(算法)通俗易懂的字符串匹配KMP算法及求next值算法
大多数据结构课本中,串涉及的内容即串的模式匹配,需要掌握的是朴素算法、KMP算法及next值的求法。在考研备考中,参考严奶奶的教材,我也是在关于求next值的算法中卡了一下午时间,感觉挺有意思的,把一些思考的结果整理出来,与大家一起探讨。
本文的逻辑顺序为
1、最基本的朴素算法
2、优化的KMP算法
3、应算法需要定义的next值
4、手动写出较短串的next值的方法
5、最难理解的、足足有5行的代码的求next值的算法
所有铺垫为了最后的第5点,我觉得以这个逻辑下来,由果索因还是相对好理解的,下面写的很通俗,略显不专业…
一、问题描述
给定一个主串S及一个模式串P,判断模式串是否为主串的子串;若是,返回匹配的第一个元素的位置(序号从1开始),否则返回0;如S=“abcd”,P=“bcd”,则返回2;S=“abcd”,P=“acb”,返回0。
二、朴素算法
最简单的方法及一次遍历S与P。以S=“abcabaaaabaaacac”,P="abaabcac"为例,一张动图模拟朴素算法:

这个算法简单,不多说,附上代码
#include
int Index_1(char s[],int sLen,char p[],int pLen){//s为主串,sLen为主串元素个数,p为模式串,pLen为模式串的个数
