Inceptionv4论文详解
原文地址:
https://arxiv.org/pdf/1602.07261.pdf
论文目标:
将最先进的Inception和Residual结构结合起来同时也提出了我们不含残差结构的inception v4,以求达到性能上的进一步提升。
论文工作:
比较两种纯粹的Inception变体,Inception-v3和v4,以及类似昂贵的混合Inception-ResNet版本。
关于Residual的一个讨论:
原作者认为,对于训练非常深的卷积模型,残留连接本质上是必需的。我们的发现似乎并不支持这种观点,至少对于图像识别来说。但是,它可能需要更多的测量点和更深的架构来了解剩余连接提供的有益方面的真实程度。在实验部分,我们证明了在不利用剩余连接的情况下训练竞争非常深的网络并不是很困难。然而,使用残余连接似乎大大提高了训练速度,这仅仅是它们使用的一个很好的论据。
Inception V4的构建过程:
1.纯Inception块的构建:
以往inception块的构建包袱:
以往的inception网络,我们对inceptin结构方面的选择比较保守,没有在结构上做很大的改动。以前结构的保守、固定直接导致了网络和结构的灵活性欠佳。反而导致网络看起来更复杂。
我们这次做的工作:
摆脱以往的包袱,我们做了一个统一,为每一个Inception块做出统一的选择。
Inception V4网络结构:
总网络结构:
值得注意的是,在网络的最后,softmax层之前, 使用了keep prob为0.8的drop out来防止过拟合。

子模块:(图中没有标记为“V”的所有卷积是相同填充的,意味着它们的输出网格与其输入的大小相匹配)
1.stem模块:
该模块解读:
我们发现Stem中使用了Inception V3中使用的并行结构、不对称卷积核结构,可以在保证信息损失足够小的情况下,使得计算量降低。结构中1*1的卷积核也用来降维,并且也增加了非线性。图中带V的标记说明该卷积核使用valid padding,其余的使用same padding。之后的结构也是这样。我们发现这个stem结构实际上是替代了Inception V3中第一个Inception block之前的结构,在V3中仅仅是一些3*3卷积核的堆积,输出的feature map为35*35*288,而在这里结构更加复杂、层次更深,输出的feature map为35*35*384,比V3的也更多。但是这一方案也在一定程度上保证了计算量。

2.Inception-A模块
模块解读:
我们发现这三个结构和Inception V3中的三种Inception block的结构一样。
不同之处在于,在这里,三种Inception block的个数分别为4、7、3个,而V3中为3、5、2个,因此新的Inception层次更深、结构更复杂,feature map的channel更多,为了降低计算量,在Inception-A和Inception-B后面分别添加了Reduction-A和Reduction-B的结构,用来降低计算量。
3.Inception-B模块

4.Inception-C模块
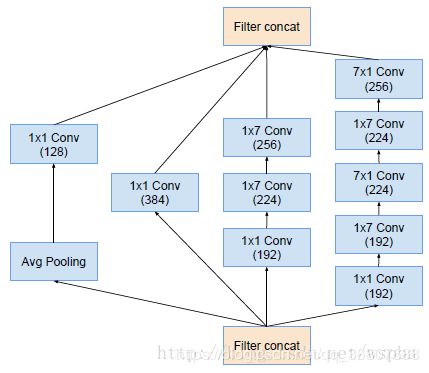
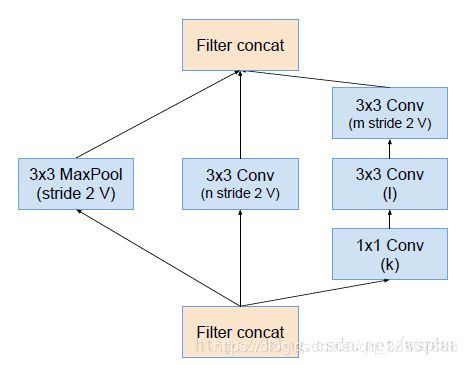
5.redution-A模块
模块解读:
我们发现这两种结构中,卷积的步长(stride)为2,并且都是用了valid padding,来降低feature map的尺寸。结构中同样是用并行、不对称卷积和1*1的卷积来降低计算量。

