1、正则的两种写法:
1、 /正则/(表示法)
2、 new RegExp(正则)
RegExp实例对象有五个属性
global:是否全局搜索,默认是false
ignoreCase:是否大小写敏感,默认是false
multiline:多行搜索,默认值是false
lastIndex:是当前表达式模式首次匹配内容中最后一个字符的下一个位置,每次正则表达式成功匹配时,lastIndex属性值都会随之改变
source:正则表达式的文本字符串
\d 表示匹配数字
\s 匹配任何空白字符,包括空格、制表符、换页符等等。
\w 匹配字母数字下划线
\D 匹配非数字
大写转义字符是小写的规则反过来,就是取非的意思。
2、需要转义的字符
与其他语言中的正则表达式类似,模式中使用所有元字符必须转义。正则表达式中的元字符包括:
( [ { \ ^ $ | ? * + .}
example
//匹配第一个'cat'或者'bat',不区分大小写
var reg01 = /[bc]at/i;
//匹配第一个'[bc]at',不区分大小写
var reg02 = /\[bc\]at/i;
//匹配以所有以'at'结尾的三字符的组合,不区分大小写;
var reg03 = /.at/gi;
//匹配所有'.at',不区分大小写
var reg04 = /\.at/gi;
3、量词
+ 表示1次或者多次
* 表示0次或者多次
? 表示0次或者一次
{num} 匹配num次
{num1,num2}最少匹配num1次,最多num2次;
{,num2} 最少0次最多num2次;
exmaple
var str = 'm132i232a332o432';
// var re = /\d/g;
// var re = /\d?/g;
// var re = /\d*/g;
// var re = /\d+/g;
// var re = /\d{2}/g;
// var re = /\d{0,}/g;
// var re = /\d{0,1}/g;
console.log(str.match(re));
4、范围
用[]表示一个字符匹配的范围
^ 匹配字符的首位
$ 匹配字符串的末尾
| 或者
example
var str = 'm132I232a332o432';
//var re = /[0-9]+/g;
var re = /[a-zA-Z]+/g;
console.log(str.match(re));
5、相关方法
RegExp.prototype.test(str)
方法用于测试字符串参数中是否存正则表达式模式,如果存在则返回true,否则返回false
var reg = /\d+\.\d{1,2}$/g;
reg.test('123.45'); //true
reg.test('0.2'); //true
reg.test('a.34'); //false
reg.test('34.5678'); //false
RegExp.prototype.exec(str)
方法用于正则表达式模式在字符串中运行查找,如果exec()找到了匹配的文本,则返回一个结果数组,否则返回 null
除了数组元素和length属性之外,exec()方法返回对象还包括两个属性。
1.index 属性声明的是匹配文本的第一个字符的位置
2.input 属性则存放的是被检索的字符串string
非全局调用
调用非全局的RegExp对象的exec()时,返回数组的第一个元素是与正则表达式相匹配的文本,第二个元素是与 RegExpObject的第一个子表达式相匹配的文本(如果有的话),第三个元素是与RegExp对象的第二个子表达式相匹配的文本(如果有的话),以此类推。
全局调用
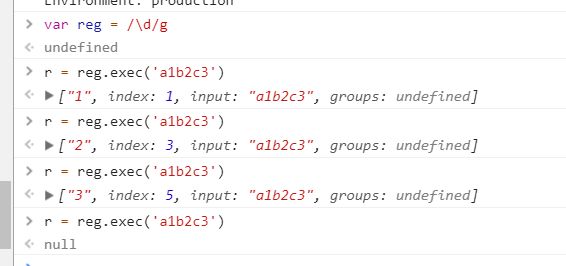
调用全局的RegExp对象的exec()时,它会在RegExp实例的lastIndex属性指定的字符处开始检索字符串string
1.当exec()找到了与表达式相匹配的文本时,在匹配后,它将把RegExp实例的lastIndex属性设置为匹配文本的最后一个字符的下一个位置。可以通过反复调用exec()方法来遍历字符串中的所有匹配文本
2.当 exec() 再也找不到匹配的文本时,它将返回null,并把lastIndex属性重置为0
var reg = /\d/g;
var r = reg.exec('a1b2c3');
console.log(reg.lastIndex); //2

除了上面的两个方法,有些字符串函数可以传入RegExp对象作为参数,进行一些复杂的操作
String.prototype.search(reg)
number string.search(string|regexp);
从string中查找参数所填的内容,如果找到就返回在string中的位置,否则返回-1。search方法和indexOf一样,唯一的区别,indexOf不支持正则。
search() 方法不执行全局匹配,它将忽略标志g,它同时忽略正则表达式对象的lastIndex属性,并且总是从字符串的开始进行检索,这意味着它总是返回字符串的第一个匹配的位置
'a1b2c3'.search(/\d/g); //1
'a1b2c3'.search(/\d/); //1
String.prototype.match(reg)
match()方法将检索字符串,以找到一个或多个与regexp匹配的文本。但regexp是否具有标志 g对结果影响很大。
非全局调用
如果regexp没有标志g,那么match()方法就只能在字符串中执行一次匹配。如果没有找到任何匹配的文本,match() 将返回null。否则它将返回一个数组,其中存放了与它找到的匹配文本有关的信息。
该数组的第一个元素存放的是匹配文本,而其余的元素存放的是与正则表达式的子表达式匹配的文本。除了这些常规的数组元素之外,返回的数组还含有两个对象属性
1.index 属性声明的是匹配文本的起始字符在字符串中的位置
2.input 属性声明的是对 stringObject 的引用
看个例子
var r = 'aaa123456'.match(/\d/);

