博客版本: 0.1 Initial Release.
Prerequisites(Very Important!!!):
- 熟悉SQLAlchemy常用用法, 一个很好的教程来自于SQLAlchmey作者Mike Bayer在PyCon13的Tutorial.
- 熟悉Flask官方文档的关于如何写一个SQLite3的Flask Extension的示例.
- 熟悉Python的一些高级特性:描述符,metaclass.
- init和new的区别.
- 对数据库有一定了解,推荐Stanford CS145的数据库入门课程.
Goals:
- 学习Flask的插件是怎么工作的.
- 增加对SQLAlchemy的认识.
- 学习Flask中teardown_appcontext的用法.
Table of Contents
Part1 定义一张表
Part2 创建一张表
Part3 查询一张表
Part4 miscellanies
Part1 定义一张表
天才第一步,让我们先从定义一个表开始吧.
在SQLAlchemy中,以ORM方式定义表有两种方法,分别是Classical vs. Declarative.
Flask-SQLAlchemy主要使用的是Declarative方法.
首先, 我们回顾一下在原生SQLAlchemy中是如何进行Declarative定义的。
# 1.py
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
from sqlalchemy import Column, Integer, String
class User(Base):
__tablename__ = 'user'
id = Column(Integer, primary_key=True)
username = Column(String(50))
email = Column(String(30))
def __repr__(self):
return "" % self.username
Declarative方法本质上就是自动完成了Classical方法所做的事情.所谓Declarative方式的意思就是说什么就有什么的方式,
比如,要有光,就有光,定义完一个User类,要有Table表,于是也就在Metadata中有了Table表.
当User定义完成时,User class现在就有了一个Table object.可以通过User.table或者
User.metadata.tables['user']来访问.The Declarative extension uses a Python metaclass, which is a handy way to run a series of operations each time a new class is first declared, to generate a new Table object from what's been declared, and pass it to the mapper funcion along with the class.
在Flask-SQLAlchemy中,Model是对SQLAlchemy的Base的包装,
在Flask-SQLAlchemy中,我们将Base改为db.Model.
# 2.py
class User(db.Model):
id = db.Column(db.Integer, primary_key=True)
username = db.Column(db.String(80), unique=True)
email = db.Column(db.String(120), unique=True)
def __init__(self, username, email):
self.username = username
self.email = email
def __repr__(self):
return '' % self.username
下面我们来看看db.Model:
# 3.py
self.Model = self.make_declarative_base(metadata)
...
def make_declarative_base(self, metadata=None):
"""Creates the declarative base."""
base = declarative_base(cls=Model, name='Model',
metadata=metadata,
metaclass=_BoundDeclarativeMeta)
base.query = _QueryProperty(self)
return base
在SQLAlchemy的官方文档中查询declarative_base的API.
# SQLAlchemy declarative_base() API.
def declarative_base(bind=None, metadata=None, mapper=None, cls=object,
name='Base', constructor=_declarative_constructor,
class_registry=None,
metaclass=DeclarativeMeta):
可知各个参数的意义:
*1. bind - An optional Connectable, will be assigned the bind attribute on the MetaData instance.
这里的Connectable这个接口的实现有:Engine和Connection.
*2. metadata - All Table objects implicitly declared by subclasses of the base will share this
MetaData.
*3. mapper - Will be used to map subclasses to their Tables.
*4. cls - A type to use as the base for the generated declarative base class.
*5. name - The display name for the generated class.
*6. constructor - ?????
*7. class_registry - ?????
*8. metaclass - A metaclass or metaclass compatible callable to use as the meta type of the
meta type of the generated declarative base class.
首先metaclass(创造class的class)默认设置为DeclarativeMeta,这是最重要的设置,
DeclarativeMeta具体我们不会去剖析,但是根据metaclass的用途,我们可以大胆猜测,
定义类User时,在metaclass创造User这个class时,会做很多背后的设置工作,具体做些什么呢:
The Declarative extension uses a Python metaclass, which is a
handy way to run a series of operations each time a new class is first declared, to generate a
new Table object from what's been declared, and pass it to the mapper funcion along with the
class.
