基于python实现全网视频解析--python篇
这学期学习了python和javaWeb,所以就想着将javaWeb和python融合起来做个小项目,这里我实现的就是利用python爬取各个网站的视频。当然,我并没有选择把这个视频下载下来,一来太大,二来没必要,所以就用javaWeb写了显示界面。
首先,我们来看一看效果图。目前总共有三种模式:电影,电视剧,动漫。
电影: 无问西东
电视剧: 人民的名义
动漫: 斗罗大陆
看了效果图是不是也很想实现呐??哈哈,要实现起来其实不难,跟着我的步骤走就ok了
准备工作:
python环境安装好了,jdk,jre配置好了
工具:
pycharm eclipse
基础知识
python html(js,css) javaWeb
我们正式开始!!
原理:
首先我们需要知道爬取视频的原理是什么。
其实,这些网站的视频存在于一个隐藏的地址,这个需要我们解析响应来获取,至于如何解析,网上已经有人做过,我跟着弄了。代码如下:
import requests
import json
import urllib.request
import urllib
vid = 'y00221a60w7' # 唯一标识符
for definition in ('shd', 'hd', 'sd'):
params = {
'isHLS': False,
'charge': 0,
'vid': vid,
'defn': definition,
'defnpayver': 1,
'otype': 'json',
'platform': 10901,
'sdtfrom': 'v1010',
'host': 'v.qq.com',
'fhdswitch': 0,
'show1080p': 1,
}
r = requests.get('http://h5vv.video.qq.com/getinfo', params=params)
data = json.loads(r.content[len('QZOutputJson='):-1])
url_prefix = data['vl']['vi'][0]['ul']['ui'][0]['url']
for stream in data['fl']['fi']:
if stream['name'] != definition:
continue
stream_id = stream['id']
urls = []
for d in data['vl']['vi'][0]['cl']['ci']:
keyid = d['keyid']
filename = keyid.replace('.10', '.p', 1) + '.mp4'
params = {
'otype': 'json',
'vid': vid,
'format': stream_id,
'filename': filename,
'platform': 10901,
'vt': 217,
'charge': 0,
}
r = requests.get('http://h5vv.video.qq.com/getkey', params=params)
data = json.loads(r.content[len('QZOutputJson='):-1])
url = '%s/%s?sdtfrom=v1010&vkey=%s' % (url_prefix, filename, data['key'])
urls.append(url)
for url in urls:
str = url.__str__().split("vkey=")[-1]+".mp4"
urllib.request.urlretrieve(url, 'D:/images/' + str) # 下载图片到本地
break
的确可以下载,但是被限速了,只有不到30kb/s.所以我选择直接调用别人的接口。
找到了地址就好比找到了寝室钥匙,可是还需要一个具体的寝室钥匙才能开门。这个寝室钥匙就是每个视频的唯一标识符。所以我们需要获取的就是这个唯一标识符。
那么,这个唯一标识符到底是什么?
比如腾讯视频
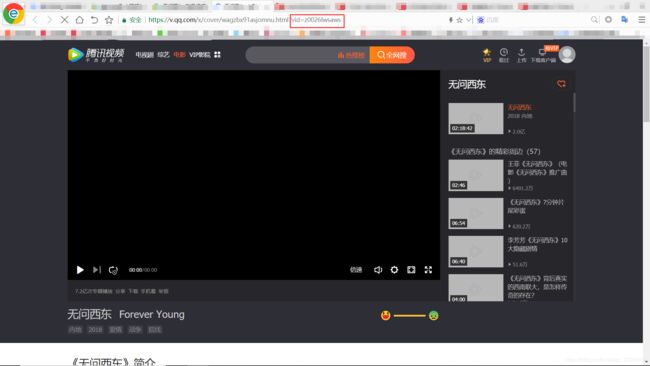
vid后面的值,就是它的唯一标识符。
需求: 根据用户的输入,获取对应视频在所在网站的唯一标识符
首先,我们来看看腾讯网站
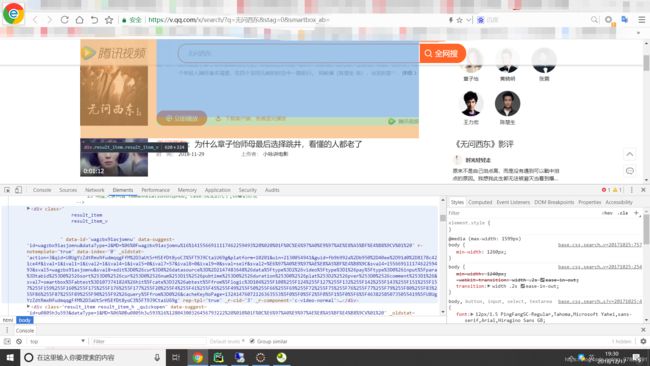
我们发现下面一堆数据啥也没有,点击也不能打开,咋办??
