学习目标:
第一天接触具体的大数据框架,总目标是让学习者建立起大数据和分布式的宏观概念
1、理解hadoop是什么,用于做什么,大体上怎么用
2、理解hive是什么,用于做什么,大体上怎么用
3、通过一个案例的演示说明,理解数据挖掘系统的基本流程和结构
HADOOP背景介绍
什么是HADOOP
- HADOOP是apache旗下的一套开源软件平台
- HADOOP提供的功能:利用服务器集群,根据用户的自定义业务逻辑,对海量数据进行分布式处理
- HADOOP的核心组件有
- HDFS(分布式文件系统)
- YARN(运算资源调度系统)
- MAPREDUCE(分布式运算编程框架)
- 广义上来说,HADOOP通常是指一个更广泛的概念——HADOOP生态圈
HADOOP产生背景
- HADOOP最早起源于Nutch。Nutch的设计目标是构建一个大型的全网搜索引擎,包括网页抓取、索引、查询等功能,但随着抓取网页数量的增加,遇到了严重的可扩展性问题——如何解决数十亿网页的存储和索引问题。
- 2003年、2004年谷歌发表的两篇论文为该问题提供了可行的解决方案。
——分布式文件系统(GFS),可用于处理海量网页的存储
——分布式计算框架MAPREDUCE,可用于处理海量网页的索引计算问题。 - Nutch的开发人员完成了相应的开源实现HDFS和MAPREDUCE,并从Nutch中剥离成为独立项目HADOOP,到2008年1月,HADOOP成为Apache顶级项目,迎来了它的快速发展期。
HADOOP在大数据、云计算中的位置和关系
- 云计算是分布式计算、并行计算、网格计算、多核计算、网络存储、虚拟化、负载均衡等传统计算机技术和互联网技术融合发展的产物。借助IaaS(基础设施即服务)、PaaS(平台即服务)、SaaS(软件即服务)等业务模式,把强大的计算能力提供给终端用户。
- 现阶段,云计算的两大底层支撑技术为“虚拟化”和“大数据技术”
- 而HADOOP则是云计算的PaaS层的解决方案之一,并不等同于PaaS,更不等同于云计算本身。
国内外HADOOP应用案例介绍
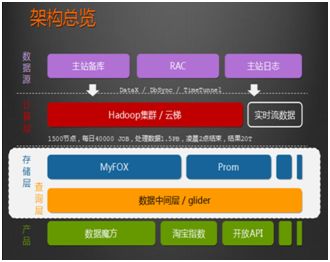

Hadoop集群搭建
Hadoop编译
1,环境:虚拟机 VirtualBox,
2,操作系统: 64 位 CentOS 6.4
下载编译需要的软件包
apache-ant-1.9.4-bin.tar.gz
findbugs-3.0.0.tar.gz
protobuf-2.5.0.tar.gz
apache-maven-3.0.5-bin.tar.gz
下载 hadoop2.4.0 的源码包
hadoop-2.4.0-src.tar.gz压解源码包
[grid@hadoopMaster01 ~]$ tar -zxvf hadoop-2.4.0-src.tar.gz
安装编译所需软件
- 安装 MAVEN
- 压解
apache-maven-3.0.5-bin.tar.gz到/opt/目录
[root@hadoopMaster01 grid]# tar -zxvf apache-maven-3.0.5-bin.tar.gz -C /opt/ - 修改/etc/profile 配置,增加 MAVEN 环境配置M2_HOME PATH
- 保存后使用 source /etc/profile 使修改配置即时生效
[root@hadoopMaster01 apache-maven-3.0.5]# source /etc/profile - 使用 mvn -v 命令进行验证,如图所示表示安装配置成功
- 压解
- 安装 ANT
- 压解 apache-ant-1.9.4-bin.tar.gz 到/opt/目录
[root@hadoopMaster01 grid]# tar -zxvf apache-ant-1.9.4-bin.tar.gz -C /opt/ - 修改/etc/profile 配置,增加 ANT 环境配置 ANT_HOME PATH
- 保存后使用 source /etc/profile 使修改配置即时生效
[root@hadoopMaster01 apache-ant-1.9.4]# source /etc/profile - 使用 ant-version 命令进行验证,如图所示表示安装配置成功
- 压解 apache-ant-1.9.4-bin.tar.gz 到/opt/目录
- 安装 FINDBUGS
- 压解 findbugs-3.0.0.tar.gz 到/opt/目录
[root@hadoopMaster01 grid]# tar -zxvf findbugs-3.0.0.tar.gz -C /opt/ - 修改/etc/profile 配置,增加 FINDBUGS 环境配置
- 保存后使用 source /etc/profile 使修改配置即时生效
[root@hadoopMaster01 apache-ant-1.9.4]# source /etc/profile - 使用 findbugs-version 命令进行验证,如图所示表示安装配置成功
- 压解 findbugs-3.0.0.tar.gz 到/opt/目录
- 安装 PROTOBUF
- 编译 Hadoop 2.4.0,需要 protobuf 的编译器protoc,一定要是 protobuf 2.5.0 以上
- 直接压解 protobuf-2.5.0.tar.gz
[root@hadoopMaster01 grid]# tar -zxvf protobuf-2.5.0.tar.gz - 安装 protobuf,依次执行如下命令
[root@hadoopMaster01 grid]# cd protobuf-2.5.0
[root@hadoopMaster01 protobuf-2.5.0]# ls
aclocal.m4 config.guess configure COPYING.txt examples