在3.py中,我们设置declarative_base的参数有:
- cls = Model
- metadata = metadata(None)
- metaclass = _BoundDeclarativeMeta
_BoundDeclarativeMeta是对DeclarativeMeta的一个简单包装:
# 4.py
class _BoundDeclarativeMeta(DeclarativeMeta):
def __new__(cls, name, bases, d):
if _should_set_tablename(bases, d):
def _join(match):
word = match.group()
if len(word) > 1:
return ('_%s_%s' % (word[:-1], word[-1])).lower()
return '_' + word.lower()
d['__tablename__'] = _camelcase_re.sub(_join, name).lstrip('_')
return DeclarativeMeta.__new__(cls, name, bases, d)
def __init__(self, name, bases, d):
bind_key = d.pop('__bind_key__', None)
DeclarativeMeta.__init__(self, name, bases, d)
if bind_key is not None:
self.__table__.info['bind_key'] = bind_key
_BoundDeclarativeMeta实现的功能就是自动添加tablename属性的设置, 在SQLAlchemy中,
比如在1.py中,tablename的设置是必须的,但是在2.py这项并不是必须,原因就是Flask-SQLAlchemy
在背后帮你自动设置好了.
首先我们思考一个问题在2.py中,在定义(创造?)User这个class过程中,
传入new中的参数会是哪些呢?设置打印语句可知:
cls --->
name ---> User
bases ---> (
d ---> {'module': ..., 'init': ..., 'id':..., 'qualname': ...,
'username': ..., 'email': ..., 'repr':...}
下面我们看 _should_set_tablename干了啥:
def _should_set_tablename(bases, d):
# 如果d中,也就是User.__dict__中含有这些属性,则不用自动设置.
if '__tablename__' in d or '__table__' in d or '__abstract__' in d:
return False
# 检查User中的Column属性,如果任何一个Column属性为primary_key,则返回True.
if any(v.primary_key for v in itervalues(d) if isinstance(v, sqlalchemy.Column)):
return True
# Joined table inheritance without explicitly naming sub-models.?????
for base in bases:
if hasattr(base, '__tablename__') or hasattr(base, '__table__'):
return False
for name in dir(base):
attr = getattr(base, name)
if isinstance(attr, sqlalchemy.Column) and attr.primary_key:
return True
如果 _should_set_tablename返回True,我们就会设置d['tablename'],设置的具体格式就忽略.
设置完后,我们再调用SQLAlchemy Base默认的metaclass的new方法.
_BoundDeclarativeMeta在init中还对bind_key进行了设置,这个
跟 MULTIPLE DATABASES WITH BINDS有关,本小节先忽略.
Part2 - 创建一张表
在SQLAlchemy中,我们可以这样创建一个数据库:
from sqlalchemy import create_engine
engine = create_engine('sqlite:///SALTRIVER.db', echo=True)
Base.metadata.create_all(engine)
于是,在电脑硬盘上就生成了一个SALTRIVER.db的数据库文件.
那么在Flask-SQLAlchemy中是如何对其进行包装的呢?
下面我们看看当定义完User后,执行db.create_all()会发生什么.
以下几段代码重点在于我们是怎么获取engine的,也就是怎么与一个engine进行绑定(bind).
在分析以下几段代码的时候,请先熟读Flask-SQLAlchemy官方文档中的第六章.
为熟悉用法,示例代码可参考test_sqlalchemy.py中的BindsTestCase
将结合示例代码对源码进行说明
关于多引擎绑定,还有一种django-style.详见Mike Bayer的博客.
在此之前,我们应该知道在init_app中我们设置了SQLALCHEMY_DATABASE_URI和
SQLALCHEMY_BINDS两项参数.