if(sLenpLen) return i-pLen;
return 0;
}
void main(){
char s[]={' ','a','b','c','a','b','a','a','a','a','b','a','a','b','c','a','c'};//从序号1开始存
char p[]={' ','a','b','a','a','b','c','a','c'};
int sLen = sizeof(s)/sizeof(char)-1;
int pLen = sizeof(p)/sizeof(char)-1;
printf("%d",Index_1(s,sLen,p,pLen));
}
三、改进的算法——KMP算法
朴素算法理解简单,但两个串都有依次遍历,时间复杂度为O(n*m),效率不高。由此有了KMP算法。
一般的,在一次匹配中,我们是不知道主串的内容的,而模式串是我们自己定义的。
朴素算法中,P的第j位失配,默认的把P串后移一位。
但在前一轮的比较中,我们已经知道了P的前(j-1)位与S中间对应的某(j-1)个元素已经匹配成功了。这就意味着,在一轮的尝试匹配中,我们get到了主串的部分内容,我们能否利用这些内容,让P多移几位(我认为这就是KMP算法最根本的东西),减少遍历的趟数呢?答案是肯定的。再看下面改进后的动图:
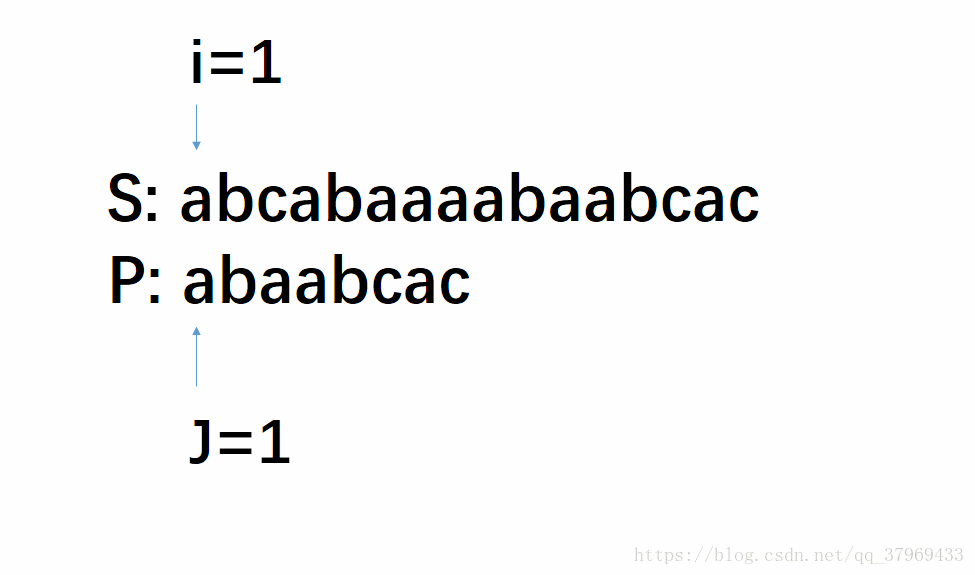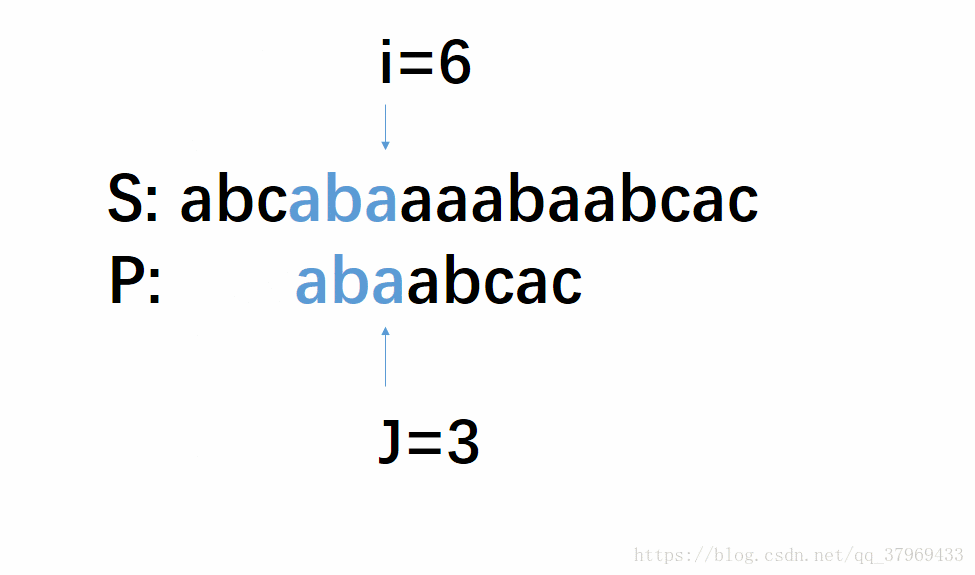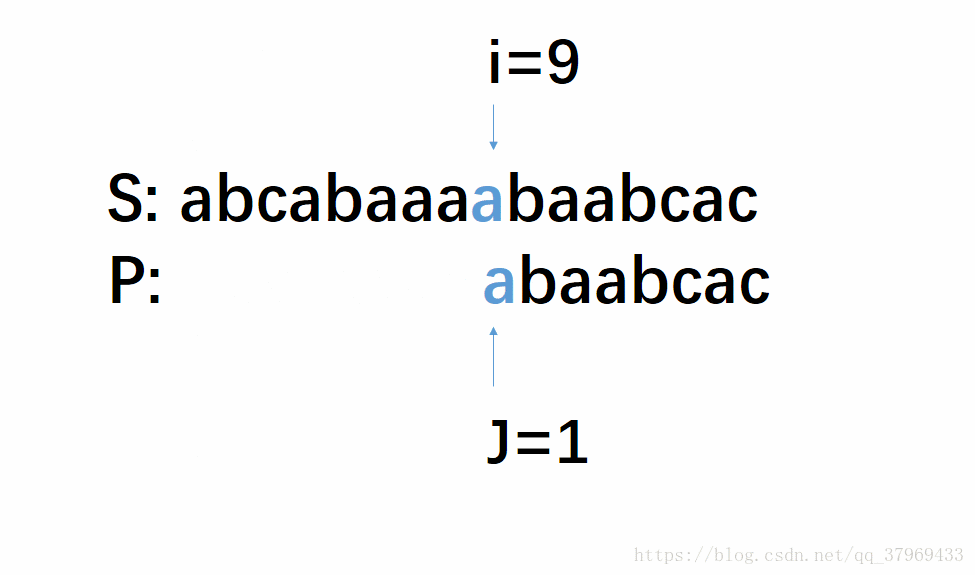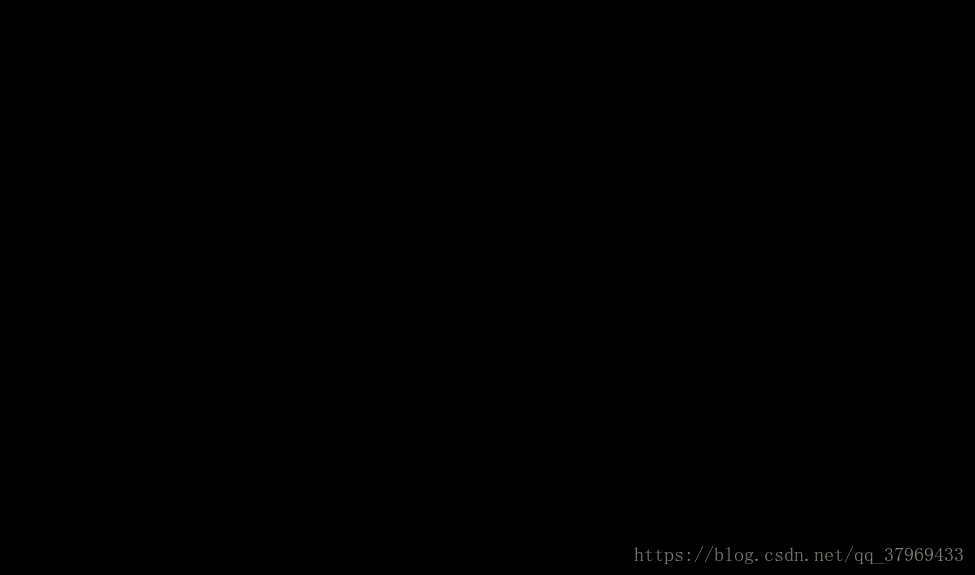
这个模拟过程即KMP算法,若没有看明白,继续往下看相应的解释,理解需要把P多移几位,然后回头再看一遍这个图就很明了了。
相比朴素算法:
朴素算法: 每次失配,S串的索引i定位的本次尝试匹配的第一个字符的后一个。P串的索引j定位到1;T(n)=O(n*m)
KMP算法: 每次失配,S串的索引i不动,P串的索引j定位到某个数。T(n)=O(n+m),时间效率明显提高
而这“定位到某个数”,这个数就是接下来引入的next值。(实际上也就是P往后移多少位,换一种说法罢了:从上图中也可以看出,失配时固定i不变,令S[i]与P[某个数]对齐,实际上是P右移几位的另一种表达,只有为什么这么表达,当然是因为程序好写。)
开——始——划——重——点!(图对逻辑关系比较好理解,但i和j的关系对后面求next的算法好理解!)
-
比如,Pj处失配,绿色的是Pj,则我们可以确定P1…Pj-1是与Si…Si+j-2相对应的位置一一相等的

