redis哨兵机制在集群中的应用
一、数据存放的2种方式
假设来了一批数据,怎么放入redis集群?
1.分片
2.镜像全量(lvs后面放的就是镜像全量)
对于redis来讲,镜像全量这种方式无效。比如一台节点内存4G,3台也是4G,6台也还是4G。因为镜像的方式,要保证所有节点的数据保持一致。镜像全量的好处:高可用,不怕谁挂了;坏处:占用资源,没有扩展能力。
分片:3台节点,4G。分片方式,最多可以存12G,分摊到3台节点上。但是也有问题,他没有备,怕挂。
又想发挥镜像全量那种高可用的能力,又想要分片的那种横向扩展的存储能力。咋办?把这两种技术给它结合起来!每个节点既有备,又能横向扩展。
二、单机的两个问题
单点故障和单点瓶颈。
单点故障,整个集群宕机了,那没辙了。
单点瓶颈:数据量已经超出了我自己的处理能力了,超过阈值了。
单兵作战风险太高,所以要“报团取暖”,一台变多台,以集群的方式来面对庞大的数据量。有了集群,就有了两点好处:
- 1.一台服务器变多台,保障了可用性。
- 2.避免了网络分区的脑裂问题,过半机制保障了最终一致性。
三、过半机制
一个redis集群3个节点,在对外提供服务之前,先其中2个,两两之间相互通信保持心跳,保持你们的数据的一致性。然后第3个节点先向那2个节点同步数据,然后也对外提供数据。这种模式:先两两通信组成势力范围;万一第3个节点无法和别的节点通信,就把节点3状态改成shutdown状态,另外2个节点shutup状态对外提供服务。(如果是4个节点,相互两两组成2组势力范围,有可能组内统一口径,组间说法不一,也会发生脑裂。所以这也是redis集群节点个数采用奇数的原因)
无主模型:每个节点各自为政,自己组成自己的势力范围。碰见事了,就来回扯皮,效率低下
那么,有了问题,有了大致的解决思路,该如何优美的使用呢?
四、redis主从复制Replication
一个Redis服务可以有多个该服务的复制品,这个Redis服务称为Master,其他复制品称为Slaves
只要网络连接正常,Master会一直将自己的数据更新同步给Slaves,保持主从同步
只有Master可以执行写命令,Slaves只能执行读命令
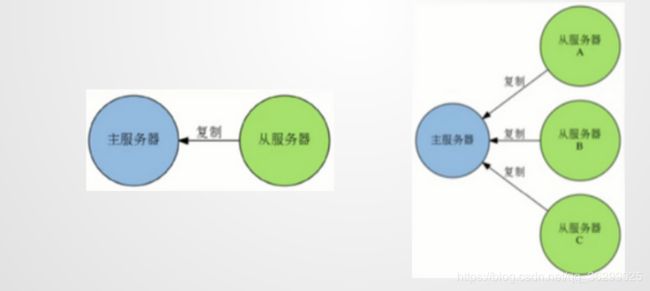 Master可以CRUD所有操作,Slaves只能查询。从的数据来源于主的同步。有问题,主单节点有单点故障风险,得做HA高可用。主从数据如何同步?主从复制的时候,redis并没有采用无主模式来搞,而是采用异步的方式(主人把任务交给仆人了,剩下的我不管了),有可能slaves提供不同的版本,但这种情况非常少,因为这类情况产生原因在于网络,这是运维该关心的事了。
Master可以CRUD所有操作,Slaves只能查询。从的数据来源于主的同步。有问题,主单节点有单点故障风险,得做HA高可用。主从数据如何同步?主从复制的时候,redis并没有采用无主模式来搞,而是采用异步的方式(主人把任务交给仆人了,剩下的我不管了),有可能slaves提供不同的版本,但这种情况非常少,因为这类情况产生原因在于网络,这是运维该关心的事了。
五、Master的高可用—哨兵机制
高可用 Sentinel:
- 官方提供的高可用方案,可以用它管理多个Redis服务实例
- 编译后产生redis-sentinel程序文件
- Redis Sentinel是一个分布式系统,可以在一个架构中运行多个Sentinel进程
sentinel 哨兵,负责监控redis集群的健康状况。如果发现Master挂了,哨兵立刻把一个slave提升为master(zookeeper的机制要比哨兵更先进,他俩都源于paxos论文)。redis最初认为自己都是主,得手动规定它们的身份:
格式:redis-server --slaveof ,配置当前服务称为某Redis服务的Slave
# redis-server --port 6380 #以主的身份启动
# redis-server --port 6380 --slaveof 127.0.0.1 6379 #主是6379,slave是6380
当然,可以改变主从身份:
SLAVEOF host port命令,将当前服务器状态从Master修改为别的服务器的Slave
redis > SLAVEOF 192.168.1.1 6379 #将服务器转换为Slave
redis > SLAVEOF NO ONE #将服务器重新恢复到Master,不会丢弃已同步数据
配置方式:启动时,服务器读取配置文件,并自动成为指定服务器的从服务器
slaveof
slaveof 127.0.0.1 6379
哨兵的工作内容
1.监控 Monitoring
- Sentinel会不断检查Master和Slaves是否正常
- 每一个Sentinel可以监控任意多个Master和该Master下的Slaves
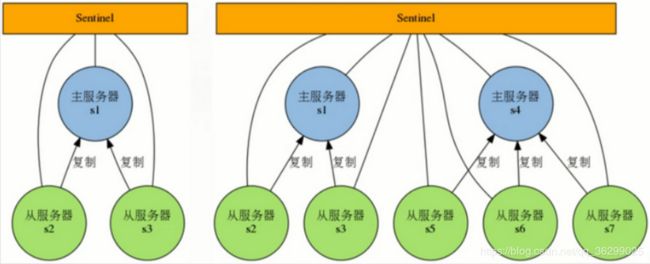 2.Sentinel网络
