sqoop和sqoop2的运行原理、安装、操作(1)
一、sqoop和sqoop2的运行原理
sqoop,也有人称之为sqoop1,指版本在sqoop1.4.6之前的版本,sqoop2指的是sqoop1.99之后的下系列,本博客是以sqoop1.4.6和sqoop1.99.5为例。
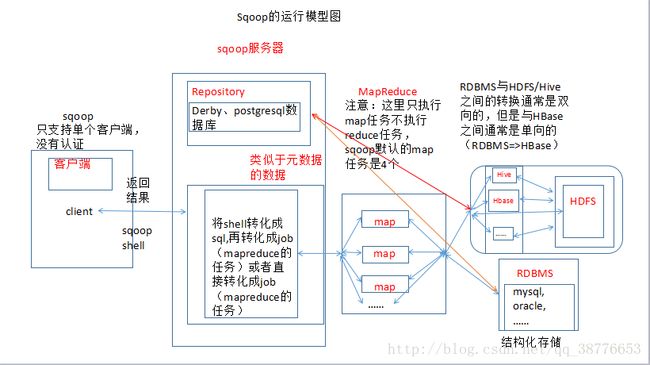

从上图中可以明显的看出是sqoop的运行漏洞比较大,不方便,仓库的数据库支持版本比较少,并且mapreduce任务只支持map,没有运行reduce。这是sqoop和sqoop2在MapReduce上的区别,同时与仓库的连接上也有很大的区别,在sqoop所有的操作对象都必须和仓库进行交互,sqoop2只是Server与仓库进行交互。提高了安全性。
二、sqoop1.4.6的安装
1、安装的前提
一定要有一个hadoop集群并且正常启动,本实例以伪分布式hadoop集群,并能正常启动,需要Hive或者Hbase或者数据库(关系型数据库:mysql或者oracle)时也要讲相应的软件安装好
导入导出的出发点是基于Hadoop角度来说
1)导入 import: RDBMS => Hadoop
2)导出 export: Hadoop => RDBMS
2、解压缩
tar -zxvf sqoop-1.4.6-cdh5.7.0.tar.gz [-C 解压路径]。我这里将解压后的文件重命名为sqoop:mv sqoop-1.4.6-cdh5.7.0 sqoop
3、配置环境变量(可以配置多种文件:本用户下的根目录的.bashrc文件 或者.bash_profile文件或者全局配置文件 /etc/profile )
打开本用户的配置文件.bashrc,配置sqoop的环境路径:
export JAVA_HOME=/usr/java/jdk1.8.0_121
export PATH=$PATH:$JAVA_HOME/bin
export HADOOP_HOME=/home/hadoop/hadoop-2.7.3
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=${HADOOP_HOME}/lib/native"
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HIVE_HOME=/home/hadoop/apache-hive-2.3.0-bin
export PATH=$PATH:$HIVE_HOME/bin
#set tomcat
#注意sqoop就是一个tomcat一定要确保在这里不用配置tomcat的环境变量,否则将启动不起来sqoop
#export CATALINA_BASE=/home/hadoop/apache-tomcat-8.5.20
#export CATALINA_HOME=/home/hadoop/apache-tomcat-8.5.20
#export PATH=$PATH:$CATALINA_HOME/bin
#set sqoop
export SQOOP_HOME=/home/hadoop/sqoop
export PATH=$PATH:$SQOOP_HOME/bin
4、切换到sqoop的安装目录下的配置文件,
在$SQOOP_HOME/conf目录下的sqoop-env.sh文件中添加如下内容:
首先将sqoop-env-template.sh修改或者复制成sqoop-env.sh文件
cd /home/hadoop/sqoop/conf
mv sqoop-env-template.sh sqoop-env.sh
或者cp sqoop-env-template.sh sqoop-env.sh
sqoop-env.sh文件中添加如下内容:
#Set path to where bin/hadoop is available
export HADOOP_COMMON_HOME=/home/hadoop/hadoop-2.7.3
#Set path to where hadoop-*-core.jar is available
export HADOOP_MAPRED_HOME=/home/hadoop/hadoop-2.7.3
#set the path to where bin/hbase is available
#export HBASE_HOME=
#Set the path to where bin/hive is available
export HIVE_HOME=/home/hadoop/apache-hive-2.3.0-bin
5、启动hadoop集群:
start-dfs.sh
start-yarn.sh
mr-jobhistory-daemon.sh start historyserver
hadoop启动之后的进程
[hadoop@Hive ~]$ jps
6497 SecondaryNameNode
3829 ResourceManager
6165 NameNode
6986 Jps
6283 DataNode
6732 NodeManager
6911 JobHistoryServe
将mysql的连接驱动移到sqoop里面$SQOOP_HOME/lib
cp mysql-connector-java-5.1.28-bin.jar /home/hadoop/sqoop/lib6、sqoop的命令
查看sqoop的用法:sqoop help
[hadoop@Hive ~]$ sqoop help
Warning: /home/hadoop/sqoop/../hbase does not exist! HBase imports will fail.