# bind参数默认为'__all__'
def create_all(self, bind='__all__', app=None):
self._execute_for_all_tables(app, bind, 'create_all')
调用db.create_all,db.drop_all,db.reflect都会调用 _execute_for_all_tables().
def _execute_for_all_tables(self, app, bind, operation, skip_tables=False):
# 首先获取app.
app = self.get_app(app)
if bind == '__all__':
# '__all__'的意思就是把每个表创建到对应的引擎的中.
# 设置过__bind_key__属性的,创建到bind对应的引擎.
# 没设置过__bind_key__,就创建到默认的引擎中---'SQLALCHEMY_DATABASE_URI'.
# binds列表中的None就对应没bind过引擎的表.
# 对于示例代码就是:Foo -> foo, Bar -> bar, Baz -> default.
binds = [None] + list(app.config.get('SQLALCHEMY_BINDS') or ())
elif isinstance(bind, string_types) or bind is None:
# 如果明确指定, binds就设置为只含有bind的列表.
# 意思是只在该bind对应的engine中创建Tables.
binds = [bind]
else:
# 比如binds为一个自行指定的列表.
binds = bind
# 注意skip_tables=False
for bind in binds:
extra = {}
if not skip_tables:
# 获取一个bind相关的tables.
tables = self.get_tables_for_bind(bind)
extra['tables'] = tables
# 获得self.Model.metadata.create_all方法.
op = getattr(self.Model.metadata, operation)
# 执行self.Model.metadata.create_all(bind=engine)
# 原生的create_all可以带个可选参数tables, which is a
# subset of the total tables in the metadata.
# 只创建指定的Tables.
op(bind=self.get_engine(app, bind), **extra)
def get_tables_for_bind(self, bind=None):
"""Returns a list of all tables relevant for a bind."""
result = []
for table in itervalues(self.Model.metadata.tables):
# bind为None,代表对应的默认引擎.
if table.info.get('bind_key') == bind:
result.append(table)
return result
下面我们看看是如何获得get_engine的.
# SQLAlchemy.get_engine()
def get_engine(self, app, bind=None):
# 获得一把锁. 思考:为什么需要上锁?
with self._engine_lock:
# 获得_SQLAlchemyState实例.
# state = app.extensions['sqlalchemy'].
state = get_state(app)
# 初次获取engine的时候,connector为None.
connector = state.connectors.get(bind)
if connector is None:
# 创建一个_EngineConnector实例.
connector = self.make_connector(app, bind)
# 将_EngineConnector加入(缓存)到state.connectors中.
state.connectors[bind] = connector
# 再调用_EngineConnector的get_engine().
return connector.get_engine()
_EngineConnector主要作用是用来缓存engine的.
# _EngineConnector.get_engine()
def get_engine(self):
# 思考: 为什么要加琐?
with self._lock:
# uri = "sqlite:///XYZ.db"
uri = self.get_uri()
echo = self._app.config['SQLALCHEMY_ECHO']
# 最开始, _connected_for为None.
# _connected_for为engine唯一identity(见下方).
if (uri, echo) == self._connected_for:
# 第二次访问该engine时,返回之前缓存在
# _EngineConnector._engine中的engine.
return self._engine
info = make_url(uri)
options = {'convert_unicode': True}
# 设置SQLALCHEMY相关的参数, 包括:
# 1, SQLALCHEMY_POOL_SIZE
# 2, SQLALCHEMY_POOL_RECYCLE
# 3, SQLALCHEMY_POOL_TIMEOUT
# 4, SQLALCHEMY_MAX_OVERFLOW
self._sa.apply_pool_defaults(self._app, options)
# What the fuck of this????????????????????????????
self._sa.apply_driver_hacks(self._app, info, options)
if echo:
options['echo'] = True
# 终于, 创建了一个engine.
self._engine = rv = sqlalchemy.create_engine(info, **options)
# - - - - - - - - - - - - - - - - - - - - - - - - -
# 暂时忽略.
if _record_queries(self._app):
_EngineDebuggingSignalEvents(self._engine,
self._app.import_name).register()
# - - - - - - - - - - - - - - - - - - - - - - - - -
# 设置self._connected_for.
# _connected_for相当于engine的一个唯一identity.
# 通过比较(uri, echo) == self._connected_for是否相等来
# 判断某个engine是非缓存在_EngineConnector中.
self._connected_for = (uri, echo)
# 返回engine.
return rv
返回engine后,最后调用self.Model.metadata.create_all(bind=engine, **extra).
