最新自然语言处理(NLP)四步流程:Embed->Encode->Attend->Predict
2016-11-22 21:57
http://www.17bigdata.com/%E4%B8%80%E5%A4%A9%E6%90%9E%E6%87%82%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0.html
过去半年以来,自然语言处理领域进化出了一件神器。此神器乃是深度神经网络的一种新模式,该模式分为:embed、encode、attend、predict四部分。本文将对这四个部分娓娓道来,并且剖析它在两个实例中的用法。
人们在谈论机器学习带来的提升时,往往只想到了机器在效率和准确率方面带给人们的提升,然而最重要的一点却是机器学习算法的通用性。如果你想写一段程序来识别社交媒体平台上的侮辱性帖子,就把问题泛化为“需要输入一段文本,预测出文本的类别ID”。这种分类与识别侮辱性帖子或是标记电子邮件类别之类的具体任务无关。如果两个问题的输入和输出类型都一致,那我们就应复用同一套模型的代码,两者的区别应该在于送入的训练数据不同,就像我们使用同一个游戏引擎玩不同的游戏。
笔者用spaCy和Keras实现了自然语言推理的可分解注意力模型。代码已经上传到github
假设你有一项强大的技术,可以预测实数稠密向量的类别标签。只要输入输出的格式相同,你就能用这项技术解决所有的问题。与此同时,你有另一项技术,可以用一个向量和一个矩阵预测出另一个向量。那么,现在你手里就握着三类问题的解决方案了,而不是两类。为什么是三类呢?因为如果第三类问题是通过矩阵和一个向量,得到一个类别标签,显然你可以组合利用前两种技术来解决。大多数NLP问题可以退化成输入一条或多条文本的机器学习问题。如果我们能将这些文本转化为向量,我们就可以复用现有的深度学习框架。接下来就是具体的做法。
文本类深度学习的四部曲
嵌入式词语表示,也被称为“词向量”,是现在最广泛使用的自然语言处理技术之一。词向量表示是一种既能表示词本身又可以考虑语义距离的表示方法。然而,大多数NLP问题面对的不是单个词语,而是需要分析更长的文本内容。现在有一个简单而灵活的解决方案,它在许多任务上都表现出了卓越的性能,即RNN模型。将文本用一个向量的序列表示之后,使用双向RNN模型将向量编码为一个句子向量矩阵。这个矩阵的每一行可以理解为词向量 —— 它们对句子的上下文敏感。最后一步被称为注意力机制。这可以将句子矩阵压缩成一个句子向量,用于预测。
第一步:词向量
词向量表将高维的稀疏二值向量映射成低维的稠密向量。举个例子,假设我们收到的文本是一串ASCII字符,共有256种可能值,于是我们把每一种可能值表示为一个256维的二值向量。字符’a’的向量只有在第97维的值等于1,其它维度的值都等于0。字符’b’的向量只有在第98维的值等于1,其它维度的值都等于0。这种表示方法称为’one hot’形式。不同字符的向量表示完全不一样。

大部分神经网络模型首先都会把输入文本切分成若干个词语,然后将词语都用词向量表示。另一些模型用其它信息扩展了词向量表示。比如,除了词语的ID之外,还会输入一串标签。然后可以学习得到标签向量,将标签向量拼接为词向量。这可以让你将一些位置敏感的信息加入到词向量表示中。然而,有一个更强大的方式来使词语表示呈现出语境相关。
第二步:编码
假设得到了词向量的序列,编码这一步是将其转化为句子矩阵,矩阵的每一行表示每个词在上下文中所表达的意思。

这一步用到了双向RNN模型。LSTM和GRU结构的模型效果都不错。每一行向量通过两部分计算得到:第一部分是正向计算,第二部分是逆向计算,然后拼接两部分得到完整的向量。计算过程如下图代码所示:

我个人认为双向RNN会是今后的主流。RNN的主要应用是读入文本内容,然后从中预测出一些信息。而我们是用它来计算一个中间表达状态。最重要的一点是得到的表达能够反映词语在文中的意义。理论上应该学到“pick up”与“pick on”这两个词语的意义有区别。这一直是NLP模型的巨大弱点。现在我们有了一个解决方案。
第三步:注意力机制
这一步是将上一步的矩阵表示压缩为一个向量表示,因此可以被送入标准的前馈神经网络进行预测。注意力机制对于其它压缩方法的优势在于它输入一个辅助的上下文向量:

