如何成为一名数据科学家
本文总结了数据科学领域的资源,很大程度上参考了Quora的这篇文章,根据博主的经验在内容上做了适当的调整,仅供参考
1.基础知识
课程方面要学的有:多值微积分、数值分析、线性几何、概率论、Python
微积分在机器学习和各种求概率中非常重要。线性几何、矩阵对于机器学习的大多数概念都是必不可少的。Python这种编程语言非常适合搞数据科学。其他的知识(比如随机森林,pandas,A/B测试)随着你的工作开展和学习会慢慢接触到,这些都不是基本的问题。
如果你还是学生,一定要学好计算科学和统计学,选课的时候要记得选线性几何、矩阵、计算科学、概率论等相关的课程。
2.Python是数据科学家最重要的语言
Python有着像matlab一样强大数值计算工具包NumPy;有着绘图工具包matplotlib;有着科学计算工具包SciPy(基于Numpy和matplotlib的)。这三者为Python提供了像Matlab一样强大的矩阵控制能力,这是Python完胜Perl和Ruby的地方。
当然,除了Python之外,R,Matlab/Octave,Mathematica/Sage也正在崛起。这些语言也有着一些优势。不过,就拿R来说,R的数据框架和相关的控制能力已经被Python的pandas工具包实现了。Scikit-learn也提供了像R一样强大的机器学习算法库。 Mathematica/Sage中“notebook”的概念也被IPython notebooks实现了。
当然,Python也不是万能的,比如:
语法比起Matlab和Octave来说还是笨重了,R的语法就好很多
Python缺少像ggplot2这种静态图和D3这种可交互图,matplotlib用起来还是比较复杂
处理大数据时,Numpy和pandas这些库有些捉襟见肘,Continuum正在致力于解决这个问题,目前来看还没有完成
对于数据控制,缺少像LINQ那样的内置的声明式的语言。Pandas对数据控制的能力还是比较低级,而且当你深入研究Pandas的时候很可能会被它的语法整崩溃
缺少面向数据科学家的专门的IDE,R的R Studio就不错
对于数据科学家而言,Python可能是最重要的语言了,如前文所述,它有着非常丰富的生态系统。
R语言能够在处理过的数据上运行机器学习算法,但是Python直接能够处理数据,而Pandas几乎可以像SQL那样对数据进行控制。Matplotlib能够让你对数据和结果进行可视化,以便快速理解你的数据。Scikit-learn提供了机器学习算法支持,Theano提供了深度学习框架(还可以使用GPU加速)。用过R、matlab、Octive、Python、SAS和Microsoft Analysis Services的人都推荐用Python。
3.加入社区
Meetup:到Meetup上找一些你感兴趣的talk,在线的学习数据科学,认识一些数据科学家或者将来的数据科学家。
博客:这里有个国外比较具有影响力的数据科学家的博客列表,可以选一些follow。
Quora、twitter:数据科学第一手的信息资源的来源一般是twitter、Quora上的用户,例如
Jeff Hammerbacher @hackingdata
Peter Skomoroch @peteskomoroch
Ryan Rosario @datajunkie
Michael E Driscoll @medriscoll
Joseph Turian @turian
Nathan Yau @flowingdata
Peter Skomoroch @peteskomoroch
Russell Jurney @rjurney
Bradford Cross @bradfordcross
J.D. Long @cmastication,Jimmy Lin @lintool
Kevin Weil @kevinweil
Mat Kelcey @mat_kelcey
Edwin Chen @edchedch
Data Drinking Group @chrisalbon/data-drinking-group
Big Data @dataspora/bigdata
Data Science @pinoystartup/sim-data-team
Strata Program Committee @strataconf/strata-committee
到Quora和Twitter上去follow这些人吧,别忘了follow自己这个领域最牛的那几个人,比如博主follow了Socher。另外,这个网站分析了twitter上哪些人在数据科学领域最具影响力。Quora上有很多资源,跟stackoverflow不同的是,Quora比较像知乎,会有人给你一些像survey类型的经验,一般问题都比较抽象,回答比较系统;stackoverflow更擅长具体的问题,尤其是编程方面的细节问题。