成功创建数据库文件.
一个助于理解的示意图为:
[PICTURE HERE]
感觉有循环引用问题?
Part3 查询一张表
Part3.1 scoped_session
以SQLAlchemy的ORM方式,我们通常是这样开始查询的:
from sqlalchemy.orm import Session
session = Session(engine)
query = session.query(User)
在Flask-SQLAlchemy中,我们是如何对其进行包装改造的呢?
在SQLAlchemy中的init函数中设置了scopefunc.
这个scopefunc与Thread Local Data有关,用来识别Thread Local Data.
...
if session_options is None:
session_options = {}
session_options.setdefault('scopefunc', connection_stack.__ident_func__)
...
self.session = self.create_scoped_session(session_options)
...
def create_scoped_session(self, options=None):
if options is None:
options = {}
scopefunc = options.pop('scopefunc', None)
return orm.scoped_session(partial(self.create_session, options),
scopedfunc=scopefunc)
Very Important!!!
继续之前请仔细阅读SQLAlchemy Documentation Release 1.1.0b1中
2.5.6 Contextual/Thread-local Sessions小节(p233-p238),
一定要仔细阅读.在此我就不翻译了.
下面看看self.create_session: SignallingSession继承Session,对get_bind方法进行了重写.
SignallingSession是Flask-SQLAlchemy默认的session.如果想使用一个不一样的session.
可对self.create_session进行重写.
def create_session(self, options):
return SignallingSession(self, **options)
# SignallingSession.__init__().
def __init__(self, db, autocommit=False, autoflush=True, app=None, **options):
self.app = app = db.get_app()
# 暂时忽略.见event小节.
track_modifications = app.config['SQLALCHEMY_TRACK_MODIFICATIONS']
# 获得bind参数.
# 单独的一个session需要与一个engine或者connection绑定,
# 所以SQL操作通过这个Connectable完成.
# 如果没有明确指定bind参数,bind设置为db.engine.
# db.engine为默认的engine(SQLALCHEMY_DATABASE_URI).
bind = options.pop('bind', None) or db.engine
# 获得binds参数, 注意bind与binds的区别.
# db.get_binds() Returns a dictionary with a table->engine mapping.
# binds中的映射还可以是: somemapper --> engine. SomeMappedClass --> engine.
# 对于示例代码而言,类似于:
# { Table_baz: Engine(sqlite://),
# Table_bar: Engine(sqlite:///XXX),
# Table_foo: Engine(sqlite:///YYY)
# }
binds = options.pop('binds', None) or db.get_binds(app)
# 暂时忽略.见event小节.
if track_modifications is None or track_modifications:
_SessionSignalEvents.register(self)
# 调用原生session的__init__<官方文档p246>.
SessionBase.__init__(
self, autocommit=autocommit, autoflush=autoflush,
bind=bind, binds=binds, **options
)
说说SessionBase.init中的参数,注意比较bind和binds的区别.
bind: An optional Engine or Connectable to which this Session should bound.
When specified, all SQL operations performed by this session will execute
via this Connectable.
binds: binds与multiply-bound有关.假如像这样传入binds:
Session = sessionmaker(binds={
SomeMappedClass: create_engine('postgresql://engine1'),
somemapper: create_engine('postgresql://engine2'),
# Flask-SQLAlchemy主要使用这种类型的映射.
some_table: create_engine('postgresql://engine3'),
})
那么,session最后是如何决定是跟哪个engine进行链接的呢?
