# 1.读取小说内容
with open('./novel/threekingdom.txt', 'r', encoding='utf-8') as f:
words = f.read()
counts = {} # {‘曹操’:234,‘回寨’:56}
excludes = {"将军", "却说", "丞相", "二人", "不可", "荆州", "不能", "如此", "商议",
"如何", "主公", "军士", "军马", "左右", "次日", "引兵", "大喜", "天下",
"东吴", "于是", "今日", "不敢", "魏兵", "陛下", "都督", "人马", "不知",
"孔明曰","玄德曰","刘备","云长"}
# 2. 分词
words_list = jieba.lcut(words)
# print(words_list)
for word in words_list:
if len(word) <= 1:
continue
else:
# 更新字典中的值
# counts[word] = 取出字典中原来键对应的值 + 1
# counts[word] = counts[word] + 1 # counts[word]如果没有就要报错
# 字典。get(k) 如果字典中没有这个键 返回 NONE
counts[word] = counts.get(word, 0) + 1
print(len(counts))
# 3. 词语过滤,删除无关词,重复词
counts['孔明'] = counts['孔明'] + counts['孔明曰']
counts['玄德'] = counts['玄德'] + counts['玄德曰'] +counts['刘备']
counts['关公'] = counts['关公'] +counts['云长']
for word in excludes:
del counts[word]
# 4.排序 [(), ()]
items = list(counts.items())
print(items)
def sort_by_count(x):
return x[1]
items.sort(key=sort_by_count, reverse=True)
li = [] # ['孔明', 孔明, 孔明,孔明...., '曹操'。。。。。]
for i in range(10):
# 序列解包
role, count = items[i]
print(role, count)
# _ 循环里面不需要使用临时变量
for _ in range(count):
li.append(role)
#5.lambda x1,x2....xn:表达式
sum_num=lambda x1,x2:x1+x2
print(sum_num(2,3))
#参数可以是无限多个,但是表达式只有一个
name_info_list=[
('张三',4500),
('李四',9900),
('王五',2000),
('赵六',5500),
]
#6.Matplotlib显示中文
plt.rcParams["font.sans-serif"] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
#7. matplotlib可视化图形
7.1曲线图
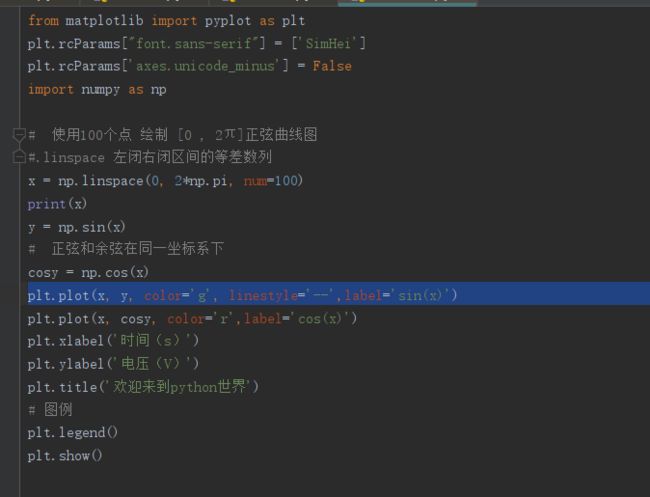
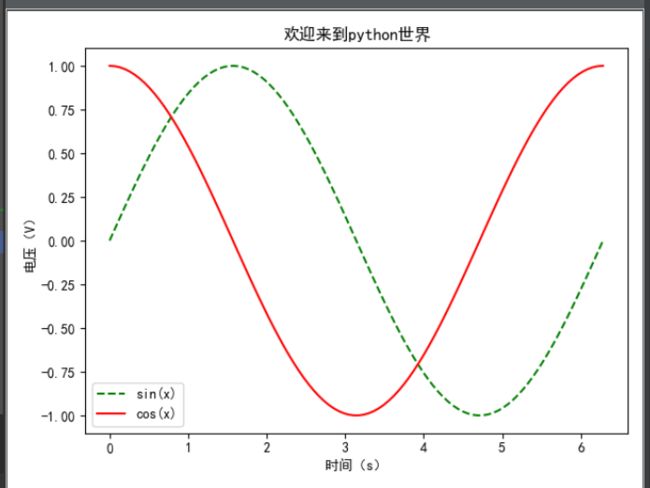
曲线图
7.2饼状图

7.3柱状图


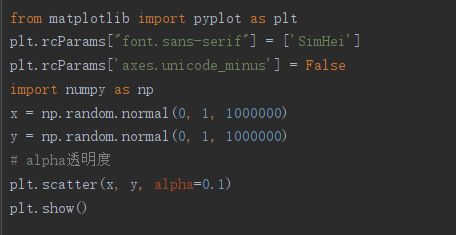
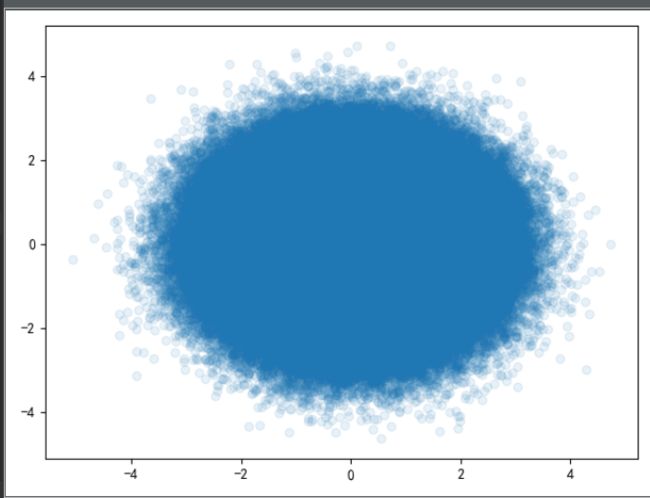
7.4散点图