etcd基础知识梳理
前言
工作中遇到了一些问题,发现对etcd基础知识的欠缺导致在一些理解上面出现了一些偏差。这篇笔记,花了3小时的时间,初步查了一些资料后,结合自己的理解,做的一些整理。
一家直言,并没有什么权威性,仅仅是自己的理解。如果需要权威,https://github.com/etcd-io/etcd/blob/master/Documentation/learning/why.md
这个才是王道。
此外,梳理完以后,自身对etcd有了大概了解,但是不深入,在理解上也许会有些矛盾,欢迎探讨。
正文开始。
产生背景
在Core OS和Kubernetes的发展中,etcd作为**高可用、强一致性的服务发现组件**被引用到其中。
etcd的产生主要适用于:(看起来和ZooKeeper很像,具体区别后续研究讨论)
- 让服务快速透明的接入到计算集群中(无需关注过多细节,反应到实际,不用增加很多的配置)
- 让共享配置信息,快速的被集群中所有的服务发现(某一组件的配置中心)
- 高可用,容易部署,快速相应
总结起来,etcd可以实现的功能Zookeeper基本上都可以。但是相比之下,etcd有如下优势:
- 简单:Go语言实现,部署简单。HTTP协议的对外服务接口,使用方便。适用Raft算法保证强一致性(性能和Paxos算法未做过多了解,但是听说Raft算法比Paxos算法要容易理解)
- 安全:支持ssl客户端安全认证(就目前实际情况而言,暂时没有场景用到)
- 数据持久化:数据一旦更新就会持久化下来
相比之下ZooKeeper的缺点:
- zk部署维护起来比较复杂,对于维护人员的要求比较高。一致性算法上面(Paxos)相对来说理解起来比较困难(研究ZK的时候看到过这个算法,貌似是在ZAB协议里面用到了),而且需要各种客户端,官方只提供了C和JAVA的API。
- 发展缓慢。Apache的问题,不赘述。
- Java语言实现。其依赖会比较复杂(Java太重了),相对微服务集群的轻量化,低耦合,便于维护等设计理念(说白了就是尽可能简单),已经不再是最优选择。
经典使用场景
一、特性(仅一家之言)
- - 简单:基于 HTTP+JSON 的 API 让你用 url 就可以轻松使用
- - 安全:可选 SSL 客户认证机制
- - 快速:
每个实例每秒支持一千次写操作(这个说法有问题。在集群中,节点的数量决定了读写性能。节点越多,吞吐量越大,因为在强一致性算法的控制下,每个节点的数据都是一样的。节点越多,写入性能越差,因为写操作,肯定通过leader节点写入,写入以后就需要同步,同步就需要耗时,推测On的时间复杂度n为follower节点个数。所以,非要说快速,应该指的是QPS。) - - 可信:使用 Raft 算法充分实现了分布式
总结:
etcd是基于Raft强一致性算法的分布式数据存储仓库。
其中分布式系统中,数据可以分为两种,即控制数据,应用数据。使用etcd默认场景就是控制数据的存储。应用数据也可以存储,但是要保证,该应用数据有数据量小,更新访问频率频繁的特性。
所以,grpc的服务发现便是用etcd实现的,符合存储控制数据的etcd默认适用场景。(此处有两个疑问,数据量小,参考值多少?更新访问频繁?有多频繁,就目前而言,每个etcd实例支持每秒1000次写操作)
引用etcd官方文档中的一句话,来说明etcd的作用。
Distributed systems use etcd as a consistent key-value store for configuration management, service discovery, and coordinating distributed work. --在分布式系统中,通过etcd的强一致性k-v数据存储来实现,配置管理,服务发现,分布式任务调度。
二、适用场景
服务发现(Service Discovery)
- 服务发现的本质
在分布式系统中,有专门的进程在监听某一TCP或UDP端口,并且支持根据服务名查询到对应服务的IP和端口。
