Spring Cloud为开发人员提供了快速构建分布式系统中一些常见模式的工具(例如配置管理,服务发现,断路器,智能路由,微代理,控制总线)。分布式系统的协调导致了样板模式, 使用Spring Cloud开发人员可以快速地支持实现这些模式的服务和应用程序。他们将在任何分布式环境中运行良好,包括开发人员自己的笔记本电脑,裸机数据中心,以及Cloud Foundry等托管平台。
版本:Dalston.RELEASE
特性
Spring Cloud专注于提供良好的开箱即用经验的典型用例和可扩展性机制覆盖。
分布式/版本化配置
服务注册和发现
路由
service - to - service调用
负载均衡
断路器
分布式消息传递
云原生应用程序
云原生是一种应用开发风格,鼓励在持续交付和价值驱动开发领域轻松采用最佳实践。相关的学科是建立12-factor Apps,其中开发实践与交付和运营目标相一致,例如通过使用声明式编程和管理和监控。Spring Cloud以多种具体方式促进这些开发风格,起点是一组功能,分布式系统中的所有组件都需要或需要时轻松访问。
许多这些功能都由Spring Boot覆盖,我们在Spring Cloud中建立。更多的由Spring Cloud提供为两个库:Spring Cloud Context和Spring Cloud Commons。Spring Cloud上下文为Spring Cloud应用程序(引导上下文,加密,刷新范围和环境端点)的ApplicationContext提供实用程序和特殊服务。Spring Cloud Commons是一组在不同的Spring Cloud实现中使用的抽象和常用类(例如Spring Cloud Netflix vs. Spring Cloud Consul)。
如果由于“非法密钥大小”而导致异常,并且您正在使用Sun的JDK,则需要安装Java加密扩展(JCE)无限强度管理策略文件。有关详细信息,请参阅以下链接:
Java 6 JCE
Java 7 JCE
Java 8 JCE
将文件解压缩到JDK / jre / lib / security文件夹(无论您使用的是哪个版本的JRE / JDK x64 / x86)。
注意
Spring Cloud根据非限制性Apache 2.0许可证发布。如果您想为文档的这一部分做出贡献,或者发现错误,请在github中找到项目中的源代码和问题跟踪器。
Spring Cloud上下文:应用程序上下文服务
Spring Boot对于如何使用Spring构建应用程序有一个看法:例如它具有常规配置文件的常规位置,以及用于常见管理和监视任务的端点。Spring Cloud建立在此之上,并添加了一些可能系统中所有组件将使用或偶尔需要的功能。
引导应用程序上下文
一个Spring Cloud应用程序通过创建一个“引导”上下文来进行操作,这个上下文是主应用程序的父上下文。开箱即用,负责从外部源加载配置属性,还解密本地外部配置文件中的属性。这两个上下文共享一个Environment,这是任何Spring应用程序的外部属性的来源。Bootstrap属性的优先级高,因此默认情况下不能被本地配置覆盖。
引导上下文使用与主应用程序上下文不同的外部配置约定,因此使用bootstrap.ymlapplication.yml(或.properties)代替引导和主上下文的外部配置。例:
bootstrap.yml
spring:
application:
name: foo
cloud:
config:
uri: ${SPRING_CONFIG_URI:http://localhost:8888}
如果您的应用程序需要服务器上的特定于应用程序的配置,那么设置spring.application.name(在bootstrap.yml或application.yml)中是个好主意。
您可以通过设置spring.cloud.bootstrap.enabled=false(例如在系统属性中)来完全禁用引导过程。
应用程序上下文层次结构
如果您从SpringApplication或SpringApplicationBuilder构建应用程序上下文,则将Bootstrap上下文添加为该上下文的父级。这是一个Spring的功能,即子上下文从其父进程继承属性源和配置文件,因此与不使用Spring Cloud Config构建相同上下文相比,“主”应用程序上下文将包含其他属性源。额外的财产来源是:
“bootstrap”:如果在Bootstrap上下文中找到任何PropertySourceLocators,则可选CompositePropertySource显示为高优先级,并且具有非空属性。一个例子是来自Spring Cloud Config服务器的属性。有关如何自定义此属性源的内容的说明,请参阅下文。
“applicationConfig:[classpath:bootstrap.yml]”(如果Spring配置文件处于活动状态,则为朋友)。如果您有一个bootstrap.yml(或属性),那么这些属性用于配置引导上下文,然后在父进程设置时将它们添加到子上下文中。它们的优先级低于application.yml(或属性)以及作为创建Spring Boot应用程序的过程的正常部分添加到子级的任何其他属性源。有关如何自定义这些属性源的内容的说明,请参阅下文。
由于属性源的排序规则,“引导”条目优先,但请注意,这些条目不包含来自bootstrap.yml的任何数据,它具有非常低的优先级,但可用于设置默认值。
您可以通过简单地设置您创建的任何ApplicationContext的父上下文来扩展上下文层次结构,例如使用自己的界面,或使用SpringApplicationBuilder方便方法(parent(),child()和sibling())。引导环境将是您创建自己的最高级祖先的父级。层次结构中的每个上下文都将有自己的“引导”属性源(可能为空),以避免无意中将值从父级升级到其后代。层次结构中的每个上下文(原则上)也可以具有不同的spring.application.name,因此如果存在配置服务器,则不同的远程属性源。普通的Spring应用程序上下文行为规则适用于属性解析:子环境中的属性通过名称和属性源名称覆盖父项中的属性(如果子级具有与父级名称相同的属性源,一个来自父母的孩子不包括在孩子中)。
请注意,SpringApplicationBuilder允许您在整个层次结构中共享Environment,但这不是默认值。因此,兄弟情境尤其不需要具有相同的资料或财产来源,尽管它们与父母共享共同点。
改变引导位置Properties
可以使用spring.cloud.bootstrap.name(默认“引导”)或spring.cloud.bootstrap.location(默认为空)指定bootstrap.yml(或.properties)位置,例如在系统属性中。这些属性的行为类似于具有相同名称的spring.config.*变体,实际上它们用于通过在其Environment中设置这些属性来设置引导ApplicationContext。如果在正在构建的上下文中有活动的配置文件(来自spring.profiles.active或通过EnvironmentAPI)),则该配置文件中的属性也将被加载,就像常规的Spring Boot应用程序,例如来自bootstrap-development.properties的“开发”简介。
覆盖远程Properties的值
通过引导上下文添加到应用程序的属性源通常是“远程”(例如从配置服务器),并且默认情况下,不能在本地覆盖,除了在命令行上。如果要允许您的应用程序使用自己的系统属性或配置文件覆盖远程属性,则远程属性源必须通过设置spring.cloud.config.allowOverride=true(在本地设置本身不起作用)授予权限。一旦设置了该标志,就会有一些更精细的设置来控制远程属性与系统属性和应用程序本地配置的位置:spring.cloud.config.overrideNone=true覆盖任何本地属性源,spring.cloud.config.overrideSystemProperties=false如果只有系统属性和env var应该覆盖远程设置,而不是本地配置文件。
自定义引导配置
可以通过在org.springframework.cloud.bootstrap.BootstrapConfiguration键下添加条目/META-INF/spring.factories来训练引导上下文来执行任何您喜欢的操作。这是用于创建上下文的Spring@Configuration类的逗号分隔列表。您可以在此处创建要用于自动装配的主应用程序上下文的任何bean,并且还有ApplicationContextInitializer类型的@Beans的特殊合同。如果要控制启动顺序(默认顺序为“最后”),可以使用@Order标记类。
警告
添加自定义BootstrapConfiguration时,请注意,您添加的类不是错误的@ComponentScanned到您的“主”应用程序上下文中,可能不需要它们。对于您的@ComponentScan或@SpringBootApplication注释配置类尚未涵盖的启动配置类,请使用单独的包名称。
引导过程通过将初始化器注入主SpringApplication实例(即正常的Spring Boot启动顺序,无论是作为独立应用程序运行还是部署在应用程序服务器中)结束。首先,从spring.factories中找到的类创建引导上下文,然后在ApplicationContextInitializer类型的所有@Beans添加到主SpringApplication开始之前。
自定义引导属性源
引导过程添加的外部配置的默认属性源是Config Server,但您可以通过将PropertySourceLocator类型的bean添加到引导上下文(通过spring.factories)添加其他源。您可以使用此方法从其他服务器或数据库中插入其他属性。
作为一个例子,请考虑以下微不足道的自定义定位器:
@Configuration
public class CustomPropertySourceLocator implements PropertySourceLocator {
@Override
public PropertySource locate(Environment environment) {
return new MapPropertySource("customProperty",
Collections.singletonMap("property.from.sample.custom.source", "worked as intended"));
}
}
传入的Environment是要创建的ApplicationContext的Environment,即为我们提供额外的属性来源的。它将已经具有正常的Spring Boot提供的资源来源,因此您可以使用它们来定位特定于此Environment的属性源(例如通过将其绑定在spring.application.name上,如在默认情况下所做的那样Config Server属性源定位器)。
如果你在这个类中创建一个jar,然后添加一个META-INF/spring.factories包含:
org.springframework.cloud.bootstrap.BootstrapConfiguration=sample.custom.CustomPropertySourceLocator
那么“customProperty”PropertySource将显示在其类路径中包含该jar的任何应用程序中。
环境变化
应用程序将收听EnvironmentChangeEvent,并以几种标准方式进行更改(用户可以以常规方式添加ApplicationListeners附加ApplicationListeners)。当观察到EnvironmentChangeEvent时,它将有一个已更改的键值列表,应用程序将使用以下内容:
重新绑定上下文中的任何@ConfigurationPropertiesbean
为logging.level.*中的任何属性设置记录器级别
请注意,配置客户端不会通过默认轮询查找Environment中的更改,通常我们不建议检测更改的方法(尽管可以使用@Scheduled注释进行设置)。如果您有一个扩展的客户端应用程序,那么最好将EnvironmentChangeEvent广播到所有实例,而不是让它们轮询更改(例如使用Spring Cloud总线)。
