浅谈Java容器及原理
学java其实学了很久了,但其实一直对容器没有一个深入的了解。了解的东西其实都是最简单的、常用的一些方法。
在这里我将对java的容器做一个系统的,比较浅显的回顾。包括容器的类型、容器的底层实现原理、具体的实例。
一、容器的原理与底层
容器:Collection收集,集合。本身也是一个对象,只不过它可以容纳其他的对象。前面比较典型的容器是数组Array[]
在这里我们主要要关注以下几个接口:Collection(容器)、Map(键值对)

Collection接口:定义了存取一组对象的方法,子接口Set、List、接口
Set:无序不可重复,若重复则后面的值会把前面的覆盖掉,子类Hashset
List:有序可重复
Map接口:(注意Map不是继承Collection的)单独的接口,键值对,子类有HashMap、TreeMap,允许值重复,键不能重复
Collection接口:size、isEmpty、contains、iterator、toArray、add、remove、containsAll(是否包含另一个集合里的所有对象)、addAll、equals、hashCode
1、List的底层实现:数组实现,它的特点是每个元素都有索引,因此优点也显而易见就是查询速度快。但是修改删除插入效率低。由于删除和插入会引起元素的移动,因此效率低下。
自定义ArrayList,实现list 的获取、增加、删除元素。Arraylist由于是数组实现,因此在扩容的时候采取的是将容量扩大到两倍。
import java.util.ArrayList;
import java.util.Date;
public class MyArrayList {
private Object[] element;
private int size;
public MyArrayList(){
this(10);
}
public MyArrayList(int capacity){
if(capacity<0){
try {
throw new Exception();
} catch (Exception e) {
e.printStackTrace();
}
}
element = new Object[capacity];
}
public void add(Object e){
// 数组扩容
if(size == element.length){
Object[] newArr = new Object[size*2+1];
System.arraycopy(element,0 ,newArr,0,element.length);
element = newArr;
}
element[size++] = e;
}
public Object get(int index){
changeIndex(index);
return element[index];
}
public void remove(int index){
if(index <0 || index >=size){
try {
throw new Exception();
} catch (Exception e) {
e.printStackTrace();
}
}
//需要移动元素 ,未写完
}
public void changeIndex(int index){
if(index<0||index>=size){
try {
throw new Exception();
} catch (Exception e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) {
MyArrayList ml=new MyArrayList();
ArrayList l = new ArrayList();
ml.add("1");
ml.add(new Date());
System.out.println(ml.get(1));
}
}
2、LinkedList原理+自定义实现
采用双向链表实现,他的特点是采用链表的原理,因此查询较List更慢,因为它没有索引,因此必须遍历整个链表,插入修改删除效率较高,无需移动元素。
自定义实现add、remove、get方法
public class MyLinkedList { private Node first; private Node last; private int size; public MyLinkedList() { } public void add(Object e){ if(null == first){ Node n = new Node(); n.setPre(null); n.setObj(e); n.setNext(null); first = n; last = n; }else{ Node n = new Node(); n.setPre(last); n.setObj(e); n.setNext(null); last.setNext(n); last = n; } size++; } public int size(){ return size; } public Object get(int index){ Node current =null; if(null==first ){ }else{ changeIndex(index); current = first; for(int i =0;i<index;i++){ current = current.next; } return current.obj; } return current; } public void remove(int index){ changeIndex(index); Node current = node(index); if(current!=null){ Node up = current.pre; Node down = current.next; up.next = down; down.pre = up; size --; } } public void changeIndex(int index){ if(index<0||index>=size){ try { throw new Exception(); } catch (Exception e) { e.printStackTrace(); } } } public Node node(int index){ Node current =null; changeIndex(index); current = first; for(int i =0;i<index;i++){ current = current.next; } return current; } public static void main(String[] args) { MyLinkedList ml= new MyLinkedList(); ml.add(3); ml.add(4); ml.add(5); // System.out.println(ml.get(1)); ml.remove(2); System.out.println(ml.size); } }