复制粘贴到本地!!

是不是,这就找到了它的vid,记住,一定要找到vid,不然解析不了
然后就是获取这个url
datas = soup.find("div", {"class", "result_btn_line"})
data = datas.a.attrs.get("href")获取到以后再调用我们的接口就可以了
是的,就是这么的简单!!!
这里获取到了电影的url,如何获取电视剧的呢?
用同样的方法呀!
但是不同的是,我们需要获取的是字符串,直接遍历就好了。
比如斗罗大陆(动漫和电视剧是一样处理的),很简单是吧?
事实证明,没那么简单,我们来看看中间的数据:
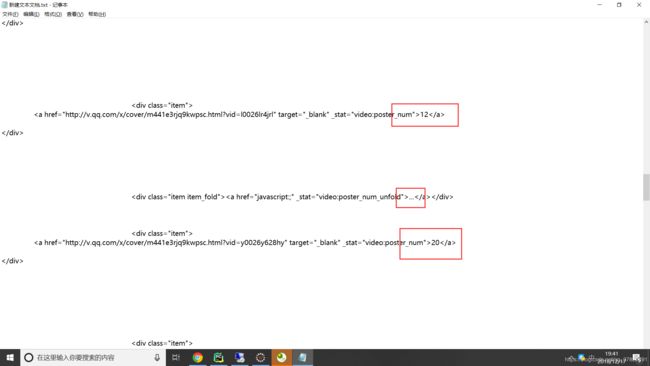
刺不刺激?惊不惊喜?意不意外???
没错,这需要点击事件才能获取到的数据。咋办???
我们再往上看看
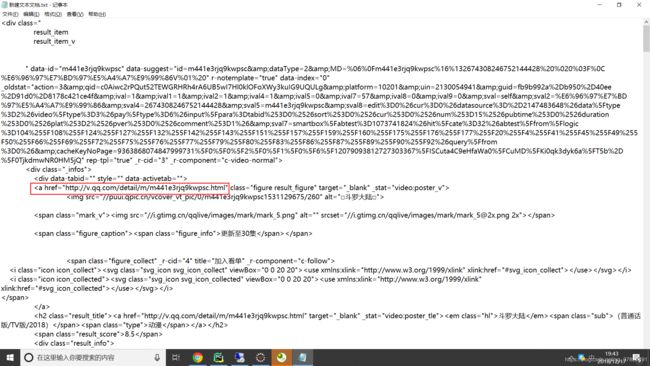
这里这个链接是干啥的??
点进去瞧瞧
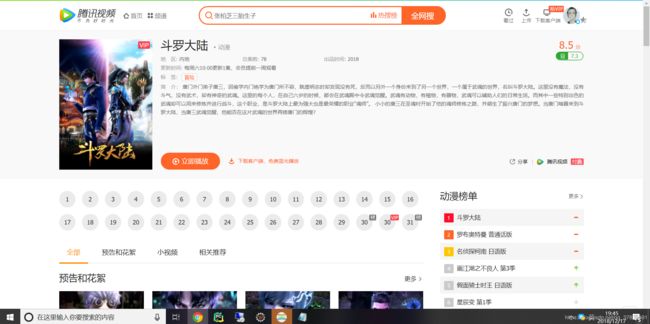
这里好像显示了所有的集数。没错,就是这个地方,然后就可以继续我们的爬取工作了
html = getHtmlText(url) #刚刚获取那个url
soup = BeautifulSoup(html, "html.parser")
try:
datas = soup.find("div", {"class", "mod_episode"})
data = datas.find_all("a")
singleURL = []
for Data in data:
singleURL.append(Data.attrs.get("href"))
return singleURL
except Exception:
print("Error !")
做到这一步,腾讯视频这部分我们就完成了。其他的网站视频,比如爱奇艺,芒果,搜狐等等,都相对而言没有难度。你们看可以自行去爬取,方法给了自己去实践吧!
这里特意强调一点----反爬虫。优酷今年做了更新,获取不到它的数据了,分析了一下它的源码,发现它在页面设置了资源拦截器,所以获取不到数据。试了很久,也没办法获取,所以索性放弃了,不过我估计或者这是一个征兆,或许以后的网站都会那样了。
好了,到了这里就意味着python这一块就完成了,下一篇是javaWeb的实现,点击这里
所有的源码,包括python,javaWeb我都已经上传至我的网站,放在资源共享/原创分享/破解vip。点击前往