Java爬虫简单教程
窥探这个网站已经很久了https://www.mzitu.com/ 最近弄了下爬虫,于是想把这个网站的图片给爬下来。
1.用到jsoup来解析html
2.这个网站有反爬机制,需要简单的爬床伪装
3.要用到递归,我只把页面展示的部分给爬下来了,具体里面的内容需要另外递归,到时候再做交流
需要引入的包,下面最主要的是两个核心包,其他包可以要可不要,比如那个mysql包,我之前爬取了招聘网站吧里面的职位信息都存到了数据库,所以我需要。这个根据你们情况而定。
com.alibaba
fastjson
1.2.47
ch.hsr
geohash
1.3.0
<这个是核心包,用于http连接的>
commons-httpclient
commons-httpclient
3.1
<这个核心包是用来解析HTML的>
org.jsoup
jsoup
1.8.3
org.slf4j
slf4j-log4j12
1.7.25
test
mysql
mysql-connector-java
5.0.8
包导入后,就是开整了,先看一下我的项目结构

其中 controllerImg.java 才是爬取妹子网站的main函数。其他dao和entity都是我之前爬取招聘网站用到的,这里就不做探讨,哎呀,也就是创建一个实体对象将职位存进去,然后通过JDBC再存到数据库。
现在我们来看看 controllerImg.java 里面的代码,作为一个合格的程序员我把导入的包也加进来了,复制即可用所见即所得。
import java.io.BufferedInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.net.HttpURLConnection;
import java.net.MalformedURLException;
import java.net.URL;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Random;
import java.util.UUID;
import org.jsoup.Connection;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import com.nf.entity.JobBean;
public class ControllerImg {
private static int count = 0;
//将地址传入解析器
public static Document getDom(String URL){
try {
URL url = new URL(URL);
Connection connection = Jsoup.connect(URL);
Document document = connection.get();
return document;
} catch (MalformedURLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return null;
}
//获得下一页,然后递归调用地址
public void getNextPageInfor(Document document){
//选择到下一页标签的class名 .bk
String URL = null;
Elements pageElement = document.select(".postlist").select(".nav-links").select("a");
for (Element element : pageElement) {
System.out.println(element);
if("下一页»".equals(element.text())) {
URL = element.attr("href");
System.err.println(URL);
}
}
if(URL==null){
return;
}
//放入下一页
Document nextPage = getDom(URL);
List list = getPageInfor(nextPage);
System.out.println("---------------"+(++count)+"-------------");
for (JobBean jobBean : list) {
System.out.println(jobBean);
}
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
getNextPageInfor(nextPage);
}
public static List getPageInfor(Document document){
Random r = new Random();
//伪装的游览器,这里越多越好
String[] ua = {"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:46.0) Gecko/20100101 Firefox/46.0",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.87 Safari/537.36 OPR/37.0.2178.32",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.57.2 (KHTML, like Gecko) Version/5.1.7 Safari/534.57.2",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2486.0 Safari/537.36 Edge/13.10586",
"Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko",
"Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; WOW64; Trident/6.0)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0)",
"Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0)",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.106 BIDUBrowser/8.3 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.80 Safari/537.36 Core/1.47.277.400 QQBrowser/9.4.7658.400",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.116 UBrowser/5.6.12150.8 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 Safari/537.36 SE 2.X MetaSr 1.0",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.116 Safari/537.36 TheWorld 7",
