pomelo源码解析之模块解析(二)
文章目录
- pomelo-protobuf解析
- 为什么可以减少传输无效数据
- 所采用编码格式
- 怎么使用
- 实例解析
- shortStr分析:buffer[0-5]
- longStr分析:buffer[6-658]
- low128分析:buffer[659-660]
- high128分析:buffer[661-663]
- negativeInt分析:buffer[664-666]
- intArray分析:buffer[667-670]
- tag过大怎么办
pomelo-protobuf解析
官方wiki:https://github.com/NetEase/pomelo/wiki/消息压缩
protobuf是一种序列化技术,能够大大减少传输无效数据
为什么可以减少传输无效数据
先看一下传统的C++通信格式
#pragma pack(1)
struct player
{
char name[32];
int sex;
};
#pragma pack()
因为名字有长有短,需要定义一个字符数组。也就是这个消息必然会发送32+4=36个字节。实际运用中会有很多的浪费。
而protobuf所采用的数据格式会去掉那些无效的数据,可以很大的压缩整个消息流的长度。
同时也更方便的使用变长字符串。与json相比,不需要在消息流中定义变量名字。
所采用编码格式
采用variant编码。第一个字节标视后续数据的tag以及type。
后续每个字节的最高位为控制位,剩余7位存储数据。如果最高位位1,代表下一个字节依旧为本次的数据。
例如传输一个 unsigned int a = 1
这个a变量序列化后的二进制为两个字节 (pomelo-protobuf采用的是小端格式,以小端存储为例,下同)
第一个字节:其中第一位flag,中间4位表示tag(用户设置,4位表示不下怎么办看最后),最后3位表示type,也就是说最多支持2^3=8种类型
| flag | tag | type |
|---|---|---|
| 0 | xxxx | 000 |
flag之后的字节是具体的value,最高位是标志位,为1的话表示下一个字节依旧为本次的数据
| flag | value |
|---|---|
| 0 | 0000001 |
如果传输的数据大于127,例如200的二进制表示为11001000。序列后为3个字节,第一个字节同上。第二三个字节如下:
| flag | value |
|---|---|
| 1 | 1001000 |
| flag | value |
|---|---|
| 0 | 0000001 |
有符号整型的话。如果是整数,直接*2存储 负数的话 *2-1存储。取值的话根据%2的余数判断符号
字符串的话,需要在flag之后的字节写入长度
怎么使用
在项目/config 内有clientProtos.json和serverProtos.json两个配置文件,分别对应客户端的消息和服务器的消息
配置格式:支持required message repeated关键字 查看源码得知optional与required关键字功能相同
{
"onMove" : {
"required uInt32 entityId" : 1,
"message Path": {
"required double x" : 1,
"required double y" : 2
},
"repeated Path path" : 2,
"required float speed" : 3
}
}
上文定义了一个onMove的消息。里面包含有3个字段 entityId path speed。最后的数字就是tag(不允许重复)
其中path为自定义类型。也就是message定义的类型。并且是个数组。
翻译成C++是这样的:
struct Path
{
double x;
double y;
};
struct onMove
{
unsigned int entityId;
Path path[]; // 未知数量
float speed;
};
pomelo-protobuf内置数据类型:pomelo-protobuf/lib/constant.js
module.exports = {
TYPES : {
uInt32 : 0,
sInt32 : 0,
int32 : 0,
double : 1,
string : 2,
message : 2,
float : 5
}
}
实例解析
修改pomelo-protobuf/test下的部分代码,测试用例如下
定义消息结构如下:
{
"pomelo-protobuf-test": {
"required string shortStr" : 1,
"required string longStr" : 2,
"required uInt32 low128" : 3,
"required uInt32 high128" : 4,
"required sInt32 negativeInt": 5,
"repeated uInt32 intArray" : 6
}
}
发送数据如下:
tc['pomelo-protobuf-test'] = {
shortStr: 'abcd',
longStr: 'abcderghijklmnopqrstuvwxyzabcderghijklmn'
+'opqrstuvwxyzabcderghijklmnopqrstuvwxyza'
+'bcderghijklmnopqrstuvwxyzabcderghijklmn'
+'opqrstuvwxyzabcderghijklmnopqrstuvwxyza'
+'bcderghijklmnopqrstuvwxyzabcderghijklmn'
+'opqrstuvwxyzabcderghijklmnopqrstuvwxyzab'
+'cderghijklmnopqrstuvwxyzabcderghijklmnop'
+'qrstuvwxyzabcderghijklmnopqrstuvwxyzabcd'
+'erghijklmnopqrstuvwxyzabcderghijklmnopqr'
+'stuvwxyzabcderghijklmnopqrstuvwxyzabcder'
+'ghijklmnopqrstuvwxyzabcderghijklmnopqrstu'