Yang等人在2016年发表的论文提出了一种注意力机制,输入一个矩阵,输出一个向量。区别于从输入内容中提取一个上下文向量,该机制的上下文向量是被当做模型的参数学习得到。这使得注意机制变成一个纯粹的压缩操作,可以替换任何的池化步骤。
第四步:预测
文本内容被压缩成一个向量之后,我们可以学习最终的目标表达 —— 一种类别标签、一个实数值或是一个向量等等。我们也可以将网络模型看做是状态机的控制器,如一个基于转移的解析器,来做结构化预测。

有趣的是,大部分的NLP模型通常更青睐浅层的前馈网络。这意味着近期在机器视觉领域取得的重要技术至今为止并没有影响到NLP领域,比如residual connections 和 batch normalization。
实例1:自然语言推测的可分解注意力模型
自然语言推测是给一对句子预测类别标签的问题,类别标签则表示它们两者的逻辑关系。斯坦福自然语言预测文本集使用三种类别标签:
1.推演(Entailment):如果第一句话是真的,那么第二句话一定为真。
2.矛盾(Contradiction):如果第一句话是真的,那么第二句话一定为假。
3.中性(Neutral):上述两者都不是。
Bowman等人在论文中给出了几条例子:
文本内容假设内容标签
某人正在检查一位来自中亚国家人士的服装此人正在睡觉矛盾
一位长者和一位青年在微笑两个人在笑,嘲笑地板上玩耍的猫中性
一辆黑色赛车在人群前面启动一个男人正沿着一条孤独的路行驶矛盾
一种多个男性玩的足球游戏几位男性正在进行体育运动推演
一位微笑盛装打扮的女性拿着一把伞一位快乐的女性在一个童话服装会上握着一把伞中性
这份语料库的目的之一是为我们提供一个新的、规模合适的语料库用于研发将句子编码为向量的模型。例如,Bowman在2016年发表的论文介绍了一种基于转移的模型,它依次读入句子,构建一种树形结构的内部表达。
Bowman他们的准确率达到了83.2%,比之前的工作成果提升了一大截。过了不到半年,Parikh的论文提出的模型取得了86.8%的准确率,而使用的模型参数数量只有Bowman模型的10%。不久之后,Chen等人发表的论文提出了一种效果更好的系统,准确率达到88.3%。当我第一次阅读Parikh的论文时,我无法理解他们的模型如何取得这么好的效果。原因在于他们的模型用独特的注意力机制融合了两个句子矩阵:
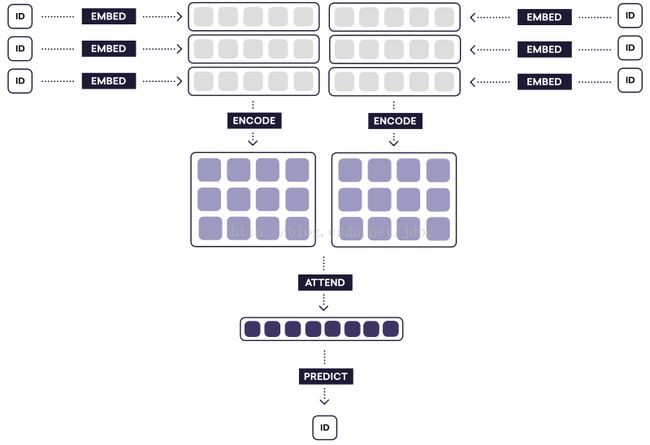
关键的优势是他们讲句子转为向量的压缩步骤合并完成,而Bowman他们则是分别将两个句子转为向量。请记住Vapnik的原则:
“当解决一个关键问题时,不要解决一个更一般的问题作为中间步骤”
—— VLADIMIR VAPNIK
Parikh的论文将自然语言推测任务当做是关键问题。他们想办法直接解决这个问题,因此比单独给句子编码有巨大的优势。Bowman等人则更关注问题的泛化,也是针对此构建模型。他们的模型适用的场景也就比Parikh的模型更广泛。比如说,利用Bowman的模型,你可以缓存句子向量,使得计算句子相似度的效率更高。
