本文译自《Query Planning》
概述
SQL最好的特性就是它是一种描述性语言,而不是过程式语言。不光是SQLite,在所有的SQL实现中它都是这样。当你编写SQL时,你告诉系统你想要得到的结果,而不是如何去计算它。决定“如何计算结果”这件事由数据库引擎中的查询计划器来完成。
对于每一条给定的SQL语句,可能有成百上千种不同的算法可以实现它。尽管每种算法都能得出正确结果,但有些算法比其他的运行的更快。查询计划器是一个AI,它尽量为每条SQL语句找出最快最高效的算法。
大多数情况下,SQLite的查询计划器工作的很好。然而,查询计划器需要与索引配合,这些索引通常必须由程序员指定。查询计划器在个别时候也会得出次优解,这时程序员可能希望提供额外的提示来指导查询计划器的工作。
这篇文档提供了关于SQLite查询计划器和查询引擎工作原理的背景知识。程序员可以使用这些信息创建出更有效的索引,或在必要时向查询计划器发出提示。
更多的信息请参考 SQLite query planner和next generation query planner等文档。
1. 搜索
1.1 不加索引的表
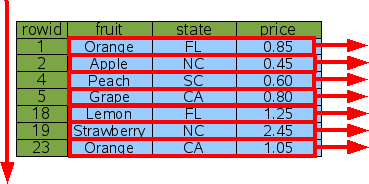
SQLite中绝大多数表都包含一个unique列,如 rowid 或INTEGER PRIMARY KEY,有一类表是例外,那就是无ROWID的表。逻辑上讲,各个行按rowid的升序存储。本文以FruitsForSale这个表为例,这个表记录了各种水果的名称,产地和市价。表的schema如下:
CREATE TABLE FruitsForSale(
Fruit TEXT,
State TEXT,
Price REAL
);
我们向表中插入一些数据(纯属虚构),这张表的逻辑存储结构如图1:

在这个例子中,rowid不是连续的,但是是有序的。SQLite通常从1开始创建rowid,并每次自增1。但如果行被删除了,rowid之间可能出现空隙。应用层可以选择控制rowid的分配,所以新的行不一定会被添加到最底部。不过无论如何,rowid是唯一的,并保持升序。
假如你想要查询peach的价格,那么SQL语句如下所示:
SELECT price FROM fruitsforsale WHERE fruit='Peach';
为了满足这个查询,SQLite读取表中的每一行,检查fruit列是否为Peach,如果是则输出对应的price。这个过程如图2所示。

这个算法被称为全表扫描,因为必须遍历表才能找到感兴趣的行。对于只有7行的表来说,全表扫描可以接受,但如果表包含7百万行的话,全表扫描为了找出几字节的数就要读取几M字节。因此,我们要尽力避免全表扫描。
1.2 按rowid查找
一种避免全表扫描的技术是按rowid查找(或者按 INTEGER PRIMARY KEY查找,它们等价)。为了查找peach的价格,我们查询rowid为4的行:
SELECT price FROM fruitsforsale WHERE rowid=4;
因为信息按照rowid顺序存储在表中,SQLite可以用二分法找出正确的行。对于N行的表,可以用O(logN)的时间查出所需要的行,而全表扫描需要O(N)的时间。如果表包含一千万条数据,按rowid查找快了大约一百万倍。

1.3 按索引查找
按rowid查找的问题就是,我们想查的是peach的价格,谁知道peach的rowid是不是4呢?
为了让最初的查询更有效率,我们可以为fruit列增加索引:
CREATE INDEX Idx1 ON fruitsforsale(fruit);
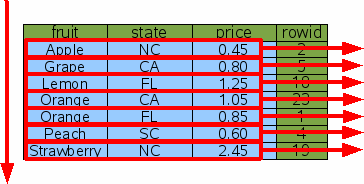
索引是与原fruitsforsale表相似的另一张表,但是被索引内容(这个例子中是fruit列)被放在rowid前边,并且所有的行按被索引列排序。图4给出了Idx1的逻辑视图。

fruit列是用来给元素排序的主键,而rowid是在fruit相同时给元素排序的次级键。注意,因为rowid是唯一的,因此rowid和fruit组成的复合键也是唯一的。
新的索引可以被用作实现一个更快的查找peach价格的算法。
一开始,先对Idx1索引进行fruit=‘Peach’的二分查询,SQLite能在Idex1上进行二分查询,是因为Idex1是按照fruit列排序的。在Idx1查找到fruit=‘Peach’的行之后,数据库引擎可以提取出rowid。然后数据库引擎根据rowid,对原表再进行一次二分查找。最后根据原表的行,可以得到Peach对应的price。这个过程如图5所示:

使用上边的方法,SQLite必须使用两次二分查找来查出peach的价格。然而对于一个数据量大的表来说,这仍比全表扫描快很多。
1.4 多行结果
前一个查询中,fruit=‘Peach’这个约束只有一行满足。但是当结果为多行时,也可以使用相同的技术。假设我们现在查找Oranges的价格
SELECT price FROM fruitsforsale WHERE fruit='Orange'
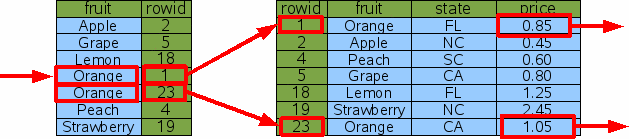
在这种情况下,SQLite仍然使用一次二分查找来搜索第一个fruit=‘Orange’的行。然后它根据rowid回原表中查找价格。不过与原先不同,数据库引擎读取下一行,并将回原表查询的操作重复一遍。读取索引的下一行的开销远远低于一次二分查找,以至于可以忽略不计,因为下一行往往与刚读取的行在相同的页中。所以我们估计总开销为3次二分查找。如果有K行结果,那么查询的开销为(K+1)*logN。
1.5 多个AND连接的WHERE子句
接下来,假设你不管要查Orange的价格,而且要求Orange的产地是California。SQL语句如下所示:
SELECT price FROM fruitsforsale WHERE fruit='Orange' AND state='CA'
一种可选方案是先找出所有Orange行,然后再过滤产地不为CA的行,这个过程如图7所示
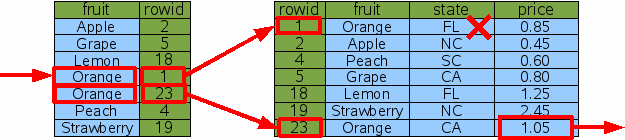
大多数情况下,这是个很合理的方案。不过数据库引擎必须为Florida的Orange做额外的二分查找,所以可能没有我们期望的那么快,尽管对多数应用来说,这足够快了。
假设我们再为state创建索引:
CREATE INDEX Idx2 ON fruitsforsale(state);
state索引和fruit索引的原理相同,只不过主键变成了state。在我们的例子中,state列的取值比较少,因此索引中每个state对应的行较多。
使用新的Idx2索引,SQLite有了更多选择:查出所有产自CA的水果,然后从其中过滤出Orange。
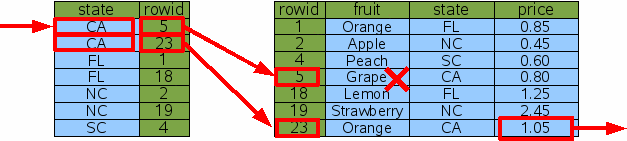
使用Idx2代替Idx1导致SQLite得出了不同的行集,但是最终结果是相同的。这非常重要,索引不改变查询结果,只是加快查询速度。这里使用Idx1和使用Idx2的查询时间相同,所以Idx2并没有提升性能。
最终两个查询花费了相同的时间,那么SQLite最终会选择哪个索引呢?如果ANALYZE命令在数据库上执行,那么SQLite会获得一个收集索引数据的机会,然后SQLite会知道Idx1通常将查询范围缩小到1行,而Idx2通常将查询范围缩小到2行。所以,如果没有其他条件,SQLite将会选择Idx1,因为它通常会让搜索范围变得更小。
这个选择不是确定的,因为它依赖ANALYZE提供的数据。如果ANALYZE没有运行,那这个选择就是随意的。
1.6 多列索引
为了实现多个AND连接的WHERE子句的最大性能,你十分需要一个多列索引来覆盖每一个AND子句。这种情况下,我们创建在fruit列和state列上创建一个新的索引。
CREATE INDEX Idx3 ON FruitsForSale(fruit, state);
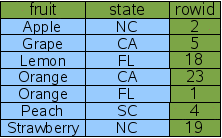
多列索引和单列索引的形式相同,都是rowid跟在被索引列后边。唯一的区别是现在被索引列有两个。最左边的列是用来给整个索引排序的主键。因为rowid确保是唯一的,所以即使所有除rowid的列都相同,也能保证索引行的唯一性。
使用新的多列索引Idx3,SQLite有可能只用两次二分查找就能找出CA的Orange。
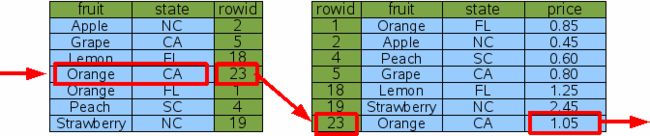
因为Idx3包含了所有WHERE子句中要查找的列,所以SQLite可以用一次二分查找搜索出一个rowid,然后回原表再做一次二分查找。这里没有无效的查找,因此效率更高。
注意,这里Idx3包含了Idx1的所有信息,所以在Idx3存在的情况下,我们不再需要Idx1。如果要查找Peach的价格,我们只需要使用Idx3,并忽略它的“state”列。
SELECT price FROM fruitsforsale WHERE fruit='Peach';
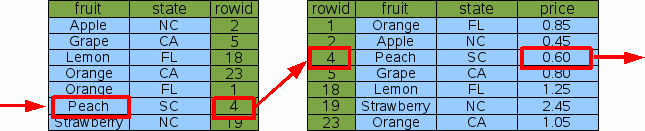
由此可见,数据库设计的一条原则是,schema不应该包含两个这样的索引,其中一个索引是另一个索引的前缀。删除其中列较少的索引,SQLite仍能高效地查找。
1.7 覆盖索引
通过双列索引,查询California Orange的价格变得更快。但是如果创建一个包含price的三列索引,SQLite可以做的更快。
CREATE INDEX Idx4 ON FruitsForSale(fruit, state, price);
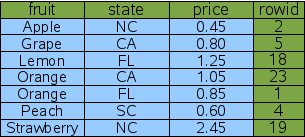
新的索引包含了查询所要用到的所有列,WHERE子句中的和要输出的。我们称这种索引为覆盖索引。使用这种索引时,SQLite不需要回原表查询。
SELECT price FROM fruitsforsale WHERE fruit='Orange' AND state='CA';

