10月19日,deepmind在Nature杂志上发表了重磅文章《Mastering the Game of Go without Human Knowledge》,介绍了其在强化学习领域的新进展。读过了朋友圈相关报道之后,新算法的效果确实让人印象深刻,主要体现在:
- 更强的准确性,以100:0击败Alphago Lee(就是击败李世石的那一版算法)。
- 不需要人类棋谱,仅保留围棋的基本规则,即可在自我博弈中进步。
- 极高的训练效率,在4个TPU(赤裸裸的植入广告)上训练3天就可以击败Alphago Lee(后者在48个TPU上训练数月之久)。
大致阅读了Nature上的文章,对新算法有了一个大致的了解,下面是论文笔记。因为不懂围棋,所以讨论算法相关内容。
tips:为了区分版本,以下将击败樊麾的版本称为fan,击败李世石的版本称为lee,击败柯洁的版本称为master,这篇论文中算法称为zero。
一、与之前版本的不同
由于没有找到lee的详细资料,所以主要与上一篇论文《Mastering the Game of Go with Deep Neural Networks and Tree Search》中提到的alphago fan进行比较。
- 没有采用人类棋谱和也没有手工设计的特征,即未利用除了规则的先验知识(文末将讨论这个问题)。
- 将policy network和value network融合为一个网络一起训练。
- zero采用了受深度网络指导的启发式蒙特卡洛搜索树。
二、算法分析
1.启发式蒙特卡洛搜索树
alphago同样采用蒙特卡洛搜索树(MCTS)进行走子。与之前算法不同的是zero在evaluation采用了价值网络的输出来替代rollouts。
![[Paper Weekly]Mastering the Game of Go without Human Knowledge_第1张图片](http://img.e-com-net.com/image/info10/41e450a9ea4e469295e8aa2c9513fac9.jpg)
fan版本
在执行MCTS时,不断执行以下步骤的模拟:
-
选择(select)。在每次模拟时,从当前根结点开始往下走,总是选择“最感兴趣”的动作(action),其评价公式为:

其中:
![[Paper Weekly]Mastering the Game of Go without Human Knowledge_第2张图片](http://img.e-com-net.com/image/info10/8416158f4b98475cb77ef78cd9a892f0.jpg)
该系数的作用是鼓励探索未走过的节点,同时尽量去走SL网络判断可能性较大的节点。
- 扩展(expand)。当我们走到一个未拓展的节点时,我们根据SL策略网络的概率输出随机拓展一个子节点。
-
评价(evaluate)。对于新创建的子节点,需要评估该节点所代表的状态的价值。在fan版本的算法中,采用混合机制对状态价值进行估计:

其中,第一部分是以节点状态为输入价值网络的输出,第二部分是从该节点状态开始使用快速走子策略(fast rollout policy)走出的胜负结果,若超过一定的步数,则计算分数。
-
回溯(backup)。
最后,根据拓展节点的价值估计,更新所有经过节点的动作价值Q(s,a):
![[Paper Weekly]Mastering the Game of Go without Human Knowledge_第3张图片](http://img.e-com-net.com/image/info10/1fb7b0f93e84443e9f4a805af9bea784.jpg)
(在实际应用中做了修改)
最后,在多次模拟后,选择从根结点状态出发,访问最多的action完成落子。在进行下一步时,当前搜索树被复用,下一个状态成为根结点。
zero版本
zero也通过MCTS进行落子,与fan版本的不同主要体现在evaluate步骤上,具体模拟步骤如下:
- 选择(select)。见fan版本。
- 扩展(expand)。基本与fan版本一致,只不过zero版本使用的是融合网络的策略输出随机拓展子节点。
- 评价(evaluate)。与fan版本不同,zero版本只使用融合网络的价值输出作为拓展节点的价值估计。所以zero版本中不需要rollouts,也不需要训练依赖人类棋谱的fast rollout policy。
- 回溯(backup)。在完成价值估计后,对动作价值函数进行更新:
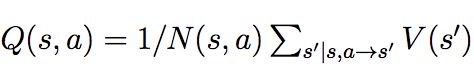
在多次模拟后,选择从根结点状态出发,访问最多的action完成落子。
2.策略网络与价值网络的结合
在网络结构上,master与zero有着相同的网络结构,它们与fan、lee相比主要由两个区别:
- 将价值网络和策略网络合并为一个网络。
- 网络结构采用residual network结构,而不是一般的convolutional结构。