-
假设P1…Pj-1中,P1…Pk-1与Pj-k+1…Pj-1是一一相等的,为了下面说的清楚,我们把这种关系叫做“首尾重合”

-
那么可以推出,P1…Pk-1与Si…Si+j-2

-
显然,接下来要做的就是把模式串右移了,移到哪里就不用多说了:

-
为了表示下一轮比较j定位的地方,我们将其定义为next[j],next[j]就是第j个元素前j-1个元素首尾重合部分个数加一,当然,为了能遍历完整,首尾重合部分的元素个数应取到最多,即next[j]应取尽量大的值,原因挺好理解的,可以想个例子模拟一下,会完美跳过正确结果。在上图中就是绿色元素的next值为蓝色元素的序号。也即,对于字符串P,next[8]=4。如此,再看一下上面的动图是不是清楚了不少。
-
最后,如果我们知道了一个字符串的next值,那么KMP算法也就很好懂了。相比朴素算法,当发生失配时,i不变,j=next[j]就好啦!接下来就是怎么确定next值了。
四、手动写出一个串的next值
我们规定任何一个串,next[1]=0。(不用next[0],与串的所有对应),仍是一张动图搞定问题:

这个扫一眼就能依次写出,会了这个方法,应付个期末考试没问题了。
通过把next值“看”出来,我们再来分析next值,这就很容易得到超级有名的公式了,这个式子对后面的算法理解很重要!所以先要看懂这个式子,如果上面的内容通下来了,这个应该很容易看懂了:

五、求next的算法
终于到了最后了~短的串的next值我们可以“看”出来,但长的串就需要借助程序了,具体算法刚接触的时候确实不容易理解,但给我的体验,把上面的内容写完,现在感觉简简单单了…先附上程序再做解释,(终于到了传说中的整整5行代码让我整理了一下午)。
int GetNext(char ch[],int cLen,int next[]){//cLen为串ch的长度
next[1] = 0;
int i = 1,j = 0;
while(i<=cLen){
if(j==0||ch[i]==ch[j]) next[++i] = ++j;
else j = next[j];
}
}
-
还是先由一般再推优化:
直接求next[j+1](至于为什么是j+1,是为了和下面的对应)
根据之前的分析,next[j+1]的值为pj+1的前j个元素的收尾重合的最大个数加一。即需要满足两个条件,把它的值一步步“检验”出来。一是“个数最多”的,因此要从可能的最大值开始验;二是“首尾重合”,因此要一一对应验是否相等。
不难理解,next[j+1]的最大值为j,所有我们从next[j+1]=j开始“验证”。有以下优先判断顺序:
if(P1…Pj-1 == P2…Pj) => next[j+1]=j
else if(P1…Pj-2 == P3…Pj) =>next[j+1]=j-1
else if(P1…Pj-3 == P4…Pj) =>next[j+1]=j-2
…
…
…
else if(P1P2 == Pj-1Pj) => next[j+1]=3
else if(P1 == Pj-1) => next[j+1]=2
else if(P1 != Pj-1) => next[j+1]=1
每次前去尾1个,后掐头1个,直至得到next[j+1] -
再进一步想,next值是一个“工具”,我们单独的求next[j+1]是完全没有意义的,就是说要求next就要把所有j的next求出来。所有一般的,我们都是已知前j个元素的next值,求next[j+1],以此递推下去,求完整的next数组。
但是,上面的思考过程还是最根本的。所以问题变为两个:知道前j个元素的next的情况下,
①next[j+1]的可能的最大值是多少(即从哪开始验证)
②某一步验证失败后,需要“前去尾几个,后掐头几个?”(即本次验证失败后,再验证哪个值)
看一下的分析:
1、next[j+1]的最大值为next[j]+1。
因为:
假设next[j]=k1,则可以说明P1…Pk1-1=Pj-k1+1…Pj-1,且这是前j个元素最大的首尾重合序列。
如果Pk1=Pj,那么P1…Pk1-1PK=Pj-k1+1…Pj-1Pj,那么k+1这也是前j+1个元素的最大首尾重合序列,也即next[j+1]的值为k1+1
2、如果Pk1≠Pj,那么next[j+1]可能的次大值为next[next[j]]+1,以此类推即可高效求出next[j+1]
这里不好解释,直接看下面的流程分析及图解
开——始——划——重——点!
从头走一遍流程
①求next[j+1],设值为m
②已知next[j]=k1,则有P1…Pk1-1 = Pj-k1+1…Pj-1
③如果Pk1=Pj,则P1…Pk1-1PK = Pj-k1+1…Pj-1Pj,则next[j+1]=k1+1,否则
④已知next[k1]=k2,则有P1…Pk2-1 = Pk1-k2+1…Pk1-1
⑤第二第三步联合得到:
P1…Pk2-1 = Pk1-k2+1…Pk1-1 = Pj-k1+1…Pk2-k1+j-1 = Pj-k2+1…Pj-1 即四段重合
⑥这时候,再判断如果Pk2=Pj,则P1…Pk2-1P~k2 = Pj-k2+1…Pj-1Pj,则next[j+1]=k2+1;否则再取next[k2]=k3…以此类推
上面几步,耐心看下来,结合那个式子很容易看懂。最后,再加一个图的模拟帮助理解:
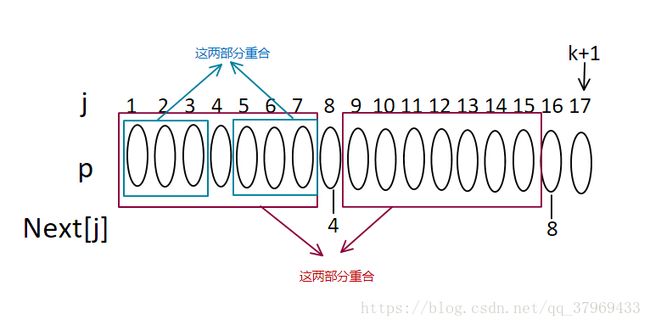
1、要求next[k+1] 其中k+1=17

