姓名:何承勇
学号:16050510005
原文链接:https://deepmind.com/blog/alphago-zero-learning-scratch/
转载自:http://www.jianshu.com/p/fee2bc92e924,有删改。
【嵌牛导读】:今年5月,乌镇大会的“人机对局”中,中国棋手、世界冠军柯洁以0:3不敌AlphaGo。随后Deepmind创始人Hassabis又宣布AlphaGo“退役”,不再进行比赛,同时表示将在今年稍晚时候发布最后一篇学术论文,详细介绍他们在算法效率上所取得的一系列进展,以及其应用在其他更全面领域中的可能性。在今天10.19,Deepmind如约在Nature发布了名为《Mastering the game of Go without human knowledge》的论文,在这篇论文中,Deepmind展示了更强大的新版本围棋程序“AlphaGo Zero”,验证了即使在像围棋这样最具挑战性的领域,也可以通过纯强化学习的方法自我完善达到目的。
【嵌牛鼻子】:AlphaGo、AlphaGo Zero、Deepmind、神经网络、围棋
【嵌牛提问】:AlphaGo Zero的自我学习系统将会如何运用在其他领域?
【嵌牛正文】:
时至今日,人工智能研究已经在从语音识别到图像分类,再到基因组学乃至药物发现等各个领域取得快速发展。而其中大多数场景原本都是需要投入大量人力资源与数据的专业系统。
然而,对于一部分特定问题,利用人类知识加以解决则往往成本过高——包括不够可靠或者根本无法承担如此庞大的工作量等。因此,AI 研究的长期目标在于绕过人为阶段,而是创造算法,最终在无需人类介入的前提下立足各类挑战性领域实现超越人类的成效表现。在最近发表于《自然》杂志的论文当中,DeepMind 展现了迈向这一目标的重要一步。
这篇论文介绍了 AlphaGo Zero,即 AlphaGo 的最新发展成果、亦是第一款能够在围棋这种古老的中国竞技项目当中击败世界冠军的计算机程序。Zero 则更为强大,可以说是有史以来最卓越的围棋棋手。
AlphaGo 之前的各个版本最初由数千名业余及专业围棋棋手进行训练,借以学习围棋的规则与技巧。AlphaGo Zero 则路过了这一步,其能够从完全随机的对弈开始自行学习规则。在这样的前提之下,Zero 很快即超过了人类的棋艺水平,并以 100 比 0 的成绩迅速击败上一代“世界冠军”AlphaGo。

其之所以能够取得如此优秀的成绩,是因为 AlphaGo Zero 利用一种全新强化学习形式实现“自为自师”。该系统最初只是一套完全不了解围棋游戏规则的神经网络。在此之后,通过将该神经网络与强大的搜索算法相结合,即可进行自我对战。在对弈过程当中,该神经网络经历高速与更新,从而预测接下来的最佳行动并最终在游戏中胜出。
这套经过更新的神经网络随后与搜索算法进行重组,借以创建新的、更为强大的 AlphaGo Zero 版本,这一过程将周而复始不断进行。在每一次迭代当中,系统成效都将迎来小幅提升,并使得 AlphaGo Zero 变得棋力愈盛、神经网络本身也越来越精确。
这项技术之所以比原本的 AlphaGo 更为强大,是因为其不再受限于人类的知识水平。相反,其能够像一张白纸般从世界上最强的棋手——AlphaGo——身上学习技巧。
另外,Zero 与初版 AlphaGo 相比还拥有以下不同之处。
• AlphaGo Zero 仅使用围棋棋盘上的黑白棋子作为输入信息,而 AlphaGo 的以往版本仍包含少量手动设计功能。
• 其仅采用单一神经网络,而非像初版 AlphaGo 那样使用两套。AlphaGo 的各早期版本利用一套“策略网络”选择下一步行动,另外配合一套“价值网络”以预测各个点位对游戏结果的影响。二者在 AlphaGo Zero 当中并合而为一,使其能够更为高效地实现训练与评估。
• AlphaGo Zero 并不使用“推演”——即常见于其它围棋程序当中,根据现有盘面局势进行结果预测的快速随机对弈流程。相反,其依赖于高质量神经网络以评估当前盘面形势。
上述差异的存在有助于提升系统成效并令其具备更为理想的通用能力。而在另一方面,算法的改变也令系统本身更为强大且高效。
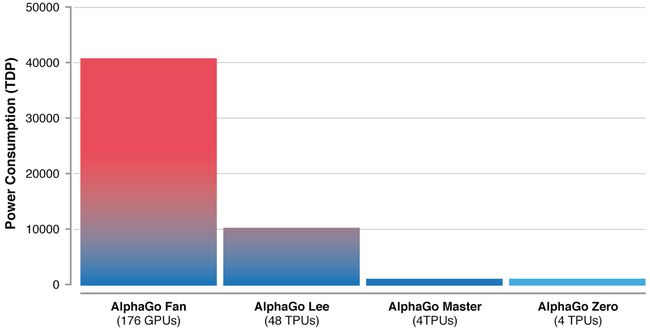
仅仅在三天的自我对弈之后,AlphaGo Zero 就已经以 100 比 0 的结果强势击败了此前发布的 AlphaGo 版本——而后者曾经击败 18 项世界冠军头衔拥有者李世石。经过 40 天的自我训练之后,AlphaGo Zero 变得更为强大,且全面碾压此前曾击败全球最强棋手柯杰的 AlphaGo“Master”版本。
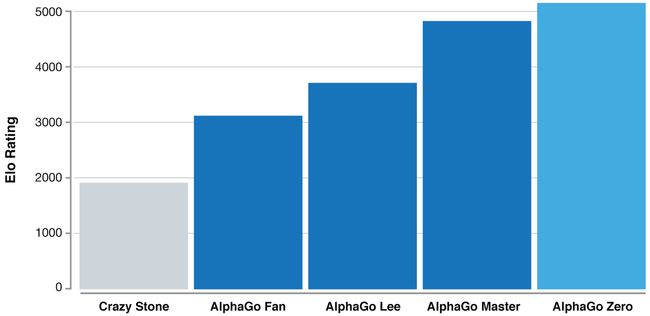
在数百万场 AlphaGo 对 AlphaGo 的比赛当中,这套系统从零开始逐步掌握了围棋技巧,并在短短数天时间中积累到了数千年孕育而来的人类知识。AlphaGo Zero 亦从中发现更多新适度,制定出更多非常规型策略以及创新下法,这进一步反映甚至超越了此前 AlphaGo 在对阵李世石与柯杰时所发挥出的水平。

这些创造性的时刻让我们相信,人工智能终将为人类带来更为强大的创造力,从而帮助我们解决人类所面临的一系列最为重要的挑战。
尽管尚处于早期发展阶段,但 AlphaGo Zero 已经成为迈向这一目标的关键性一步。如果能够将类似的技术应用于其它结构化问题当中——例如蛋白质折叠、能源消耗控制或者发现革命性新材料等等,那么这些突破无疑将对整个人类社会产生积极的推动作用。
原文作者:AI前线