此外,服务发现还分为两种模式,即客户端服务发现与服务端服务发现,这里打个tag后续补充
服务发现,有三大基础缺一不可(一家之言)
1. 一个高可用,强一致性的服务目录(基于Raft算法的etcd天然支持)
> 高可用计算公式:
A=MTBF/MTBF+MTTR
>A:可用性.>平均故障时间(MTBF):Mean Time Between Failure,即相邻两次故障之间的平均工作时间。
>平均修复时间(MTTR):Mean Time To Repair,即数据库系统由故障状态转为工作状态所花费的修理时间的平均值。
2. 服务注册和服务健康状况的监控机制(用户可以在 etcd 中注册服务,并且对注册的服务设置key TTL,定时保持服务的心跳以达到监控健康状态的效果。扩展一下:目前所使用的GPRC服务都会配置一个探活端口,也许etcd就是使用这个端口用于探活)
3. 查找和链接服务的机制(通过在 etcd 指定的主题下注册的服务也能在对应的主题下查找到。为了确保连接,我们可以在每个服务机器上都部署一个 Proxy 模式的 etcd,这样就可以确保能访问 etcd 集群的服务都能互相连接)。
- 服务查找:通过ZK树状目录的思路,很好理解。
- Proxy模式的etcd,这点属于盲区,后续补充
服务发现示意图
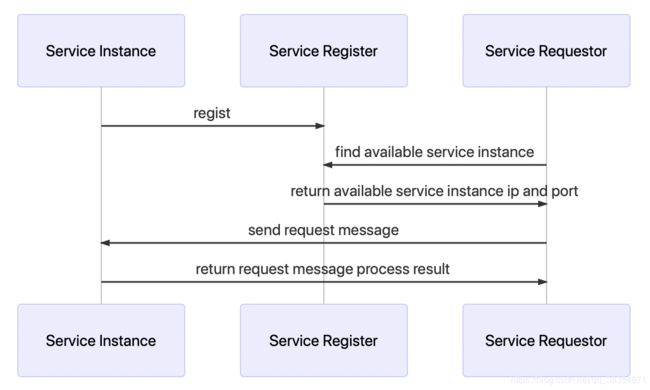
基于etcd的服务发现流程描述
其实很简单,在某一服务启动时,就会在注册中心创建服务目录,在该目录下存储着服务的所有实例的ip和端口。请求发起时,client端会从regist center获取对应ip端口,在结合对应负载均衡策略,选择Service Instance。在此场景中,使用了etcd的数据存储特性完成。
- - 服务的动态添加:同一个应用多个实例,每启动一个,即向Regist Center对应的topic下写入IP端口即可实现。
- - 实例故障与实例重启透明化:个人喜欢借用ESB的思想去理解这个透明化。总结为,对外暴露etcd(Regist Service Data)与对应Topic,即可实现透明化。
订阅发布模型(watcher机制)
在分布式系统中常用的一种模型。etcd和zk同样也支持该模型。相对与MQ来说,etcd和zk更加适用于集群中应用的统一配置管理。例如动态数据源,便是通过ZK实现数据源信息变更的监听机制。就grpc服务的服务发现机制来说,etcd也能实现类似zk的功能。
订阅发布模型的使用场景,可以尝试的理解为,某一组建的统一配置中心。(apllo底层搞不清楚是什么实现的。搞不好核心的控制数据存储就是用的etcd或者zk)
- - 应用中用到的一些配置信息放到 etcd 上进行集中管理。这类场景的使用方式通常是这样:应用在启动的时候主动从 etcd 获取一次配置信息,同时,在 etcd 节点上注册一个 Watcher 并等待,以后每次配置有更新的时候,etcd 都会实时通知订阅者,以此达到获取最新配置信息的目的。
- - 分布式搜索服务中,索引的元信息和服务器集群机器的节点状态存放在 etcd 中,供各个客户端订阅使用。使用 etcd 的key TTL功能可以确保机器状态是实时更新的
- - 日志处理。每个服务都有对应的日志处理单元,日志处理服务单元订阅etcd的对应topic,在服务ip变更后,可动态获取。(配置数据存储仓库)
负载均衡
利用etcd可监控应用健康状态的特性与每个etcd节点都可以独立提供服务的特点。可以利用etcd维护一个负载均衡节点表,根据该节点表,即可找到available节点,在此基础上做负载均衡策略。(类似zookeeper来维持kafka的负载均衡)
分布式通知与协调(watcher机制)
通过注册与异步通知机制,实现分布式环境下不同系统之间的通知与协调,从而对数据变更做到实时处理。实现方式通常是这样:不同系统都在 etcd 上对同一个目录进行注册,同时设置 Watcher 观测该目录的变化(如果对子目录的变化也有需要,可以设置递归模式),当某个系统更新了 etcd 的目录,那么设置了 Watcher 的系统就会收到通知,并作出相应处理。