由此可见,将被输出的列也加入索引,我们可以避免回原表查询的操作,来让二分查找的次数减半。这可以让查询速度获得大概两倍的提升。但是另一方面,这只是一个细微的优化,两倍的提升并不像刚加索引时百万倍的提升那样戏剧性。对大多数查询来说,1ms和2ms的开销没什么差别。
1.8 多个OR连接的WHERE子句
多列索引只在约束条件用AND连接时起作用。所以Idx3和Idx4只在搜索既是Orange,又生长在California的水果时有用。如果我们想要查找Orange,或者生长在California的水果,这两个索引则起不到作用。
SELECT price FROM FruitsForSale WHERE fruit='Orange' OR state='CA';
当处理OR连接的WHERE子句时,SQLite检查每个被OR连接的条件,并且尽力对每个子句都使用索引。然后对各个条件查出的rowid取并集。这个过程如下图所示:
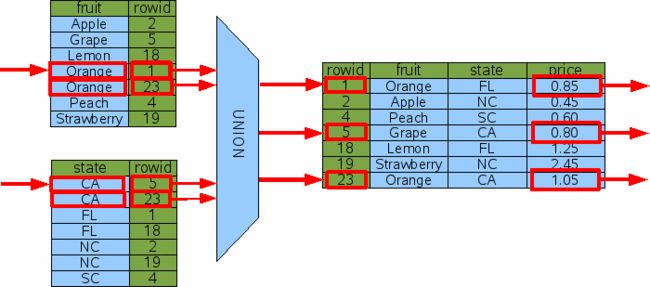
上图显示了SQLite先计算各个组的rowid,然后对它们取并集,最后回原表查询。实际上rowid查找和求并集是交替进行的。SQLite一次使用一个索引来查找rowid,同时将它们标记为已查过,来避免之后出现重复。当然,这只是一个实现细节。上图很好地概述了算法过程,虽然不是完全精确。
为了让上边的取并集技术(OR-by-UNION)奏效,每个被OR连接的WHERE子句必须要有一个索引。即使只有一个子句没被索引,那么为了找出这个子句对应的rowid,SQLite必须进行全表扫描。如果要进行全表扫描,那么之前那些并集,二分查找操作也就么必要了,直接在全表扫描时全都查出来就行了。
我们可以发现,通过取并集实现OR(OR-by-UNION)的技术可以被推广到AND。被AND连接的WHERE子句可以使用多个索引查询rowid,然后取交集。许多数据库引擎就是这么做的。但是这比只是用一个索引的性能提升很小,所以SQLite目前没有实现这种技术。然而,SQLite未来版本可能会支持取交集实现AND(AND-by-INTERSECT)。
2. 排序
除了加快查找,SQLite以及其他的SQL数据库引擎也可以使用索引来完成ORDER BY子句。换句话说,索引除了能加快搜索,也能加快排序。
当没有合适的索引可以用时,一个带ORDER BY的查询必须分步骤进行排序。考虑如下的查询:
SELECT * FROM fruitsforsale ORDER BY fruit;
SQLite先查出所有输出,然后通过sorter对结果进行排序。