EnvironmentChangeEvent涵盖了大量的刷新用例,只要您真的可以更改Environment并发布事件(这些API是公开的,部分内核为Spring)。您可以通过访问/configprops端点(普通Spring Boot执行器功能)来验证更改是否绑定到@ConfigurationPropertiesbean。例如,DataSource可以在运行时更改其maxPoolSize(由Spring Boot创建的默认DataSource是一个@ConfigurationPropertiesbean),并且动态增加容量。重新绑定@ConfigurationProperties不会覆盖另一大类用例,您需要更多的控制刷新,并且您需要更改在整个ApplicationContext上是原子的。为了解决这些担忧,我们有@RefreshScope。
刷新范围
当配置更改时,标有@RefreshScope的Spring@Bean将得到特殊处理。这解决了状态bean在初始化时只注入配置的问题。例如,如果通过Environment更改数据库URL时DataSource有开放连接,那么我们可能希望这些连接的持有人能够完成他们正在做的工作。然后下一次有人从游泳池借用一个连接,他得到一个新的URL。
刷新范围bean是在使用时初始化的懒惰代理(即当调用一个方法时),并且作用域作为初始值的缓存。要强制bean重新初始化下一个方法调用,您只需要使其缓存条目无效。
RefreshScope是上下文中的一个bean,它有一个公共方法refreshAll()来清除目标缓存中的范围内的所有bean。还有一个refresh(String)方法可以按名称刷新单个bean。此功能在/refresh端点(通过HTTP或JMX)中公开。
注意
@RefreshScope(技术上)在@Configuration类上工作,但可能会导致令人惊讶的行为:例如,这并不意味着该类中定义的所有@Beans本身都是@RefreshScope。具体来说,任何取决于这些bean的东西都不能依赖它们在刷新启动时被更新,除非它本身在@RefreshScope(在其中将重新刷新并重新注入其依赖关系),那么它们将从刷新的@Configuration)重新初始化。
加密和解密
Spring Cloud具有一个用于在本地解密属性值的Environment预处理器。它遵循与Config Server相同的规则,并通过encrypt.*具有相同的外部配置。因此,您可以使用{cipher}*格式的加密值,只要有一个有效的密钥,那么在主应用程序上下文获取Environment之前,它们将被解密。要在应用程序中使用加密功能,您需要在您的类路径中包含Spring安全性RSA(Maven协调“org.springframework.security:spring-security-rsa”),并且还需要全面强大的JCE扩展你的JVM
如果由于“非法密钥大小”而导致异常,并且您正在使用Sun的JDK,则需要安装Java加密扩展(JCE)无限强度管理策略文件。有关详细信息,请参阅以下链接:
Java 6 JCE
Java 7 JCE
Java 8 JCE
将文件解压缩到JDK / jre / lib / security文件夹(无论您使用的是哪个版本的JRE / JDK x64 / x86)。
端点
对于Spring Boot执行器应用程序,还有一些额外的管理端点:
POST到/env以更新Environment并重新绑定@ConfigurationProperties和日志级别
/refresh重新加载引导带上下文并刷新@RefreshScopebean
/restart关闭ApplicationContext并重新启动(默认情况下禁用)
/pause和/resume调用Lifecycle方法(stop()和start()ApplicationContext)
Spring Cloud Commons:普通抽象
诸如服务发现,负载平衡和断路器之类的模式适用于所有Spring Cloud客户端可以独立于实现(例如通过Eureka或Consul发现)的消耗的共同抽象层。
@EnableDiscoveryClient
Commons提供@EnableDiscoveryClient注释。这通过META-INF/spring.factories查找DiscoveryClient接口的实现。Discovery Client的实现将在org.springframework.cloud.client.discovery.EnableDiscoveryClient键下的spring.factories中添加一个配置类。DiscoveryClient实现的示例是Spring Cloud Netflix Eureka,Spring Cloud Consul发现和Spring Cloud Zookeeper发现。
默认情况下,DiscoveryClient的实现将使用远程发现服务器自动注册本地Spring Boot服务器。可以通过在@EnableDiscoveryClient中设置autoRegister=false来禁用此功能。
ServiceRegistry
Commons现在提供了一个ServiceRegistry接口,它提供了诸如register(Registration)和deregister(Registration)之类的方法,允许您提供定制的注册服务。Registration是一个标记界面。
@Configuration
@EnableDiscoveryClient(autoRegister=false)
public class MyConfiguration {
private ServiceRegistry registry;
public MyConfiguration(ServiceRegistry registry) {
this.registry = registry;
}
// called via some external process, such as an event or a custom actuator endpoint
public void register() {
Registration registration = constructRegistration();
this.registry.register(registration);
}
}
每个ServiceRegistry实现都有自己的Registry实现。
服务部门自动注册
默认情况下,ServiceRegistry实现将自动注册正在运行的服务。要禁用该行为,有两种方法。您可以设置@EnableDiscoveryClient(autoRegister=false)永久禁用自动注册。您还可以设置spring.cloud.service-registry.auto-registration.enabled=false以通过配置禁用该行为。
服务注册执行器端点
Commons提供/service-registry致动器端点。该端点依赖于Spring应用程序上下文中的Registrationbean。通过GET调用/service-registry/instance-status将返回Registration的状态。具有String主体的同一端点的POST将将当前Registration的状态更改为新值。请参阅您正在使用的ServiceRegistry实现的文档,以获取更新状态的允许值和为状态获取的值。
Spring RestTemplate作为负载平衡器客户端
RestTemplate可以自动配置为使用功能区。要创建负载平衡RestTemplate创建RestTemplate@Bean并使用@LoadBalanced限定符。
警告
通过自动配置不再创建RestTemplatebean。它必须由单个应用程序创建。
@Configuration
public class MyConfiguration {
@LoadBalanced
@Bean
RestTemplate restTemplate() {
return new RestTemplate();
}
}
public class MyClass {
@Autowired
private RestTemplate restTemplate;
public String doOtherStuff() {
String results = restTemplate.getForObject("http://stores/stores", String.class);
return results;
}
}
URI需要使用虚拟主机名(即服务名称,而不是主机名)。Ribbon客户端用于创建完整的物理地址。有关如何设置RestTemplate的详细信息,请参阅RibbonAutoConfiguration。
重试失败的请求
负载平衡RestTemplate可以配置为重试失败的请求。默认情况下,该逻辑被禁用,您可以通过将Spring重试添加到应用程序的类路径来启用它。负载平衡RestTemplate将符合与重试失败请求相关的一些Ribbon配置值。如果要在类路径中使用Spring重试来禁用重试逻辑,则可以设置spring.cloud.loadbalancer.retry.enabled=false。您可以使用的属性是client.ribbon.MaxAutoRetries,client.ribbon.MaxAutoRetriesNextServer和client.ribbon.OkToRetryOnAllOperations。请参阅Ribbon文档,了解属性的具体内容。
注意
上述示例中的client应替换为您的Ribbon客户端名称。
多个RestTemplate对象
如果你想要一个没有负载平衡的RestTemplate,创建一个RestTemplatebean并注入它。要创建@Bean时,使用@LoadBalanced限定符来访问负载平衡RestTemplate。
重要
请注意下面示例中的普通RestTemplate声明的@Primary注释,以消除不合格的@Autowired注入。
@Configuration
public class MyConfiguration {
@LoadBalanced
@Bean
RestTemplate loadBalanced() {
return new RestTemplate();
}
@Primary
@Bean
RestTemplate restTemplate() {
return new RestTemplate();
}
}
public class MyClass {
@Autowired
private RestTemplate restTemplate;
@Autowired
@LoadBalanced
private RestTemplate loadBalanced;
public String doOtherStuff() {
return loadBalanced.getForObject("http://stores/stores", String.class);
}
public String doStuff() {
return restTemplate.getForObject("http://example.com", String.class);
}
}
小费
如果您看到错误java.lang.IllegalArgumentException: Can not set org.springframework.web.client.RestTemplate field com.my.app.Foo.restTemplate to com.sun.proxy.$Proxy89,请尝试注入RestOperations或设置spring.aop.proxyTargetClass=true。
忽略网络接口
有时,忽略某些命名网络接口是有用的,因此可以将其从服务发现注册中排除(例如,在Docker容器中运行)。可以设置正则表达式的列表,这将导致所需的网络接口被忽略。以下配置将忽略“docker0”接口和以“veth”开头的所有接口。
application.yml
spring:
cloud:
inetutils:
ignoredInterfaces:
- docker0
- veth.*
您还可以强制使用正则表达式列表中指定的网络地址:
application.yml
spring:
cloud:
inetutils:
preferredNetworks:
- 192.168
- 10.0
您也可以强制仅使用站点本地地址。有关更多详细信息,请参阅Inet4Address.html.isSiteLocalAddress())是什么是站点本地地址。
application.yml
spring:
cloud:
inetutils:
useOnlySiteLocalInterfaces: true
Spring Cloud Config
Dalston.RELEASE