Please set $HBASE_HOME to the root of your HBase installation.
Warning: /home/hadoop/sqoop/../hcatalog does not exist! HCatalog jobs will fail.
Please set $HCAT_HOME to the root of your HCatalog installation.
Warning: /home/hadoop/sqoop/../accumulo does not exist! Accumulo imports will fail.
Please set $ACCUMULO_HOME to the root of your Accumulo installation.
Warning: /home/hadoop/sqoop/../zookeeper does not exist! Accumulo imports will fail.
Please set $ZOOKEEPER_HOME to the root of your Zookeeper installation.
17/09/02 13:10:24 INFO sqoop.Sqoop: Running Sqoop version: 1.4.6-cdh5.7.0
usage: sqoop COMMAND [ARGS]
这些警告都不需要在意,这是sqoop用的几个场景。
Available commands:
codegen Generate code to interact with database records
create-hive-table Import a table definition into Hive
eval Evaluate a SQL statement and display the results
export Export an HDFS directory to a database table
help List available commands
import Import a table from a database to HDFS
import-all-tables Import tables from a database to HDFS
import-mainframe Import datasets from a mainframe server to HDFS
job Work with saved jobs
list-databases List available databases on a server
list-tables List available tables in a database
merge Merge results of incremental imports
metastore Run a standalone Sqoop metastore
version Display version information
See 'sqoop help COMMAND' for information on a specific command.
sqoop help COMMAND :可以查看帮助文档
6.1 list-databases
------------------
执行sqoop list-databases时会出现错误:
Error: Required argument --connect is missing.
Try --help for usage instructions.
查看帮助文档
sqoop help list-databases
Common arguments:
--connect Specify JDBC connect string
--connection-manager Specify connection manager
class name
--connection-param-file Specify connection
parameters file
--driver Manually specify JDBC
driver class to use
--hadoop-home Override
$HADOOP_MAPRED_HOME_ARG
--hadoop-mapred-home Override
$HADOOP_MAPRED_HOME_ARG
--help Print usage instructions
-P Read password from console
--password Set authentication
password
--password-alias Credential provider
password alias
--password-file Set authentication
password file path
--relaxed-isolation Use read-uncommitted
isolation for imports
--skip-dist-cache Skip copying jars to
distributed cache
--username Set authentication
username
--verbose Print more information
while working
Generic Hadoop command-line arguments:
(must preceed any tool-specific arguments)
Generic options supported are
-conf file> specify an application configuration file
-D <property=value> use value for given property
-fs <local|namenode:port> specify a namenode
-jt <local|resourcemanager:port> specify a ResourceManager
-files list of files> specify comma separated files to be copied to the map reduce cluster
-libjars list of jars> specify comma separated jar files to include in the classpath.
-archives list of archives> specify comma separated archives to be unarchived on the compute machines.
