Mastering the game of Go without human knowledge
authors:David Silver, Julian Schrittwieser, Karen Simonyan, ioannis Antonoglou, Aja Huang, Arthur Guez, Thomas Hubert, Lucas baker, Matthew Lai, Adrian bolton, Yutian chen, Timothy Lillicrap, Fan Hui, Laurent Sifre, George van den Driessche, Thore Graepel & Demis Hassabis
Abstract
Here we introduce an algorithm based solely on reinforcement learning, without human data, guidance or domain knowledge beyond game rules.
人工智能的一个长期目标便是算法可以在挑战性领域中学习,纯粹的,并有着超过人类表现的能力。最近,AlphaGo成为了第一个能够打败世界围棋冠军的程序。AlphaGo的树搜索方法分析位置并通过深度搜索树来选择下一步。这些神经网络通过监督学习和人类围棋步骤来学习训练,通过加强学习来自我博弈。这里我们介绍了一种只基于增强学习方法的算法,不需要人类的数据,指导或者除了规则之外的其他专业知识。AlphaGo成为了自己的老师:一个神经网络用于预测AlphaGo自身的步骤选择并成为了AlphaGo对局中的赢家。这种神经网络提升了树搜索的强度,通过高质量的步骤选择和在下一次迭代的强大的自我博弈能力。从最空白的时刻开始,我们的新程序AlphaGo Zero达到了超过人类的性能,和前任已经打败了冠军的AlphaGo相比,是100:0的成绩。
Contribution:
- Much progress towards artificial intelligence has been made using
supervised learning systems that are trained to replicate the decisions
of human experts。 - By contrast, reinforcement learning systems are trained from their own experience, in principle allowing them to exceed human capabilities, and to operate in domains where human expertise is lacking.
- Recently, there has been rapid progress towards this
goal, using deep neural networks trained by reinforcement learning.
graph LR
AlphaGo_Fan-->AlphaGo_Lee
AlphaGo_Lee-->AlphaGo_Zero
Our program, AlphaGo Zero, differs from AlphaGo Fan and AlphaGo Lee in several important aspects:
- First and foremost, it is trained solely by self-play reinforcement learning, starting from random play, without any supervision or use of human data.
- Second, it uses only the black and white stones from the board as input features.
- Third, it uses a single neural network, rather than separate policy and value networks.
- Finally, it uses a simpler tree search that relies upon this single neural network to evaluate positions and sample moves, without performing any Monte Carlo rollouts.
首先,它只是通过自我强化学习进行训练,是无监督的方法。
第二,输入只是黑白棋。
第三,它只使用single neural network,而不是分别的policy network和value network。
最后,它使用更简单的tree search,依靠这个单一的神经网络来评估位置和样本移动,而不执行任何Monte Carlo rollouts。
Reinforcement learning in AlphaGo Zero
Self-play training pipeline:


The main idea of our reinforcement learning algorithm is to use these search operators repeatedly in a policy iteration procedure: the neural network’s parameters are updated to make the move probabilities and value (p, v)=fθ(s) more closely match the improved search probabilities and self-play winner (π, z); these new parameters are used in the next iteration
of self-play to make the search even stronger.
The neural network $(p,v)=f_{\theta_i}(s) $ is adjusted to minimize the error between
the predicted value v and the self-play winner z, and to maximize the
similarity of the neural network move probabilities p to the search
probabilities π.
Loss function $l $ that sums over the mean-squared error and cross-entropy losses, respectively:
Empirical analysis of AlphaGo Zero training

Notably, although supervised learning achieved higher move prediction accuracy, the self-learned player performed much better overall, defeating the human-trained player within the first 24h of training. This suggests that AlphaGo Zero may be learning a strategy that is qualitatively different to human play.