"Mozilla/5.0 (Windows NT 6.1; W…) Gecko/20100101 Firefox/60.0"};
int i = r.nextInt(14);
//输入输入流
FileOutputStream outputStream = null;
InputStream inputStream = null;
BufferedInputStream bis = null;
List list = new ArrayList();
Elements elements = document.select("#pins li");
elements.remove(0);
for (Element element : elements) {
Elements needElements = element.select("a");
//选取图片
String messageUrl = needElements.get(0).select("img[src]").attr("data-original");
//每张图片生成UUID
String outImage = UUID.randomUUID().toString().replaceAll("-", "") + ".jpg";
try {
//创建链接
URL imgUrl = new URL(messageUrl);
HttpURLConnection connection = (HttpURLConnection) imgUrl.openConnection();
//伪装请求,绕过反爬
connection.setRequestProperty("User-Agent", ua[i]);
//添加来源
connection.setRequestProperty("Referer","http://www.mzitu.com/");
//添加地址解析
connection.setRequestProperty("Host","i.meizitu.net");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
//获取输入流
inputStream = connection.getInputStream();
//将输入流信息放入缓冲提升读写速度
bis = new BufferedInputStream(inputStream);
//获取字节数;
byte[] buf = new byte[1024];
//生产文件
outputStream = new FileOutputStream("D:\\meizitu\\"+outImage); int size = 0;
while ((size =bis.read(buf)) != -1) {
outputStream.write(buf, 0, size);
}
//刷新文件流
outputStream.flush();
}catch (MalformedURLException e) {
e.printStackTrace();
}catch (IOException e) {
e.printStackTrace();
}finally {
try {
if(outputStream != null){
outputStream.close();
}
if(bis != null) {
bis.close();
}
if(inputStream != null) {
inputStream.close();
}
} catch(Exception e) {
e.printStackTrace();
}
}
//list.add(jobBean);
}
return list;
}
public static void main(String[] args){
ControllerImg c = new ControllerImg();
String URL = "https://www.mzitu.com/xinggan/";
Document document = getDom(URL);
List list = getPageInfor(document);
System.out.println("---------------"+(++count)+"-------------");
for (JobBean jobBean : list) {
System.out.println(jobBean);
}
c.getNextPageInfor(document);
}
}
接下来解析这个代码,妹子离我们不远了 getDom(String URL)方法
//将地址传入解析器
public static Document getDom(String URL){
try {
URL url = new URL(URL);
Connection connection = Jsoup.connect(URL);
Document document = connection.get();
return document;
} catch (MalformedURLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return null;
}这个是对起始页码的URL转Document对象做了个简单的封装,把目标网址传进来,然后通过Jsoup返回docuemt对象。
docment对象里面装的HTML,非常强大,下面介绍怎么分析页面
页面递归,当第一个页面解析完后,需要进入到下一个页面 getNextPageInfor(Document document)方法
//获得下一页,然后递归调用地址
public void getNextPageInfor(Document document){
String URL = null;
//选取整个分页栏的 a 标签
Elements pageElement = document.select(".postlist").select(".nav-links").select("a");
//a 标签肯定是多个,所有只要找到某个a标签的text()是下一页就能那到里面的URL
for (Element element : pageElement) {
System.out.println(element);
if("下一页»".equals(element.text())) {
URL = element.attr("href");
System.err.println(URL);
}
}
if(URL==null){
return;
}
//放入下一页
Document nextPage = getDom(URL);
List list = getPageInfor(nextPage);
System.out.println("---------------"+(++count)+"-------------");
for (JobBean jobBean : list) {
System.out.println(jobBean);
}
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
getNextPageInfor(nextPage);
} 具体注释也已经写到代码里的,上分析图!!!