Spring Cloud Config为分布式系统中的外部配置提供服务器和客户端支持。使用Config Server,您可以在所有环境中管理应用程序的外部属性。客户端和服务器上的概念映射与SpringEnvironment和PropertySource抽象相同,因此它们与Spring应用程序非常契合,但可以与任何以任何语言运行的应用程序一起使用。随着应用程序通过从开发人员到测试和生产的部署流程,您可以管理这些环境之间的配置,并确定应用程序具有迁移时需要运行的一切。服务器存储后端的默认实现使用git,因此它轻松支持标签版本的配置环境,以及可以访问用于管理内容的各种工具。很容易添加替代实现,并使用Spring配置将其插入。
快速开始
启动服务器:
$ cd spring-cloud-config-server
$ ../mvnw spring-boot:run
该服务器是一个Spring Boot应用程序,所以您可以从IDE运行它,而不是喜欢(主类是ConfigServerApplication)。然后尝试一个客户端:
$ curl localhost:8888/foo/development
{"name":"development","label":"master","propertySources":[
{"name":"https://github.com/scratches/config-repo/foo-development.properties","source":{"bar":"spam"}},
{"name":"https://github.com/scratches/config-repo/foo.properties","source":{"foo":"bar"}}
]}
定位资源的默认策略是克隆一个git仓库(在spring.cloud.config.server.git.uri),并使用它来初始化一个迷你SpringApplication。小应用程序的Environment用于枚举属性源并通过JSON端点发布。
HTTP服务具有以下格式的资源:
/{application}/{profile}[/{label}]
/{application}-{profile}.yml
/{label}/{application}-{profile}.yml
/{application}-{profile}.properties
/{label}/{application}-{profile}.properties
其中“应用程序”作为SpringApplication中的spring.config.name注入(即常规的Spring Boot应用程序中通常是“应用程序”),“配置文件”是活动配置文件(或逗号分隔列表的属性),“label”是可选的git标签(默认为“master”)。
Spring Cloud Config服务器从git存储库(必须提供)为远程客户端提供配置:
spring:
cloud:
config:
server:
git:
uri: https://github.com/spring-cloud-samples/config-repo
客户端使用
要在应用程序中使用这些功能,只需将其构建为依赖于spring-cloud-config-client的Spring引导应用程序(例如,查看配置客户端或示例应用程序的测试用例)。添加依赖关系的最方便的方法是通过Spring Boot启动器org.springframework.cloud:spring-cloud-starter-config。还有一个Maven用户的父pom和BOM(spring-cloud-starter-parent)和用于Gradle和Spring CLI用户的Spring IO版本管理属性文件。示例Maven配置:
的pom.xml
org.springframework.boot
spring-boot-starter-parent
1.3.5.RELEASE
org.springframework.cloud
spring-cloud-dependencies
Brixton.RELEASE
pom
import
org.springframework.cloud
spring-cloud-starter-config
org.springframework.boot
spring-boot-starter-test
test
org.springframework.boot
spring-boot-maven-plugin
那么你可以创建一个标准的Spring Boot应用程序,像这个简单的HTTP服务器:
@SpringBootApplication
@RestController
public class Application {
@RequestMapping("/")
public String home() {
return "Hello World!";
}
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}
当它运行它将从端口8888上的默认本地配置服务器接收外部配置,如果它正在运行。要修改启动行为,您可以使用bootstrap.properties(如application.properties)更改配置服务器的位置,但用于应用程序上下文的引导阶段),例如
spring.cloud.config.uri: http://myconfigserver.com
引导属性将在/env端点中显示为高优先级属性源,例如
$ curl localhost:8080/env
{
"profiles":[],
"configService:https://github.com/spring-cloud-samples/config-repo/bar.properties":{"foo":"bar"},
"servletContextInitParams":{},
"systemProperties":{...},
...
}
(名为“configService:<远程存储库的URL> / <文件名>”的属性源包含值为“bar”的属性“foo”,是最高优先级)。
注意
属性源名称中的URL是git存储库,而不是配置服务器URL。
Spring Cloud Config服务器
服务器为外部配置(名称值对或等效的YAML内容)提供了基于资源的HTTP。服务器可以使用@EnableConfigServer注释轻松嵌入到Spring Boot应用程序中。所以这个应用程序是一个配置服务器:
ConfigServer.java
@SpringBootApplication
@EnableConfigServer
public class ConfigServer {
public static void main(String[] args) {
SpringApplication.run(ConfigServer.class, args);
}
}
像所有的默认端口8080上运行的所有Spring Boot应用程序一样,但您可以通过各种方式将其切换到常规端口8888。最简单的也是设置一个默认配置库,它是通过启动它的spring.config.name=configserver(在Config Server jar中有一个configserver.yml)。另一个是使用你自己的application.properties,例如
application.properties
server.port: 8888
spring.cloud.config.server.git.uri: file://${user.home}/config-repo
其中${user.home}/config-repo是包含YAML和属性文件的git仓库。
注意
在Windows中,如果文件URL为绝对驱动器前缀,例如file:///${user.home}/config-repo,则需要额外的“/”。
小费
以下是上面示例中创建git仓库的方法:
$ cd $HOME
$ mkdir config-repo
$ cd config-repo
$ git init .
$ echo info.foo: bar > application.properties
$ git add -A .
$ git commit -m "Add application.properties"
警告
使用本地文件系统进行git存储库仅用于测试。使用服务器在生产环境中托管配置库。
警告
如果您只保留文本文件,则配置库的初始克隆将会快速有效。如果您开始存储二进制文件,尤其是较大的文件,则可能会遇到服务器中第一个配置请求和/或内存不足错误的延迟。
环境库
您要在哪里存储配置服务器的配置数据?管理此行为的策略是EnvironmentRepository,服务于Environment对象。此Environment是SpringEnvironment(包括propertySources作为主要功能)的域的浅层副本。Environment资源由三个变量参数化:
{application}映射到客户端的“spring.application.name”;
{profile}映射到客户端上的“spring.profiles.active”(逗号分隔列表);和
{label}这是一个服务器端功能,标记“版本”的配置文件集。
存储库实现通常表现得像一个Spring Boot应用程序从“spring.config.name”等于{application}参数加载配置文件,“spring.profiles.active”等于{profiles}参数。配置文件的优先级规则也与常规启动应用程序相同:活动配置文件优先于默认配置,如果有多个配置文件,则最后一个获胜(例如向Map添加条目)。
示例:客户端应用程序具有此引导配置:
bootstrap.yml
spring:
application:
name: foo
profiles:
active: dev,mysql
(通常使用Spring Boot应用程序,这些属性也可以设置为环境变量或命令行参数)。
如果存储库是基于文件的,则服务器将从application.yml创建Environment(在所有客户端之间共享),foo.yml(以foo.yml优先))。如果YAML文件中有文件指向Spring配置文件,那么应用的优先级更高(按照列出的配置文件的顺序),并且如果存在特定于配置文件的YAML(或属性)文件,那么这些文件也应用于优先级高于默认值。较高优先级转换为Environment之前列出的PropertySource。(这些规则与独立的Spring Boot应用程序相同。)
Git后端
EnvironmentRepository的默认实现使用Git后端,这对于管理升级和物理环境以及审核更改非常方便。要更改存储库的位置,可以在Config Server中设置“spring.cloud.config.server.git.uri”配置属性(例如application.yml)。如果您使用file:前缀进行设置,则应从本地存储库中工作,以便在没有服务器的情况下快速方便地启动,但在这种情况下,服务器将直接在本地存储库上进行操作,而不会克隆如果它不是裸机,因为配置服务器永远不会更改“远程”资源库)。要扩展Config Server并使其高度可用,您需要将服务器的所有实例指向同一个存储库,因此只有共享文件系统才能正常工作。即使在这种情况下,最好使用共享文件系统存储库的ssh:协议,以便服务器可以将其克隆并使用本地工作副本作为缓存。
该存储库实现将HTTP资源的{label}参数映射到git标签(提交ID,分支名称或标签)。如果git分支或标签名称包含斜杠(“/”),则应使用特殊字符串“(_)”指定HTTP URL中的标签,以避免与其他URL路径模糊。例如,如果标签为foo/bar,则替换斜杠将导致标签看起来像foo(_)bar。如果您使用像curl这样的命令行客户端(例如使用引号将其从shell中转出来),请小心URL中的方括号。
Git URI中的占位符
Spring Cloud Config服务器支持一个Git仓库URL,其中包含{application}和{profile}(以及{label})的占位符,如果需要,请记住标签应用为git标签)。因此,您可以使用(例如)轻松支持“每个应用程序的一个repo”策略:
spring:
cloud:
config:
server:
git:
uri: https://github.com/myorg/{application}
或使用类似模式但使用{profile}的“每个配置文件一个”策略。
模式匹配和多个存储库
还可以通过应用程序和配置文件名称的模式匹配来支持更复杂的需求。模式格式是带有通配符的{application}/{profile}名称的逗号分隔列表(可能需要引用以通配符开头的模式)。例:
spring:
cloud:
config:
server:
git:
uri: https://github.com/spring-cloud-samples/config-repo
repos:
simple: https://github.com/simple/config-repo
special:
pattern: special*/dev*,*special*/dev*
uri: https://github.com/special/config-repo
local:
pattern: local*
uri: file:/home/configsvc/config-repo
如果{application}/{profile}不匹配任何模式,它将使用在“spring.cloud.config.server.git.uri”下定义的默认uri。在上面的例子中,对于“简单”存储库,模式是simple/*(即所有配置文件中只匹配一个名为“简单”的应用程序)。“本地”存储库与所有配置文件中以“local”开头的所有应用程序名称匹配(将/*后缀自动添加到任何没有配置文件匹配器的模式)。
注意
在上述“简单”示例中使用的“单行”快捷方式只能在唯一要设置的属性为URI的情况下使用。如果您需要设置其他任何内容(凭据,模式等),则需要使用完整的表单。
repo中的pattern属性实际上是一个数组,因此您可以使用属性文件中的YAML数组(或[0],[1]等后缀)绑定到多个模式。如果要运行具有多个配置文件的应用程序,则可能需要执行此操作。例:
spring:
cloud:
config:
server:
git:
uri: https://github.com/spring-cloud-samples/config-repo
repos:
development:
pattern:
- */development
- */staging
uri: https://github.com/development/config-repo
staging:
pattern:
- */qa
- */production
uri: https://github.com/staging/config-repo
注意
Spring Cloud将猜测包含不在*中的配置文件的模式意味着您实际上要匹配从此模式开始的配置文件列表(因此*/staging是["*/staging", "*/staging,*"])。这是常见的,您需要在本地的“开发”配置文件中运行应用程序,但也可以远程运行“云”配置文件。
每个存储库还可以选择将配置文件存储在子目录中,搜索这些目录的模式可以指定为searchPaths。例如在顶层:
spring:
cloud:
config:
server:
git:
uri: https://github.com/spring-cloud-samples/config-repo
searchPaths: foo,bar*
在此示例中,服务器搜索顶级和“foo /”子目录以及名称以“bar”开头的任何子目录中的配置文件。
默认情况下,首次请求配置时,服务器克隆远程存储库。服务器可以配置为在启动时克隆存储库。例如在顶层:
spring:
cloud:
config:
server:
git:
uri: https://git/common/config-repo.git
repos:
team-a:
pattern: team-a-*
cloneOnStart: true
uri: http://git/team-a/config-repo.git
team-b:
pattern: team-b-*
cloneOnStart: false
uri: http://git/team-b/config-repo.git
team-c:
pattern: team-c-*
uri: http://git/team-a/config-repo.git
在此示例中,服务器在启动之前克隆了team-a的config-repo,然后它接受任何请求。所有其他存储库将不被克隆,直到请求从存储库配置。
注意
在配置服务器启动时设置要克隆的存储库可以帮助在配置服务器启动时快速识别错误配置的源(例如,无效的存储库URI)。配置源不启用cloneOnStart时,配置服务器可能会成功启动配置错误或无效的配置源,而不会检测到错误,直到应用程序从该配置源请求配置为止。
认证
要在远程存储库上使用HTTP基本身份验证,请分别添加“username”和“password”属性(不在URL中),例如
spring:
cloud:
config:
server:
git:
uri: https://github.com/spring-cloud-samples/config-repo
username: trolley
password: strongpassword
如果您不使用HTTPS和用户凭据,当您将密钥存储在默认目录(~/.ssh)中,并且uri指向SSH位置时,SSH也应该开箱即用,例如“[email protected]:配置/云配置”。必须在~/.ssh/known_hosts文件中存在Git服务器的条目,并且它是ssh-rsa格式。其他格式(如ecdsa-sha2-nistp256)不受支持。为了避免意外,您应该确保Git服务器的known_hosts文件中只有一个条目,并且与您提供给配置服务器的URL匹配。如果您在URL中使用了主机名,那么您希望在known_hosts文件中具有这一点,而不是IP。使用JGit访问存储库,因此您发现的任何文档都应适用。HTTPS代理设置可以~/.git/config设置,也可以通过系统属性(-Dhttps.proxyHost和-Dhttps.proxyPort)与任何其他JVM进程相同。
小费
如果您不知道~/.git目录使用git config --global来处理设置的位置(例如git config --global http.sslVerify false)。
使用AWS CodeCommit进行认证
AWS CodeCommit认证也可以完成。当从命令行使用Git时,AWS CodeCommit使用身份验证助手。该帮助器不与JGit库一起使用,因此如果Git URI与AWS CodeCommit模式匹配,则将创建用于AWS CodeCommit的JGit CredentialProvider。AWS CodeCommit URI始终看起来像https://git-codecommit.$ {AWS_REGION} .amazonaws.com / $ {repopath}。
如果您使用AWS CodeCommit URI提供用户名和密码,那么这些URI必须是用于访问存储库的AWS accessKeyId和secretAccessKey。如果不指定用户名和密码,则将使用AWS默认凭据提供程序链检索accessKeyId和secretAccessKey。
如果您的Git URI与CodeCommit URI模式(上述)匹配,则必须在用户名和密码或默认凭据提供程序链支持的某个位置中提供有效的AWS凭据。AWS EC2实例可以使用EC2实例的IAM角色。
注意:aws-java-sdk-core jar是一个可选的依赖关系。如果aws-java-sdk-core jar不在您的类路径上,则无论git服务器URI如何,都将不会创建AWS代码提交凭据提供程序。
Git搜索路径中的占位符
Spring Cloud Config服务器还支持具有{application}和{profile}(以及{label}(如果需要))占位符的搜索路径。例:
spring:
cloud:
config:
server:
git:
uri: https://github.com/spring-cloud-samples/config-repo
searchPaths: '{application}'
在资源库中搜索与目录(以及顶级)相同名称的文件。通配符在具有占位符的搜索路径中也是有效的(搜索中包含任何匹配的目录)。
力拉入Git存储库
如前所述Spring Cloud Config服务器克隆远程git存储库,如果某种方式本地副本变脏(例如,通过操作系统进程更改文件夹内容),则Spring Cloud Config服务器无法从远程存储库更新本地副本。
要解决这个问题,有一个force-pull属性,如果本地副本是脏的,将使Spring Cloud Config Server强制从远程存储库拉。例:
spring:
cloud:
config:
server:
git:
uri: https://github.com/spring-cloud-samples/config-repo
force-pull: true
如果您有多个存储库配置,则可以为每个存储库配置force-pull属性。例:
spring:
cloud:
config:
server:
git:
uri: https://git/common/config-repo.git
force-pull: true
repos:
team-a:
pattern: team-a-*
uri: http://git/team-a/config-repo.git
force-pull: true
team-b:
pattern: team-b-*
uri: http://git/team-b/config-repo.git
force-pull: true
team-c:
pattern: team-c-*
uri: http://git/team-a/config-repo.git
注意
force-pull属性的默认值为false。
版本控制后端文件系统使用
警告
使用基于VCS的后端(git,svn)文件被检出或克隆到本地文件系统。默认情况下,它们放在系统临时目录中,前缀为config-repo-。在linux上,例如可以是/tmp/config-repo-。一些操作系统会定期清除临时目录。这可能会导致意外的行为,例如缺少属性。为避免此问题,请通过将spring.cloud.config.server.git.basedir或spring.cloud.config.server.svn.basedir设置为不驻留在系统临时结构中的目录来更改Config Server使用的目录。
文件系统后端
配置服务器中还有一个不使用Git的“本机”配置文件,只是从本地类路径或文件系统加载配置文件(您想要指向的任何静态URL“spring.cloud.config.server .native.searchLocations“)。要使用本机配置文件,只需使用“spring.profiles.active = native”启动Config Server。
注意
请记住使用file:前缀的文件资源(缺省没有前缀通常是classpath)。与任何Spring Boot配置一样,您可以嵌入${}样式的环境占位符,但请记住,Windows中的绝对路径需要额外的“/”,例如file:///${user.home}/config-repo
警告
searchLocations的默认值与本地Spring Boot应用程序(所以[classpath:/, classpath:/config, file:./, file:./config])相同。这不会将application.properties从服务器暴露给所有客户端,因为在发送到客户端之前,服务器中存在的任何属性源都将被删除。
小费
文件系统后端对于快速入门和测试是非常好的。要在生产中使用它,您需要确保文件系统是可靠的,并在配置服务器的所有实例中共享。
搜索位置可以包含{application},{profile}和{label}的占位符。以这种方式,您可以隔离路径中的目录,并选择一个有用的策略(例如每个应用程序的子目录或每个配置文件的子目录)。
如果您不在搜索位置使用占位符,则该存储库还将HTTP资源的{label}参数附加到搜索路径上的后缀,因此属性文件将从每个搜索位置加载并具有相同名称的子目录作为标签(标记的属性在Spring环境中优先)。因此,没有占位符的默认行为与添加以/{label}/. For example `file:/tmp/config结尾的搜索位置与file:/tmp/config,file:/tmp/config/{label}相同
Vault后端
Spring Cloud Config服务器还支持Vault作为后端。
Vault是安全访问秘密的工具。一个秘密是你想要严格控制访问的任何东西,如API密钥,密码,证书等等。Vault为任何秘密提供统一的界面,同时提供严格的访问控制和记录详细的审核日志。
有关Vault的更多信息,请参阅Vault快速入门指南。
要使配置服务器使用Vault后端,您必须使用vault配置文件运行配置服务器。例如在配置服务器的application.properties中,您可以添加spring.profiles.active=vault。
