Redis哨兵模式详解
文章目录
- 哨兵模式
- 什么是哨兵
- 实现哨兵模式
- 1.配置一主两从
- 2.哨兵模式配置
- 3.一个哨兵监控多个Redis主从系统
- 实现原理
- 主观下线
- 客观下线
- 选举领头哨兵
- 故障恢复
在主从模式的Redis系统中,从数据库在整个系统中起到了数据 冗余备份和 读写分离的作用,但是当数据库遇到异常中断服务后,我们只能通过手动的方式选择一个从数据库来升格为主数据库,显然这种方式很麻烦需要人工介入,这时通过哨兵模式可以实现自动化的系统监控和故障恢复。
哨兵模式
什么是哨兵
哨兵的作用是监控Redis系统的运行状态,功能包括以下两个:
| 序号 | 功能 |
|---|---|
| 1 | 监控主数据库和从数据库是否正常运行 |
| 2 | 主数据库出现故障时自动将从数据库转换为主数据库 |
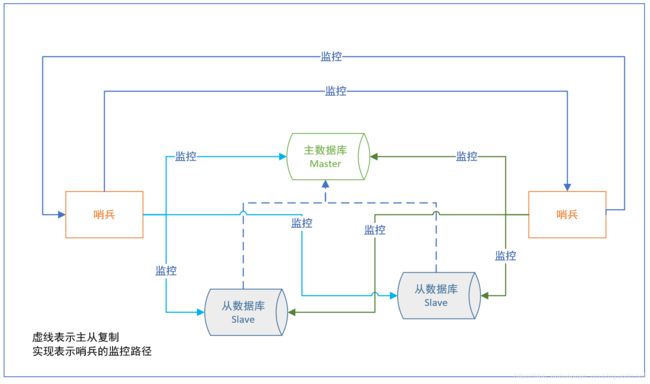
哨兵是一个独立的进程,使用哨兵的典型结构图如下:

在一主多从的Redis系统中,可以使用多个哨兵进行监控任务以保证系统的问题。
实现哨兵模式
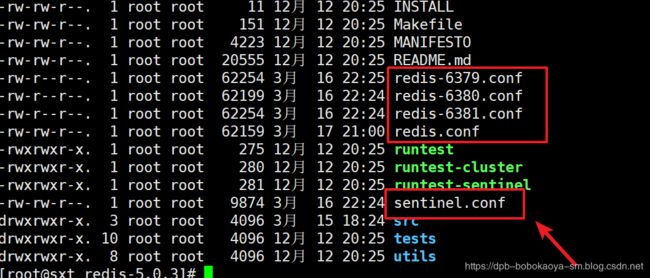
1.配置一主两从
主服务器端口号6379,两个从服务器端口分别为:6380和6381.
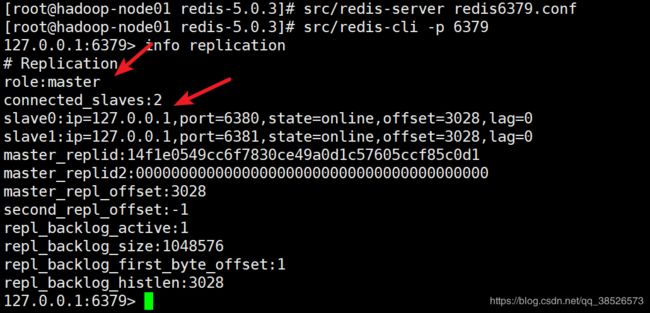
主服务器 6379
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:2
slave0:ip=127.0.0.1,port=6381,state=online,offset=84,lag=0
slave1:ip=127.0.0.1,port=6380,state=online,offset=84,lag=1
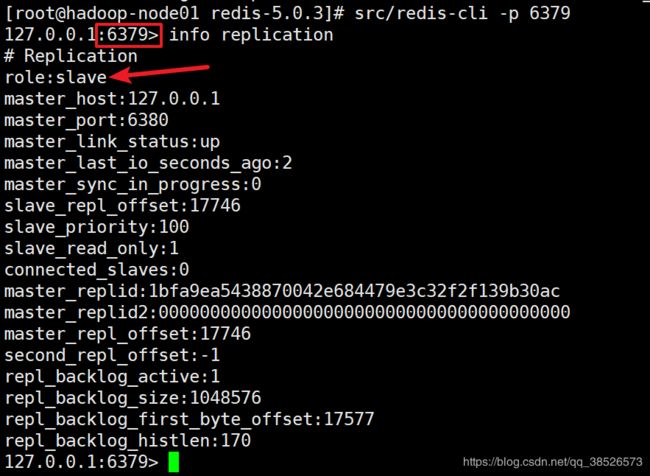
从服务器 6380
127.0.0.1:6380> info replication
# Replication
role:slave
master_host:127.0.0.1
master_port:6379
master_link_status:up
从服务器 6381
127.0.0.1:6381> info replication
# Replication
role:slave
master_host:127.0.0.1
master_port:6379
master_link_status:up
2.哨兵模式配置
修改和redis.conf同级目录下的sentinel.conf文件.

sentinel monitor mymaster 127.0.0.1 6380 1
# sentinel monitor master-name ip redis-port quorum
| 命令 | 用例 | 说明 |
|---|---|---|
| master-name | mymaster | 要监控的主数据库的名称,可以自定义, 组成大小写字母,数字和". - _"组成 |
| ip | 127.0.0.1 | 主数据库(master)的地址 |
| redis-port | 6379 | 主数据库的端口 |
| quorum | 1 | 最低通过的票数 |
启动哨兵模式:
src/redis-sentinel sentinel.conf

