数据结构之线性表
鸟哥说,坚持学习基础才能有出人头地的一天。不能只专注于练武功了,内功也得练。
本篇文章是讲数据结构的第一篇,跟着书好好再过一篇基础。
一、线性表
线性表是n个数据特性相同的元素的组成有限序列,是最基本且常用的一种线性结构(线性表,栈,队列,串和数组都是线性结构),同时也是其他数据结构的基础。
对于非空的线性表或者线性结构的特点:
(1)存在唯一的一个被称作“第一个”的数据元素;
(2)存在唯一的一个被称作“最后一个”的数据元素;
(3)除第一个外,结构中的每个数据元素均只有一个前驱;
(4)除最后一个外,结构中的每个数据元素均只有一个后继;
二、线性表的两种实现方式
1.1顺序表示(顺序表)
概念:用一组地址连续的存储单元依次存储线性表的数据元素,这种存储结构的线性表称为顺序表。
特点:逻辑上相邻的数据元素,物理次序也是相邻的。
只要确定好了存储线性表的起始位置,线性表中任一数据元素都可以随机存取,所以线性表的顺序存储结构是一种随机存取的储存结构,因为高级语言中的数组类型也是有随机存取的特性,所以通常我们都使用数组来描述数据结构中的顺序储存结构,用动态分配的一维数组表示线性表。
1.2 代码实现
以最简单的学生信息管理为例:
首先先创建两个数据结构,如下:
#define maxsize 100 //定义学生最大数量
#define OK 1 //正确标志
#define ERROR 0 //失败标志
//学生信息的数据结构
typedef struct
{
int id; //学生id
char name[30]; //学生姓名
}Student;
//顺序表数据结构
typedef struct
{
Student *elem; //储存空间的基地址
int length; //数据结构的长度
}SqList;
//定义SqList类型的变量
SqList L;这是一个十分简单的例子,这样我们就可以通过L.elem[i-1]访问序号为i的学生信息了。其实这里我们用到了指针数组。如果你对指针数组还不熟悉的话,可以去我写过的另一篇文章看看:https://blog.csdn.net/qq_38378384/article/details/79951651
1.初始化
基本算法:
//初始化顺序表基本算法
Status InitList(SqList &L)
{
//构造一个空的顺序表L
L.elem = new ElemType[maxsize]; //分配内存空间
if(!L.elem) exit(-1);
L.length = 0;
return OK;
}
2.取值
基本算法:
//顺序表取值
Status Get(SqList &L,int i,ElemType &e)
{
if(i<1||i>L.length) return ERROR;
e = L.elem[i-1];
return OK;
}
3.查找
基本算法:
//顺序表查找
int Find(SqList L,ElemType e)
{
//查找值为e的数据元素,返回其序号
for(i=0;i
4.插入
基本算法:
//顺序表插入
Status ListInsert(SqList &L,int i,ElemType e)
{
if((i<1)||(i>L.length+1)) return ERROR; //i不合法
if(L.length == maxsize) return ERROR; //满了
for(j=L.length-1;j>=i-1;j--)
L.elem[j+1]=L.elem[j]; //将第n个至i个位置的元素后移
L.elem[i-1]=e; //将e放进第i个位置
}
5.删除
//顺序表删除
Status ListDelete(SqList &L,int i)
{
//删除第i个元素,i的值为[1,L.length]
if((i<1)||(i>L.length)) return ERROR;
for(j=i;j<=L.length-1;j++)
L.elem[j-1]=L.elem[j];
--L.length; //长度减一
return OK;
}算法都十分的简单,眼尖的你可能发现了,为啥有的参数用的是引用,有的不是呢?
这里我就得讲下使用引用作为形参的作用了,主要有三点:
(1)使用引用作为参数与使用指针作为参数的效果是一样的,形参变化时实参对应也会变化,这个我在上篇文章(我上面给的链接)也有说明,引用只是一个别名。
(2)引用类型作为形参,在内存中并没有产生实参的副本,而使用一般变量作为形参,,形参和实参会分别占用不同给的存储空间,当数据量较大时,使用变量作为形参可能会浪费时间和空间。
(3)虽然使用指针也可以达到引用一样的效果,但是在被调函数中需要重复使用"*指针变量名"来访问,很容易产生错误并且使程序的阅读性变差。
此时你会发现,使用顺序表作为存储时,空间是一次性直接开辟的,所以可能会有空间不足或者浪费空间的情况出现,那么为啥不用一个就分配一个空间呢,再使用一个方式将这些空间串起来不就好了,是时候展现真正的技术了(链表)。
2.1链表
概念:用一组任意的存储单元存储线性表的数据元素(这组存储单元可以是连续的,也可以是不连续的),包括数据域和指针域,数据域存数据,指针域指示其后继的信息。
这里重点讲单链表,如图:
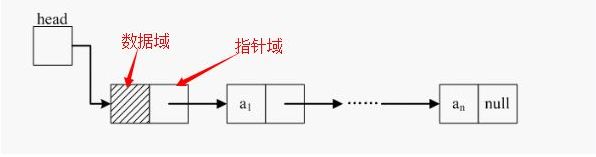
2.1代码实现
//单链表存储结构
typedef struct LNode
{
ElemType data; //数据域
struct LNode *next; //指针域