install-sh ltmain.sh Makefile.in protobuf.pc.in src
autogen.sh config.h.in configure.ac depcomp generate_descriptor_proto.sh
INSTALL.txt m4 missing python vsprojects
CHANGES.txt config.sub CONTRIBUTORS.txt editors gtest
java Makefile.am protobuf-lite.pc.in README.txt
[root@hadoopMaster01 protobuf-2.5.0]# ./configure
[root@hadoopMaster01 protobuf-2.5.0]# make
[root@hadoopMaster01 protobuf-2.5.0]# make check
[root@hadoopMaster01 protobuf-2.5.0]# make install
使用 protoc --version 命令进行验证,如图所示表示安装配置成功
-
安装 依赖包
- 安装 cmake,openssl-devel,ncurses-devel 依赖包(root 用户且能够连上互联网)
[root@hadoopMaster01 ~]# yum install cmake
如下图表示安装成功
[root@hadoopMaster01 ~]# yum install openssl-devel
如下图表示安装成功
[root@hadoopMaster01 ~]# yum install ncurses-devel
如下图表示依赖包系统中已经安装并且为最新版本
- 安装 cmake,openssl-devel,ncurses-devel 依赖包(root 用户且能够连上互联网)
-
编译 64 位本地库
- 进入已解压的 hadoop 源码目录
[grid@hadoopMaster01 ~]$ cd hadoop-2.4.0-src
[grid@hadoopMaster01 hadoop-2.4.0-src]$ pwd
/home/grid/hadoop-2.4.0-src - 执行
mvn clean install -DskipTests命令,等待完成(会自动联网下载很多东西,会执行相当长的时间)
[grid@hadoopMaster01 hadoop-2.4.0-src]$ mvn clean install -DskipTests - 执行
mvn package -Pdist,native -DskipTests -Dtar命令,开始编译,等待完成
grid@hadoopMaster01 hadoop-2.4.0-src]$ mvn package -Pdist,native -DskipTests -Dtar
出现如下信息
- 进入已解压的 hadoop 源码目录
[INFO] ------------------------------------------------------------------------
[INFO] Reactor Summary:
[INFO]
[INFO] Apache Hadoop Main ................................ SUCCESS[6.304s]
[INFO] Apache Hadoop Project POM ......................... SUCCESS [26.555s]
[INFO] Apache Hadoop Annotations ......................... SUCCESS[2.757s]
[INFO] Apache Hadoop Assemblies .......................... SUCCESS [0.216s]
[INFO] Apache Hadoop Project Dist POM .................... SUCCESS [19.592s]
[INFO] Apache Hadoop Maven Plugins ....................... SUCCESS [2.715s]
[INFO] Apache Hadoop MiniKDC ............................. SUCCESS [2.360s]
[INFO] Apache Hadoop Auth ................................ SUCCESS [2.950s]
[INFO] Apache Hadoop Auth Examples ....................... SUCCESS[2.119s]
[INFO] Apache Hadoop Common .............................. SUCCESS [1:22.302s]
[INFO] Apache Hadoop NFS ................................. SUCCESS [5.095s]
[INFO] Apache Hadoop Common Project...................... SUCCESS [0.026s]
[INFO] Apache Hadoop HDFS ................................ SUCCESS [2:06.178s]
[INFO] Apache Hadoop HttpFS .............................. SUCCESS [1:09.142s]
[INFO] Apache Hadoop HDFS BookKeeper Journal ............. SUCCESS [14.457s]
