Java容器之HashMap
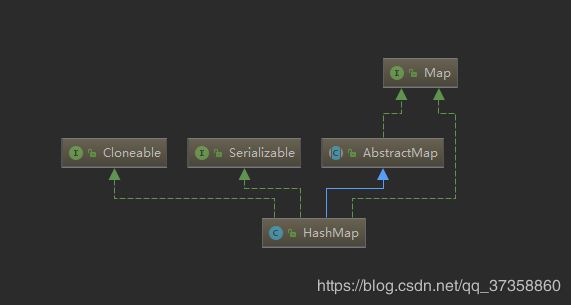
一. HashMap的类关系图
二. HashMap简介
- 这个简介之前先附张图.
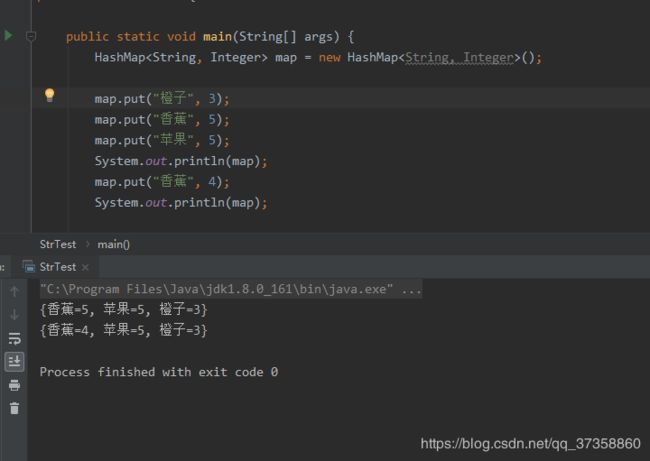
这回我们结合图片看 - HashMap长度是可变的
- HashMap没有顺序,在图片上我们可以看出打印出来的顺序和添加的顺序不一样.实际上,随着HashMap中的键值对越来越多的时候,打印的顺序也也是会发生变化的.
- HashMap中的key值是不可重复的,value值是可以重复的
- 线程不安全
- 特点:键值对
- 存储结构: 这里是重点,HashMap中的数据存储结构在容器中是相对复杂的,尤其是在JDK1.8之后又引入的红黑树.本文基于JDK1.8进行分析HashMap.HashMap的存储结构是 数组+单向链表+红黑树 并且是基于散列算法,保证了性能.
HashMap的存储结构与源码
- 先断点看看HashMap的结构,然后我们去源码中找一下对应的属性都是什么
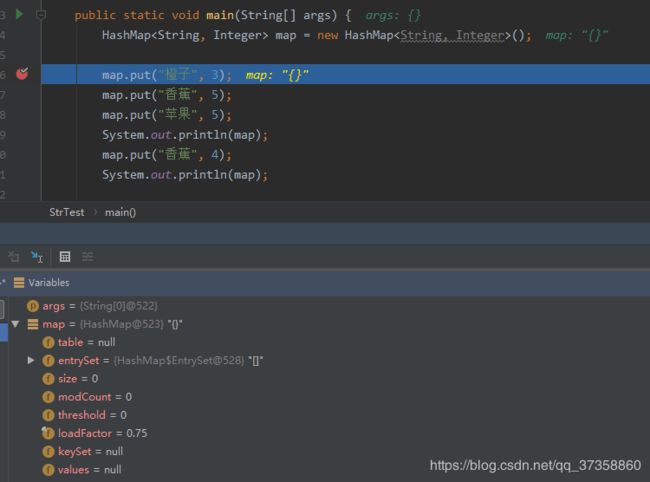
先找下table
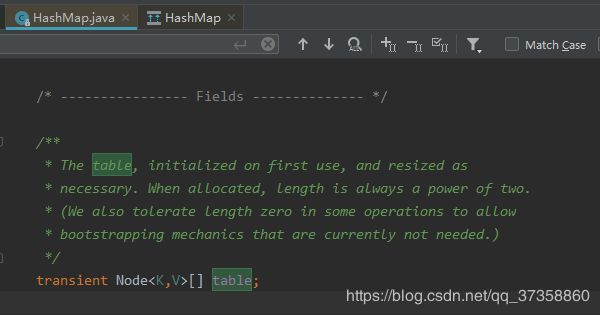
在这这这里我们能看到的是table属性就是一个数组,存储的是Node - 在找下Node
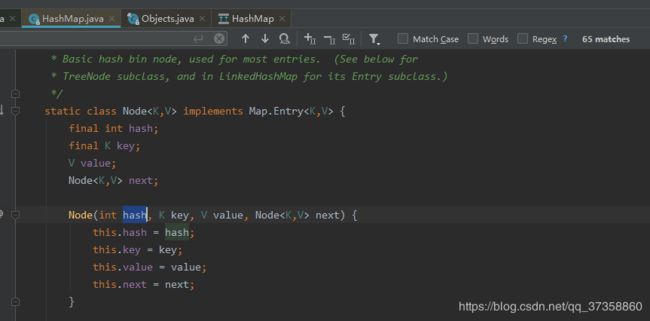
在这里我们能够看到Node是HashMap的一个内部类.包括一个final修饰int类型的hash属性,一个final 修饰的泛型key, 一个泛型 value,最后一个还是Node - 这就是前面说的HashMap的数据结构是 数组+单向链表 (红黑树我们稍后在说), 接下来我们画图看一下这个数据结构
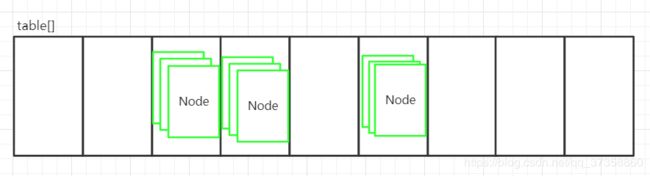
用图形表示的话,大概就是这么一个形式,数组中装着一个单向链表. - 接下来我们看看HashMap到底是以什么方式将数据存储到这个数组加链表的结构中,或者说是如何确定一个键值对应该存储到的具体位置(数组中的哪个位置,链表中的哪个位置),我们先打断点,然后在分析源码.
