在上篇《单例,真了解吗?》中,提及到了重排序、volatile等概念,有的同学还没接触过这些,那么此篇就简单介绍一下它们。
JMM
java中,所有实例域、静态域、数组元素都存储在堆中,堆可被多个线程共享。在多线程环境下,线程之间是如何通信和实现这些共享数据的同步?java的并发采用的是共享内存模型。
JMM(Java Memory Model),Java内存模型,JMM决定一个线程对共享变量的写入何时对另一个线程可见。JMM定义了线程和主内存之间的抽象关系,多个线程的共享数据存在主内存中,但是每个线程拥有自己的本地内存,本地内存中存储的是该线程从主内存那里读取共享变量的副本(注意:本地内存是个抽象概念,不存在的),下图是JMM的抽象结构示意图:

从图来看,如果线程A要和线程B通信的话,需要两步:
①线程A把本地内存A中的更新过的共享变量刷新到主内存中;
②线程B再从主内存中读取线程A之前已更新过的共享变量。
happens-before
在JMM中,如果一个操作执行的结果需要对另一个操作可见,那么这两个操作之间就必须存在happens-before关系,当然两个操作可能属于同一线程,也有可能属于不同的线程。
happens-before规则:
1、程序次序规则:在一个单独的线程中,按照程序代码的执行流顺序,(时间上)先执行的操作happens-before(时间上)后执行的操作。
2、管理锁定规则:一个unlock操作happens-before后面(时间上的先后顺序,下同)对同一个锁的lock操作。
3、volatile变量规则:对一个volatile变量的写操作happens-before后面对该变量的读操作。
4、传递性:如果操作A happens-before操作B,操作B happens-before操作C,那么可以得出A happens-before操作C。
注意:两个操作之间具有happens-before关系,并不意味前一个操作必须要在后一个操作之前执行!仅仅要求前一个操作的执行结果,对于后一个操作是可见的,且前一个操作按顺序排在后一个操作之前。
重排序
重排序是指编译器和处理器为了优化程序性能而对指令序列进行重新排序的一种方式。
数据依赖性
如果两个操作访问同一个变量,一个操作为写操作,另一个是读操作,那这两个操作就存在数据依赖性。
//写a
int a = 1;
//读a
int b = a;
编译器和处理器是不会对存在数据依赖关系的两个操作做重排序的。(这里的数据依赖性仅针对单个处理器单线程中的操作,不同处理器不同线程间的数据依赖性不被编译器和处理器考虑)
as-if-serial
as-if-serial的意思是,不管怎么重排序,单线程程序的执行结果不能被改变。编译器和处理器都必须遵守as-if-serial语义。
//写a
int a = 1; //A
//写b
int b = 1; //B
//写c
int c = a + b; //C
比如上面的这个例子,A和B之间没有数据依赖性,A和C、B和C存在数据依赖关系,所以C不允许重排序到A和B前面(一旦排到A或B前面,执行结果必定发生改变),A和B之间爱怎么排怎么排,对于执行结果并无影响。
重排序对多线程的影响
public class Test8 {
int a = 0;
boolean flag = false;
public void writer(){
a = 1; //A
flag = true; //B
}
public void reader(){
if(flag){ //C
int i = a * a; //D
}
}
}
假如有两个线程E和F,E先执行writer()方法,然后F执行reader()方法。最终线程F执行完会得到始终一直的i吗?是不行的。因为操作A和操作B没有数据依赖性,A和B可能发生重排序,操作C和操作D也没有数据依赖性,C和D也可能发生重排序。假设操作A和B发生了重排序,会怎样?
