tesseract-ocr的安装及使用
1、下载安装包
根据https://github.com/tesseract-ocr/tesseract/wiki,我找到非官方的安装包,好像我只看到64位的安装包http://digi.bib.uni-mannheim.de/tesseract/tesseract-ocr-setup-4.00.00dev.exe,下载后直接安装即可,但是要记得你的安装目录,我们等会配置环境变量要用。
如果不是做英文的图文识别,还需要下载其他语言的识别包https://github.com/tesseract-ocr/tesseract/wiki/Data-Files。
简体字识别包:https://raw.githubusercontent.com/tesseract-ocr/tessdata/4.00/chi_sim.traineddata
繁体字识别包:https://github.com/tesseract-ocr/tessdata/raw/4.0/chi_tra.traineddata
或者直接我的百度云盘:链接:tesseract 密码:tmdm
第二步:安装
直接执行下载好的tesseract-ocr-setup-4.0.0-alpha.20180109.exe,下一步、下一步安装。安装过程中,会让你安装额外的语言包,可根据选择下载。
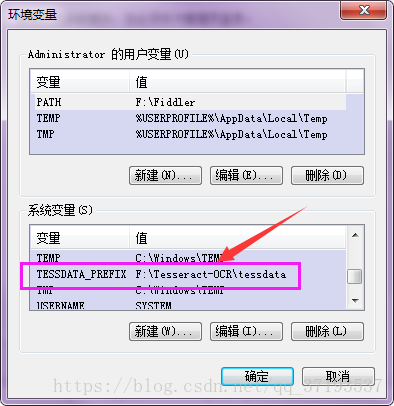
第三步:配置环境变量
我的是安装在C:\Program Files (x86)\Tesseract-OCR,界面如下:

将“F:\Tesseract-OCR”添加到环境变量中。如图:

增加一个TESSDATA_PREFIX变量名,变量值还是我的安装路径F:\Tesseract-OCR\tessdata这是将语言字库文件夹添加到变量中;
使用
打开命令终端,输入:tesseract -v,可以看到版本信息
用命令tesseract --list-langs来查看Tesseract-OCR支持语言。

将命令行切换至目标图像文件目录,比如我们转换文件为test.png(图片文件允许多种格式),位于C:\Users\Lian\Desktop\test;然后在命令行中输入
tesseract test.png output_1 –l eng
【语法】: tesseract imagename outputbase [-l lang] [-psm pagesegmode] [configfile…]
imagename为目标图片文件名,需加格式后缀;outputbase是转换结果文件名;lang是语言名称(在Tesseract-OCR中tessdata文件夹可看到以eng开头的语言文件eng.traineddata),如不标-l eng则默认为eng。
![]()
打开文件output_1.txt,发现tesseract成功的将图像转换成152408。

遇到的问题:
问题1:

没有配置环境变量,按上面情况将环境变量配置好
问题2:
E:\testdir>tesseract ttest1.png test1 -l eng
Error opening data file \Program Files (x86)\Tesseract-OCR\tessdata/eng.traineddata
Please make sure the TESSDATA_PREFIX environment variable is set to the parent directory of your "tessdata" directory.
Failed loading language 'eng'
Tesseract couldn't load any languages!
Could not initialize tesseract.
错误信息的关键词是tesseract_prefix的环境变量设置。
解决办法: 找到testData所在的目录,默认情况下是在tesseract安装的目录,在环境变量中设置TESSDATA_PREFIX的环境变量为testdata所在的目录即可。 重新运行命令即可正常使用。