新浪微博:由于博主只是一个普通的微博用户,且个人较偏向于文本方向,对大咖们的了解还不够深入,难免有缺漏,如果有缺漏了请多包涵且告知。以下是我个人关注的微博大咖们:
王威廉
王伟DL
刘知远THU
张栋_机器学习
李航博士
丕子
winsty
黄亮-算法时代
梁斌penny
licstar
老师木
数盟社区
52nlp
好东西传送门
西瓜大丸子汤
数据挖掘研究院
爱可可-爱生活
龙星镖局
另外,好东西传送门的日报每天都会收录微博精华,懒得刷微博的同学可以看这里http://memect.com/
个人加的几个QQ群:
自然语言处理 174735435
龙星课程-机器学习 163973179
神经网络 / 深度学习 385206220
Deep Learning高质量 209306058
生物医学文本挖掘BIONLP 290210559
数盟【数据分析1群】 321311420
4.配置你的环境
Python的安裝
R和R studio
Sublime Text(比notepad++和ue更适合写代码,个人用的eclipse+PyDev)
5.学习相关工具的使用
Python: 可以结合官方教程、笨办法学Python(英文原版)、Think Python:How to Think Like a Computer Scientist来学习。书可以从这里找几本。当然,找到最适合自己的方式是最好的,以上只是提供一些选择而已,博主当时是学的Udacity的programming language外加Natural Language Processing With Python
R: 推荐swirl,一个数据科学和R配套学习的教程
Sublime Text:这个网站还不错,从配置到快捷键,里边的视频在youtube上
SQL: 个人感觉这个不太重要,而且SQL相对来说较简单,对找工作也许有点用处
结合概率统计来学习: 以上这些语言比起C、Java来说语法很简单,有基础的同学很轻松就能掌握,对于这类同学来说,可以结合概率统计顺便把编程语言给学了。例如:针对Python的Think Stats(pdf)、针对R的An Introduction to Statistical Learning(MOOC)、应该掌握的统计学知识点可以参考这里。
6.哈佛的data science公开课
不必多说,看了再说,视频,配套PPT,配套实验,配套作业
7.到Kaggle上找一些基础的竞赛练手
刚开始的时候最好不要直接参加由奖金的竞赛,因为这些竞赛的数据往往很大、复杂、晦涩,不适合学习。可以先学(wan)学(wan)Scikit-learn,拿这个简单的二元分类任务练手:Data Science London + Scikit-learn。
接下来可以进军第二个任务:Titanic: Machine Learning from Disaster,这个任务比第一个要稍微复杂那么一点(有枚举类型的变量categorical variables,丢失的变量这些情况了)。
第三个任务,可以尝试Forest Cover Type Prediction。
第四个任务,可以尝试Bike Sharing Demand,这里边有一些时间戳数据。
第五个任务,尝试一些自然语言处理的任务,如情感分析。
做完这些之后,再找些自己感兴趣的竞赛做做。
8.数据科学相关的知识
产品指标会教你公司里边关心什么、看重什么、他们是怎么衡量产品的:The 27 Metrics in Pinterest’s Internal Growth Dashboard
优化方法能帮你理解统计学和机器学习:Convex Optimization - Boyd and Vandenberghe
A/B测试其实在医学上已经应用多年了,只是换了个名字而已:How do I learn about A/B Testing?
用户行为This Explains Everything " User Behavior
Feature Engineering一些经验,一个案例
大数据技术针对大数据技术的工具、框架How do I learn big data technologies?
Machine LearningHow do I learn Machine Learning?
Natural Language Processing自然语言处理需要把文本数据数学化,并且要尽量不丢失文本的“含义”。文本挖掘会让你接触全新的、令人兴奋的数据(做了都说好,谁做谁知道)How do I learn Natural Language Processing (NLP)?
时间序列分析How do I learn about time series analysis?