默认情况下,配置服务器将假定您的Vault服务器正在运行于http://127.0.0.1:8200。它还将假定后端名称为secret,密钥为application。所有这些默认值都可以在配置服务器的application.properties中配置。以下是可配置Vault属性的表。所有属性前缀为spring.cloud.config.server.vault。
名称默认值
host
127.0.0.1
port
8200
scheme
HTTP
backend
秘密
defaultKey
应用
profileSeparator
,
所有可配置的属性可以在org.springframework.cloud.config.server.environment.VaultEnvironmentRepository找到。
运行配置服务器后,可以向服务器发出HTTP请求,以从Vault后端检索值。为此,您需要为Vault服务器创建一个令牌。
首先放置一些数据给你Vault。例如
$ vault write secret/application foo=bar baz=bam
$ vault write secret/myapp foo=myappsbar
现在,将HTTP请求发送给您的配置服务器以检索值。
$ curl -X "GET" "http://localhost:8888/myapp/default" -H "X-Config-Token: yourtoken"
在提出上述要求后,您应该会看到类似的回复。
{
"name":"myapp",
"profiles":[
"default"
],
"label":null,
"version":null,
"state":null,
"propertySources":[
{
"name":"vault:myapp",
"source":{
"foo":"myappsbar"
}
},
{
"name":"vault:application",
"source":{
"baz":"bam",
"foo":"bar"
}
}
]
}
多个Properties来源
使用Vault时,您可以为应用程序提供多个属性源。例如,假设您已将数据写入Vault中的以下路径。
secret/myApp,dev
secret/myApp
secret/application,dev
secret/application
写入secret/application的Properties可用于使用配置服务器的所有应用程序。名称为myApp的应用程序将具有写入secret/myApp和secret/application的任何属性。当myApp启用dev配置文件时,写入所有上述路径的属性将可用,列表中第一个路径中的属性优先于其他路径。
与所有应用共享配置
基于文件的存储库
使用基于文件(即git,svn和native)的存储库,文件名为application*的资源在所有客户端应用程序(所以application.properties,application.yml,application-*.properties等)之间共享)。您可以使用这些文件名的资源来配置全局默认值,并根据需要将其覆盖应用程序特定的文件。
#_property_overrides [属性覆盖]功能也可用于设置全局默认值,并且允许占位符应用程序在本地覆盖它们。
小费
使用“本机”配置文件(本地文件系统后端),建议您使用不属于服务器自身配置的显式搜索位置。否则,默认搜索位置中的application*资源将被删除,因为它们是服务器的一部分。
Vault服务器
当使用Vault作为后端时,可以通过将配置放在secret/application中与所有应用程序共享配置。例如,如果您运行此Vault命令
$ vault write secret/application foo=bar baz=bam
使用配置服务器的所有应用程序都可以使用属性foo和baz。
复合环境库
在某些情况下,您可能希望从多个环境存储库中提取配置数据。为此,只需在配置服务器的应用程序属性或YAML文件中启用多个配置文件即可。例如,如果您要从Git存储库以及SVN存储库中提取配置数据,那么您将为配置服务器设置以下属性。
spring:
profiles:
active: git, svn
cloud:
config:
server:
svn:
uri: file:///path/to/svn/repo
order: 2
git:
uri: file:///path/to/git/repo
order: 1
除了指定URI的每个repo之外,还可以指定order属性。order属性允许您指定所有存储库的优先级顺序。order属性的数值越低,优先级越高。存储库的优先顺序将有助于解决包含相同属性的值的存储库之间的任何潜在冲突。
注意
从环境仓库检索值时的任何类型的故障将导致整个复合环境的故障。
注意
当使用复合环境时,重要的是所有repos都包含相同的标签。如果您有类似于上述的环境,并且使用标签master请求配置数据,但是SVN repo不包含称为master的分支,则整个请求将失败。
自定义复合环境库
除了使用来自Spring Cloud的环境存储库之外,还可以提供自己的EnvironmentRepositorybean作为复合环境的一部分。要做到这一点,你的bean必须实现EnvironmentRepository接口。如果要在复合环境中控制自定义EnvironmentRepository的优先级,您还应该实现Ordered接口并覆盖getOrdered方法。如果您不实现Ordered接口,那么您的EnvironmentRepository将被赋予最低优先级。
属性覆盖
配置服务器具有“覆盖”功能,允许操作员为应用程序使用普通的Spring Boot钩子不会意外更改的所有应用程序提供配置属性。要声明覆盖,只需将名称/值对的地图添加到spring.cloud.config.server.overrides。例如
spring:
cloud:
config:
server:
overrides:
foo: bar
将导致配置客户端的所有应用程序独立于自己的配置读取foo=bar。(当然,应用程序可以以任何方式使用Config Server中的数据,因此覆盖不可强制执行,但如果它们是Spring Cloud Config客户端,则它们确实提供有用的默认行为。)
小费
通过使用反斜杠(“\”)来转义“$”或“{”,例如\${app.foo:bar}解析,可以转义正常的Spring具有“$ {}”的环境占位符到“bar”,除非应用程序提供自己的“app.foo”。请注意,在YAML中,您不需要转义反斜杠本身,而是在您执行的属性文件中配置服务器上的覆盖。
您可以通过在远程存储库中设置标志spring.cloud.config.overrideNone=true(默认为false),将客户端中所有覆盖的优先级更改为更为默认值,允许应用程序在环境变量或系统属性中提供自己的值。
健康指标
配置服务器附带运行状况指示器,检查配置的EnvironmentRepository是否正常工作。默认情况下,它要求EnvironmentRepository应用程序名称为app,default配置文件和EnvironmentRepository实现提供的默认标签。
您可以配置运行状况指示器以检查更多应用程序以及自定义配置文件和自定义标签,例如
spring:
cloud:
config:
server:
health:
repositories:
myservice:
label: mylabel
myservice-dev:
name: myservice
profiles: development
您可以通过设置spring.cloud.config.server.health.enabled=false来禁用运行状况指示器。
安全
您可以以任何对您有意义的方式(从物理网络安全性到OAuth2承载令牌)保护您的Config Server,并且Spring Security和Spring Boot可以轻松做任何事情。
要使用默认的Spring Boot配置的HTTP Basic安全性,只需在类路径中包含Spring Security(例如通过spring-boot-starter-security)。默认值为“user”的用户名和随机生成的密码,这在实践中不会非常有用,因此建议您配置密码(通过security.user.password)并对其进行加密(请参阅下文的说明怎么做)。
加密和解密
重要
先决条件:要使用加密和解密功能,您需要在JVM中安装全面的JCE(默认情况下不存在)。您可以从Oracle下载“Java加密扩展(JCE)无限强度管理策略文件”,并按照安装说明(实际上将JRE lib / security目录中的2个策略文件替换为您下载的文件)。
如果远程属性源包含加密内容(以{cipher}开头的值),则在通过HTTP发送到客户端之前,它们将被解密。这种设置的主要优点是,当它们“静止”时,属性值不必是纯文本(例如在git仓库中)。如果值无法解密,则从属性源中删除该值,并添加具有相同键的附加属性,但以“无效”作为前缀。和“不适用”的值(通常为“”)。这主要是为了防止密码被用作密码并意外泄漏。
如果要为config客户端应用程序设置远程配置存储库,可能会包含一个application.yml,例如:
application.yml
spring:
datasource:
username: dbuser
password: '{cipher}FKSAJDFGYOS8F7GLHAKERGFHLSAJ'
.properties文件中的加密值不能用引号括起来,否则不会解密该值:
application.properties
spring.datasource.username: dbuser
spring.datasource.password: {cipher}FKSAJDFGYOS8F7GLHAKERGFHLSAJ
您可以安全地将此纯文本推送到共享git存储库,并且保密密码。
服务器还暴露了/encrypt和/decrypt端点(假设这些端点将被保护,并且只能由授权代理访问)。如果您正在编辑远程配置文件,可以使用Config Server通过POST到/encrypt端点来加密值,例如
$ curl localhost:8888/encrypt -d mysecret
682bc583f4641835fa2db009355293665d2647dade3375c0ee201de2a49f7bda
注意
如果要加密的值具有需要进行URL编码的字符,则应使用--data-urlencode选项curl来确保它们已正确编码。
逆向操作也可通过/decrypt获得(如果服务器配置了对称密钥或全密钥对):
$ curl localhost:8888/decrypt -d 682bc583f4641835fa2db009355293665d2647dade3375c0ee201de2a49f7bda
mysecret
小费
如果您使用curl进行测试,则使用--data-urlencode(而不是-d)或设置显式Content-Type: text/plain,以确保在有特殊字符时正确地对数据进行编码('+'特别是棘手)。
将加密的值添加到{cipher}前缀,然后再将其放入YAML或属性文件中,然后再提交并将其推送到远程可能不安全的存储区。
/encrypt和/decrypt端点也都接受/*/{name}/{profiles}形式的路径,当客户端调用到主环境资源时,可以用于每个应用程序(名称)和配置文件控制密码。
注意
为了以这种细微的方式控制密码,您还必须提供一种TextEncryptorLocator类型的@Bean,可以为每个名称和配置文件创建不同的加密器。默认提供的不会这样做(所有加密使用相同的密钥)。
spring命令行客户端(安装了Spring Cloud CLI扩展)也可以用于加密和解密,例如
$ spring encrypt mysecret --key foo
682bc583f4641835fa2db009355293665d2647dade3375c0ee201de2a49f7bda
$ spring decrypt --key foo 682bc583f4641835fa2db009355293665d2647dade3375c0ee201de2a49f7bda
mysecret
要在文件中使用密钥(例如用于加密的RSA公钥),使用“@”键入键值,并提供文件路径,例如
$ spring encrypt mysecret --key @${HOME}/.ssh/id_rsa.pub
AQAjPgt3eFZQXwt8tsHAVv/QHiY5sI2dRcR+...