![[Paper Weekly]Mastering the Game of Go without Human Knowledge_第4张图片](http://img.e-com-net.com/image/info10/bf2cabd9f094427f88cb7be7b9013dd7.jpg)
fan版本
fan版本算法机构中有两种网络:策略网络和价值网络。
策略网络使用人类棋谱KGS数据集训练的SL网络进行初始化,使用自我博弈数据进行训练。价值网络主要通过特定策略下的自我博弈数据进行训练。
网络的输入都为多通道[19,19]矩阵,每个通道代表的feature如下:
![[Paper Weekly]Mastering the Game of Go without Human Knowledge_第5张图片](http://img.e-com-net.com/image/info10/087a7911677d4fc7a8845cec1f37d6f4.jpg)
zero版本
zero版本策略网络和价值网络相结合,仅使用自我博弈的数据进行训练,网络采用res结构。
输入是shape为[19,19,17]的矩阵,其中8通道矩阵表示现在时刻及从此时开始的前7个时刻当前玩家的棋子位置,8通道矩阵表示现在时刻及从此时开始的前7个时刻当前对手的棋子位置,最后一个常数通道表示现在走棋的颜色(黑色为1,白色为0)。
三、训练过程
zero在训练上也与fan有着不同。在训练过程中,zero包含着三个过程:
- 神经网络的优化,就是一个有监督网络的训练。
- 从不同时间点产生的网络中选择最优网络(best player)。
- 使用最优的网络走子产生self-play数据用于训练。
![[Paper Weekly]Mastering the Game of Go without Human Knowledge_第6张图片](http://img.e-com-net.com/image/info10/b76760762ff045dcacca587a1e2c4b07.jpg)
四、一些记录
- 论文中提到之前在线上以60连胜的战绩击败人类职业选手的alphago master与zero有着相同的算法结构,不同的是master利用了人类棋谱以及手工设计的特征作为输入。在与zero的100场对弈中,zero以89比11战胜了master。
- 论文中讨论了不通过MCTS,只通过策略网络进行走子(选用最大p值的走子方法),相当于人类不思考推理,纯粹靠直觉进行走子的方式。采用这样的策略算法性能会有所下降,大概下降到能击败欧洲冠军的地步(fan版本的性能)。
五、问题
疑问:为什么没有使用人类棋谱反而算法性能提升了?
个人理解:先说结论,用没用人类棋谱其实并没有太大影响,不使用人类棋谱最大的作用是让论文的题目更炫酷。首先看一下不同版本下alphago的算法表现。
![[Paper Weekly]Mastering the Game of Go without Human Knowledge_第7张图片](http://img.e-com-net.com/image/info10/0b80a1d3aa2e4d69a43cf1c2f82c2783.jpg)
在这里zero与master采用了相同的算法结构,区别主要在于master采用了人类棋谱对网络进行预训练并采用了部分手工设计特征,zero未使用人类棋谱对于网路预训练并只采用黑白子位置作为输入。从上面的图中可以看到,其实两者的性能差距并不大(在围棋中极小的准确度提升就会带来压倒性的胜率优势)。而zero相对于lee版本的性能提升主要是由于算法机构的优化(网络融合、res机构替代conv结构等)。
这里说到了人类数据对算法的影响,我认为从lee版本开始,人类棋谱对算法的性能的提升就有限了。但是在fan版本中,人类棋谱还是对算法性能影响比较大,
疑问:为什么将策略网络和价值网络融合提升了算法性能?
个人理解:首先来看看论文中的比较。
![[Paper Weekly]Mastering the Game of Go without Human Knowledge_第8张图片](http://img.e-com-net.com/image/info10/f21104af9cfb43069e1b388fbc2255d2.jpg)
论文中提到了将策略网络与价值网络融合后,略微降低了策略网络的准确性,提高了价值网络的准确性,最终提升了算法在对弈时的表现。带来这种提升的主要原因是双重相关任务训练使上层特征得到了多次训练,即在训练策略网络时上层特征参与了一次训练,在价值策略网络时上层特征参与了一次训练,从而得到了“更好”的上层特征的表达。
疑问:增强学习在没有人类知识的情况下就这么强,人工智能会不会毁灭人类呢?
个人理解:至少目前来看,还需要很长的时间。围棋是一个可观测到“完全信息”的游戏,它符合马尔可夫过程,目前的强化学习的基础大都建立在马尔可夫过程之上。而现实生活中的任务许多不符合马尔可夫过程,所以算法并没有在围棋中展现的令人惊叹的性能。
还有一个问题就是,目前强化学习的依赖多次模拟(或者在真实条件下实验),但是现实中的任务(譬如驾驶),没有办法完美的模拟也没有办法多次实验(不能让一辆自动驾驶汽车上二环多撞几次来采集数据),所以很难像围棋这样构建端到端的解决方案。所以,目前增强学习的应用场景还极其有限,监督学习依然是主流。