数据文明data-driven.pdf
9.参与/solo个顶层产品
用已掌握的数据科学和软件工程技能做出个让别人看了会点赞的成品出来,可以是网站、处理数据的新方法、炫酷的可视化等等。要做这么个成品,可以先看看以下内容:
数据科学中的toy problem
如何搭建一个推荐引擎
怎么利用利用闲暇时间快速搭建Python项目
如何衡量一个twitter用户的影响力
开放的大规模数据集
邮件优先级相关算法
一些优秀的数据科学project
10.公开和社交
在github上创建公开的仓库,写博客,把你的研究工作、参与的项目、Kaggle竞赛的解决方案、见解和想法都贴出来,这会让你提升影响力,为你的简历准备素材,跟通灵玉的其他人建立联系。
11.获得数据科学的实习或工作
BAT都有相关领域的实习岗位,另外这里有些国外的提供实习机会的公司
搞不清自己该申请数据科学还是软件开发的实习?参考这里
现在很多公司在初秋一直到冬天都会招聘数据科学岗位实习,仅仅是实习的话,记得不要花过多的时间去准备,直接去应聘就行。
12.在线书籍
Elements of Statistical Learning: data mining, inference, and prediction. 2nd Edition.
Introduction to Statistical Learning: Page on usc.edu
Think Stats: Probability and Statistics for Programmers
13.像数据科学家一样思考
以上已经详细的介绍了数据科学家所需要的具体技巧。想要像数据科学家一样思考,建立正确的态度,只有这些技术是远远不够的。以下列出了成为合格数据科学家的7项挑战:
(1) 保持对数据的好奇
作为一名数据科学家,你要自己找问题并且自己做出回答。数据科学家要自然而然的对他们看到的数据产生好奇,并找到解决问题的创新性方法。
很多时候数据科学并不只是分析,而是找出一个有趣的问题并且找到解决方案。
这里有两个典型的案例:
Hilary: the most poisoned baby name in US history
A Look at Fire Response Data
总结: 对你感兴趣的问题或者主题进行思考,然后用数据的方式作出回答。
(2) 用怀疑的眼光阅读新闻
数据科学家的很多贡献往往是,他们从一堆信息里找出了哪些是重要的、哪些是假的(这是机器很难取代数据科学家的原因),这种习惯性的怀疑的眼光在任何科学领域都是有益的,尤其是在发展速度快的领域,因为这些领域更容易被假象误导。
在看新闻的时候练习批判性的眼光吧,很多文章本质上都是有瑕疵的。这里有两个例子,评论里有答案:
Easier:You Love Your iPhone. Literally
Harder:Who predicted Russia’s military intervention?
总结:每当你看到新的文章时,记得持怀疑的态度,对文章进行评论,并指出它的问题在哪。
(3) 把数据看成是改善消费者产品的工具
试着了解一款互联网产品,检查它的主要渠道。有没有结账渠道?注册渠道?订单渠道?
反复的检查这些渠道,然后提出一些假设方案来提升核心指标(比如转化率、用户分享数、注册用户数量等)。设计实验来验证你的假设是否真的会改变这些指标。
总结:通过反馈邮件跟这个网站分享你的idea
(4) 像贝叶斯一样思考
像贝叶斯一样思考,用先验来作判断。这意味着,要想树立起数据科学家的思维方式,就必须一方面能够周详考虑新观测到的信息,另一方面又需要以往的直觉和经验(贝叶斯里的先验)。
比如,检查下数据,发现今天的用户参与量明显下降了,下面哪种原因是最有可能的呢?
用户参与量就是会突然的减少
网站的某些功能down掉了
登陆模块down掉了
尽管1也能够作为一种解释,但是2和3看上去比1更靠谱,因为根据先验概率来看,2和3的概率要比1更大。
再比如,你是Tesla公司的高级工程师,而在上个月中,5辆Tesla S着火了。有可能是什么原因呢?
生产质量下降了,现在Tesla的安全性应当被重新测试
安全性不是问题,因为与其他同行汽油车相比,Tesla S着火的概率已经算很低的了
即使没什么经验的人也可能会得出1这样的结论,如果你经常做质量测试,那你的先验对2是否正确就会更有把握。不过,你应该继续寻找分别支持两个结论的信息,并继续寻找提升质量的办法,那么问题来了:什么样的信息应该值得留意呢?