The general command line syntax is
bin/hadoop command [genericOptions] [commandOptions]
查看mysql数据库里面的数据库列表: 并不需要跑mr作业,直接通过MySQLManager获取即可
--------------------------------------------------
sqoop list-databases \
--connect jdbc:mysql://mysql所在的主机IP:3306 \
--username root \
--password mysql
查看指定数据库里面表的列表
-------------
sqoop list-tables \
--connect jdbc:mysql://ip:3306/数据库名 \
--username root \
--password mysql
sqoop import 命令:
usage: sqoop import [GENERIC-ARGS] [TOOL-ARGS]
Common arguments:
--connect Specify JDBC connect
string
--connection-manager Specify connection manager
class name
--connection-param-file Specify connection
parameters file
--driver Manually specify JDBC
driver class to use
--hadoop-home Override
$HADOOP_MAPRED_HOME_ARG
--hadoop-mapred-home Override
$HADOOP_MAPRED_HOME_ARG
--help Print usage instructions
-P Read password from console
--password Set authentication
password
--password-alias Credential provider
password alias
--password-file Set authentication
password file path
--relaxed-isolation Use read-uncommitted
isolation for imports
--skip-dist-cache Skip copying jars to
distributed cache
--username Set authentication
username
--verbose Print more information
while working
Import control arguments:
--append Imports data
in append
mode
--as-avrodatafile Imports data
to Avro data
files
--as-parquetfile Imports data
to Parquet
files
--as-sequencefile Imports data
to
SequenceFile
s
--as-textfile Imports data
as plain
text
(default)
--autoreset-to-one-mapper Reset the
number of
mappers to
one mapper
if no split
key
available
--boundary-query Set boundary
query for
retrieving
max and min
value of the
primary key
--columns Columns to
import from
table
--compression-codec Compression
codec to use
for import
--delete-target-dir Imports data
in delete
mode
--direct Use direct
import fast
path
--direct-split-size Split the
input stream
every 'n'
bytes when
importing in
direct mode
-e,--query Import
results of
SQL
'statement'
--fetch-size Set number
'n' of rows
to fetch
from the
database
when more
rows are
needed
--inline-lob-limit Set the
maximum size
for an
inline LOB
-m,--num-mappers Use 'n' map
tasks to
import in
parallel
--mapreduce-job-name Set name for
generated
mapreduce
job
--merge-key Key column
to use to
join results
--split-by Column of
the table
used to
split work
units
--split-limit Upper Limit
of rows per
split for
split
columns of
Date/Time/Ti
mestamp and
integer
types. For
date or
timestamp
fields it is
calculated
in seconds.
split-limit
should be
greater than
0
--table Table to
read
--target-dir HDFS plain
table
destination
--validate Validate the
copy using
the
configured
validator
--validation-failurehandler Fully
qualified
class name
for
ValidationFa
ilureHandler
--validation-threshold Fully
qualified
class name
for
ValidationTh
reshold
--validator Fully
qualified
class name
for the
Validator
--warehouse-dir HDFS parent
for table
destination
--where WHERE clause
to use
during
import
-z,--compress Enable
compression
Incremental import arguments:
--check-column Source column to check for incremental
change
--incremental Define an incremental import of type
'append' or 'lastmodified'
--last-value Last imported value in the incremental
check column
Output line formatting arguments:
--enclosed-by Sets a required field enclosing
character
--escaped-by Sets the escape character
--fields-terminated-by Sets the field separator character
--lines-terminated-by Sets the end-of-line character
--mysql-delimiters Uses MySQL's default delimiter set:
fields: , lines: \n escaped-by: \
optionally-enclosed-by: '
--optionally-enclosed-by Sets a field enclosing character
Input parsing arguments:
--input-enclosed-by Sets a required field encloser
--input-escaped-by Sets the input escape
character
--input-fields-terminated-by Sets the input field separator
--input-lines-terminated-by Sets the input end-of-line
char
--input-optionally-enclosed-by Sets a field enclosing
character
Hive arguments:
--create-hive-table Fail if the target hive
table exists
--hive-database Sets the database name to
use when importing to hive
--hive-delims-replacement Replace Hive record \0x01
and row delimiters (\n\r)
from imported string fields
with user-defined string
--hive-drop-import-delims Drop Hive record \0x01 and
row delimiters (\n\r) from
imported string fields
--hive-home Override $HIVE_HOME
--hive-import Import tables into Hive
(Uses Hive's default
delimiters if none are
set.)
