser{
public InsertSqlParser(String originalSql) {
super(originalSql);
}
//insert into table_name (name,age,sex) values ("小明","28","女");
@Override
protected void initializeSegments() {
segments.add(new SqlSegment("(insert into)(.+?)([(])","[,]"));
segments.add(new SqlSegment("([(])(.+?)([)] values [(])","[,]"));
segments.add(new SqlSegment("([)] values [(])(.+)([)] ENDOFSQL)","[,]"));
// values
}
public String getParsedSql()
{
String retval=super.getParsedSql();
retval=retval+")";
return retval;
}
}
Test.java 主类
package com.sitinspring.common.sqlparser.single;
import java.util.ArrayList;
import java.util.List;
import java.util.Scanner;
public class Test {
public static void main (String arg[])
{
System.out.println("欢迎您登录登录,请开始使用。");
/*
* 应该有一个验证管理员和用户的功能。
*/
System.out.println("请出入sql语句");
boolean temp = true;
while(temp)
{
@SuppressWarnings("resource")
Scanner input = new Scanner(System.in);
String sql = input.nextLine();
/*
* 预处理:获得语句;
* 处理前后空格;
* 变小写;
* 处理中间多余的空格回车和特殊字符;
* 在末尾加特殊符号;
* 处理掉最后的;
*/
//处理分行输入的问题,就是读;号才停止;
while(sql.lastIndexOf(";")!=sql.length()-1){
sql = sql+" "+input.nextLine();
}
sql = sql.trim();
sql=sql.toLowerCase();
sql=sql.replaceAll("\\s+", " ");
sql = sql.substring(0, sql.lastIndexOf(";"));
sql=""+sql+" ENDOFSQL";
System.out.println(sql);
/*
* 结束输入判断
*/
// Pattern pattern=Pattern.compile("(quit)");
// Matcher matcher=pattern.matcher(sql);
// System.out.println(matcher.find());
@SuppressWarnings("unused")
List> parameter_list=new ArrayList>();
if(sql.equals("quit"))
{
temp = false;
}
else
{
//System.out.println("准备执行SingleSqlParserFactory.generateParser函数");
/*
* 工厂类判断调用什么语句的正则表达分割
*/
parameter_list = SingleSqlParserFactory.generateParser(sql);
//----------------------------------------------------------------------------------------------------------------
System.out.println("执行结束SingleSqlParserFactory.generateParser函数");
for(int i = 0;i < parameter_list.size();i++)
{
System.out.println(parameter_list.get(i));
}
// System.out.println();
//
// List test = new ArrayList();
// test = parameter_list.get(2);
//
// for(int i = 0;i < test.size();i++)
// {
// String r = test.get(i);
// System.out.println(r.trim());
// }
//----------------------------------------------------------------------------------------------------------------
}
}
}
} 现在,在我完成了sql的编写好,我的下一个问题是,如果方便的传参然后调用每个功能模块!!!!