解释一下为什么要递归
首先我们看妹子图的地址栏
https://www.mzitu.com/xinggan/page/2/ 这是性感妹子专栏的第二页
https://www.mzitu.com/xinggan/page/3/ 第三页
https://www.mzitu.com/xinggan/page/4/ 第四页
每一页只有最后一个参数在变,表示那个参数就是页码参数
![]()
然后这个标签里面就有下一页的参数。所有我们只需要做个递归模拟点击下一页的功能即可

锤开F12就能看到具体的HTML内容了,然后通过游览器的选择标签功能选到分页栏,然后就会看到是一个大的DIV包裹着许多小DIV,这里我们就能看到我在上面分析到的很多的 a 标签,这里的每个 a 标签对应的有分页地址,我们只需要找到他的内容时
下一页 的做对比就行。对比在上面的代码里,仔细看。
通过递归我吗就拿到每一页的内容了,然后我需要再来一个方法来解析每一页里面的元素 getPageInfor(Document document)方法
public static List getPageInfor(Document document){
Random r = new Random();
String[] ua = {"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:46.0) Gecko/20100101 Firefox/46.0",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.87 Safari/537.36 OPR/37.0.2178.32",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.57.2 (KHTML, like Gecko) Version/5.1.7 Safari/534.57.2",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2486.0 Safari/537.36 Edge/13.10586",
"Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko",
"Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; WOW64; Trident/6.0)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0)",
"Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0)",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.106 BIDUBrowser/8.3 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.80 Safari/537.36 Core/1.47.277.400 QQBrowser/9.4.7658.400",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.116 UBrowser/5.6.12150.8 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 Safari/537.36 SE 2.X MetaSr 1.0",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.116 Safari/537.36 TheWorld 7",
"Mozilla/5.0 (Windows NT 6.1; W…) Gecko/20100101 Firefox/60.0"};
int i = r.nextInt(14);
//输入输入流
FileOutputStream outputStream = null;
InputStream inputStream = null;
BufferedInputStream bis = null;
List list = new ArrayList();
Elements elements = document.select("#pins li");
elements.remove(0);
for (Element element : elements) {
Elements needElements = element.select("a");
//选取图片
String messageUrl = needElements.get(0).select("img[src]").attr("data-original");
//每张图片生成UUID
String outImage = UUID.randomUUID().toString().replaceAll("-", "") + ".jpg";
try {
//创建链接
URL imgUrl = new URL(messageUrl);
HttpURLConnection connection = (HttpURLConnection) imgUrl.openConnection();
//伪装请求,绕过反爬
connection.setRequestProperty("User-Agent", ua[i]);
//添加来源
connection.setRequestProperty("Referer","http://www.mzitu.com/");
//添加地址解析
connection.setRequestProperty("Host","i.meizitu.net");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
//获取输入流
inputStream = connection.getInputStream();
//将输入流信息放入缓冲提升读写速度
bis = new BufferedInputStream(inputStream);
//获取字节数;
byte[] buf = new byte[1024];
//生产文件
outputStream = new FileOutputStream("D:\\meizitu\\"+outImage); int size = 0;
while ((size =bis.read(buf)) != -1) {
outputStream.write(buf, 0, size);
}
//刷新文件流
outputStream.flush();
}catch (MalformedURLException e) {
e.printStackTrace();