6.redution-B模块
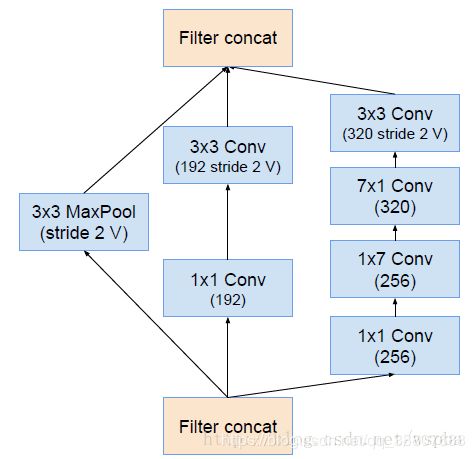
2.在和resnet结合的版本中,我们使用了更简单的Inception块。
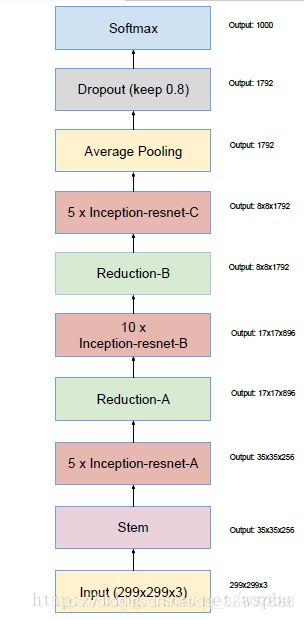
1.Inception-ResNet-v1结构:
总体结构:
在网络的最后,softmax之前,同样是用了drop out。文章中,作者还提到了,在traditional layers的前面添加了BN层,笔者认为,就是在每一个Inception-ResNet block中Residual function的最前面添加BN。值得一提的是,虽然层次变得更深了,这个Inception-ResNet-v1的计算量仍然只和Inception V3大致相同。
子模块结构:
1.stem结构:
我们发现,为了保证计算量是cheap的,这里使用了和Inception V3中很类似的结构,只不过channel的数量有些许不同。

2.Inception-ResNet-A结构:
这三种block的数量分别为5、10、5个,相比之前更多了,我们发现每一个block中都使用了identity connection(源自于ResNet),也就是ReLU之前的+号。而block右部的residual function可以看成是简化版的Inception,结构和参数量都比传统的Inception block要小,并且后面都使用1*1的滤波器进行连接,主要用来进行维度匹配。
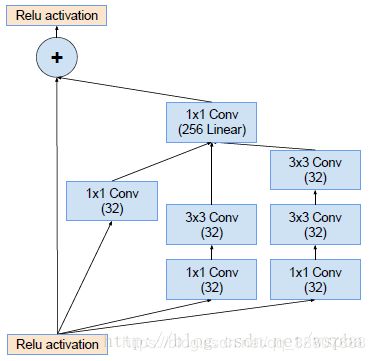
3.Inception-ResNet-B结构:
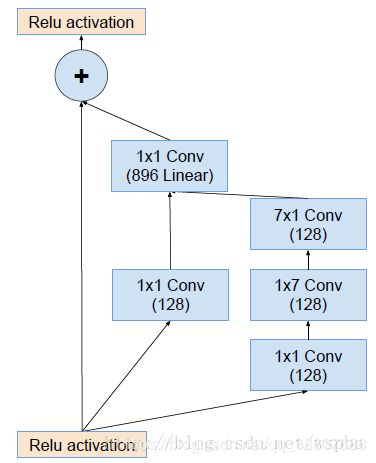
4.Inception-ResNet-C结构:
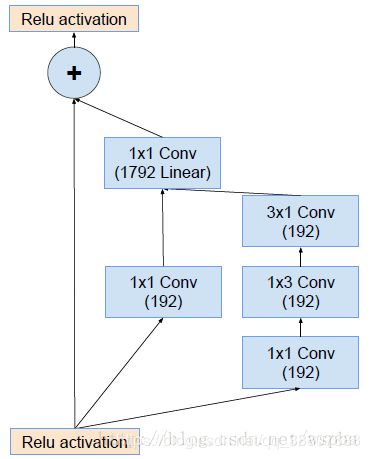
5.Reduction-A结构:
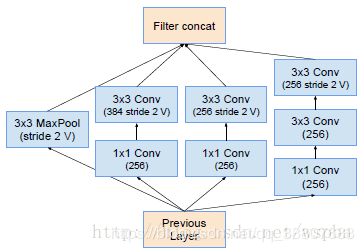
与Inception V4相同的是,在Inception-ResNet-A及Inception-ResNet-B后分别添加了Reduction-A和Reduction-B,其中Reduction-A的结构与Inception V4的一致,Reduction-B的结构如下。
6.Reduction-B结构:
2.Inception-ResNet-v2结构:
Inception-ResNet-v2的整体框架和Inception-ResNet-v1的一致。
只不过v2的计算量更加expensive些,它的stem结构与Inception V4的相同,Reduction-A与v1的相同,Inception-ResNet-A、Inception-ResNet-B、Inception-ResNet-C和Reduction-B的结构与v1的类似,只不过输出的channel数量更多。总的来说,Inception-ResNet-v2与Inception V4的相近。在Inception-ResNet-v2中同样使用了drop out和BN。
模型训练:
1.使用TensorFlow [1]分布式机器学习系统
2.我们之前的实验使用动量,衰减为0.9的SGD,而我们的最佳模型是使用RMSProp 和衰减0.9和ε=1.0实现的。
3.0.045的学习率,每两个时期使用0.94的指数率衰减。
问题讨论:
1.缩放残差:
作者发现,当一个Residual function中滤波器的数量超过1000时,这个block变得不稳定,训练容易出现‘died’的现象,产生的输出只为0,这明显是不可以的,并且通过降低学习率、增加额外的BN都无法解决这个问题。
作者给出的解决办法是,在Residual function之后、激活函数之前,使用一个activation scaling的操作能够稳定训练,其中缩放因子为0.1到0.3。至于这么做的原因,笔者就不得而知了,希望能够获得大家的指教。(缩放模块只是通过一个合适的常数来缩放最后一次线性激活,通常在0.1左右。)

