Python爬取猫眼电影
爬取猫眼电影中经典电影里所有电影的电影名,图片以及评分
不多说,直接上代码:
由于爬取数量较多,所以电影图片就没有下载了,爬下来的是图片的网页连接,
可以看我博客里面有篇文章是讲文件的读写操作的,包括json和pickle方式。
import requests
import re
import random
import pymysql
import time
# ------连接数据库
db = pymysql.connect(host='localhost', port=3306,
user='root', passwd='a', db='python', charset='utf8')
cursor=db.cursor()
sql="insert into maoyan( fname,fpic,fscore ) values( %s,%s,%s )"
#proxies={ 'http':'http://61.138.33.20.808' } #使用代理包装一下自己
#浏览器头,同样的包装一下自己
headers={
'User-Agent':'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)'
}
files=[] #用来存储爬到的电影
timeTotal=0 #总耗时
#print(headers)
for type in range(67):
#循环拼接地址
r=requests.get('http://maoyan.com/films?showType=3&offset={type}'.format(type=type*30),proxies=proxies,headers=headers,verify=False)
#定义一个正则表达式获取需要的数据
filemsgPattern=re.compile( 'movie-poster.*?下面是开始爬取到爬取完的截图

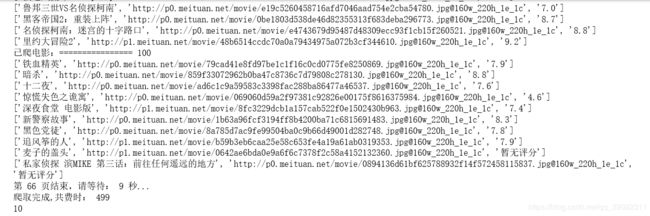
如果执行上面代码报错,可能是那个代理ip用不了了,在西刺代理或者快代理上重新找一个可用的就行了。我博客里面有一篇是关于爬取快代理的文章
谢谢您的阅读!