--hive-overwrite Overwrite existing data in
the Hive table
--hive-partition-key Sets the partition key to
use when importing to hive
--hive-partition-value Sets the partition value to
use when importing to hive
--hive-table Sets the table name to use
when importing to hive
--map-column-hive Override mapping for
specific column to hive
types.
HBase arguments:
--column-family Sets the target column family for the
import
--hbase-bulkload Enables HBase bulk loading
--hbase-create-table If specified, create missing HBase tables
--hbase-row-key Import to in HBase
HCatalog arguments:
--hcatalog-database HCatalog database name
--hcatalog-home Override $HCAT_HOME
--hcatalog-partition-keys Sets the partition
keys to use when
importing to hive
--hcatalog-partition-values Sets the partition
values to use when
importing to hive
--hcatalog-table HCatalog table name
--hive-home Override $HIVE_HOME
--hive-partition-key Sets the partition key
to use when importing
to hive
--hive-partition-value Sets the partition
value to use when
importing to hive
--map-column-hive Override mapping for
specific column to
hive types.
HCatalog import specific options:
--create-hcatalog-table Create HCatalog before import
--hcatalog-storage-stanza HCatalog storage stanza for table
creation
Accumulo arguments:
--accumulo-batch-size Batch size in bytes
--accumulo-column-family Sets the target column family for
the import
--accumulo-create-table If specified, create missing
Accumulo tables
--accumulo-instance Accumulo instance name.
--accumulo-max-latency Max write latency in milliseconds
--accumulo-password Accumulo password.
--accumulo-row-key Import to in Accumulo
--accumulo-user Accumulo user name.
--accumulo-visibility Visibility token to be applied to
all rows imported
--accumulo-zookeepers Comma-separated list of
zookeepers (host:port)
Code generation arguments:
--bindir Output directory for compiled
objects
--class-name Sets the generated class name.
This overrides --package-name.
When combined with --jar-file,
sets the input class.
--input-null-non-string Input null non-string
representation
--input-null-string Input null string representation
--jar-file Disable code generation; use
specified jar
--map-column-java Override mapping for specific
columns to java types
--null-non-string Null non-string representation
--null-string Null string representation
--outdir Output directory for generated
code
--package-name Put auto-generated classes in
this package
Generic Hadoop command-line arguments:
(must preceed any tool-specific arguments)
Generic options supported are
-conf file> specify an application configuration file
-D <property=value> use value for given property