[INFO] Apache Hadoop HDFS-NFS ............................SUCCESS [2.859s]
[INFO] Apache Hadoop HDFS Project ........................ SUCCESS [0.030s]
[INFO] hadoop-yarn ....................................... SUCCESS [0.029s]
[INFO] hadoop-yarn-api ................................... SUCCESS [59.010s]
[INFO] hadoop-yarn-common ................................ SUCCESS [20.743s]
[INFO] hadoop-yarn-server ................................ SUCCESS[0.026s]
[INFO] hadoop-yarn-server-common ......................... SUCCESS [7.344s]
[INFO] hadoop-yarn-server-nodemanager .................... SUCCESS [11.726s]
[INFO] hadoop-yarn-server-web-proxy ...................... SUCCESS [2.508s]
[INFO] hadoop-yarn-server-applicationhistoryservice ...... SUCCESS [4.041s]
[INFO] hadoop-yarn-server-resourcemanager ................ SUCCESS [10.370s]
[INFO] hadoop-yarn-server-tests .......................... SUCCESS [0.374s]
[INFO] hadoop-yarn-client ................................ SUCCESS [4.791s]
[INFO] hadoop-yarn-applications .......................... SUCCESS [0.025s]
[INFO] hadoop-yarn-applications-distributedshell ......... SUCCESS [2.242s]
[INFO] hadoop-yarn-applications-unmanaged-am-launcher .... SUCCESS [1.553s]
[INFO] hadoop-yarn-site .................................. SUCCESS [0.024s]
[INFO] hadoop-yarn-project ............................... SUCCESS [3.261s]
[INFO] hadoop-mapreduce-client ........................... SUCCESS [0.082s]
[INFO] hadoop-mapreduce-client-core ...................... SUCCESS [18.549s]
[INFO] hadoop-mapreduce-client-common .................... SUCCESS [13.772s]
[INFO] hadoop-mapreduce-client-shuffle ................... SUCCESS [2.441s]
[INFO] hadoop-mapreduce-client-app ....................... SUCCESS [6.866s]
[INFO] hadoop-mapreduce-client-hs ........................ SUCCESS [6.280s]
[INFO] hadoop-mapreduce-client-jobclient .................SUCCESS [3.510s]
[INFO] hadoop-mapreduce-client-hs-plugins ................ SUCCESS [1.725s]
[INFO] Apache Hadoop MapReduce Examples .................. SUCCESS [4.641s]
[INFO] hadoop-mapreduce .................................. SUCCESS[3.002s]
[INFO] Apache Hadoop MapReduce Streaming ................. SUCCESS [3.497s]
[INFO] Apache Hadoop Distributed Copy .................... SUCCESS [5.847s]
[INFO] Apache Hadoop Archives ............................ SUCCESS [1.791s]
[INFO] Apache Hadoop Rumen ............................... SUCCESS [4.693s]
[INFO] Apache Hadoop Gridmix ............................. SUCCESS [3.235s]
[INFO] Apache Hadoop Data Join........................... SUCCESS [2.349s]