}LNode,*LinkList;为了提高程序的可阅读性,在此对同一结构体指针类型起了两个名称,LinkList与LNode*,本质上两者是等价的。通常习惯上用LinkList定义单链表,强调定义的是某个单链表的头指针,用LNode *定义指向单链表中任意结点的指针变量。
例如,定义LinkList L,则L为单链表的头指针,若定义LNode *p ,则p为指向单链表中某个结点的指针,用*p代表该结点。
1.初始化
基本算法:
//初始化
Status InitList(LinkList &L)
{
//构造一个单链表
L=new LNode; //生成头结点,用头指针L指向头结点
L->next =NULL;
return OK;
}2.取值
基本算法:
//取值
Status Get(LinkList L,int i,ElemType &e)
{
//在带头结点的单链表L中根据序号I获取元素的值,用e返回L中第i个数据元素的值
p=L->next;
j=1;//计数器
while(p&&jnext;
++j;
}
if(!p||j>i) return ERROR; //不合法
e=p->data; //找到该结点后获取该结点的数据域
return OK;
} 3.查找
基本算法:
//查找
LNode *Find(LinkList L,ElemType e)
{
p=L->next; //使p指向首元结点
while(p && p->data!=e)
{
p=p->next; //不符合条件就一直滚下去
}
return p; //这里有两种情况,找到的时候返回指针p,如果找不到那么这个p则为null,因为最后一个指向的是null
}
4.插入
基本算法:
//插入
Status ListInsert(LinkList &L,int i,ElemType e)
{
//在带头结点的单链表L中第i个位置插入值为e的新结点
p=L;j=0;
while(p&&(jnext; //查找第i-1个结点,p指向该结点
++j;
}
if(!p||j>i-1) return ERROR;
s=new LNode; //生成一个新结点
s->data=e; //将结点*s的数据域置为e
s->next=p->next; //先接尾部
p->next=s; //再接头部
}
5.删除
基本算法:
//删除
Status ListDelete(LinkList &L,int i)
{
//删除第i个元素
p=L;j=0;
while((p->next)&&(jnext; //查找i-1个结点
++j;
}
if(!(p->next)||(j>i-1)) return ERROR; //当i>n或i<1时,不符合条件
q=p->next; //临时保存被删除的地址
p->next=q->next; //将前驱结点指向后驱
delete q; //释放删除结点的空间
return OK;
} 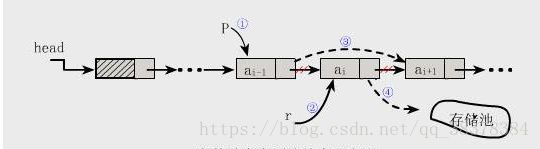
其实单链表可以想象成一列人在玩游戏,每个人都把手搭到后面那个人的肩膀上,每个人身上都有一个大口袋用来放数据,最后一个人没人可以搭就一直悬空着,第一个带头领队的就不用口袋了,它是一个头结点,是用来找到第一个有口袋的人的,也就是首元结点。
这样想的话就简单了,初始化的时候就是用一个人当头结点,它没有口袋,他的手是用来搭到第一个有口袋的人肩膀的,因为这个人还没来,所以它的next是Null,而取值时,通过参数i,我们就可以从首元结点开始数,数到第i个人,找到他后,就可以拿他口袋里面的东西,查找是知道口袋里面东西是什么,想找到这个东西的拥有者,也是一样从首元结点开始找。遍历下去,插入的话,比如要插入第i个位置,那么我们就先找到第i-1个人,然后让新来的手搭到第i个人身上,然后再让第i-1个人把之前放在第i个人的手挪开,放在新来的人的肩膀上,删除操作的话,例如删除第i个人,那么也是先找到第i-1个人,这里的重点是,因为链表的查询只能是从头开始找的,是不能逆回去的,所以我们需要找个变量把要删的那个人的地址先存起来,然后把第i-1个的手放到第i+1个人身上,如果我们不找个变量把那个人的地址存起来,这时候我们就没办法找到他了,因为我们用一个变量临时保存他的地址,于是我们只需要释放这个地址的空间就可以了。
这就是单链表的基本操作,那么如何创建单链表呢?
主要有着两种方法(前插法和后插法)
//前插法创建单链表
void CreateList(LinkList &L,int n)
{
//逆次序输出n个元素的值
L=new LNode;
L->next=NULL;
for(i=0;i>p->data; //输入新结点的数据域内容
p->next=L->next; //将新结点插到头结点之后
L->next=p;
}
} //后插法
void CreateList(LinkList &L,int n)
{
//正次序输入n个元素的值
L=new LNode;
L->next=NULL; //建立一个带头结点的空链表
r=L; //尾指针r指向头结点
for(i=0;i>p->data; //输入新结点的数据域内容
p->next=NULL;
r->next=p; //将新结点插入尾结点之后
r=p; //改变尾指针,使其指向新的尾结点
}
} 两种方式的结果是一样的,区别就是前插法是把新的元素插到最前面,代替了首元结点的位置,就是明摆的插队,而后插法是插到最后面,有点类似于队列。而且后插法多了一个用来指向尾结点的尾指针。
实际上链表还有两种,双向链表和循环链表,循环链表用的比较多,就是把头和尾连起来了,像一个圈一样。这里我就不说明了,因为只要懂了单链表,另外两种理解起来是十分容易的事情。