-fs <local|namenode:port> specify a namenode
-jt <local|resourcemanager:port> specify a ResourceManager
-files list of files> specify comma separated files to be copied to the map reduce cluster
-libjars list of jars> specify comma separated jar files to include in the classpath.
-archives list of archives> specify comma separated archives to be unarchived on the compute machines.
The general command line syntax is
bin/hadoop command [genericOptions] [commandOptions]
At minimum, you must specify --connect and --table
Arguments to mysqldump and other subprograms may be supplied
after a '--' on the command line.
[hadoop@Hive ~]$ jps
8963 NodeManager
8469 DataNode
8677 SecondaryNameNode
8844 ResourceManager
12204 Jps
12110 Sqoop
6911 JobHistoryServer
8351 NameNode
三、将mysql里面的表导入到hdfs里面,
sqoop import \
--connect jdbc:mysql://ip:3306/tableName \ 数据库连接的url
--username root \ 数据库的用户名
--password mysql \ 数据库的密码
--table emp \ 要操作的mysql数据库的表
-m 1 分成map的数量
有时会出现错误:
Exception in thread "main" java.lang.NoClassDefFoundError: org/json/JSONObject
这是json的jar包没导成功
将json的jar包java-json.jar导到sqoop的lib下面
mv java-json.jar ~/sqoop/lib
默认导入HDFS路径:/user/用户名/表名
重复执行第二次时会出现这样的错误:
ExistsException: Output directory hdfs://Hive:9000/user/hadoop/emp already exists
解决方案:
1)手工把存在的目录删除
2)sqoop有参数控制
sqoop import \
--connect jdbc:mysql://ip:3306/sqoop \
--username root --password root \
--delete-target-dir \
--table EMP -m 1

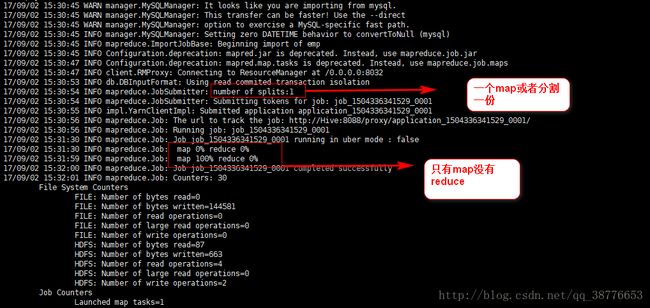


导入数据并设置mapreduce作业的名字
sqoop import \
--connect jdbc:mysql://192.168.170.111:3306/sqoop \
--username root --password mysql \
--delete-target-dir \ 开启自动删除目标文件夹
--mapreduce-job-name FromMySQLToHDFS \ 给job起别名,默认是数据库表名.job
--table emp -m 1
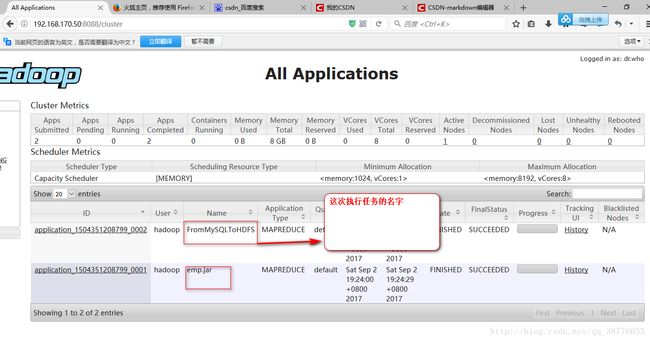
导入指定的列的数据
sqoop import \
--connect jdbc:mysql://192.168.170.111:3306/sqoop \
--username root --password mysql\
--delete-target-dir \
--target-dir EMP_COLUMN \ 指定hdfs的生成目录
--columns "EMPNO,ENAME,JOB,SAL,COMM" \指定查询的列名
--mapreduce-job-name FromMySQLToHDFS \
--table emp -m 1
[hadoop@Hive ~]$ hadoop fs -ls /user/hadoop/EMP_COLUMN/*
-rw-r--r-- 1 hadoop supergroup 0 2017-09-02 19:39 /user/hadoop/EMP_COLUMN/_SUCCESS
-rw-r--r-- 1 hadoop supergroup 397 2017-09-02 19:39 /user/hadoop/EMP_COLUMN/part-m-00000
[hadoop@Hive ~]$ hadoop fs -text /user/hadoop/EMP_COLUMN/*
7369,SMITH,CLERK,800,null
7499,ALLEN,SALESMAN,1600,300
7521,WARD,SALESMAN,1250,500
7566,JONES,MANAGER,2975,null
7654,MARTIN,SALESMAN,1250,1400
7698,BLAKE,MANAGER,2850,null
7782,CLARK,MANAGER,2450,null
7788,SCOTT,ANALYST,3000,null
7839,KING,PRESIDENT,5000,null
7844,TURNER,SALESMAN,1500,0
7876,ADAMS,CLERK,1100,null
7900,JAMES,CLERK,950,null
7902,FORD,ANALYST,3000,null
