使用scrapy框架爬取斗鱼图片
使用scrapy框架爬取斗鱼图片
首先我们先认识一下框架
scrapy—Scrapy是Python开发的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
Scrapy吸引人的地方在于它是一个框架,任何人都可以根据需求方便的修改。它也提供了多种类型爬虫的基类,如BaseSpider、sitemap爬虫等,最新版本又提供了web2.0爬虫的支持。
1、首先第一步先进行框架的安装操作
利用python的pip进行安装scrapy
这里如果直接pip3 install scrapy可能会出错。所以你可以先安装lxml:pip3 install lxml(已安装请忽略)。安装pyOpenSSL:在官网下载wheel文件。安装Twisted:在官网下载wheel文件。安装PyWin32:在官网下载wheel文件。下载地址:https://www.lfd.uci.edu/~gohlke/pythonlibs/配置环境变量:将scrapy所在目录添加到系统环境变量即可。ctrl+f搜索即可。最后安装scrapy,pip3 install scrapy
2、安装成功后,再进行创建框架
利用该命令scrapy startproject douyuSpider ,创建项目成功后在进行,进入douyuSpider 目录,使用命令创建一个基础爬虫类:# douyuspider 为爬虫名,douyu.com为爬虫作用范围
scrapy genspider tencentPostion “douyu.com” 创建成功后在查看一下目录结构 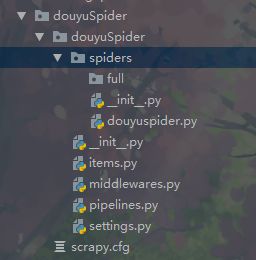
3、json数据
之后在进行抓包 、、这是抓包的 API,可以直接使用http://capi.douyucdn.cn/api/v1/getVerticalRoom?limit=200&offset=1,这个是颜值的json数据,可以直接进行提取使用。
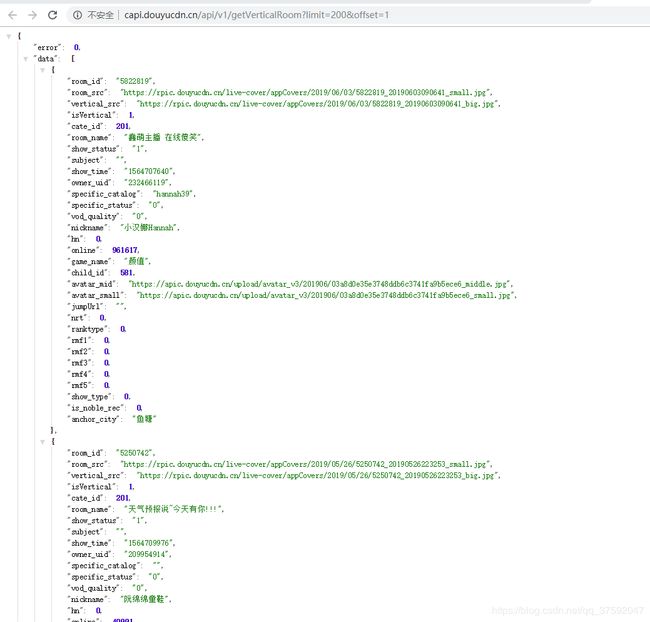
这就是json数据,
4、下面进行代码展示,

5 、这个是爬虫类
进行数据的提取
item: 这个是接收的字段,主要是主播的昵称和图片的链接 ,主播名称用为文件的名字,图片的链接用于下载
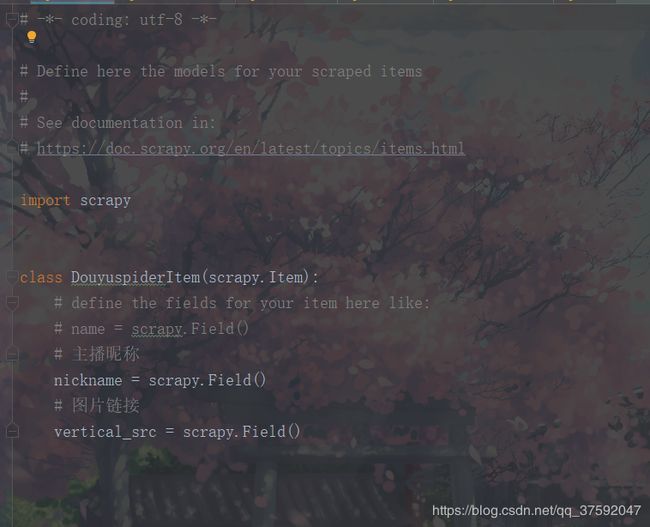
6、Pipeline:管道文件用于下载图片的文件和进行保存,文件名利用字符串的拼接把昵称保存为文件名
下载文件需要把管道类的参数尽心更改为ImagesPipeline

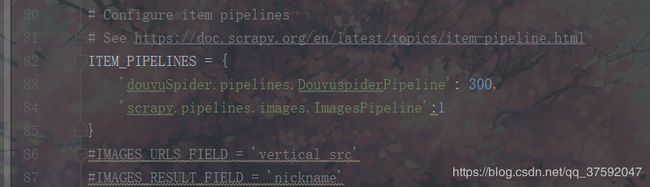
7、settings:这是框架的配置文件
首先进行写入文件的保存位置
然后进行模拟请求头,防止本机的ip进行拦截或者被封,这是最基本的防爬机制
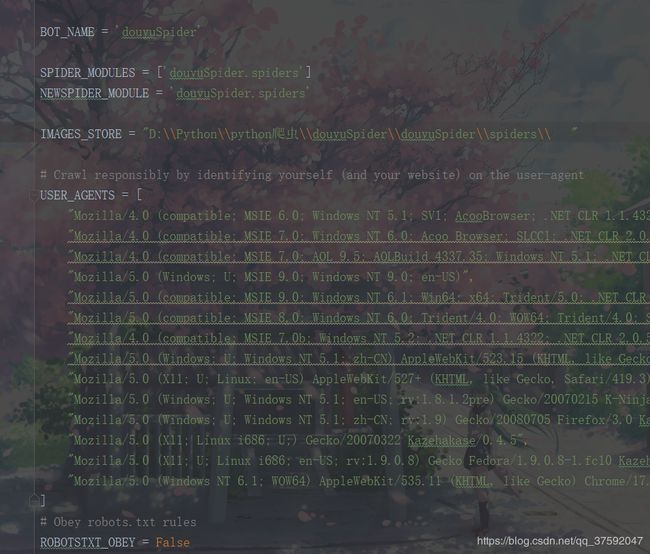
然后开启管道 ,也可以配置其优先级,
,然后这样就结束了。。。。祝你天天愉快!~~~~