[INFO] Apache Hadoop Extras .............................. SUCCESS [2.488s]
[INFO] Apache Hadoop Pipes ............................... SUCCESS [5.863s]
[INFO] Apache Hadoop OpenStack support ................... SUCCESS [3.776s]
[INFO] Apache Hadoop Client .............................. SUCCESS [5.235s]
[INFO] Apache Hadoop Mini-Cluster ........................ SUCCESS [0.070s]
[INFO] Apache Hadoop Scheduler Load Simulator ............ SUCCESS [3.935s]
[INFO] Apache Hadoop Tools Dist .......................... SUCCESS [4.392s]
[INFO] Apache Hadoop Tools ............................... SUCCESS [0.022s]
[INFO] Apache Hadoop Distribution ........................ SUCCESS [21.274s]
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 10:25.147s
[INFO] Finished at: Mon Jul 28 16:09:56 CST 2014
[INFO] Final Memory: 75M/241M
[INFO] ------------------------------------------------------------------------
表示编译成功
进入/home/grid/hadoop-2.4.0-src/hadoop-dist/target/hadoop-2.4.0/lib/native 检查,使用 file *命令,如下图已经成功将编译 64 本地库
将 64 位的 native 文件夹替换原 32 位的文件夹即可
HAadoop安装配置、启动
本案例使用四台主机mini1、mini2、mini3、mini4搭建Hadoop集群,其中mini1为namenode,其他三台为datanode。
前提条件
- 确保四台主机都已经配置好java环境
- 确保四台主机都能使用scp命令(安装了openssh_client)
- mini1能通过SSH免密登录到其他三台主机(教程后面有配置的步骤)
- 四台主机都设置了
hostname,使用hostname -f命令能看到mini1,mini2...,要使用hostname -f命令看到正确的值,必须/etc/sysconfig/network和/etc/hosts都正确配置,然后重启电脑hostname生效 - 关闭四台机的防火墙,这个不是一定要这样的,可以配置端口开放
[hadoop@mini1 ~]$ su
Password:
[root@mini1 hadoop]# service iptables stop
iptables: Setting chains to policy ACCEPT: filter [ OK ]
iptables: Flushing firewall rules: [ OK ]
iptables: Unloading modules: [ OK ]
[root@mini1 hadoop]# chkconfig iptables off
[root@mini1 hadoop]#
步骤
-
给四台主机添加hadoop的用户,设置密码为hadoop
useradd hadoop
passwd hadoop

- 给hadoop用户添加root权限
vi /etc/sudoers
## Allow root to run any commands anywhere
root ALL=(ALL) ALL
hadoop ALL=(ALL) ALL
拷贝到mini2上
[root@mini1 ~]# scp /etc/sudoers mini2:/etc/
Warning: Permanently added the RSA host key for IP address '192.168.230.202' to the list of known hosts.
root@mini2's password:
sudoers
scp /etc/sudoers mini2:/etc/
scp /etc/sudoers mini3:/etc/
scp /etc/sudoers mini4:/etc/
然后使用hadoop用户重新连接到这四台主机
-
上传hadoop包
- 本案例使用已经编译好的
cenos-6.5-hadoop-2.6.4.tar.gz包 - 上传到mini1:
put D:\linux_file\cenos-6.5-hadoop-2.6.4.tar.gz
- 本案例使用已经编译好的
解压
[hadoop@mini1 ~]$ pwd
/home/hadoop
[hadoop@mini1 ~]$ mkdir apps
[hadoop@mini1 ~]$ tar zxvf cenos-6.5-hadoop-2.6.4.tar.gz -C apps/
- 进入hadoop目录
[hadoop@mini1 ~]$ cd apps/
[hadoop@mini1 apps]$ cd hadoop-2.6.4/