+'vwxyzabcderghijklmnopqrstuvwxyzabcderghij'
+'klmnopqrstuvwxyzabcderghijklmnopqrstuvwxy'
+'zabcderghijklmnopqrstuvwxyzabcderghijklmn'
+'opqrstuvwxyzabcderghijklmnopqrstuvwxyzabc'
+'derghijklmnopqrstuvwxyzabcderghijklmnopqrstuvwxyz',
low128: 127,
high128: 200,
negativeInt: -120,
intArray: [1,2]
};
调试可见被序列化成了671个字节的二进制流:

shortStr分析:buffer[0-5]
第一个字节=10,tag=1就是我们定义的那个,type=2也就是string或者message类型。
解析器本身也会读取结构定义,所以知道第一个类型具体是什么。详见decoder.decodeMsg
| flag | tag | type |
|---|---|---|
| 0 | 0001 | 010 |
第二个字节=4,代表字符串长度为4
| flag | value |
|---|---|
| 0 | 0000100 |
第三个字节=97,字符串数据开始,97就是字符‘a’ 。3-5字节一次是bcd
| flag | value |
|---|---|
| 0 | 1100001 |
longStr分析:buffer[6-658]
第一个字节=18: tag=2,type=2
| flag | tag | type |
|---|---|---|
| 0 | 00010 | 010 |
第二个字节=138,实际数据为10需要联系下一个字节
| flag | value |
|---|---|
| 1 | 00001010 |
第三个字节=5。联系上一个字节10,最终长度为5*2^8+10=650字节
| flag | value |
|---|---|
| 0 | 0000110 |
其余字节就是字串内容了,直接跳到buffer[659]
low128分析:buffer[659-660]
第一个字节=24: tag=3,type=0
| flag | tag | type |
|---|---|---|
| 0 | 00011 | 000 |
第二个字节=127,实际数据为127
| flag | value |
|---|---|
| 0 | 1111111 |
high128分析:buffer[661-663]
第一个字节=32: tag=4,type=0
| flag | tag | type |
|---|---|---|
| 0 | 00100 | 000 |
第二个字节=200,flag=1代表后续还有数据,value=72
| flag | value |
|---|---|
| 1 | 1001000 |
第三个字节=1,value=1。结合第二个字节,这个字段:1*2^8+72=200
| flag | value |
|---|---|
| 0 | 0000001 |
negativeInt分析:buffer[664-666]
第一个字节=40: tag=5,type=0
| flag | tag | type |
|---|---|---|
| 0 | 00101 | 000 |
第二个字节=239,flag=1代表后续还有数据,value=101
| flag | value |
|---|---|
| 1 | 1101111 |
第三个字节=1,value=1。结合第二个字节,这个字段:1*2^8+101=239。解析器知道该字段为有符号的。
%2=1,所以最终结果为 (239+1)/2 *(-1)=-120 代码在:Encoder.encodeSInt32
| flag | value |
|---|---|
| 0 | 0000001 |
intArray分析:buffer[667-670]
第一个字节=48: tag=6,type=0
| flag | tag | type |
|---|---|---|
| 0 | 00110 | 000 |
第二个字节=2,代表该数组有2个元素,分别是1和2。数组实际就是递归分析,只是里面元素不再需要flag字节,因为数组类型已经标注过了。
.
tag过大怎么办
我们可以分析下源码写入tag的地方
function encodeTag(type, tag){
var value = constant.TYPES[type];
if(value === undefined) value = 2;
return codec.encodeUInt32((tag<<3)|value);
}
实际上也就是tag*8+type字节当作uInt32写入。
读取就是
function getHead(){
var tag = codec.decodeUInt32(getBytes());
return {
type : tag&0x7,
tag : tag>>3
};
}
Encoder.decodeUInt32 = function(bytes){
var n = 0;
for(var i = 0; i < bytes.length; i++){
var m = parseInt(bytes[i]);
n = n + ((m & 0x7f) * Math.pow(2,(7*i)));
if(m < 128){
return n;
}
}
return n;
};
function getBytes(flag){
var bytes = [];
var pos = offset;
flag = flag || false;
var b;
do{
var b = buffer.readUInt8(pos);
bytes.push(b);
pos++;
}while(b >= 128);
if(!flag){
offset = pos;
}
return bytes;
}
也就是说tag超过4位表示的依旧可以支持。
测试如下。设置第一个元素tag=50
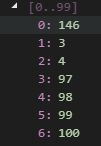
第一个字节=146,因为超过128会继续读取第二个字节3。合并成整数3*128+18=402 注意第一字节的146要去掉最高位
计算出tag=402/8=50,type=402%8=2