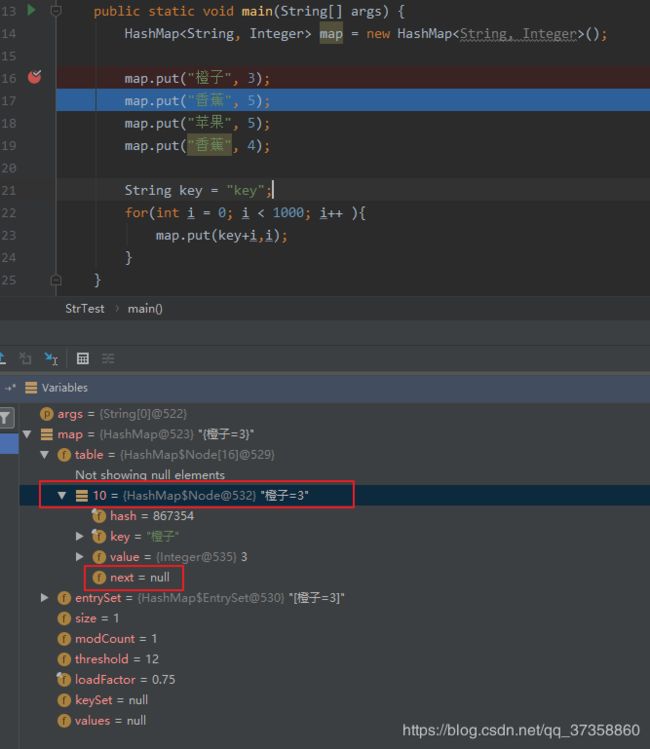
当我们执行 map.put(“橙子”, 3); 之后,我们可以看见table中已经有值,在下标为10的位置有了一个Node,这个Node中的key和value就是我们put进去的key和value. - 那么这里为什么是将Node节点放在了下标是10的这么一个位置呢?这个10是从哪里得出来的?我们接着看HashMap中put的源码.

在这里直接return了一个putVal()方法,而方法中的第一个参数是调用了hash(key)的返回值,我们接着往下看hash(key)

到这里我们可以看到,hash方法是根据你put中的key值,来得到一个int类型的数字,如果key是null,就直接返回一个0.如果不是null,就调用这个key的hashCode()方法得到一个hashCode码,返回的实际上就是这个hashCode码的高16位与低16位的按位异或运算的结果,如果这里你理解不了,你就记住这个方法是根据你put的key值从新计算出一个int类型的整数就可以了.知道这个方法返回的是一个整数,我们接着就可以看putVal()这个方法了.
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) {
Node[] tab; Node p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
下面我们开始分析putVal这个方法.这里是重点 这里是重点 这里是重点
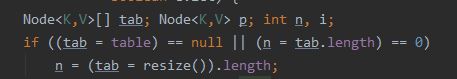
第一个if实际上就是执行了一个赋值的过程,给tab和n赋值.先将HashMap中的table赋值给tab,将table.lenght赋值给你,如果tab是null,或者n是0,resize()方法重新赋值.resize()方法我们一会在说,我们接着往下看第二个if.