关键参数是强制性的(尽管有一个--前缀)。
密钥管理
Config Server可以使用对称(共享)密钥或非对称密钥(RSA密钥对)。非对称选择在安全性方面是优越的,但是使用对称密钥往往更方便,因为它只是配置的一个属性值。
要配置对称密钥,您只需要将encrypt.key设置为一个秘密字符串(或使用环境变量ENCRYPT_KEY将其从纯文本配置文件中删除)。
要配置非对称密钥,您可以将密钥设置为PEM编码的文本值(encrypt.key),也可以通过密钥库设置密钥(例如由JDK附带的keytool实用程序创建)。密钥库属性为encrypt.keyStore.*,*等于
location(aResource位置),
password(解锁密钥库)和
alias(以识别商店中使用的密钥)。
使用公钥进行加密,需要私钥进行解密。因此,原则上您只能在服务器中配置公钥,如果您只想进行加密(并准备使用私钥本地解密值)。实际上,您可能不想这样做,因为它围绕所有客户端传播密钥管理流程,而不是将其集中在服务器中。另一方面,如果您的配置服务器真的相对不安全,并且只有少数客户端需要加密的属性,这是一个有用的选项。
创建用于测试的密钥库
要创建一个密钥库进行测试,您可以执行以下操作:
$ keytool -genkeypair -alias mytestkey -keyalg RSA \
-dname "CN=Web Server,OU=Unit,O=Organization,L=City,S=State,C=US" \
-keypass changeme -keystore server.jks -storepass letmein
将server.jks文件放在类路径(例如)中,然后在您的application.yml中配置服务器:
encrypt:
keyStore:
location: classpath:/server.jks
password: letmein
alias: mytestkey
secret: changeme
使用多个键和键旋转
除了加密属性值中的{cipher}前缀之外,配置服务器在(Base64编码)密文开始前查找{name:value}前缀(零或多个)。密钥被传递给TextEncryptorLocator,它可以执行找到密码的TextEncryptor所需的任何逻辑。如果配置了密钥库(encrypt.keystore.location),默认定位器将使用“key”前缀提供的别名,即使用如下密码查找存储中的密钥:
foo:
bar: `{cipher}{key:testkey}...`
定位器将寻找一个名为“testkey”的键。也可以通过前缀中的{secret:…}值提供一个秘密,但是如果不是默认值,则使用密钥库密码(这是您在构建密钥库时获得的,并且不指定密码)。如果你这样做提供一个秘密建议你也加密使用自定义SecretLocator的秘密。
如果密钥只用于加密几个字节的配置数据(即它们没有在其他地方使用),则密码转换几乎不是必需的,但是如果存在安全漏洞,有时您可能需要更改密钥实例。在这种情况下,所有客户端都需要更改其源配置文件(例如,以git格式),并在所有密码中使用新的{key:…}前缀,当然事先检查密钥别名在配置服务器密钥库中是否可用。
小费
如果要让Config Server处理所有加密以及解密,也可以将{name:value}前缀添加到发布到/encrypt端点的明文中。
服务加密Properties
有时您希望客户端在本地解密配置,而不是在服务器中进行配置。在这种情况下,您仍然可以拥有/加密和解密端点(如果您提供encrypt.*配置来定位密钥),但是您需要使用spring.cloud.config.server.encrypt.enabled=false明确地关闭传出属性的解密。如果您不关心端点,那么如果您既不配置密钥也不配置使能的标志,则应该起作用。
服务替代格式
来自环境端点的默认JSON格式对于Spring应用程序的消费是完美的,因为它直接映射到Environment抽象。如果您喜欢,可以通过向资源路径(“.yml”,“.yaml”或“.properties”)添加后缀来使用与YAML或Java属性相同的数据。这对于不关心JSON端点的结构的应用程序或其提供的额外的元数据的应用程序来说可能是有用的,例如,不使用Spring的应用程序可能会受益于此方法的简单性。
YAML和属性表示有一个额外的标志(作为一个布尔查询参数resolvePlaceholders提供)),以标示Spring${…}形式的源文档中的占位符,应在输出中解析可能在渲染之前。对于不了解Spring占位符惯例的消费者来说,这是一个有用的功能。
注意
使用YAML或属性格式存在局限性,主要是与元数据的丢失有关。JSON被构造为属性源的有序列表,例如,名称与源相关联。即使源的起源具有多个源,并且原始源文件的名称丢失,YAML和属性表也合并成一个映射。YAML表示不一定是后台存储库中YAML源的忠实表示:它是由平面属性源的列表构建的,并且必须对键的形式进行假设。
服务纯文本
您的应用程序可能需要通用的纯文本配置文件,而不是使用Environment抽象(或YAML中的其他替代表示形式或属性格式)。配置服务器通过/{name}/{profile}/{label}/{path}附加的端点提供这些服务,其中“name”,“profile”和“label”的含义与常规环境端点相同,但“path”是文件名(例如log.xml)。此端点的源文件位于与环境端点相同的方式:与属性或YAML文件相同的搜索路径,而不是聚合所有匹配的资源,只返回匹配的第一个。
找到资源后,使用正确格式(${…})的占位符将使用有效的Environment解析为应用程序名称,配置文件和标签提供。以这种方式,资源端点与环境端点紧密集成。例如,如果您有一个GIT(或SVN)资源库的布局:
application.yml
nginx.conf
其中nginx.conf如下所示:
server {
listen 80;
server_name ${nginx.server.name};
}
和application.yml这样:
nginx:
server:
name: example.com
---
spring:
profiles: development
nginx:
server:
name: develop.com
那么/foo/default/master/nginx.conf资源如下所示:
server {
listen 80;
server_name example.com;
}
和/foo/development/master/nginx.conf这样:
server {
listen 80;
server_name develop.com;
}
注意
就像环境配置的源文件一样,“配置文件”用于解析文件名,因此,如果您想要一个特定于配置文件的文件,则/*/development/*/logback.xml将由一个名为logback-development.xml的文件解析(优先于logback.xml)。
嵌入配置服务器
配置服务器最好作为独立应用程序运行,但如果需要,可以将其嵌入到另一个应用程序中。只需使用@EnableConfigServer注释。在这种情况下可以使用的可选属性是spring.cloud.config.server.bootstrap,它是一个标志,表示服务器应该从其自己的远程存储库配置自身。该标志默认关闭,因为它可能会延迟启动,但是当嵌入在另一个应用程序中时,以与其他应用程序相同的方式初始化是有意义的。
注意
应该是显而易见的,但请记住,如果您使用引导标志,配置服务器将需要在bootstrap.yml中配置其名称和存储库URI。
要更改服务器端点的位置,您可以(可选)设置spring.cloud.config.server.prefix,例如“/ config”,以提供前缀下的资源。前缀应该开始但不以“/”结尾。它被应用于配置服务器中的@RequestMappings(即Spring Boot前缀server.servletPath和server.contextPath)之下。
如果您想直接从后端存储库(而不是从配置服务器)读取应用程序的配置,这基本上是一个没有端点的嵌入式配置服务器。如果不使用@EnableConfigServer注释(仅设置spring.cloud.config.server.bootstrap=true),则可以完全关闭端点。
推送通知和Spring Cloud Bus
许多源代码存储库提供程序(例如Github,Gitlab或Bitbucket)将通过webhook通知您存储库中的更改。您可以通过提供商的用户界面将webhook配置为URL和一组感兴趣的事件。例如,Github将使用包含提交列表的JSON主体和“X-Github-Event”等于“push”的头文件发送到webhook。如果在spring-cloud-config-monitor库中添加依赖关系并激活配置服务器中的Spring Cloud Bus,则启用“/ monitor”端点。
当Webhook被激活时,配置服务器将发送一个RefreshRemoteApplicationEvent针对他认为可能已经改变的应用程序。变更检测可以进行策略化,但默认情况下,它只是查找与应用程序名称匹配的文件的更改(例如,“foo.properties”针对的是“foo”应用程序,“application.properties”针对所有应用程序) 。如果要覆盖该行为的策略是PropertyPathNotificationExtractor,它接受请求标头和正文作为参数,并返回更改的文件路径列表。
默认配置与Github,Gitlab或Bitbucket配合使用。除了来自Github,Gitlab或Bitbucket的JSON通知之外,您还可以通过使用表单编码的身体参数path={name}通过POST为“/ monitor”来触发更改通知。这将广播到匹配“{name}”模式的应用程序(可以包含通配符)。
注意
只有在配置服务器和客户端应用程序中激活spring-cloud-bus时才会传送RefreshRemoteApplicationEvent。
注意
默认配置还检测本地git存储库中的文件系统更改(在这种情况下不使用webhook,但是一旦编辑配置文件,将会播放刷新)。
Spring Cloud Config客户端
Spring Boot应用程序可以立即利用Spring配置服务器(或应用程序开发人员提供的其他外部属性源),并且还将获取与Environment更改事件相关的一些其他有用功能。
配置第一引导
这是在类路径上具有Spring Cloud Config Client的任何应用程序的默认行为。配置客户端启动时,它将通过配置服务器(通过引导配置属性spring.cloud.config.uri)绑定,并使用远程属性源初始化SpringEnvironment。
这样做的最终结果是所有想要使用Config Server的客户端应用程序需要bootstrap.yml(或环境变量),服务器地址位于spring.cloud.config.uri(默认为“http:// localhost:8888” )。
发现第一个引导
如果您正在使用DiscoveryClient实现,例如Spring Cloud Netflix和Eureka服务发现或Spring Cloud Consul(Spring Cloud Zookeeper不支持此功能),那么您可以使用Config Server如果您想要发现服务注册,但在默认的“配置优先”模式下,客户端将无法利用注册。
如果您希望使用DiscoveryClient找到配置服务器,可以通过设置spring.cloud.config.discovery.enabled=true(默认为“false”)来实现。最终的结果是,客户端应用程序都需要具有适当发现配置的bootstrap.yml(或环境变量)。例如,使用Spring Cloud Netflix,您需要定义Eureka服务器地址,例如eureka.client.serviceUrl.defaultZone。使用此选项的价格是启动时额外的网络往返,以定位服务注册。好处是配置服务器可以更改其坐标,只要发现服务是一个固定点。默认的服务标识是“configserver”,但您可以使用spring.cloud.config.discovery.serviceId在客户端进行更改(在服务器上以服务的通常方式更改,例如设置spring.application.name)。
发现客户端实现都支持某种元数据映射(例如Eureka,我们有eureka.instance.metadataMap)。可能需要在其服务注册元数据中配置Config Server的一些其他属性,以便客户端可以正确连接。如果使用HTTP Basic安全配置服务器,则可以将凭据配置为“用户名”和“密码”。并且如果配置服务器具有上下文路径,您可以设置“configPath”。例如,对于作为Eureka客户端的配置服务器:
bootstrap.yml
eureka:
instance:
...