2.Sentinel网络
监控同一个Master的Sentinel会自动连接,组成一个分布式的Sentinel网络,互相通信并交换彼此关于被监视服务器的信息
哨兵也怕挂,下图中3个Sentinel监控着S1和它的2个Slave:
 哨兵集群,哨兵之间也要进行通信。哨兵的工作机制是无主模型。无主模型,就有可能造成脑裂。哨兵1也有可能误判,就会造成数据的混乱。为了解决脑裂,就需要投票、过半机制。
哨兵集群,哨兵之间也要进行通信。哨兵的工作机制是无主模型。无主模型,就有可能造成脑裂。哨兵1也有可能误判,就会造成数据的混乱。为了解决脑裂,就需要投票、过半机制。
3.服务器下线
当一个sentinel认为被监视的服务器已经下线时,它会向网络中的其他Sentinel进行确认,判断该服务器是否真的已经下线
如果下线的服务器为主服务器,那么sentinel网络将对下线主服务器进行自动故障转移,通过将下线主服务器的某个从服务器提升为新的主服务器,并让其从服务器转为复制新的主服务器,以此来让系统重新回到上线的状态
六、搭建redis伪分布式集群
1.解压redis包到指定目录
2.配置redis环境变量:
export REDIS_HOME=/opt/software/redis
export PATH=$PATH:$JAVA_HOME/bin:xxxxxx$REDIS_HOME/bin
3.执行/root/software/redis-2.8.18/utils目录下的命令:./install_server.sh
Installation successful!
[root@node1 utils]# ps aux | grep redis
root 4511 0.1 0.3 137384 7436 ? Ssl 18:48 0:01 /opt/software/redis/bin/redis-server *:6379
root 4526 0.0 0.0 103332 908 pts/0 S+ 19:11 0:00 grep redis
[root@node1 utils]#
- redis-cli连接默认的6379:
[root@node1 utils]# redis-cli
127.0.0.1:6379> ping
PONG
127.0.0.1:6379> set hello world
OK
127.0.0.1:6379> get hello
"world"
127.0.0.1:6379> quit
[root@node1 utils]# redis-cli
127.0.0.1:6379> set hello "连接"
OK
127.0.0.1:6379> get hello
"\xe8\xbf\x9e\xe6\x8e\xa5"
127.0.0.1:6379> quit
[root@node1 utils]# redis-cli --raw
127.0.0.1:6379> get hello
连接
127.0.0.1:6379>
[root@node1 utils]#
5.查看帮助
redis-server -h
家目录创建redis文件夹,新创建3个端口文件:6380、6381、6382
在6380中以主的身份启动redis:
[root@node1 ~]# redis-server --port 6380
新打开一个标签页面进入6381并启动从:
redis-server --port 6381 --slaveof 127.0.0.1 6380
新打开一个标签页面进入6382并启动从:
redis-server --port 6382 --slaveof 127.0.0.1 6380
新开一个标签页客户端登录主节点验证:
[root@node1 ~]# redis-cli -p 6380
127.0.0.1:6380> set k1 5
OK
127.0.0.1:6380> get k1
"5"
新开一个客户端页面登录6381slave节点,就能拿到主节点上设置的值。slave只能读,不能写:
[root@node1 ~]# redis-cli -p 6381
127.0.0.1:6381> get k1
"5"
127.0.0.1:6381> set k2
(error) ERR wrong number of arguments for 'set' command
如果主挂了,就选出一个slave变成主:
在主上ctrl+c停掉主,两个slave立刻找不到主了,群龙无首。
手动调一下,在从的一个上面执行,立刻就会有一个新的主了,6381就脱离了slave身份
127.0.0.1:6381> SLAVEOF no one
OK
此时虽然6381自己篡权做主人了,但是6382不会主动认他。如果想让6382重新认主,还得给它重新设置一下。手动控制,不太靠谱也不太安全,最好搞成自动的形式,这项工作,就是由哨兵来完成的。
Sentinel 配置文件
1.至少包含一个监控配置选项,用于指定被监控Master的相关信息