![]()
这个if又干了什么呢? 这里我们可以先看如果这个if条件如果为true会执行什么,然后在看条件判断这部分.
先看tab[i] = newNode(hash, key, value, null); 这行代码我感觉挺简单的,之前将HashMap中的table赋值给了tab,并且做了一些处理之后才赋值的,确保table不为null,长度大于0.那么tab就是一个Node类型的数组,这里就是根据你传给putVal方法的值创建了一个Node对象,然后赋值给tab[i]这个位置.
ok,这个时候我们可以继续看上面的条件什么时候为true了,(i的这个值,也是在条件判断的时候赋值的)
if ((p = tab[i = (n - 1) & hash]) == null);
先看这行代码中的几个属性:
p 是Node类型的对象, 但是没有初始化
tab 就是table赋值过来的Node类型的数组
n 就是table的length
在看这行代码的执行顺序.我们把这行代码拆分成几个部分
第一个 执行的是 (n-1) 得到的结果是15
table的初始长度是16,此时我们先把n当做16,为了保证我们的思路能够清晰,这里先不看别的方法.不信你可以自己去验证,或者给我留言
第二个 执行的是 i = (n - 1) & hash 也就是15 与一个 int 类型的整数进行 按位与 运算的结果赋值给 变量 i
到这里就比较有意思了,我们知道 i 代表的是tab这个数组也可以说是table这个数组中的下标,那么这个下标是怎么来的呢?
首先说 n 代表的是数组的长度,那么当n等于16的时候,最大最大下标的位置就是 15 ,也就是说只有 0-15 之间的数可以做这个数组的下标
到这里,也就是说我想给 i 这个变量赋值一个0-15之间的下标, 然后通过这个下标去数组中取值 给 变量 p 赋值. 我们考虑一下这个 i 下标需要满足什么特性?
a. i >= 0 && i <= 15
b. 我下次再put值的时候, 这个i的值应该是相同的.
我们看下HashMap是怎么实现的. (n - 1) & hash
a. 现在已知 n-1 = 15 , hash是一个整数 ,我们来进行按位与运算
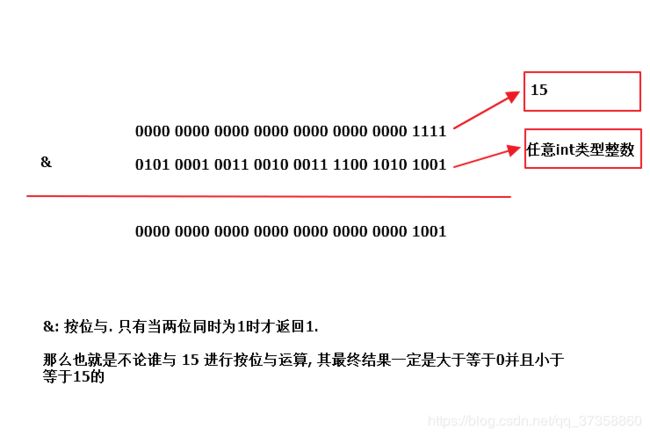
b.怎么保证 i 下次再计算的时候 i 的值是不变的 , 这个时候我们就需要看这个这两个运算数是怎么来的, 15 根据数组长度来的,只要数组长度不变,这个就绝对不会变(如果数组长度改变的话,涉及到扩容,存储的位置也可能发生变化),另外一个hash变量是跟你你传入的key的hashCode()方法返回的hashCode码得来的,java中同一个对象多次调用hashCode()方法返回的值是相同的,除非你重新了hashCode()方法.
c.这种算法的好处,首先能够保证其运算性能,第二还在HashMap进行扩容的时候提供了一定的方便,这个后面我们在说.