7934,MILLER,CLERK,1300,null
导入数据并以parquet的格式存储,并指定两个map作业
sqoop import \
--connect jdbc:mysql://192.168.170.111:3306/sqoop \
--username root --password mysql \
--delete-target-dir \
--target-dir EMP_COLUMN_PARQUET \
--as-parquetfile \ hdfs的文件存储格式
--columns "EMPNO,ENAME,JOB,SAL,COMM" \
--mapreduce-job-name FromMySQLToHDFS \
--table emp \
-m 2 \指定map的数量

生成后的文件结构,由于这种文件存储格式不能够查看出来。

导入数据并设置分隔符
sqoop import \
--connect jdbc:mysql://192.168.170.111:3306/sqoop \
--username root --password mysql \
--delete-target-dir \
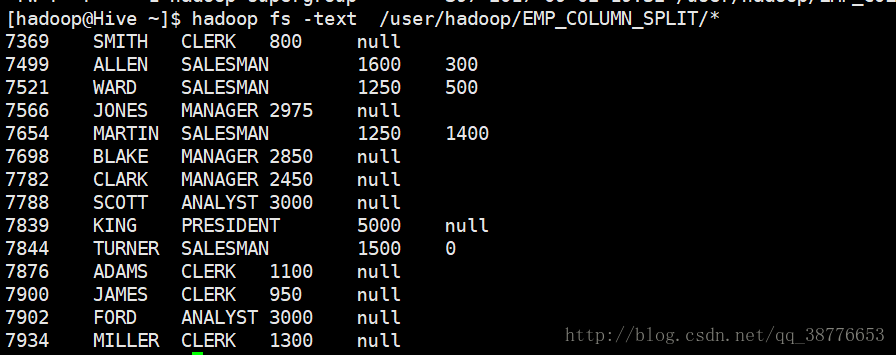
--target-dir EMP_COLUMN_SPLIT \
--columns "EMPNO,ENAME,JOB,SAL,COMM" \
--mapreduce-job-name FromMySQLToHDFS \
--fields-terminated-by '\t' \字段之间以制表符分割,默认是按照,分割
--lines-terminated-by '\n' \行之间按照换行符
--table emp -m 2
指定hdfs文件的压缩格式
文件常用的压缩格式的codec:

sqoop import \
--connect jdbc:mysql://192.168.170.111:3306/sqoop \
--username root --password mysql \
--delete-target-dir \
--target-dir EMP_COLUMN_Zlib \
--mapreduce-job-name FromMySQLToHDFS \
--fields-terminated-by '\t' --lines-terminated-by '\n' \
--table emp -m 2 \
--compression-codec org.apache.hadoop.io.compress.DefaultCodec
[hadoop@Hive ~]$ hadoop fs -ls /user/hadoop/EMP_COLUMN_Zlib/*
-rw-r--r-- 1 hadoop supergroup 0 2017-09-02 20:03 /user/hadoop/EMP_COLUMN_Zlib/_SUCCESS
-rw-r--r-- 1 hadoop supergroup 130 2017-09-02 20:03 /user/hadoop/EMP_COLUMN_Zlib/part-m-00000.deflate
-rw-r--r-- 1 hadoop supergroup 240 2017-09-02 20:03 /user/hadoop/EMP_COLUMN_Zlib/part-m-00001.deflate
[hadoop@Hive ~]$ hadoop fs -text /user/hadoop/EMP_COLUMN_Zlib/*
17/09/02 20:04:58 INFO zlib.ZlibFactory: Successfully loaded & initialized native-zlib library
17/09/02 20:04:58 INFO compress.CodecPool: Got brand-new decompressor [.deflate]
7369 SMITH CLERK 7902 1980-12-17 800 null 20
7499 ALLEN SALESMAN 7698 1981-02-20 1600 300 30
7521 WARD SALESMAN 7698 1981-02-22 1250 500 30
7566 JONES MANAGER 7839 1981-04-02 2975 null 20
17/09/02 20:04:58 INFO compress.CodecPool: Got brand-new decompressor [.deflate]
7654 MARTIN SALESMAN 7698 1981-09-28 1250 1400 30
7698 BLAKE MANAGER 7839 1981-05-01 2850 null 30
7782 CLARK MANAGER 7839 1981-06-09 2450 null 10
7788 SCOTT ANALYST 7566 1987-07-13 3000 null 20
7839 KING PRESIDENT null 1981-11-17 5000 null 10
7844 TURNER SALESMAN 7698 1981-09-08 1500 0 30
7876 ADAMS CLERK 7788 1987-07-13 1100 null 20
7900 JAMES CLERK 7698 1981-12-03 950 null 30
7902 FORD ANALYST 7566 1981-12-03 3000 null 20
7934 MILLER CLERK 7782 1982-01-23 1300 null 10
将null值用别的字符代替
sqoop import \
--connect jdbc:mysql://192.168.170.111:3306/sqoop \
--username root --password mysql \
--delete-target-dir \
--target-dir EMP_COLUMN_Zlib \