2.Sentinel monitor,例如sentinel monitor mymaster 127.0.0.1 6379 2监视mymaster的主服务器,服务器ip和端口,将这个主服务器判断为下线失效至少需要2个Sentinel同意,多数Sentinel同意才会执行故障转移
3.Sentinel会根据Master的配置自动发现Master的Slaves
4.Sentinel默认端口号为26379
哨兵配置使用
1.要想随时运行哨兵,就需要将其拷贝到bin下:
[root@node1 src]# cp /root/software/redis-2.8.18/src/redis-sentinel /opt/software/redis/bin/
2.创建sent目录放配置文件:
s1.conf
port 23680
sentinel monitor husky 127.0.0.1 6380 2
s2.conf
port 23681
sentinel monitor husky 127.0.0.1 6380 2
s3.conf
port 23682
sentinel monitor husky 127.0.0.1 6380 2
跑起来3个节点:
[root@node1 ~]# redis-server --port 6380
[root@node1 ~]# redis-server --port 6381 --slaveof 127.0.0.1 6380
[root@node1 ~]# redis-server --port 6382 --slaveof 127.0.0.1 6380
另启动3个节点跑哨兵:
[root@node1 sent]# redis-sentinel s1.conf
[root@node1 sent]# redis-sentinel s2.conf
[root@node1 sent]# redis-sentinel s3.conf
测试
新开3个页面测试:
[root@node1 ~]# redis-cli -p 6380
127.0.0.1:6380> set k1 5
OK
127.0.0.1:6380> get k1
"5"
使6380的server挂掉,马上另外两个就找不到了。经历过一个短暂的下线后,哨兵就起作用了,使6381成为了新的主:
[1683] 20 Jun 19:21:57.701 # +switch-master husky 127.0.0.1 6380 127.0.0.1 6381
[1683] 20 Jun 19:21:57.701 * +slave slave 127.0.0.1:6382 127.0.0.1 6382 @ husky 127.0.0.1 6381
[1683] 20 Jun 19:21:57.709 * +slave slave 127.0.0.1:6380 127.0.0.1 6380 @ husky 127.0.0.1 6381
之后,就算6380重新恢复服务,也只能作为slave了。
七、Sentinel 总结
1.主从复制,解决了读请求的分担,从节点下线,会使得读请求能力有所下降
2.Master只有一个,写请求单点问题
3.Sentinel会在Master下线后自动执行Failover操作,提升一台Slave为Master,并让其他Slaves重新成为新Master的Slaves
4.主从复制+哨兵Sentinel只解决了读性能和高可用问题,但是没有解决写性能问题
八、问题引出
主从对写压力没有分担(如果想横向扩展存储能力?)
解决思路就是,使用多个节点分担,将写请求分散到不同节点处理
分片Sharding:多节点分担的思路就是关系型数据库处理大表的水平切分思路
解决:
Twitter开发Twemproxy,代理用户的读写请求
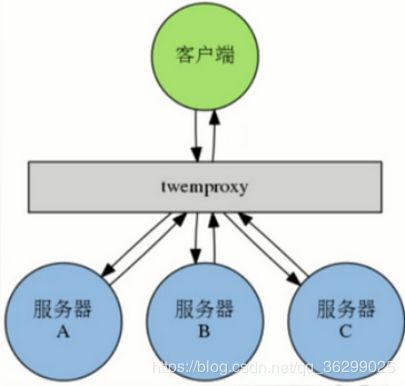
加了twemproxy路由代理层,对key做hash,%服务器数。
1.Twitter开发的代理服务器,他兼容Redis和Memcached,允许用户将多个redis服务器添加到一个服务器池(pool)里面,并通过用户选择的散列函数和分布函数,将来自客户端的命令请求分发给服务器池中的各个服务器
2.通过使用twemproxy我们可以将数据库分片到多台redis服务器上面,并使用这些服务器来分担系统压力以及数据库容量:在服务器硬件条件相同的情况下,对于一个包含N台redis服务器的池来说,池中每台平均1/N的客户端命令请求
3.向池里添加更多服务器可以线性的扩展系统处理命令请求的能力,以及系统能够保存的数据量
这结构也有问题,会发生数据倾斜。有可能大部分的key都被%到了某一台服务器上,于是就造成了数据倾斜。
另外,路由代理层就只有一个,面临单点问题。很明显,路由也要做高可用。还有,hash是稳定算法,随着业务量增加,数据量也增大,单点对处理有瓶颈,有阈值,因此服务器要增加,蝴蝶效应,算法也得跟着改,原来%3现在可能要%5,数据还要重新分配。