实验结果:
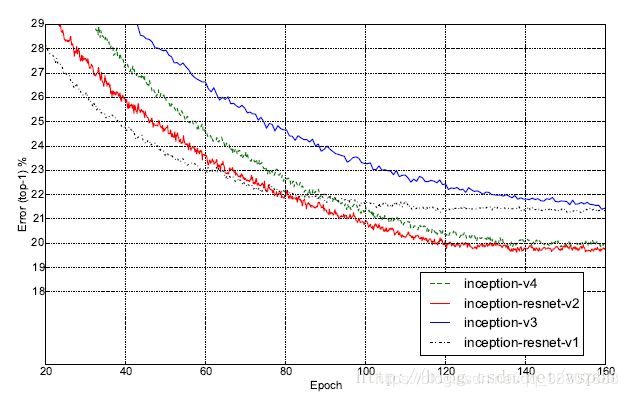
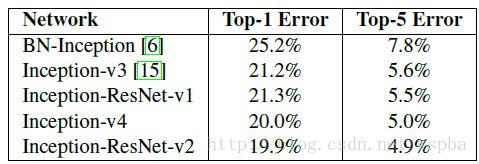
分析得结论:
我们发现,Inception-ResNet-v1的准确率与Inception-v3的准确率接近,Inception-ResNet-v2的与Inception-V4的接近, 但是Inception-ResNet-v1和Inception-ResNet-v2的收敛速度明显比Inception-v3和Inception-v4的快得多。
总结论:
1.与Inception V3相比,更加复杂的Inception V4的性能得到了明显的提高。当然Inception V4中也使用了很多技巧和操作来降低计算量。
2.常用的降低计算量的方法有:
1.使用并行结构
2.使用不对称的卷积
3.使用1*1的卷积进行维度变换
3.同时我们也发现,使用ResNet的identity connection能够极大程度的提高收敛速度,可见它对于解决优化难题是非常有效果的。
欢迎批评指正,讨论学习~
最近在github放了两份分类的代码,分别是用Tensorflow和Pytorch实现的,主要用于深度学习入门,学习Tensorflow和Pytorch搭建网络基本的操作。打算将各网络实现一下放入这两份代码中,有兴趣可以看一看,期待和大家一起维护更新。
代码地址:
Tensorflow实现分类网络
Pytorch实现分类网络