总结:回想一下你上一次没有用先验来指导思考就得出结论是什么时候,从现在开始避免再犯类似的错误。
(5) 了解每种工具的能力
“Knowledge is knowing that a tomato is a fruit, wisdom is not putting it in a fruit salad.” - Miles Kington
知识会指导你实现经典的线性回归,而经验会告诉你这在实际当中几乎不会用到。
知识会让你了解k-means聚类的5种变种,而经验会告诉你实际当中几乎不会单独在数据上聚类,以及k-means在特征过多的时候表现是多么的不如人意。
知识会告诉你一堆复杂的技术,而经验会告诉你怎么在有限的时间里从这里边为你的公司选择一个最能产生效益的。
当你到Coursera或EdX上学一门课的时候,你可能会随着课程开发出一堆工具,除非你能搞清楚在什么场合下用哪个合适,否则这一堆工具毫无实际作用。
总结:在真实数据上尝试各种工具,发现他们各自的优点和不足。哪种工具在这种场合下最好,为什么?
(6) 给别人讲一个复杂的概念
Richard Feynman是怎么判断哪个概念他能懂,哪个不懂呢?
Feynman称得上是一位伟大的老师,他能够向一些什么都不懂的学生讲明白一些较深的知识,这一点他为自己感到自豪。有人告诉他说:“Dick,跟我解释一下,为什么自选1/2粒子服从费米 - 狄拉克统计”,他考虑了一下听众的知识水平,然后说,“我会针对这个专门为新生讲一次课的。”过了几天他说:“我做不到。这个知识没有办法简化到新生能听懂的地步。这意味着我们并没有真的搞懂了这个知识点”
Richard Feynman与众不同的地方就在于他能够提炼复杂的概念,把他们转换成可以理解的想法。类似的,一流的数据科学家与众不同的地方就是他们能够诚恳的分享他们的想法并且对这些想法作出解释和分析。
总结:把你懂的一种技术概念介绍给你的朋友吧,也可以是在知乎、Quora或者优酷、youtube上。
(7) 说服其他人什么才是重要的
对一个数据科学家来说,比解释他们的分析更重要的,可能是与大家交流某个见解的价值和潜在的影响。
数据科学的某个具体的任务将会商品化编程数据科学工具,然后不断的完善。新工具会让一些任务更新迭代,比如手写版应用、data wrangling(数据清洗)、甚至是某些预测建模。
然而,数据科学家发现并和别人分享什么才是重要的,这种能力永远不会过时。数据量在逐渐增加,对数据的一些潜在的见解也在增加,公司总会需要数据科学家来找出该怎么做才能对任务进行优化。
数据科学家在企业中扮演的角色,是数据和公司之间的使者。数据科学家成功与否,关键在于他/她是怎么讲故事的、以及对公司带来了什么样的影响,其他的技能都是对这种能力的一种放大。
总结:从统计学的角度来讲故事吧,跟别人交流你在数据上的重要发现,针对观众关心的事做些具有说服力的presentation。
14.关于找工作
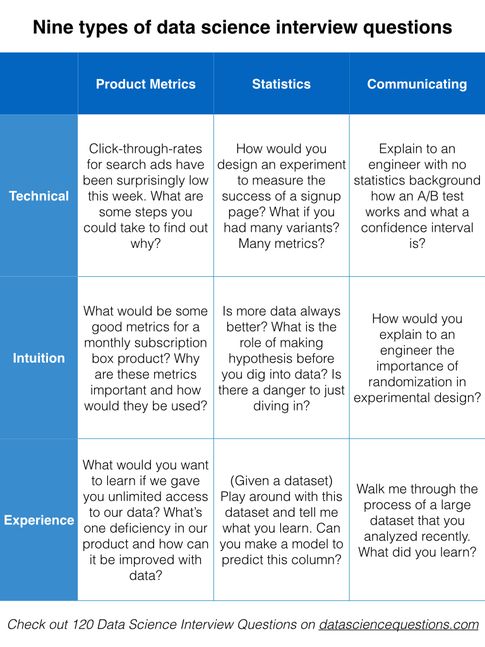
15.不同人群如何成为数据科学家定制版
本科生如何成为数据科学家
博士生如何成为数据科学家
没有任何技术的人如何数据科学家
没有本科学历如何成为数据科学家
没有博士学历如何成为数据科学家
物理专业的博士如何成为数据科学家
正在从事其他行业工作的人如何成为数据科学家
不会编程如何成为数据科学家
更多的数据科学FAQ