}catch (IOException e) {
e.printStackTrace();
}finally {
try {
if(outputStream != null){
outputStream.close();
}
if(bis != null) {
bis.close();
}
if(inputStream != null) {
inputStream.close();
}
} catch(Exception e) {
e.printStackTrace();
}
}
//list.add(jobBean);
}
return list;
}
String[] ua这个里面装的是User-Agent,游览器的参数信息,为什么这样做,因为我们要将我们的JAVA程序的请求伪装成游览器请求,这样别人网站才放心给我们资源嘛。这个里面的参数越多越好
下面代码是从上面代码取下来的好做分析
Elements elements = document.select("#pins li");
elements.remove(0);
for (Element element : elements) {
Elements needElements = element.select("a");
//选取图片
String messageUrl = needElements.get(0).select("img[src]").attr("data-original");
document.select("#pins li");这句代码就是在选择元素了,因为前面我吗已经拿到每个页面的HTML,在这里只需要解析拿到元素就行了,下面的图是每一页的图片的HTML
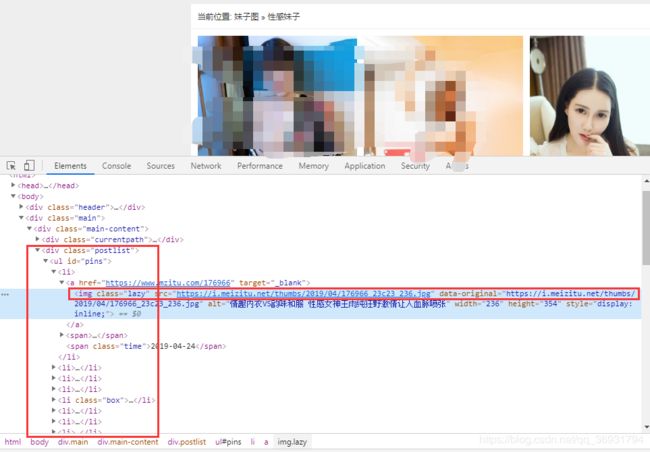
由图可知,每一页的图片是放在
document.select("#pins li") 意思是选取 #pins 下的所里 li 元素,而 li 元素里面的 a 标签 存我们需要的 img 资源。选取过后返回的是个 Elements 意思是每个 li 下面可能有多个元素,所有在这里用到了遍历,遍历后选择 a 标签,并拿到 attr 里面的值,就是我们需要的 地址了
String messageUrl = needElements.get(0).select("img[src]").attr("data-original");
拿到地址还是不行,因为这个网站做了简单的反爬,所有要做一个简单防反爬,这时要给我们的 img 地址加一层伪装,刚刚的游览器伪装也是必要的,看代码
try {
//创建链接
URL imgUrl = new URL(messageUrl);
HttpURLConnection connection = (HttpURLConnection) imgUrl.openConnection();
//伪装请求,绕过反爬
connection.setRequestProperty("User-Agent", ua[i]);
//添加来源
connection.setRequestProperty("Referer","http://www.mzitu.com/");
//添加地址解析
connection.setRequestProperty("Host","i.meizitu.net");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
这里加了个延时,防止爬取过快被服务器拉黑。
User-Agent 这个是游览器伪装 ua[i] 是上面代码String[] 里面的值 i 是随机生成的,从String[] 里面取
Referer 这个是来源,意思的请求从哪里来,如果我们拿到图片的URL直接访问,是不能多次访问的,因为这个URL的来源 不是从规定的官网来的,所有服务求会给你403报错,这个重要
Host 图片的地址和官网地址不一样,这个也是一定要加的
三个加上过后就可以访问地址了,访问了还要通过IO流来下载到本地,呆,看代码,这个就不解释了
//获取输入流
inputStream = connection.getInputStream();
//将输入流信息放入缓冲提升读写速度
bis = new BufferedInputStream(inputStream);
//获取字节数;
byte[] buf = new byte[1024];
//生产文件
outputStream = new FileOutputStream("D:\\meizitu\\"+outImage); int size = 0;
while ((size =bis.read(buf)) != -1) {
outputStream.write(buf, 0, size);
}
//刷新文件流
outputStream.flush();
}catch (MalformedURLException e) {
e.printStackTrace();
}catch (IOException e) {
e.printStackTrace();
}finally {
try {
if(outputStream != null){
outputStream.close();
}
if(bis != null) {
bis.close();
}
if(inputStream != null) {
inputStream.close();
}
} catch(Exception e) {
e.printStackTrace();
}
}
最后main跑一波!!!!!!
public static void main(String[] args){
ControllerImg c = new ControllerImg();
String URL = "https://www.mzitu.com/xinggan/";
Document document = getDom(URL);
List list = getPageInfor(document);
System.out.println("---------------"+(++count)+"-------------");
for (JobBean jobBean : list) {
System.out.println(jobBean);
}
c.getNextPageInfor(document);
}
里面的 list 不用管,这是我之前装了职位信息的。也懒得改了,方法里面返回一个null就行。
结果!!!!!

哈哈哈,存到磁盘了,来看看黄金宝库!!!!

吃水不忘挖井人,感谢下面两篇博客
https://blog.csdn.net/qq_36980713/article/details/84868135
https://blog.csdn.net/qq_42982169/article/details/83155040