--mapreduce-job-name FromMySQLToHDFS \
--fields-terminated-by '\t' --lines-terminated-by '\n' \
--table emp -m 2 --null-string '0' --null-non-string '0'
–null-string ‘0’ –null-non-string ‘0’必须同时出现才有效果
[hadoop@Hive ~]$ hadoop fs -text /user/hadoop/EMP_COLUMN_Zlib/*
7369 SMITH CLERK 7902 1980-12-17 800 0 20
7499 ALLEN SALESMAN 7698 1981-02-20 1600 300 30
7521 WARD SALESMAN 7698 1981-02-22 1250 500 30
7566 JONES MANAGER 7839 1981-04-02 2975 0 20
7654 MARTIN SALESMAN 7698 1981-09-28 1250 1400 30
7698 BLAKE MANAGER 7839 1981-05-01 2850 0 30
7782 CLARK MANAGER 7839 1981-06-09 2450 0 10
7788 SCOTT ANALYST 7566 1987-07-13 3000 0 20
7839 KING PRESIDENT 0 1981-11-17 5000 0 10
7844 TURNER SALESMAN 7698 1981-09-08 1500 0 30
7876 ADAMS CLERK 7788 1987-07-13 1100 0 20
7900 JAMES CLERK 7698 1981-12-03 950 0 30
7902 FORD ANALYST 7566 1981-12-03 3000 0 20
7934 MILLER CLERK 7782 1982-01-23 1300 0 10
利用条件查询:
sqoop import \
--connect jdbc:mysql://192.168.170.111:3306/sqoop \
--username root --password mysql \
--delete-target-dir \
--target-dir EMP_COLUMN_WHERE \
--columns "EMPNO,ENAME,JOB,SAL,COMM" \
--mapreduce-job-name FromMySQLToHDFS \
--where 'SAL>2000' \
--fields-terminated-by '\t' --lines-terminated-by '\n' \
--table emp -m 2
sqoop import \
--connect jdbc:mysql://192.168.170.111:3306/sqoop \
--username root --password mysql \
--delete-target-dir \
--target-dir EMP_COLUMN_QUERY \
--query 'select * from emp where SAL>2000' \
--mapreduce-job-name FromMySQLToHDFS \
--fields-terminated-by '\t' --lines-terminated-by '\n' \
--table emp -m 2
会报错:
17/09/02 20:31:22 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead.
Cannot specify --query and --table together.
去掉–table之后还会报错
When importing query results in parallel, you must specify --split-by.
增加–split-by ‘EMPNO’
还会报错:
17/09/02 20:36:51 ERROR tool.ImportTool: Encountered IOException running import job: java.io.IOException: Query [select * from emp where SAL>2000] must contain '$CONDITIONS' in WHERE clause.
sql语句后增加and $CONDITIONS,
sqoop import \
--connect jdbc:mysql://192.168.170.111:3306/sqoop \
--username root --password mysql \
--delete-target-dir \
--target-dir EMP_COLUMN_QUERY \
--query 'select * from emp where SAL>2000 and $CONDITIONS' \
--mapreduce-job-name FromMySQLToHDFS \
--fields-terminated-by '\t' --lines-terminated-by '\n' \
-m 2 \
--split-by 'EMPNO'
–query: 里面不仅支持单表,也支持多表的(比如: select * from a join b join c on a.x=b.x and b.x=c.x)
sqoop import \
--connect jdbc:mysql://192.168.170.111:3306/sqoop \
--username root --password mysql \
--delete-target-dir \
--target-dir EMP_COLUMN_QUERY \
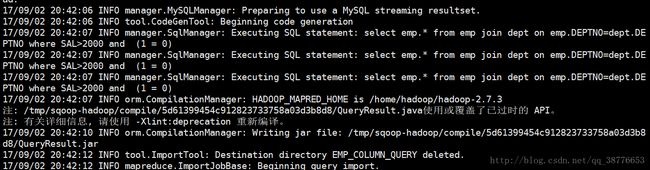
--query 'select emp.* from emp join dept on emp.DEPTNO=dept.DEPTNO where SAL>2000 and $CONDITIONS' \