- - 通过 etcd 进行低耦合的心跳检测。检测系统和被检测系统通过 etcd 上某个目录关联而非直接关联起来,这样可以大大减少系统的耦合性。
- - 完成系统调度。事件触发模型。系统A完成某项处理以后,通过改变etcd目录的值,来通知订阅了该topic的下游系统,实现事件触发模型。(微服务架构下,多服务责任链模式的实现貌似可以用该特性实现。)
分布式锁
得益于基于Raft算法的数据强一致性特性。搞分布式锁这种需要全局唯一性的值的实现,etcd实现起来很容易(没实现过,不知道和基于redis的有啥区别。)锁的两种使用方式,保持独占(悲观锁),控制时序。
- - etcd本身提供了基于CAS算法的原子性操作API,通过设置prevExist值,可以保证在多个节点同时去创建某个目录时,只有一个成功。而创建成功的用户就可以认为是获得了锁。
- - 控制时序,即所有想要获得锁的用户都会被安排执行,但是获得锁的顺序也是全局唯一的,同时决定了执行顺序。etcd 为此也提供了一套 API(自动创建有序键),对一个目录建值时指定为POST动作,这样 etcd 会自动在目录下生成一个当前最大的值为键,存储这个新的值(客户端编号)。同时还可以使用 API 按顺序列出所有当前目录下的键值。此时这些键的值就是客户端的时序,而这些键中存储的值可以是代表客户端的编号。
分布式队列(灵活运用etcd自建有序key的特性的产物)
分布式队列的常规用法与场景五中所描述的分布式锁的控制时序用法类似,即创建一个先进先出的队列,保证顺序。
另一种比较有意思的实现是在保证队列达到某个条件时再统一按顺序执行。这种方法的实现可以在 /queue 这个目录中另外建立一个 /queue/condition 节点。
- - condition 可以表示队列大小。比如一个大的任务需要很多小任务就绪的情况下才能执行,每次有一个小任务就绪,就给这个 condition 数字加 1,直到达到大任务规定的数字,再开始执行队列里的一系列小任务,最终执行大任务。
- - condition 可以表示某个任务在不在队列。这个任务可以是所有排序任务的首个执行程序,也可以是拓扑结构中没有依赖的点。通常,必须执行这些任务后才能执行队列中的其他任务。
- - condition 还可以表示其它的一类开始执行任务的通知。可以由控制程序指定,当 condition 出现变化时,开始执行队列任务。
集群监控与 Leader 竞选
通过 etcd 来进行监控实现起来非常简单并且实时性强。
1. 前面几个场景已经提到 Watcher 机制,当某个节点消失或有变动时,Watcher 会第一时间发现并告知用户。
2. 节点可以设置TTL key,比如每隔 30s 发送一次心跳使代表该机器存活的节点继续存在,否则节点消失。
这样就可以第一时间检测到各节点的健康状态,以完成集群的监控要求。
另外,使用分布式锁,可以完成 Leader 竞选。这种场景通常是一些长时间 CPU 计算或者使用 IO 操作的机器,只需要竞选出的 Leader 计算或处理一次,就可以把结果复制给其他的 Follower。从而避免重复劳动,节省计算资源。
这个的经典场景是搜索系统中建立全量索引。如果每个机器都进行一遍索引的建立,不但耗时而且建立索引的一致性不能保证。通过在 etcd 的 CAS 机制同时创建一个节点,创建成功的机器作为 Leader,进行索引计算,然后把计算结果分发到其它节点。
总结
根据这7中适用场景可以归纳出etcd有以下应用特性(后续补充)
1. 基于Raft算法的强数据一致性特点。可用于分布式系统中,全局性质变量的存储。
2. key TTL(Time To Live)特性(类比redis的key有效时间),实现服务的健康状态监控(根据目前知识推测,是不是key失效以后,所有的订阅者都会接收到该消息?如果是的话,非固定时常的延迟队列既可以利用该特性实现)
3. Topic的概念。(借用kafka的Topic概念,consumer监听的是topic,即监听该topic的所有consumer都可以收到消息。)
4. Watcher机制。