程序时序图如下:
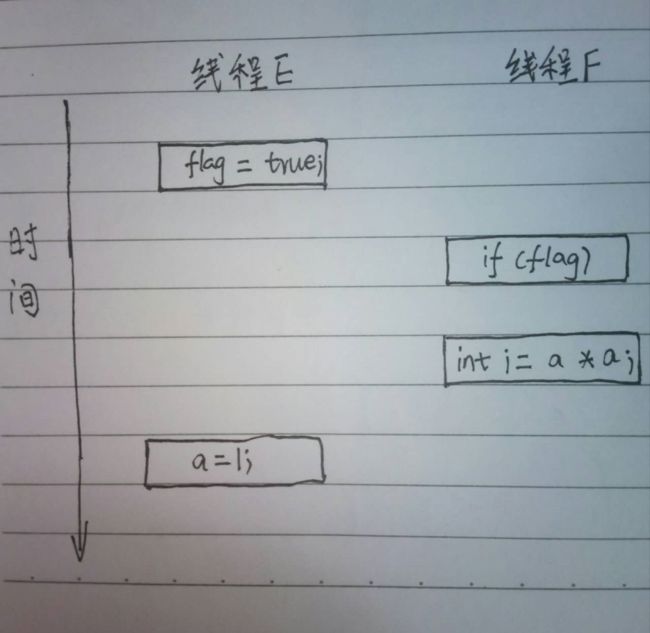
当操作A和操作B发生重排序,线程E首先标记变量flag,随后线程F读flag,flag为真再读取a。此时,变量a并未被线程E写入,多线程语义就被重排序破坏掉了。
内存屏障
内存屏障,又称内存栅栏,是一个CPU指令,基本上它是一条这样的指令:
1、保证特定操作的执行顺序。
2、影响某些数据(或则是某条指令的执行结果)的内存可见性。
编译器和CPU能够重排序指令,保证最终相同的结果,尝试优化性能。插入一条Memory Barrier会告诉编译器和CPU:不管什么指令都不能和这条Memory Barrier指令重排序。
Memory Barrier所做的另外一件事是强制刷出各种CPU cache,如一个 Write-Barrier(写入屏障)将刷出所有在 Barrier 之前写入 cache 的数据,因此,任何CPU上的线程都能读取到这些数据的最新版本。
volatile
volatile是基于Memory Barrier实现的,可以将volatile简单看作是一个轻量级锁。
public class Test8 {
//使用volatile修饰vl
volatile long vl = 0L;
public long getVl() {
return vl;
}
public void setVl(long vl) {
this.vl = vl;
}
public void getAndIncrement(){
vl++;
}
}
假如有多个线程分别调用上面程序的三个方法,程序在语义上和下面程序等价。
public class Test8 {
long vl = 0L;
public synchronized long getVl() {
return vl;
}
public synchronized void setVl(long vl) {
this.vl = vl;
}
public void getAndIncrement(){
long temp = getVl();
temp += 1L;
setVl(temp);
}
}
一个volatile变量的单个读/写操作,与一个普通变量的读/写操作都使用同一个锁来同步效果一样。锁的happens-before规则保证释放锁和获取锁的两个线程间的内存可见性,所以对一个volatile变量的读,总能看到任意线程对这个volatile变量最后的写入。
简单来说,volatile拥有以下特性;
①可见性,对一个volatile变量的读,总能看到任意线程对这个volatile变量最后的写入。
②不保证原子性,对任意单个volatile变量的读/写具有原子性,但对于像volatile++这种复合操作不具有原子性。
如果一个变量是volatile修饰的,JMM会在写入这个字段之后插进一个Write-Barrier指令,并在读这个字段之前插入一个Read-Barrier指令。
当写一个volatile变量时,JMM会把该线程对应的本地内存中的共享变量值刷新到主内存中。
当读一个volatile变量时,JMM会把该线程对应的本地内存置为无效,然后再从主内存中读取共享变量。
问题:volatile为什么对复合操作不保证原子性?
答:拿上面的案例来讲,某个时刻变量vl为10,线程1要调用getAndIncrement(),线程1先读取vl的原始值,然后线程1被阻塞了;然后线程2也要调用getAndIncrement(),线程2也会先读取vl的原始值,由于线程1直对vl进行了读操作,并未做修改,所以不会线程2本地内存中的缓存变量vl失效,不会导致主内存的vl刷新,所以线程2读取的vl还是10,调用完getAndIncrement()后,把11写入本地内存,再写入主内存。接着,线程1也调用了getAndIncrement(),由于已经读取了vl,线程1本地内存的vl依然为10,自增完后vl变为对象11,然后将11写入本地内存,最后写入主内存。2个线程一共执行了两次自增操作,但是最后vl是11不是12。
问题:对于volatile不能保证原子性,如何解决?
答:用synchronized或者Lock来加锁。
问题:volatile和synchronized的区别有哪些?
答:①volatile只能修饰变量,而synchronized可修饰变量、方法、代码块;②volatile在多线程中不存在阻塞问题,synchronized存在阻塞问题;③volatile能保证数据的可见性,不能保证数据的原子性,synchronized能保证可见性、原子性;④volatile解决的是变量在线程间的可见性,而synchronized解决的是线程之间访问资源的同步性。
总结
此篇主要介绍了JMM、happens-before、重排序、内存屏障、volatile的一些基本概念及重要性质。只有真正理解线程之间的通信机制,才能写出健壮的并发程序。
本篇顶多算个基础介绍,需要深入了解的同学可以阅读书籍《并发编程的艺术》、《并发编程实战》。
略陈固陋,如有不当之处,欢迎各位看官批评指正!