--mapreduce-job-name FromMySQLToHDFS \
--fields-terminated-by '\t' --lines-terminated-by '\n' \
-m 2 \
--split-by 'EMPNO'
执行一个脚本导入:
编辑文件test.text
指令和参数必须换行
import
--connect
jdbc:mysql://localhost:3306/sqoop
--username
root
--password
root
--delete-target-dir
--target-dir
EMP_OPTIONS_FILE
--mapreduce-job-name
FromMySQLToHDFS
--table
EMP
-m
1
执行命令:
sqoop --options-file test.text
四、从hdfs中导出到mysql
保证数据库里面必须有导入的数据库的数据库和表及表结构
CREATE TABLE emp_load AS SELECT * FROM emp WHERE 1=2;
sqoop export \
--connect jdbc:mysql://192.168.170.111:3306/sqoop \
--username root --password mysql \
--table emp_load \ 导入的数据库的表
--export-dir /user/hadoop/emp \ 需要导出的文件
-m 1
如果在同一张表中执行两次,会将数据追加
sqoop export \
--connect jdbc:mysql://192.168.170.111:3306/sqoop \
--username root --password mysql \
--table emp_load \
--columns "EMPNO,ENAME,JOB,SAL,COMM" \ 只导入表的字段,不要求字段相邻
--export-dir /user/hadoop/EMP_COLUMN \
-m 1

sqoop export \
--connect jdbc:mysql://192.168.170.111:3306/sqoop \
--username root --password mysql \
--table emp_load \
--columns "EMPNO,ENAME,JOB,SAL,COMM" \
--fields-terminated-by '\t' --lines-terminated-by '\n' \
分割方式
--export-dir /user/hadoop/EMP_COLUMN_SPLIT \
--direct \
-m 1
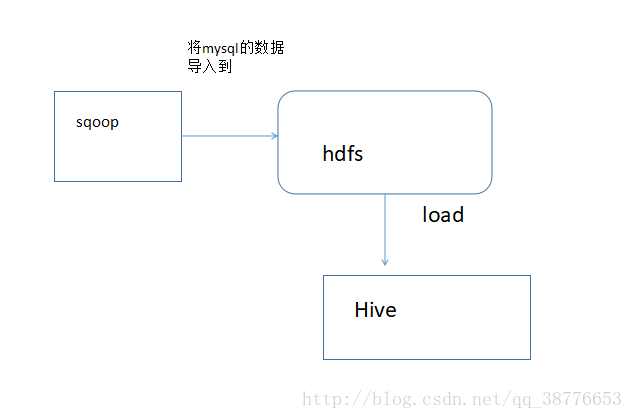
五、将mysql导入hive的hdfs
Hive arguments:
**--create-hive-table** Fail if the target hive
table exists
**--hive-database ** Sets the database name to
use when importing to hive
--hive-delims-replacement Replace Hive record \0x01
and row delimiters (\n\r)
from imported string fields
with user-defined string
--hive-drop-import-delims Drop Hive record \0x01 and
row delimiters (\n\r) from
imported string fields
--hive-home Override $HIVE_HOME
**--hive-import** Import tables into Hive
(Uses Hive's default
delimiters if none are
set.)
--hive-overwrite Overwrite existing data in
the Hive table
**--hive-partition-key key >** Sets the partition key to
use when importing to hive
**--hive-partition-value value>** Sets the partition value to
use when importing to hive
**--hive-table <table-name>** Sets the table name to use
when importing to hive
**--map-column-hive ** Override mapping for
specific column to hive
types.
sqoop import \
--connect jdbc:mysql://192.168.170.111:3306/sqoop \
--username root --password mysql \
--table emp \
--delete-target-dir \
--hive-import --create-hive-table --hive-table emp_import \
-m 1
报错:
tool.ImportTool: Encountered IOException running import job: java.io.IOException: java.lang.ClassNotFoundException: org.apache.hadoop.hive.conf.HiveConf
解决方案:
将hive中的hive-shims*.jar和hive-common….jar拷贝到sqoop的lib下
cp hive-shims*.jar /home/hadoop/sqoop/lib
cp hive-common*.jar /home/hadoop/sqoop/lib