- Using a residual network was more accurate, achieved lower error and improved performance in AlphaGo by over 600 Elo.
- Combining policy and value together into a single network slightly reduced the move prediction accuracy, but reduced the value error and boosted playing performance in AlphaGo by around another 600 Elo.
Knowledge learned by AlphaGo Zero
AlphaGo Zero discovered a remarkable level of Go knowledge during its self-play training process. This included not only fundamental elements of human Go knowledge, but also non-standard strategies beyond the scope of traditional Go knowledge.
AlphaGo Zero rapidly progressed from entirely random moves towards a sophisticated understanding of Go concepts.
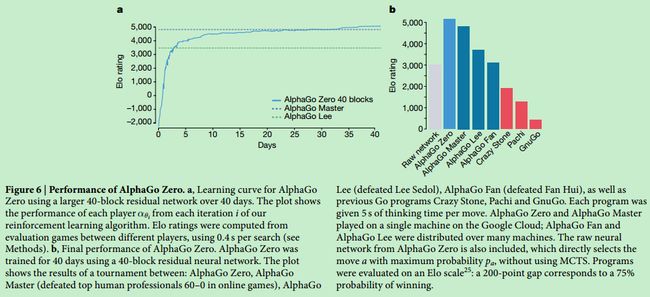
Final performance of AlphaGo Zero
The learning curve is shown in Fig. 6a.
Figure 6b shows the performance of each program on an Elo scale.
Conclusion
- a pure reinforcement learning approach is fully feasible, even in the most challenging of domains
- a pure reinforcement learning approach requires just a few more hours to train, and achieves much better asymptotic performance, compared to training on human expert data.
METHODS
Reinforcement learning.
Policy iteration
- A simple approach to policy evaluation is to estimate the value function from the outcomes of sampled trajectories.
- A simple approach to policy improvement is to select actions greedily with respect to the value function.
Classification-based reinforcement learning
- Classification-based reinforcement learning improves the policy using a simple ++Monte Carlo search++.
Classification-based modified policy iteration (CBMPI)
- policy evaluation by regressing a value function towards truncated rollout values.
AlphaGo Zero self-play algorithm
- as an approximate policy iteration scheme in which MCTS is used for both policy improvement and policy evaluation.
Self-play reinforcement learning in games.
- NeuroGo
- RLGO
- MCTS may also be viewed as a form of self-play reinforcement learning.
AlphaGo versions.
- AlphaGo Fan
- AlphaGo Lee
- AlphaGo Master
- AlphaGo Zero
Domain knowledge.
- AlphaGo Zero is provided with perfect knowledge of the game rules.
- AlphaGo Zero uses Tromp–Taylor scoring66 during MCTS simulations and self-play training.
- The neural network architecture is matched to the grid-structure of the board.
- The rules of Go are invariant under rotation and reflection.
- AlphaGo Zero does not use any form of domain knowledge beyond the points listed above.
Self-play training pipeline.
Main components:
- Neural network parameters θi are continually optimized from recent self-play data;
- AlphaGo Zero players αθi are continually evaluated; and the best performing player so far,αθ∗, is used to generate new self-play data.
Optimization.
- Each neural network
$f_{\theta_i}$is optimized on the Google Cloud using TensorFlow, with 64 GPU workers and 19 CPU parameter servers. - Neural network parameters are optimized by stochastic gradient descent with momentum and learning rate annealing.
Evaluator.
The neural network $f_{\theta_i}$ is evaluated by the performance of an MCTS search $\alpha_{\theta_i}$ that uses $f_{\theta_i}$ to evaluate leaf positions and prior probabilities.
Self-play.
The best current player $\alpha_{\theta_*}$, as selected by the evaluator, is used to generate data.
Supervised learning.
- For comparison, we also trained neural network parameters
$\theta_{SL}$by supervised learning. - Parameters were optimized by stochastic gradient descent with momentum and learning rate annealing
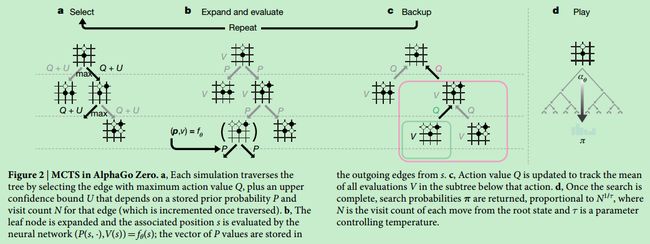
Search algorithm.
graph LR
Select -->Expand_and_evaluate
Expand_and_evaluate -->Backup
Backup -->Play
Each node s in the search tree contains edges $(s, a)$ for all legal actions a $s\in A(s)$. Each edge stores a set of statistics,
$ \{N(s,a),W(s,a),Q(s,a),P(s,a)\} $.where $N(s, a)$ is the visit count, $W(s, a)$ is the total action value, $ Q(s, a) $ is the mean action value and $ P(s, a) $ is the prior probability of selecting that edge.
Neural network architecture.
input features $s_t=[X_t,Y_t,X_{t-1},Y_{t-1},...,X_{t-7},Y_{t-7},C]$.
- Eight feature planes,
$X_t$, consist of binary values indicating the presence of the current player’s stones. - A further 8 feature planes,
$Y_t$, represent the corresponding features for the opponent’s stones. - The final feature plane,
$C$, represents the colour to play, and has a constant value of either 1 if black is to play or 0 if white is to play.
刘丽
2017-10-25