public class Node { Node pre; Object obj; Node next; public Node(){ } public Node(Node pre, Object obj, Node next) { this.pre = pre; this.obj = obj; this.next = next; } public Object getPre() { return pre; } public void setPre(Node pre) { this.pre = pre; } public void setNext(Node next) { this.next = next; } public Object getObj() { return obj; } public void setObj(Object obj) { this.obj = obj; } public Object getNext() { return next; } }3、Vector:
Vector:线程安全的,效率低。前两者线程不安全,效率高
我们需要掌握手写ArrayList的add、get、remove方法。
4、Hashmap
Hashmap在JDK1.7以前是采用数组+链表的形式实现的,数组存储hashcode的地址,使用链表处理冲突,同一hash值的链表都存储在一个链表里。但是当位于一个数组中的元素较多,即hash值相等的元素较多时,通过key值依次查找的效率较低。
JDK1.8中,HashMap采用位桶+链表+红黑树实现,当链表长度超过阈值(8)时,将链表转换为红黑树,这样大大减少了查找时间。
简单说一下原理,当我们在调用hashmap的add方法,我们需要先计算插入的key的hash值,来判断它属于数组的哪一个位置,比如计算出来的hash值是1,那么就存在arr[1]这个位置,但是hash值可能会重复,那么重复的这个元素也会被放在arr[1]中,这时候建立链表,将同一hash值的元素放入链表中,但当链表长度过大时,效率又降低了,因此当它的长度超过某一个阈值的时候,将链表转换为红黑树提高效率。
图如下:
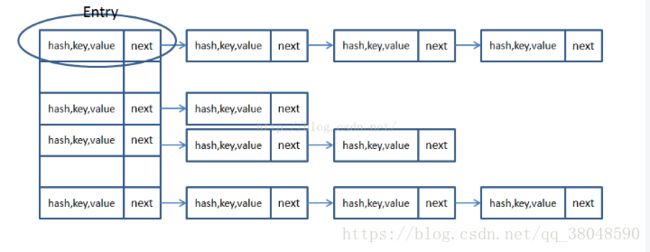
两个内容相同的对象的hashcode一定相等,两个key相等,则hash码一定相等,反之不然。hashcode重写,则equals也必须重写。保证两个内容相同的对象是一样的。hashmap里面的键不能重复的原理是覆盖,如果有重复则覆盖掉了
自定义Map实现get和put(初级版本):
import java.util.HashMap;
import java.util.LinkedList;
/**
* 自定义map的升级版
* 提高查询的效率
*/
public class Mymap01 {
// myEntry[] arr = new myEntry[999];
LinkedList[] arr = new LinkedList[999];//map的底层机构 数组+链表
int size;
public void put(Object key,Object value)
{
myEntry m = new myEntry(key,value);
int a = key.hashCode()%999;
if (null == arr[a]){
LinkedList list = new LinkedList();
arr[a] = list;
list.add(m);
}else{
//需要做判断,避免key重复
LinkedList list= arr[a];
for(int i =0;i5、Set
底层是通过map实现的。无序集合,没有重复元素,这是利用map的键不重复的原理,重复则覆盖
/** * @author lively * 自己定义hashSet,不能有重复元素 */ public class MySet { HashMap map; int size; private static final Object PRESENT = new Object(); public int size(){ return map.size(); } public MySet(){ map = new HashMap(); } public void add(Object obj){ map.put(obj,PRESENT);//Set的不可重复就是利用了hashMap里面的键不可重复 size++; } public void remove(Object obj){ } public static void main(String[] args) { // Set s = new HashSet(); // s.add("1"); // s.add("2"); // s.add("1"); // Iterator it = s.iterator(); // System.out.println(s.size()); // while(it.hasNext()){ // System.out.println(it.next()); // } MySet mySet = new MySet(); mySet.add("name"); mySet.add("name"); mySet.add(new String("name")); mySet.add(new String("name")); System.out.println(mySet.size()); } }
6、map里面最重要的一个方法:Iterator
Iterator迭代器遍历Map和Set,所有实现了Collection接口的容器类都有一个iterator方法以返回一个实现Iterator接口的对象。
使用迭代器遍历List和map的两个方法:for和while(后者用的居多)
三个方法:boolean hasNext,next方法,remove方法 自己实现
/** * 加入接口,提供方法 */ public class MyIterator2 { String[] elem = {"a","b","c","d","e","f","g"}; int size = elem.length;//简化迭代器原理 private int cursor=-1; public Iterator<String> iterator() { return new Iterator<String>() { @Override public boolean hasNext() { { return (cursor +1!=size); } } @Override public String next() { cursor++; return elem[cursor]; } public void remore(String e){ } }; } public static void main(String[] args) { MyIterator2 m = new MyIterator2(); Iterator iterator = m.iterator(); while (iterator.hasNext()){ System.out.println(iterator.next()); } } }
容器的原理和使用就说到这里,重点要掌握容器的底层原理,自定义map、list的常用方法等。
未完待续。。。