第四个 执行的就是 if ((p = tab[i = (n - 1) & hash]) == null); 也就是最终判断 p == null
到这里第二个if就要分析完了, 第二个if干了什么,实际上就是通过一系列算法根据put的key值,取得数组中对应位置的Node对象,如果这个对象为null,也就是数组中这个位置没有值,那么就根据传入的参数创建一个Node对象,放在这个位置.有值就进行else操作.大概的流程图
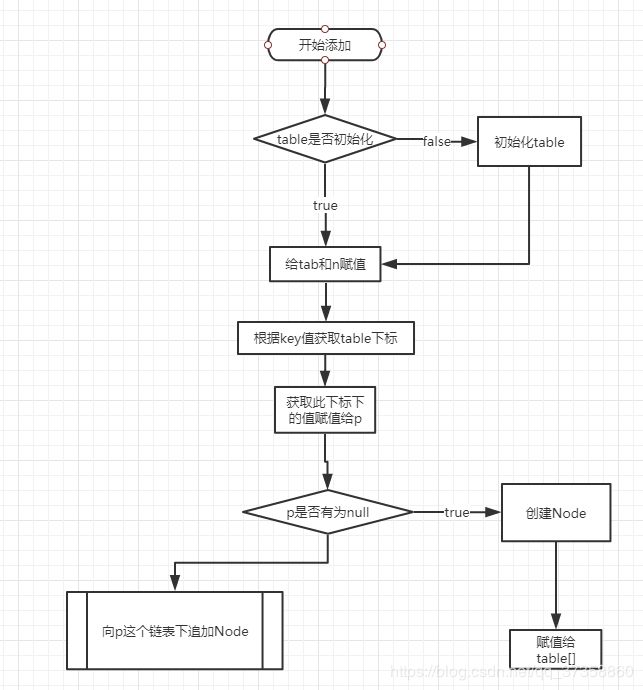
- 当代码执行到这里的时候,put操作算是走了一半了,我们通过key的hashCode码,定位了这个Node对象应该放到数组中的那个位置,如果这个位置当前没有值,我就将这个Node直接放到这个位置就ok了, 接下来我们看看如果这个位置已经有值了怎么处理,是不是说的太磨叽了,下面开启加速模式

这段代码判断当前要保存的key值与数组中此位置的key值是否相同,判断的标准就是 == 或者 equals() 返回是true就认为是同一个key,所以,你保存在HashMap中的key如果是一个对象,并且还重写了equals()方法,那么你应该小心使用HashMap.

这段代码判断的就是table[]中的数据是以单项链表存储还是以红黑树存储.红黑出的话就要调用putTreeVal()方法了.
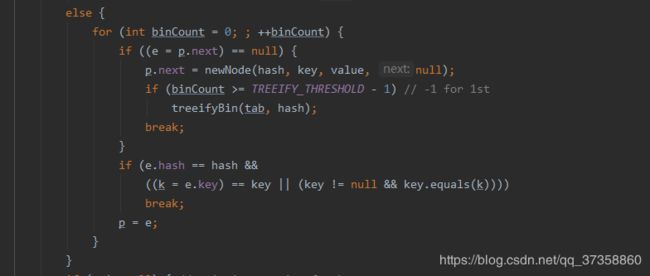
遍历这个链表下的所有的所有节点,依次判断key值是否是当前要添加的key,如果是的话就直接改变这个node就ok了,如果不是的话就看看这个node指向的下一个node是否为null,如果是null,就创建一个Node赋值给当前这个Node的next属性就ok了,赋值完之后还要判断一下当前数组位置下的链表的长度.

长度如果大于等于7(TREEIFY_THRESHOLD的值是8)就要将这个链表转成红黑树的存储结构了.
四. 总结
-
首先跟大家说声抱歉,这篇文章写的有点虎头蛇尾了,HashMap中的知识点实际上挺多的,我本意是打算写的详细一点,那种小白都可以看的懂的,但是写的太详细了,如果都在一篇文章中可能篇幅会有点大.如果你看到这里,感觉前面写的还算清楚的话,想继续了解关于HashMap的一些细节,欢迎留言.我会抽出时间接着写下去关于你提出的问题.
-
还是说啊,源码是最好的文档,多看看优秀的源码对你的帮助一定是很大的.接下来简单总结下HashMap可能问道的一些面试题.还是说,怎么实现的你都清楚了,面试题应该就不存在问题了.
-
HashMap中的table的默认大小是16
-
HashMap的长度达到table.length乘以0.75(负载因子)的值的时候就需要扩容了

-
扩容是扩容2倍,(一定是2n)
-
resize()功能是初始化和扩容.
-
扩容后的数据转存三种情况
1.table[]数组中的这个位置不为null,且next下为null,直接重新添加
2.table[]数组中的这个位置不为null,且next下不为null,类型是红黑树,打散重新添加
3.table[]数组中的这个位置不为null,且next下不为null,类型是链表,重新计算位置.
计算位置方式,只有两种可能,一种是原来的位置,另一种是原来的位置+原来数组的长度.
用hash码与原来数组长度进行&运算结果为0就是原来的位置.不为0就是原来的位置加上原来数组长度的位置.