[hadoop@mini1 hadoop-2.6.4]$ ll
total 52
drwxrwxr-x. 2 hadoop hadoop 4096 Mar 7 2016 bin
drwxrwxr-x. 3 hadoop hadoop 4096 Mar 7 2016 etc
drwxrwxr-x. 2 hadoop hadoop 4096 Mar 7 2016 include
drwxrwxr-x. 3 hadoop hadoop 4096 Mar 7 2016 lib
drwxrwxr-x. 2 hadoop hadoop 4096 Mar 7 2016 libexec
-rw-r--r--. 1 hadoop hadoop 15429 Mar 7 2016 LICENSE.txt
-rw-r--r--. 1 hadoop hadoop 101 Mar 7 2016 NOTICE.txt
-rw-r--r--. 1 hadoop hadoop 1366 Mar 7 2016 README.txt
drwxrwxr-x. 2 hadoop hadoop 4096 Mar 7 2016 sbin
drwxrwxr-x. 4 hadoop hadoop 4096 Mar 7 2016 share
[hadoop@mini1 hadoop-2.6.4]$ cd etc/hadoop/
[hadoop@mini1 hadoop]$ ll
total 152
-rw-r--r--. 1 hadoop hadoop 4436 Mar 7 2016 capacity-scheduler.xml
-rw-r--r--. 1 hadoop hadoop 1335 Mar 7 2016 configuration.xsl
-rw-r--r--. 1 hadoop hadoop 318 Mar 7 2016 container-executor.cfg
-rw-r--r--. 1 hadoop hadoop 774 Mar 7 2016 core-site.xml
-rw-r--r--. 1 hadoop hadoop 3670 Mar 7 2016 hadoop-env.cmd
-rw-r--r--. 1 hadoop hadoop 4224 Mar 7 2016 hadoop-env.sh
-rw-r--r--. 1 hadoop hadoop 2598 Mar 7 2016 hadoop-metrics2.properties
-rw-r--r--. 1 hadoop hadoop 2490 Mar 7 2016 hadoop-metrics.properties
-rw-r--r--. 1 hadoop hadoop 9683 Mar 7 2016 hadoop-policy.xml
-rw-r--r--. 1 hadoop hadoop 775 Mar 7 2016 hdfs-site.xml
-rw-r--r--. 1 hadoop hadoop 1449 Mar 7 2016 httpfs-env.sh
-rw-r--r--. 1 hadoop hadoop 1657 Mar 7 2016 httpfs-log4j.properties
-rw-r--r--. 1 hadoop hadoop 21 Mar 7 2016 httpfs-signature.secret
-rw-r--r--. 1 hadoop hadoop 620 Mar 7 2016 httpfs-site.xml
-rw-r--r--. 1 hadoop hadoop 3523 Mar 7 2016 kms-acls.xml
-rw-r--r--. 1 hadoop hadoop 1325 Mar 7 2016 kms-env.sh
-rw-r--r--. 1 hadoop hadoop 1631 Mar 7 2016 kms-log4j.properties
-rw-r--r--. 1 hadoop hadoop 5511 Mar 7 2016 kms-site.xml
-rw-r--r--. 1 hadoop hadoop 11291 Mar 7 2016 log4j.properties
-rw-r--r--. 1 hadoop hadoop 938 Mar 7 2016 mapred-env.cmd
-rw-r--r--. 1 hadoop hadoop 1383 Mar 7 2016 mapred-env.sh
-rw-r--r--. 1 hadoop hadoop 4113 Mar 7 2016 mapred-queues.xml.template
-rw-r--r--. 1 hadoop hadoop 758 Mar 7 2016 mapred-site.xml.template
-rw-r--r--. 1 hadoop hadoop 10 Mar 7 2016 slaves
-rw-r--r--. 1 hadoop hadoop 2316 Mar 7 2016 ssl-client.xml.example
-rw-r--r--. 1 hadoop hadoop 2268 Mar 7 2016 ssl-server.xml.example
-rw-r--r--. 1 hadoop hadoop 2237 Mar 7 2016 yarn-env.cmd
-rw-r--r--. 1 hadoop hadoop 4567 Mar 7 2016 yarn-env.sh
-rw-r--r--. 1 hadoop hadoop 690 Mar 7 2016 yarn-site.xml
- 配置
hadoop-env.sh
[hadoop@mini1 hadoop]$ echo $JAVA_HOME
/usr/local/jdk1.7.0_45
[hadoop@mini1 hadoop]$ vi hadoop-env.sh
配置下面这一行如下:
# The java implementation to use.
export JAVA_HOME=/usr/local/jdk1.7.0_45
- 配置
core-site.xml,如下
fs.defaultFS
hdfs://mini1:9000
hadoop.tmp.dir
/home/hadoop/hdpdata
- 配置
hdfs-site.xml,如下:
dfs.replication
2
- 配置
mapred-site.xml
[hadoop@mini1 hadoop]$ mv mapred-site.xml.template mapred-site.xml
[hadoop@mini1 hadoop]$ vi mapred-site.xml
配置如下:
mapreduce.framework.name
yarn
- 配置
yarn-site.xml,如下:
yarn.resourcemanager.hostname
mini1
yarn.nodemanager.aux-services
mapreduce_shuffle
- 将配置好的hadoop拷贝到其他三台主机
[hadoop@mini1 hadoop-2.6.4]$ cd ~
[hadoop@mini1 ~]$ scp -r apps/ mini2:/home/hadoop
[hadoop@mini1 ~]$ scp -r apps/ mini3:/home/hadoop
[hadoop@mini1 ~]$ scp -r apps/ mini4:/home/hadoop
- 将hadoop配置到环境变量最后
vi /etc/profile
export JAVA_HOME=/usr/local/jdk1.7.0_45
export HADOOP_HOME=/home/hadoop/apps/hadoop-2.6.4
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
将配置好的环境变量拷贝到其他三台机器
[hadoop@mini1 ~]$ sudo scp /etc/profile mini2:/etc/
[hadoop@mini1 ~]$ sudo scp /etc/profile mini3:/etc/
[hadoop@mini1 ~]$ sudo scp /etc/profile mini4:/etc/
- 格式化mini1上的namenode的HDFS
[hadoop@mini1 ~]$ source /etc/profile
[hadoop@mini1 ~]$ hadoop namenode -format
启动和关闭
- 启动mini1上的namenode
[hadoop@mini1 ~]$ hadoop-daemon.sh start namenode
starting namenode, logging to /home/hadoop/apps/hadoop-2.6.4/logs/hadoop-hadoop-namenode-mini1.out
[hadoop@mini1 ~]$
启动之后查看网页端的管理页面:
如果本机一配置好hosts,可以直接在浏览器输入:http://mini1:50070,
如果没有配置hosts,在浏览器输入:http://mini1的ip:50070
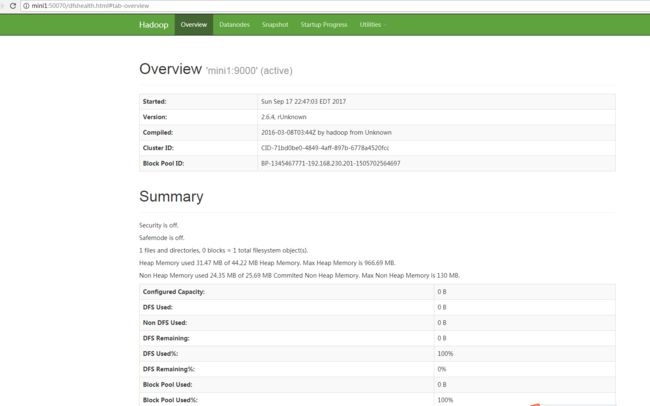
- 启动mini2上的datanode
[hadoop@mini2 ~]$ source /etc/profile
[hadoop@mini2 ~]$ hadoop-daemon.sh start datanode
starting datanode, logging to /home/hadoop/apps/hadoop-2.6.4/logs/hadoop-hadoop-datanode-mini2.out
[hadoop@mini2 ~]$
然后刷新mini1的web管理端
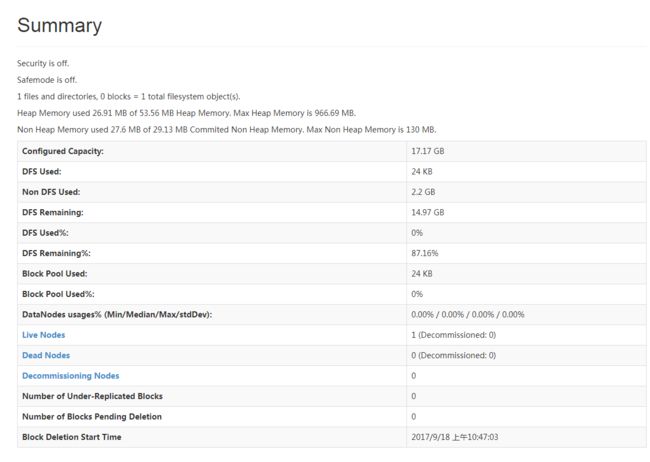
可以看到添加了一个节点
- 启动mini3上的datanode
[hadoop@mini3 ~]$ source /etc/profile
[hadoop@mini3 ~]$ hadoop-daemon.sh start datanode
starting datanode, logging to /home/hadoop/apps/hadoop-2.6.4/logs/hadoop-hadoop-datanode-mini3.out
[hadoop@mini3 ~]$
然后刷新mini1的web管理端
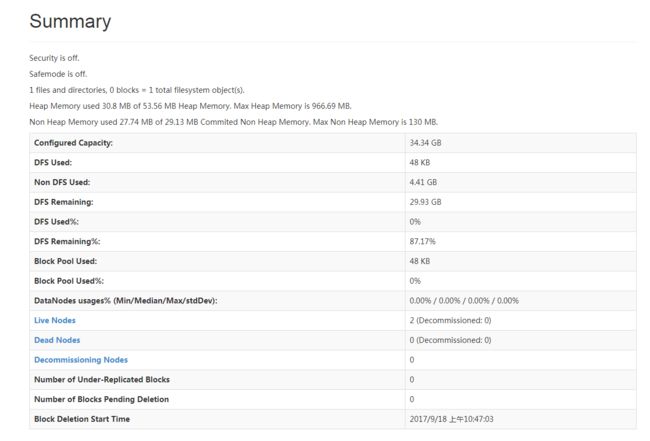
可以看到又添加了一个节点
- 同理启动mini4的datanode
- 关闭mini2、3、4的datanode
[hadoop@mini3 ~]$ hadoop-daemon.sh stop datanode