实例2:文档分类的分层注意力网络
给文档分类是我接触到的第一个NLP项目。澳大利亚的类似证券交易所的机构资助了一个项目,爬取澳大利亚的网站页面,并且自动检测金融诈骗。尽管这个项目已经过去了一段时间,但是文档分类的方法在之后的十年中几乎没有变化。这也是我看到Yang等人发表的分层注意力网络模型之后如此兴奋的原因。这是继词袋模型之后,我看到的第一篇真正有通用性改进的论文。下面是它的原理。
该模型接收一篇文档作为输入,文档由句子的序列组成,其中每个句子是一个词语的序列。每句话的每个词语分别编码,生成两个词向量序列,每个序列表示一个句子。这两个序列分别编码成两个句子矩阵。然后由注意力机制将句子矩阵压缩为句子向量,多个句子向量又组成文本矩阵。最后一步注意力操作将文本矩阵压缩为文本向量,然后送入最终的预测网络来预测类别标签。
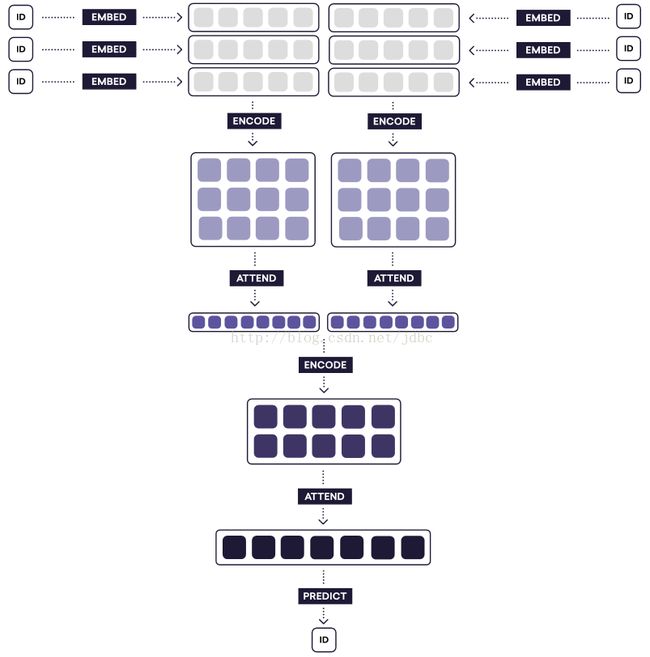
该模型使用注意机制作为一个纯粹的压缩步骤:它学会了把矩阵作为输入,然后将其概括成一个向量。这种学习过程是通过学习上下文向量的两个注意力转换,我们可以将这种转换理解为表示模型认为相关的词语或者句子,该模型会找到理想相关。或者,你也可以把整个压缩过程看做是特征提取的过程。按照这种观点,上下文向量只是另一个不透明的参数。
作者方法YELP ‘13YELP ‘14YELP ‘15IMDB
Yang et al. (2016)HN-ATT68.270.57149.4
Yang et al. (2016)HN-AVE6769.369.947.8
Tang et al. (2015)Paragraph Vector57.759.260.534.1
Tang et al. (2015)SVM + Bigrams57.661.662.440.9
Tang et al. (2015)SVM + Unigrams58.96061.139.9
Tang et al. (2015)CNN-word59.76161.537.6
将yang等人的模型与卷积神经网络做比较,可以得到有意思的结果。两个模型都能自动提取位置敏感特征。然而,CNN模型既不通用,效率也较低。而双向RNN模型只需要对每个句子读入两次 ——正向一次,反向一次。LSTM编码还能提取任意长度的特征,因为句子上下文的任何信息都有可能被揉入词语的向量表示。将句子矩阵压缩成向量的步骤简单并且有效的。要构建文档向量,只需要对句子向量再进行一次同样的操作。
提升模型准确率的主要因素是双向LSTM编码器,它创建了位置敏感的特点。作者通过将注意力机制替换为平均池化,证明了上述观点。使用平均池化的方法,该模型在所有测试数据上仍然优于以前的最好模型。然而,注意力机制进一步普遍地提高了性能。
后续内容
我已经用我们自己的NLP库spaCy实现了第一个例子,我正在实现文本分类的系统。我们还计划开发一个SpaCy版的通用双向LSTM模型,能够方便地将预训练的词向量用于实际问题中。