下面来看看重写的get_bind()方法,因为get_bind()会决定到底用binds中的哪一个bind参数:
|
|
V
```
def get_bind(self, mapper=None, clause=None):
# 关于mapper, clause会传入什么.见'EXTRA MATERIAL'
if mapper is not None:
# 比如session.query(User).all()中, 是怎么获取bind的呢?
# 知道User class, 便知道了User class的mapper, User.__mapper__,
# 知道了mapper, 便知道了mapper.mapped_table.
# 在Runtime时, 传入mapper的参数就是User.__mapper__.
# 在_BoundDeclarativeMeta.__init__函数中设置了
# mapped_table的info属性.
info = getattr(mapper.mapped_table, 'info', {})
# 获取bind_key参数.
bind_key = info.get('bind_key')
if bind_key is not None:
state = get_state(self.app)
return state.db.get_engine(self.app, bind=bind_key)
# 如果bind_key为None,也就是表没有与任何engine绑定,调用原生的get_bind().
# 原生是怎么决定engine的呢?这需要看sqlalchemy的源码了.但是这里我们可以
# 猜想一下大概会是这样决定engine的: Baz->mapper->mapped_table
# ->metadata->binded_engine. 因为在最初创建Baz这张表的时候,会与Baz
# 这张表所在的metadata在调用metadata.create_all(bind=engine)中的engine
# 进行绑定.到底是不是这样呢?有兴趣可以查看sqlalchemy中的源码.
return SessionBase.get_bind(self, mapper, clause)
```
此处应该有一个示意图.
==========================EXTRA MATERIAL=============================
在仔细剖析重写的get_bind()函数之前,先来看看文档是怎么说原生的get_bind()函数的:
```
get_bind(mapper=None, clause=None)
----------------------------------
For a multiply-bound or unbound Session, the mapper or clause arguments are
used to determine the appropriate bind to return.
Note that the "mapper" argument is usually present when Session.get_bind() is
called via an ORM operation such as a Session.query(), each individual
INSERT/UPDATE/DELETE operation within a Session.flush(), call, etc.
The order of resolution is:
...
Parameters:
* mapper - Optional mapper() mapped class or instance of Mapper. The bind
can be derived from a Mapper first by consulting the "binds" map associated
with this Session, and secondly by consultiong the MetaData associated with
the Table to which the Mapper is mapped for a bind.
* clause - A ClauseElement (i.e. select(), text(), etc.). If the mapper argument
is not present or could not produce a bind, the given expression construct will
be searched for a bound element, typically a Table associated with bound MetaData.
```
下面我们来看一些示例代码来看看get_bind函数中传入的参数到底是什么.
示例代码选自Mike Bayer的博客, 完整代码见博客.
调用add_all或者add的时候,以s.add(Model1(data='river'))为例, 此时传入的参数为:
Mapper为将Model1映射为model1的Mapper, Clause为None.
with s.begin(): # 11. Writes go to "leader".... s.add_all([ Model1(data='m1_a'), Model2(data='m2_a'), Model1(data='m1_b'), Model2(data='m2_b'), Model3(data='m3_a'), Model3(data='m3_b'), ])
Mapper为将Model1映射为model1的Mapper,Clause为:
s.query(Model1).all()
Mapper和Clause都为None.
```
# - - - - - - Added by myself - - - - - - -
from sqlalchemy import select
model1 = Model1.__mapper__.tables[0]
sel = select([model1.c.data])
d = s.connection().execute(sel).fetchall()
# - - - - - - - - - - - - - - - - - - - - -
```
===================================================================
- - - - - - - - - - - - - - - - - - - - - - - -
db.session.add(user1)
db.session.commit()
当一个请求结束后,如何处理session呢?
...
# 0.9 and later
if hasattr(app, 'teardown_appcontext'):
teardown = app.teardown_appcontext
...
@teardown
def shutdown_session(response_or_exc):
if app.config['SQLALCHEMY_COMMIT_ON_TEARDOWN']:
if response_or_exc is None:
self.session.commit()
self.session.remove()
return response_or_exc
在SQLAlchemy.init_app()中,我们为app设置teardown_appcontext回调函数.
在Flask中,每当一个request结束后,都会执行注册过@teardown_appcontext的函数,
可以看到在shutdown_session函数中,会调用self.session.remove(),将session管理的资源,
比如connection,返回到connection pool.