哨兵模式只需要配置其监控的主数据库即可,哨兵会自动发现所有复制该数据库的从数据库。
关闭6379master测试
查看6379状态
关闭6379等待一会查看哨兵进程界面

当看到如上图的信息后,我们再查看6380的时候,发现该节点已经变成了master了。

再启动6379我们发现该实例依然是slave并不会改变
3.一个哨兵监控多个Redis主从系统
配置
sentinel monitor mymaster 127.0.0.1 6380 2
sentinel monitor othermaster 192.168.88.60 6380 4
监控不同数据库使用不同的配置参数:
sentinel down-after-millisenconds mymaster 60000
sentinel down-after-millisenconds othermaster 10000
实现原理
哨兵启动后会与要监控的主数据库建立两条连接

和主数据库连接建立完成后,哨兵会使用连接2发送如下命令:
- 每10秒钟哨兵会向主数据库和从数据库发送INFO 命令
- 每2秒钟哨兵会向主数据库和从数据的_sentinel_:hello频道发送自己的消息。
- 每1秒钟哨兵会向主数据、从数据库和其他哨兵节点发送PING命令。
首先,发送INFO命令会返回当前数据库的相关信息(运行id,从数据库信息等)从而实现新节点的自动发现,前面提到的配置哨兵时只需要监控Redis主数据库即可,因为哨兵可以借助INFO命令来获取所有的从数据库信息(slave),进而和这两个从数据库分别建立两个连接。在此之后哨兵会每个10秒钟向已知的主从数据库发送INFO命令来获取信息更新并进行相应的操作。
接下来哨兵向主从数据库的_sentinel_:hello 频道发送信息来与同样监控该数据库的哨兵分享自己的信息。发送信息内容为:
<哨兵的地址>,<哨兵的端口>,<哨兵的运行ID>,<哨兵的配置版本>,
<主数据库的名字>,<主数据库的地址>,<主数据库的端口>,<主数据库的配置版本>

哨兵通过监听的_sentinel_:hello频道接收到其他哨兵发送的消息后会判断哨兵是不是新发现的哨兵,如果是则将其加入已发现的哨兵列表中并创建一个到其的连接(哨兵与哨兵只会创建用来发送PING命令的连接,不会创建订阅频道的连接)。
实现了自定发现从数据库和其他哨兵节点后,哨兵要做的就是定时监控这些数据和节点运行情况,每隔一定时间向这些节点发送PING命令来监控。间隔时间和down-after-milliseconds选项有关,down-after-milliseconds的值小于1秒时,哨兵会每隔down-after-milliseconds指定的时间发送一次PING命令,当down-after-milliseconds的值大于1秒时,哨兵会每隔1秒发送一次PING命令。例如:
// 每隔1秒发送一次PING命令
sentinel down-after-milliseconds mymaster 60000
// 每隔600毫秒发送一次PING命令
sentinel down-after-milliseconds othermaster 600
主观下线
当超过down-after-milliseconds指定时间后,如果被PING的数据库或节点仍然未回复,则哨兵认为其主观下线(subjectively down),主观下线表示从当前的哨兵进程看来,该节点已经下线。
客观下线
在主观下线后,如果该节点是主数据库,则哨兵会进一步判断是否需要对其进行故障恢复,哨兵发送SENTINEL is-master-down-by-addr 命令询问其他哨兵节点以了解他们是否也认为该主数据库主观下线,如果达到指定数量时,哨兵会认为其客观下线(objectively down),并选举领头的哨兵节点对主从系统发起故障恢复。这个指定数量就是前面配置的 quorum参数。
sentinel monitor mymaster 127.0.0.1 6380 2
该配置表示只有当至少有两个Sentinel节点(包括当前节点)认为该主数据库主观下线时,当前哨兵节点才会认为该主数据库客观下线。接下来选举领头哨兵。
选举领头哨兵
当前哨兵虽然发现了主数据客观下线,需要故障恢复,但故障恢复需要由领头哨兵来完成。这样来保证同一时间只有一个哨兵来执行故障恢复,选举领头哨兵的过程使用了Raft算法,具体过程如下:
- 发现主数据库客观下线的哨兵节点(A)向每个哨兵节点发送命令,要求对象选择自己成为领头哨兵
- 如果目标哨兵节点没有选过其他人,则会同样将A设置为领头哨兵
- 如果A发现有超过半数且超过quorum参数值的哨兵节点同样选择自己成为领头哨兵,则A成功成为领头哨兵
- 当有多个哨兵节点同时参选领头哨兵,则会出现没有任何节点当选的可能,此时每个参选节点将等待一个随机事件重新发起参选请求进行下一轮选举,直到选举成功。
故障恢复
选出领头哨兵后,领头哨兵将会开始对主数据库进行故障恢复。步骤如下
- 首先领头哨兵将从停止服务的主数据库的从数据库中挑选一个来充当新的主数据库。
| 序号 | 挑选依据 |
|---|---|
| 1 | 所有在线的从数据库中,选择优先级最高的从数据库。优先级通过replica-priority参数设置 |
| 2 | 优先级相同,则复制的命令偏移量越大(复制越完整)越优先 |
| 3 | 如果以上都一样,则选择运行ID较小的从数据库 |
- 选出一个从数据库后,领头哨兵将向从数据库发送SLAVEOF NO ONE命令使其升格为主数据库,而后领头哨兵向其他从数据库发送 SLAVEOF命令来使其成为新主数据库的从数据库,最后一步则是更新内部的记录,将已经停止服务的旧的主数据库更新为新的主数据库的从数据库,使得当其恢复服务时自动以从数据库的身份继续服务