原文链接:线性分类器与性能评价(R语言)
微信公众号:机器学习养成记 搜索添加微信公众号:chenchenwings
“分类问题是机器学习算法中最基础和重要的问题,本文用R语言,对网上的Irvine数据集,通过线性回归方法,构建线性分类器。并统计出预测结果与实际结果的混淆矩阵,通过计算ROC和AUC,判断分类器性能。”
几个概念
一、混淆矩阵(confusion matrix)及相关指标
下图是混淆矩阵的例子和相应指标的计算公式。在后面计算ROC时,会用到相应的指标。
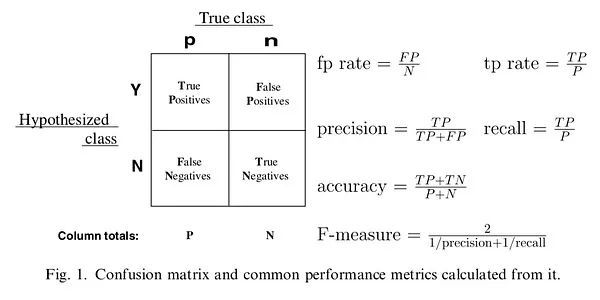
左上角的单元格包含预测结果为正且真实标签为正的样本,成为真正例,简写为TP。右上角对应的是预测为正,但实际为负的样本,称为假正例,简写为FP。左下角为预测为负但实际为正的样本,称为假负例,简写为FN。右下角为预测为负实际也为负的样本,称为真负例,简写为TN。混淆矩阵中的数字表示基于指定阈值进行决策所产生的性能值。
二、ROC与AUC
ROC(接收者操作曲线)绘制的是真正率(tp rate)随假正率(fp rate)的变化情况。tp rate代表被正确分类的正样本比例。fp rate是FP相对于实际负样本的比例。ROC曲线越接近于左上角,分类器效果越好。AUC为曲线下方的面积,面积越大,证明效果越好。
实例代码
1、数据准备。导入数据,并随机抽取70%作为训练集,剩下30%作为测试集,并将变量与标签列拆开。
target.url <- 'https://archive.ics.uci.edu/ml/machine-learning-databases/undocumented/connectionist-bench/sonar/sonar.all-data'
data <- read.csv(target.url,header = F)
#divide data into training and test sets
set.seed(100)
index <- sample(nrow(data),0.7*nrow(data))
train <- data[index,]
test <- data[-index,]
#arrange date into list and label sets
trainlist <- train[,1:60]
testlist <- test[,1:60]
trainlabel <- train[,61]
testlabel <- test[,61]
2、构建分类器并预测。在R语言中,函数lm()用来进行线性回归。首先用训练集生成分类器,并预测训练集的结果,与真实结果统计出混淆矩阵。
#train linear regression model
lm.mod <- lm(as.numeric(trainlabel)~.,data = trainlist)
#generate predictions for train-set data
lm.pred <- predict(lm.mod ,trainlist)#interval = "prediction",level = 0.95#给出预测区间
#generate confusion matrix on training set
predlabel <- lm.pred
predlabel[which(lm.pred>=1.5)] <- "R"
predlabel[which(lm.pred<1.5)] <- "M"
table(predlabel,trainlabel)
混淆矩阵结果为:
trainlabel
predlabel M R
M 74 2
R 5 64
用训练好的分类器,预测测试集的结果,并结合测试集的真实标签,统计混淆矩阵。
tpredlabel[which(lmt.pred>=1.5)] <- "R"
tpredlabel[which(lmt.pred<1.5)] <- "M"
table(tpredlabel,testlabel)
结果为:
testlabel
tpredlabel M R
M 27 12
R 5 19
3、绘制ROC曲线,判断性能。使用包pROC分别绘制训练集和测试集的ROC曲线,并计算出相应的AUC值。
#generate ROC for training set
library(pROC)
trainroc <- roc(as.numeric(trainlabel),lm.pred)
plot(trainroc, print.auc=TRUE, auc.polygon=TRUE, grid=c(0.1, 0.2),
grid.col=c("green", "red"), max.auc.polygon=TRUE,
auc.polygon.col="skyblue", print.thres=TRUE,main="ROC curve for training set")
#generate ROC for testing set
testroc <- roc(as.numeric(testlabel),lmt.pred)
plot(testroc, print.auc=TRUE, auc.polygon=TRUE, grid=c(0.1, 0.2),
grid.col=c("green", "red"), max.auc.polygon=TRUE,
auc.polygon.col="skyblue", print.thres=TRUE,main="ROC curve for testing set")
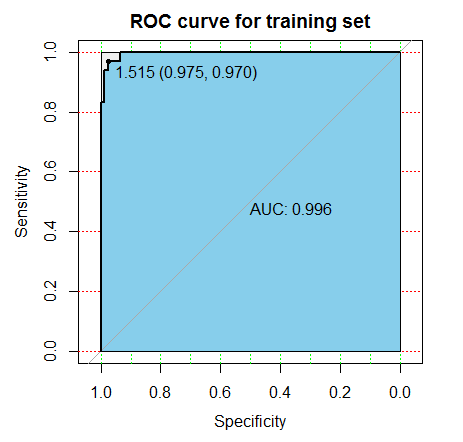
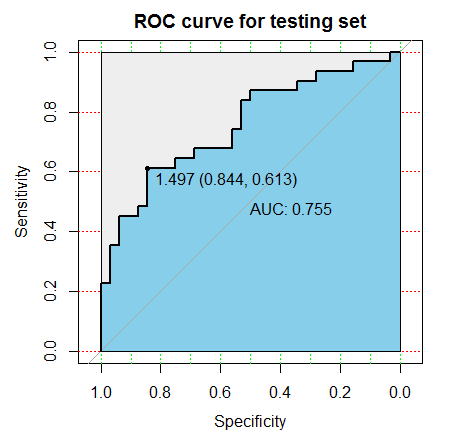
从图上可以直观看出,训练集上,ROC曲线更靠左上角,并且AUC值也更大,因此我们建立的线性分类器在训练集上的表现要优于测试集。
图上还有一条过(0,0)和(1,1)的直线,代表随机判断的情况。如果ROC曲线在这条线的下方,说明分类器的效果不如随机判断。一般是因为把预测符号弄反了,需要认真检查代码。
推荐历史文章:
第一弹->小案例(一):商业街抽奖
第二弹->小案例(二):面包是不是变轻了
第三弹->小案例(三):调查问卷
第四弹->小案例(四):销售额下滑
第五弹->小案例(五):销量预测
第六弹->小案例(六):预测小偷行为
第七弹->小案例(七):口碑分析(python)
机器学习养成记
搜索添加微信公众号:chenchenwings

扫描二维码,关注我们。
如需转载,请在开篇显著位置注明作者和出处,并在文末放置机器学习养成记二维码和添加原文链接。
快来关注我们吧!