如果输出行数为K,排序的复杂度为K*logK。如果K很小,那么排序的时间无关紧要,但如果像上边这样,K等于表的总行数,那么排序花费的时间会远大于全表扫描的时间。此外,整个输出的中间结果被存在临时存储中(可能是硬盘,也可能是内存,取决于许多编译时和运行时的设置),这意味着查询将消耗大量临时存储空间。
2.1 按rowid排序
因为排序操作开销很大,SQLite会努力避免排序。如果SQLite能确定输出结果已经按照指定的方式排序,那么它不会在进行排序操作。所以,比如你希望输出按照rowid的顺序,那么排序操作就不会执行。
SELECT * FROM fruitsforsale ORDER BY rowid;
你也可以要求按rowid的逆序输出,像这样:
SELECT * FROM fruitsforsale ORDER BY rowid DESC;
SQLite仍会忽略排序操作。不过为了逆序输出,SQLite将会从后向前扫描表,而不是像图17那样从前到后。
2.2 按索引排序
当然,将输出按rowid排序通常没什么用。通常我们希望结果能按照其他的某一列排序。
如果ORDER BY制定的列上有索引,那么索引可以用来排序。考虑如下的查询:
SELECT * FROM fruitsforsale ORDER BY fruit;

为了查出按fruit排序的rowid,Idx1索引被从前到后扫描(如果有DESC,那么就是从后到前扫描)。对于每一个rowid,都需要用一次二分查询来查出对应的行。通过这种方式,不需要额外的排序步骤就能使结果按顺序输出。
但这真的节省了时间么?如果我们不使用索引,全表排序的复杂度为NlogN,因为他要为N个数据排序。然而当我们使用Idx1时,我们必须要做N次复杂度为logN的二分查找,所以复杂度仍然是NlogN。
SQLite使用基于开销的查询计划器。当有两个或更多可选方案时,SQLite试图分析各个方案的总开销,然后选择开销最低的方案。开销的计算主要考虑运行时间,它可能根据表的大小和WHERE子句的情况而变化。但通常来讲,索引排序可能会被选择。因为它不需要将结果集存进临时存储中,因而空间开销更小。
2.3 使用覆盖索引排序
如果能使用覆盖索引,那么多次根据rowid回原表查询的操作就能避免,开销会产生戏剧性的降低。
通过一个覆盖索引,SQLite可以直接将索引从头到尾遍历一遍,然后输出结果,这只需要O(N)的开销,也不需要大量的额外存储。