Part3.2 - Custom Query Object.
在Flask-SQLAlchemy中,我们还可以这样查询:
User.query.first()
或者通常可以这样:
db.session.query(User).first()
第二种很熟悉了, 我们看看第一种是怎么实现的.
class Model(object):
query_class = BaseQuery
query = None
|
V
def make_declarative_base(self, metadata=None):
# 所有继承db.Model(也就是base)的类(如User)的基类都将被设置为cls参数,也就是Model.
# 那么, User也就有了query_class和query属性.
base = declarative_base(cls=Model, # <---
name='Model',
metadata=metadata,
metaclass=_BoundDeclarativeMeta)
base.query = _QueryProperty(self)
return base
|
V
class _QueryProperty(object):
def __init__(self, sa):
self.sa = sa
def __get__(self, obj, type):
try:
mapper = orm.class_mapper(type)
if mapper:
return type.query_class(mapper, session=self.sa.session())
except UnmappedClassError:
return None
_QueryProperty是个Non-Data描述符.当我们调用User.query.first()时,
会触发db.Model.query描述符的get方法执行,传入的参数obj=None, type=
然后获取User.mapper, orm.class_mapper(type)等同于type.mapper.
最后返回type.query_class(), 也就是type.BaseQuery(),即User.BaseQuery().
BaseQuery继承自orm.Query.
# Query Object API
class sqlalchemy.orm.query.Query(entities, session=None)
Query的init函数接受2个参数entities和session.实际上:
# 用法1
session.query(User).all()
# 用法2
Query(User, session).all()
用法1和用法2是一样的.
于是,type.query_class(mapper, session=self.sa.session())会返回一个与
某个mapper和session一起绑定了的Query Object.
实际上, User.query.all() 转化为了 session.query(User).all().
Part 4 Miscellanies
1,BaseQuery中的paginate方法.
paginate主要用来实现分页功能.一个简单的示例可参考flask web development的11章.
我们一起看看是如何实现分页功能的.
def paginate(self, page=None, per_page=None, error_out=True):
...
items = self.limit(per_page).offset((page - 1) * per_page).all()
...
else:
total = self.order_by(None).count()
return Pagination(self, page, per_page, total, items)
paginate的参数page代表第几页. 这个参数是用浏览器中的url中的参数传递的.per_page代表没页有多少个items. paginate主要干了俩件事,第一,获取该页的items.
items = self.limit(per_page).offset((page - 1) * per_page).all()
第二,获取total参数.(万一total参数为百万级别呢?比如google的搜索结果?)
然后返回一个Pagination对象.我们结合示例中的模版来看看Pagination对象:
{% macro pagination_widget(pagination, endpoint) %}
{% endmacro %}
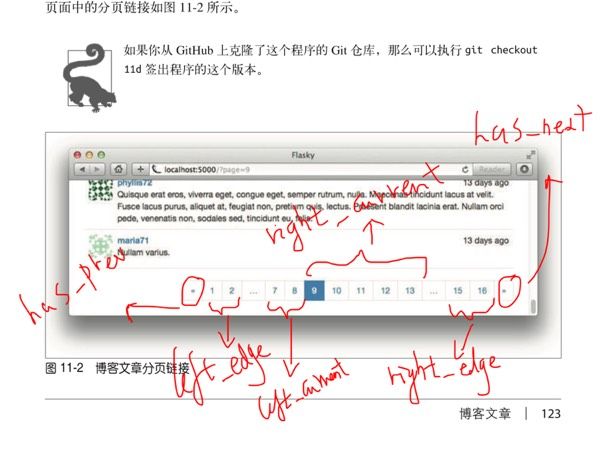
一图胜千言.
References and Useful Resources:
- Python Official Documentation: Descriptor HowTo Guide
- Armin Ronacher's slides: Why SQLAlchemy is Awesome
- SQLAlchemy Official Documentation
- [Flask-SQLAlchemy Official Documentation]
- PyCon Session in Depth
- Mike Bayer的博客