stopping datanode
- 关闭mini1的namenode
[hadoop@mini1 ~]$ hadoop-daemon.sh stop namenode
stopping namenode
[hadoop@mini1 ~]$
集群启动
在/home/hadoop/apps/hadoop-2.6.4/sbin下,有启动集群的脚本
[hadoop@mini1 sbin]$ ll
total 120
-rwxr-xr-x. 1 hadoop hadoop 2752 Mar 7 2016 distribute-exclude.sh
-rwxr-xr-x. 1 hadoop hadoop 6452 Mar 7 2016 hadoop-daemon.sh
-rwxr-xr-x. 1 hadoop hadoop 1360 Mar 7 2016 hadoop-daemons.sh
-rwxr-xr-x. 1 hadoop hadoop 1640 Mar 7 2016 hdfs-config.cmd
-rwxr-xr-x. 1 hadoop hadoop 1427 Mar 7 2016 hdfs-config.sh
-rwxr-xr-x. 1 hadoop hadoop 2291 Mar 7 2016 httpfs.sh
-rwxr-xr-x. 1 hadoop hadoop 2059 Mar 7 2016 kms.sh
-rwxr-xr-x. 1 hadoop hadoop 4080 Mar 7 2016 mr-jobhistory-daemon.sh
-rwxr-xr-x. 1 hadoop hadoop 1648 Mar 7 2016 refresh-namenodes.sh
-rwxr-xr-x. 1 hadoop hadoop 2145 Mar 7 2016 slaves.sh
-rwxr-xr-x. 1 hadoop hadoop 1779 Mar 7 2016 start-all.cmd
-rwxr-xr-x. 1 hadoop hadoop 1471 Mar 7 2016 start-all.sh
-rwxr-xr-x. 1 hadoop hadoop 1128 Mar 7 2016 start-balancer.sh
-rwxr-xr-x. 1 hadoop hadoop 1401 Mar 7 2016 start-dfs.cmd
-rwxr-xr-x. 1 hadoop hadoop 3705 Mar 7 2016 start-dfs.sh
-rwxr-xr-x. 1 hadoop hadoop 1357 Mar 7 2016 start-secure-dns.sh
-rwxr-xr-x. 1 hadoop hadoop 1571 Mar 7 2016 start-yarn.cmd
-rwxr-xr-x. 1 hadoop hadoop 1347 Mar 7 2016 start-yarn.sh
-rwxr-xr-x. 1 hadoop hadoop 1770 Mar 7 2016 stop-all.cmd
-rwxr-xr-x. 1 hadoop hadoop 1462 Mar 7 2016 stop-all.sh
-rwxr-xr-x. 1 hadoop hadoop 1179 Mar 7 2016 stop-balancer.sh
-rwxr-xr-x. 1 hadoop hadoop 1455 Mar 7 2016 stop-dfs.cmd
-rwxr-xr-x. 1 hadoop hadoop 3206 Mar 7 2016 stop-dfs.sh
-rwxr-xr-x. 1 hadoop hadoop 1340 Mar 7 2016 stop-secure-dns.sh
-rwxr-xr-x. 1 hadoop hadoop 1642 Mar 7 2016 stop-yarn.cmd
-rwxr-xr-x. 1 hadoop hadoop 1340 Mar 7 2016 stop-yarn.sh
-rwxr-xr-x. 1 hadoop hadoop 4295 Mar 7 2016 yarn-daemon.sh
-rwxr-xr-x. 1 hadoop hadoop 1353 Mar 7 2016 yarn-daemons.sh
在/home/hadoop/apps/hadoop-2.6.4/etc/hadoop下的slaves文件可以配置集群中的其他主机
- 配置集群中的其他主机
[hadoop@mini1 hadoop]$ vi slaves,配置如下:
mini2
mini3
mini4
- 配置mini1对其他三台主机的免密登录
因为一般都在mini1的namenode上启动集群- 生成秘钥
[hadoop@mini1 hadoop]$ ssh-keygen
Generating public/private rsa key pair.