metadataMap:
user: osufhalskjrtl
password: lviuhlszvaorhvlo5847
configPath: /config
配置客户端快速失败
在某些情况下,如果服务无法连接到配置服务器,则可能希望启动服务失败。如果这是所需的行为,请设置引导配置属性spring.cloud.config.failFast=true,客户端将以异常停止。
配置客户端重试
如果您希望配置服务器在您的应用程序启动时可能偶尔不可用,您可以要求它在发生故障后继续尝试。首先,您需要设置spring.cloud.config.failFast=true,然后您需要添加spring-retry和spring-boot-starter-aop到您的类路径。默认行为是重试6次,初始退避间隔为1000ms,指数乘数为1.1,用于后续退避。您可以使用spring.cloud.config.retry.*配置属性配置这些属性(和其他)。
小费
要完全控制重试,请使用ID“configServerRetryInterceptor”添加RetryOperationsInterceptor类型的@Bean。Spring重试有一个RetryInterceptorBuilder可以轻松创建一个。
查找远程配置资源
配置服务从/{name}/{profile}/{label}提供属性源,客户端应用程序中的默认绑定
“name”=${spring.application.name}
“profile”=${spring.profiles.active}(实际上是Environment.getActiveProfiles())
“label”=“master”
所有这些都可以通过设置spring.cloud.config.*(其中*是“name”,“profile”或“label”)来覆盖。“标签”可用于回滚到以前版本的配置;使用默认的Config Server实现,它可以是git标签,分支名称或提交ID。标签也可以以逗号分隔的列表形式提供,在这种情况下,列表中的项目会逐个尝试,直到成功。例如,当您可能希望将配置标签与您的分支对齐,但使其成为可选(例如spring.cloud.config.label=myfeature,develop)时,这对于在特征分支上工作时可能很有用。
安全
如果您在服务器上使用HTTP基本安全性,那么客户端只需要知道密码(如果不是默认用户名)。您可以通过配置服务器URI,或通过单独的用户名和密码属性,例如
bootstrap.yml
spring:
cloud:
config:
uri: https://user:[email protected]
要么
bootstrap.yml
spring:
cloud:
config:
uri: https://myconfig.mycompany.com
username: user
password: secret
spring.cloud.config.password和spring.cloud.config.username值覆盖URI中提供的任何内容。
如果您在Cloud Foundry部署应用程序,则提供密码的最佳方式是通过服务凭证(例如URI),因为它甚至不需要在配置文件中。在Cloud Foundry上为本地工作的用户提供的服务的一个例子,名为“configserver”:
bootstrap.yml
spring:
cloud:
config:
uri: ${vcap.services.configserver.credentials.uri:http://user:password@localhost:8888}
如果您使用另一种形式的安全性,则可能需要向ConfigServicePropertySourceLocator提供RestTemplate(例如,通过在引导上下文中获取它并注入一个)。ConfigServicePropertySourceLocator提供{470/}(例如通过在引导上下文中获取它并注入)。
健康指标
Config Client提供一个尝试从Config Server加载配置的Spring Boot运行状况指示器。可以通过设置health.config.enabled=false来禁用运行状况指示器。由于性能原因,响应也被缓存。默认缓存生存时间为5分钟。要更改该值,请设置health.config.time-to-live属性(以毫秒为单位)。
提供自定义RestTemplate
在某些情况下,您可能需要从客户端自定义对配置服务器的请求。通常这涉及传递特殊的Authorization标头来对服务器的请求进行身份验证。要提供自定义RestTemplate,请按照以下步骤操作。
设置spring.cloud.config.enabled=false以禁用现有的配置服务器属性源。
使用PropertySourceLocator实现创建一个新的配置bean。
CustomConfigServiceBootstrapConfiguration.java
@Configuration
public class CustomConfigServiceBootstrapConfiguration {
@Bean
public ConfigClientProperties configClientProperties() {
ConfigClientProperties client = new ConfigClientProperties(this.environment);
client.setEnabled(false);
return client;
}
@Bean
public ConfigServicePropertySourceLocator configServicePropertySourceLocator() {
ConfigClientProperties clientProperties = configClientProperties();
ConfigServicePropertySourceLocator configServicePropertySourceLocator = new ConfigServicePropertySourceLocator(clientProperties);
configServicePropertySourceLocator.setRestTemplate(customRestTemplate(clientProperties));
return configServicePropertySourceLocator;
}
}
在resources/META-INF中创建一个名为spring.factories的文件,并指定您的自定义配置。
spring.factorties
org.springframework.cloud.bootstrap.BootstrapConfiguration = com.my.config.client.CustomConfigServiceBootstrapConfiguration
Vault
当使用Vault作为配置服务器的后端时,客户端将需要为服务器提供一个令牌,以从Vault中检索值。可以通过在bootstrap.yml中设置spring.cloud.config.token在客户端中提供此令牌。
bootstrap.yml
spring:
cloud:
config:
token: YourVaultToken
Vault
Vault中的嵌套密钥
Vault支持将键嵌入存储在Vault中的值。例如
echo -n '{"appA": {"secret": "appAsecret"}, "bar": "baz"}' | vault write secret/myapp -
此命令将向您的Vault编写一个JSON对象。要在Spring中访问这些值,您将使用传统的点(。)注释。例如
@Value("${appA.secret}")
String name = "World";
上述代码将name变量设置为appAsecret。
Spring Cloud Netflix
Dalston.RELEASE
该项目通过自动配置为Spring Boot应用程序提供Netflix OSS集成,并绑定到Spring环境和其他Spring编程模型成语。通过几个简单的注释,您可以快速启用和配置应用程序中的常见模式,并通过经过测试的Netflix组件构建大型分布式系统。提供的模式包括服务发现(Eureka),断路器(Hystrix),智能路由(Zuul)和客户端负载平衡(Ribbon)。
服务发现:Eureka客户端
服务发现是基于微服务架构的关键原则之一。尝试配置每个客户端或某种形式的约定可能非常困难,可以非常脆弱。Netflix服务发现服务器和客户端是Eureka。可以将服务器配置和部署为高可用性,每个服务器将注册服务的状态复制到其他服务器。
如何包含Eureka客户端
要在您的项目中包含Eureka客户端,请使用组org.springframework.cloud和工件IDspring-cloud-starter-eureka的启动器。有关使用当前的Spring Cloud发布列表设置构建系统的详细信息,请参阅Spring Cloud项目页面。
注册Eureka
当客户端注册Eureka时,它提供关于自身的元数据,例如主机和端口,健康指示符URL,主页等。Eureka从属于服务的每个实例接收心跳消息。如果心跳失败超过可配置的时间表,则通常将该实例从注册表中删除。
示例eureka客户端:
@Configuration
@ComponentScan
@EnableAutoConfiguration
@EnableEurekaClient
@RestController
public class Application {
@RequestMapping("/")
public String home() {
return "Hello world";
}
public static void main(String[] args) {
new SpringApplicationBuilder(Application.class).web(true).run(args);
}
}
(即完全正常的Spring Boot应用程序)。在这个例子中,我们明确地使用@EnableEurekaClient,但只有Eureka可用,你也可以使用@EnableDiscoveryClient。需要配置才能找到Eureka服务器。例:
application.yml
eureka:
client:
serviceUrl:
defaultZone: http://localhost:8761/eureka/
其中“defaultZone”是一个魔术字符串后备值,为任何不表示首选项的客户端提供服务URL(即它是有用的默认值)。
从Environment获取的默认应用程序名称(服务ID),虚拟主机和非安全端口分别为${spring.application.name},${spring.application.name}和${server.port}。
@EnableEurekaClient将应用程序同时进入一个Eureka“实例”(即注册自己)和一个“客户端”(即它可以查询注册表以查找其他服务)。实例行为由eureka.instance.*配置键驱动,但是如果您确保您的应用程序具有spring.application.name(这是Eureka服务ID或VIP的默认值),那么默认值将是正常的。