全局调用
如果regexp具有标志g则match()方法将执行全局检索,找到字符串中的所有匹配子字符串
若没有找到任何匹配的子串,则返回 null。如果找到了一个或多个匹配子串,则返回一个数组
不过全局匹配返回的数组的内容与前者大不相同,它的数组元素中存放的是字符串中所有的匹配子串,而且也没有index属性或input属性。
var r = 'aaa123456'.match(/\d/g);

String.prototype.replace()
replace用法1 - 基础用法
最核心的易错点:如果要替换全部匹配项,需要传入一个 RegExp 对象并指定其 global 属性。
//基本用法:
var myString = "javascript is a good script language";
//在此我想将字母a替换成字母A
console.log(myString.replace("a","A"));
// 我想大家运行后可以看到结果,它只替换了找到的第一个字符,如果想替换多个字符怎么办?
// 答案:结合正则表达式,这也是replace的核心用法之一!
//将字母a替换成字母A 错误的写法 少了/g
myString = "javascript is a good script language";
console.log(myString.replace(/a/,"A"));
//console.log(myString.replace(new RegExp('a','gm'),"A"));
//将字母a替换成字母A 正确的写法 /g表示匹配所有
myString = "javascript is a good script language";
console.log(myString.replace(/a/g,"A"));
**replace用法2 - 高级用法 特殊标记:
1.$i (i:1-99) : 表示从左到右正则子表达式所匹配的文本。
2.$&:表示与正则表达式匹配的全文本。
3.$`(`:切换技能键):表示匹配字符串的左边文本。
4.$'(‘:单引号):表示匹配字符串的右边文本。
5.$$:表示$转移。
//案例1- 匹配后替换
console.log('replace功能1 - 匹配后替换')
//在本例中,我们将把所有的花引号替换为直引号:
myString = '"a", "b"';
myString = myString.replace(/"([^"]*)"/g, "'$1'");
//寻找所有的"abb"形式字符串,此时组合表示字符串,,然后用'$1'替换
console.log(myString)
//案例2- 匹配后替换
myString= "javascript is a good script language";
console.log(myString.replace(/(javascript)\s*(is)/g,"$1 $2 fun. it $2"));
//案例3 - 分组匹配后颠倒
console.log('replace功能2 - 颠倒')
//在本例中,我们将把 "itcast,cn" 转换为 "cn itcast" 的形式:
myString = "itcast , cn";
myString = myString.replace(/(\w+)\s*, \s*(\w+)/, "$2 $1");
console.log(myString)
//案例4 - 分组匹配后颠倒
myString = "boy & girl";
myString = myString.replace(/(\w+)\s*&\s*(\w+)/g,"$2 & $1") //girl & boy
console.log(myString)
//案例5 - $&:表示与正则表达式匹配的全文本。
myString = "boy";
myString = myString.replace(/\w+/g,"$&-$&") // boy-boy
console.log(myString)
// 案例6 - $`(`:切换技能键):表示匹配字符串的左边文本。
myString = "javascript";
myString = myString.replace(/script/,"$& != $`") //javascript != java
console.log(myString)
//案例7 - $'(‘:单引号):表示匹配字符串的右边文本。
myString = "javascript";
myString = myString.replace(/java/,"$&$' is ") // javascript is script
console.log(myString)
**replace用法3 - 高级用法 第二个参数可以是函数 **
//无敌的函数 - replace第二个参数可以传递函数
//如果第二参数是一个函数的话,那么函数的参数是什么呢?
console.log('replace - replace第二个参数可以传递函数')
myString = "bbabc";
myString.replace(/(a)(b)/g, function(){
console.log(arguments) // ["ab", "a", "b", 2, "bbabc"]
});
// 参数将依次为:
// 1、整个正则表达式匹配的字符。
// 2、第一分组匹配的内容、第二分组匹配的内容…… 以此类推直到最后一个分组。
// 3、此次匹配在源自符串中的下标(位置)。
// 4、源自符串
// 所以例子的输出是 ["ab", "a", "b", 2, "bbabc"]
//用法举例 1. 首字母大写 -- 一个参数 表示匹配的整个字符串
console.log('replace功能 - 将首字符转为大写')
//在本例中,我们将把字符串中所有单词的首字母都转换为大写:
var myString = 'aaa bbb ccc';
myString=myString.replace(/\b\w+\b/g, function(word){
return word.substring(0,1).toUpperCase()+word.substring(1);}
);
console.log(myString)
6、正向预查和负向预查
(?:pattern)
匹配 pattern 但不获取匹配结果,也就是说这是一个非获取匹配,不进行存储供以后使用。这在使用 "或" 字符 (|) 来组合一个模式的各个部分是很有用。例如, 'industr(?:y|ies) 就是一个比 'industry|industries' 更简略的表达式。
(?=pattern)
正向预查,在任 何匹配 pattern 的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。例如, 'Windows (?=95|98|NT|2000)' 能匹配 "Windows 2000" 中的 "Windows" ,但不能匹配 "Windows 3.1" 中的 "Windows"。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。
(?!pattern)
负向预查,在任 何不匹配Negative lookahead matches the search string at any point where a string not matching pattern 的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。例如'Windows (?!95|98|NT|2000)' 能匹配 "Windows 3.1" 中的 "Windows",但不能匹配 "Windows 2000" 中的 "Windows"。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。
例子 数字千分位加逗号
if (/\./.test(str)) {
return str.replace(/\d(?=(\d{3})+\.)/g, '$&,').replace(/\d{3}(?![,.]|$)/g, '$&,');
} else {
return str.replace(/\d(?=(\d{3})+$)/g, '$&,');
}