Enter file in which to save the key (/home/hadoop/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /home/hadoop/.ssh/id_rsa.
Your public key has been saved in /home/hadoop/.ssh/id_rsa.pub.
The key fingerprint is:
22:b9:12:a5:05:f9:e2:5c:97:9f:d6:7a:52:27:6a:41 hadoop@mini1
The key's randomart image is:
+--[ RSA 2048]----+
| .. |
| .. |
| .o . |
| .+o.o E |
| oooo..oSo |
| o. o .= + . |
| . . . = o |
| . = . |
| . o |
+-----------------+
[hadoop@mini1 hadoop]$
- 配置到其他主机(包括自己)
[hadoop@mini1 hadoop]$ ssh-copy-id mini1
The authenticity of host 'mini1 (192.168.230.201)' can't be established.
RSA key fingerprint is 27:7a:bd:db:5c:79:ec:69:00:90:a5:02:66:48:ca:73.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'mini1,192.168.230.201' (RSA) to the list of known hosts.
hadoop@mini1's password:
Now try logging into the machine, with "ssh 'mini1'", and check in:
.ssh/authorized_keys
to make sure we haven't added extra keys that you weren't expecting.
[hadoop@mini1 hadoop]$ ssh-copy-id mini2
hadoop@mini2's password:
Now try logging into the machine, with "ssh 'mini2'", and check in:
.ssh/authorized_keys
to make sure we haven't added extra keys that you weren't expecting.
[hadoop@mini1 hadoop]$ ssh-copy-id mini3
hadoop@mini3's password:
Now try logging into the machine, with "ssh 'mini3'", and check in:
.ssh/authorized_keys
to make sure we haven't added extra keys that you weren't expecting.
[hadoop@mini1 hadoop]$ ssh-copy-id mini4
hadoop@mini4's password:
Now try logging into the machine, with "ssh 'mini4'", and check in:
.ssh/authorized_keys
to make sure we haven't added extra keys that you weren't expecting.
[hadoop@mini1 hadoop]$
- 启动HDFS集群
/home/hadoop/apps/hadoop-2.6.4/sbin
[hadoop@mini1 sbin]$ start-dfs.sh
Starting namenodes on [mini1]
mini1: starting namenode, logging to /home/hadoop/apps/hadoop-2.6.4/logs/hadoop-hadoop-namenode-mini1.out
mini3: starting datanode, logging to /home/hadoop/apps/hadoop-2.6.4/logs/hadoop-hadoop-datanode-mini3.out
mini2: starting datanode, logging to /home/hadoop/apps/hadoop-2.6.4/logs/hadoop-hadoop-datanode-mini2.out
mini4: starting datanode, logging to /home/hadoop/apps/hadoop-2.6.4/logs/hadoop-hadoop-datanode-mini4.out
Starting secondary namenodes [0.0.0.0]
0.0.0.0: starting secondarynamenode, logging to /home/hadoop/apps/hadoop-2.6.4/logs/hadoop-hadoop-secondarynamenode-mini1.out
[hadoop@mini1 sbin]$
- 关闭HDFS集群