2、已知next[16]=8,则元素有以下关系:

3、如果P8=P16,则明显next[17]=8+1=9
4、如果不相等,又若next[8]=4,则有以下关系
又加上2的条件知
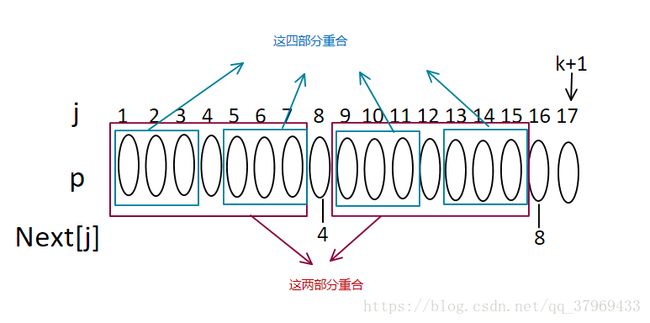
主要是为了证明:
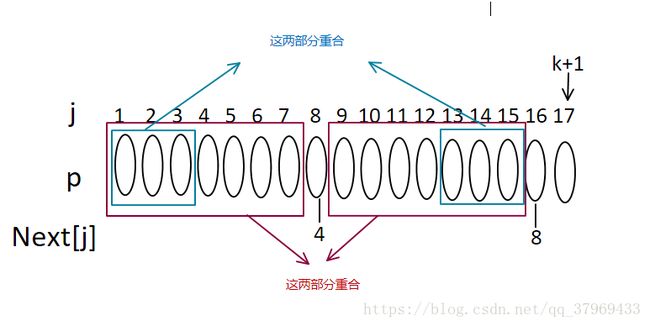
5、现在在判断,如果P16=P4则next[17]=4+1=5,否则,在继续递推
6、若next[4]=2,则有以下关系
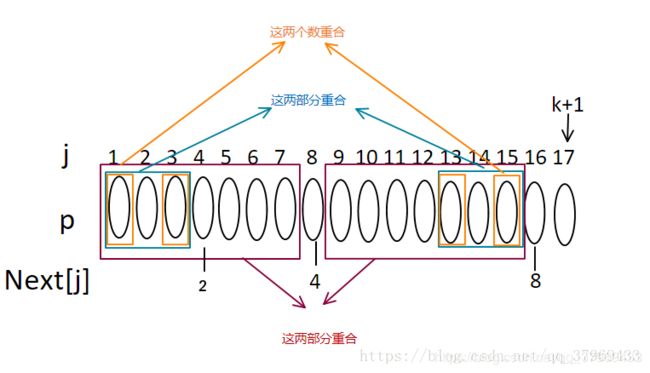
7、若P16=P2,则next[17]=2+1=3;否则继续取next[2]=1、next[1]=0;遇到0时还没出结果,则递推结束,此时next[17]=1。最后,再返回看那5行算法,应该很容易明白了!