有关可配置选项的更多详细信息,请参阅EurekaInstanceConfigBean和EurekaClientConfigBean。
使用Eureka服务器进行身份验证
如果其中一个eureka.client.serviceUrl.defaultZone网址中包含一个凭据(如http://user:password@localhost:8761/eureka)),HTTP基本身份验证将自动添加到您的eureka客户端。对于更复杂的需求,您可以创建DiscoveryClientOptionalArgs类型的@Bean,并将ClientFilter实例注入到其中,所有这些都将应用于从客户端到服务器的调用。
注意
由于Eureka中的限制,不可能支持每个服务器的基本身份验证凭据,所以只能使用第一个找到的集合。
状态页和健康指标
Eureka实例的状态页面和运行状况指示器分别默认为“/ info”和“/ health”,它们是Spring Boot执行器应用程序中有用端点的默认位置。如果您使用非默认上下文路径或servlet路径(例如server.servletPath=/foo)或管理端点路径(例如management.contextPath=/admin),则需要更改这些,即使是执行器应用程序。例:
application.yml
eureka:
instance:
statusPageUrlPath: ${management.context-path}/info
healthCheckUrlPath: ${management.context-path}/health
这些链接显示在客户端使用的元数据中,并在某些情况下用于决定是否将请求发送到应用程序,因此如果它们是准确的,这是有帮助的。
注册安全应用程序
如果您的应用程序想通过HTTPS联系,则可以分别在EurekaInstanceConfig,即eureka.instance.[nonSecurePortEnabled,securePortEnabled]=[false,true]中设置两个标志。这将使Eureka发布实例信息显示安全通信的明确偏好。Spring CloudDiscoveryClient将始终为以这种方式配置的服务返回一个https://…;URI,并且Eureka(本机)实例信息将具有安全的健康检查URL。
由于Eureka内部的工作方式,它仍然会发布状态和主页的非安全网址,除非您也明确地覆盖。您可以使用占位符来配置eureka实例URL,例如
application.yml
eureka:
instance:
statusPageUrl: https://${eureka.hostname}/info
healthCheckUrl: https://${eureka.hostname}/health
homePageUrl: https://${eureka.hostname}/
(请注意,${eureka.hostname}是仅在稍后版本的Eureka中可用的本地占位符,您也可以使用Spring占位符实现同样的功能,例如使用${eureka.instance.hostName}。
注意
如果您的应用程序在代理服务器后面运行,并且SSL终止服务在代理中(例如,如果您运行在Cloud Foundry或其他平台作为服务),则需要确保代理“转发”头部被截取并处理应用程序。Spring Boot应用程序中的嵌入式Tomcat容器会自动执行“X-Forwarded - \ *”标头的显式配置。你这个错误的一个迹象就是你的应用程序本身所呈现的链接是错误的(错误的主机,端口或协议)。
Eureka的健康检查
默认情况下,Eureka使用客户端心跳来确定客户端是否启动。除非另有规定,否则发现客户端将不会根据Spring Boot执行器传播应用程序的当前运行状况检查状态。这意味着成功注册后Eureka将永远宣布申请处于“UP”状态。通过启用Eureka运行状况检查可以改变此行为,从而将应用程序状态传播到Eureka。因此,每个其他应用程序将不会在“UP”之外的状态下将流量发送到应用程序。
application.yml
eureka:
client:
healthcheck:
enabled: true
警告
eureka.client.healthcheck.enabled=true只能在application.yml中设置。设置bootstrap.yml中的值将导致不期望的副作用,例如在具有UNKNOWN状态的eureka中注册。
如果您需要更多的控制健康检查,您可以考虑实施自己的com.netflix.appinfo.HealthCheckHandler。
Eureka实例和客户端的元数据
值得花点时间了解Eureka元数据的工作原理,以便您可以在平台上使用它。有主机名,IP地址,端口号,状态页和运行状况检查等标准元数据。这些发布在服务注册表中,由客户使用,以直接的方式联系服务。额外的元数据可以添加到eureka.instance.metadataMap中的实例注册中,并且这将在远程客户端中可访问,但一般不会更改客户端的行为,除非意识到元数据的含义。下面描述了几个特殊情况,其中Spring Cloud已经为元数据映射指定了含义。
在Cloudfoundry上使用Eureka
Cloudfoundry有一个全局路由器,所以同一个应用程序的所有实例都具有相同的主机名(在具有相似架构的其他PaaS解决方案中也是如此)。这不一定是使用Eureka的障碍,但如果您使用路由器(建议,甚至是强制性的,具体取决于您的平台的设置方式),则需要明确设置主机名和端口号(安全或非安全),以便他们使用路由器。您可能还需要使用实例元数据,以便您可以区分客户端上的实例(例如,在自定义负载平衡器中)。默认情况下,eureka.instance.instanceId为vcap.application.instance_id。例如:
application.yml
eureka:
instance:
hostname: ${vcap.application.uris[0]}
nonSecurePort: 80
根据Cloudfoundry实例中安全规则的设置方式,您可以注册并使用主机VM的IP地址进行直接的服务到服务调用。此功能尚未在Pivotal Web Services(PWS)上提供。
在AWS上使用Eureka
如果应用程序计划将部署到AWS云,那么Eureka实例必须被配置为AWS意识到,这可以通过定制来完成EurekaInstanceConfigBean方式如下:
@Bean
@Profile("!default")
public EurekaInstanceConfigBean eurekaInstanceConfig(InetUtils inetUtils) {
EurekaInstanceConfigBean b = new EurekaInstanceConfigBean(inetUtils);
AmazonInfo info = AmazonInfo.Builder.newBuilder().autoBuild("eureka");
b.setDataCenterInfo(info);
return b;
}
更改Eureka实例ID
香草Netflix Eureka实例注册了与其主机名相同的ID(即每个主机只有一个服务)。Spring Cloud Eureka提供了一个明智的默认,如下所示:${spring.cloud.client.hostname}:${spring.application.name}:${spring.application.instance_id:${server.port}}}。例如myhost:myappname:8080。
使用Spring Cloud,您可以通过在eureka.instance.instanceId中提供唯一的标识符来覆盖此。例如:
application.yml
eureka:
instance:
instanceId: ${spring.application.name}:${vcap.application.instance_id:${spring.application.instance_id:${random.value}}}
使用这个元数据和在localhost上部署的多个服务实例,随机值将在那里进行,以使实例是唯一的。在Cloudfoundry中,vcap.application.instance_id将在Spring Boot应用程序中自动填充,因此不需要随机值。
使用EurekaClient
一旦您拥有@EnableDiscoveryClient(或@EnableEurekaClient)的应用程序,您就可以使用它来从Eureka服务器发现服务实例。一种方法是使用本机com.netflix.discovery.EurekaClient(而不是Spring云DiscoveryClient),例如
@Autowired
private EurekaClient discoveryClient;
public String serviceUrl() {
InstanceInfo instance = discoveryClient.getNextServerFromEureka("STORES", false);
return instance.getHomePageUrl();
}
小费
不要使用@PostConstruct方法或@Scheduled方法(或ApplicationContext可能尚未启动的任何地方)EurekaClient。它被初始化为SmartLifecycle(带有phase=0),所以最早可以依靠它可用的是另一个具有更高阶段的SmartLifecycle。
本机Netflix EurekaClient的替代方案
您不必使用原始的NetflixEurekaClient,通常在某种包装器后面使用它更为方便。Spring Cloud支持Feign(REST客户端构建器),还支持SpringRestTemplate使用逻辑Eureka服务标识符(VIP)而不是物理URL。要使用固定的物理服务器列表配置Ribbon,您可以将.ribbon.listOfServers设置为逗号分隔的物理地址(或主机名)列表,其中是客户端的ID。
您还可以使用org.springframework.cloud.client.discovery.DiscoveryClient,它为Netflix不具体的发现客户端提供简单的API,例如
@Autowired
private DiscoveryClient discoveryClient;
public String serviceUrl() {
List list = discoveryClient.getInstances("STORES");
if (list != null && list.size() > 0 ) {
return list.get(0).getUri();
}
return null;
}
为什么注册服务这么慢?
作为一个实例也包括定期心跳到注册表(通过客户端的serviceUrl),默认持续时间为30秒。在实例,服务器和客户端在其本地缓存中都具有相同的元数据(因此可能需要3个心跳)之前,客户端才能发现服务。您可以使用eureka.instance.leaseRenewalIntervalInSeconds更改期限,这将加快客户端连接到其他服务的过程。在生产中,最好坚持使用默认值,因为服务器内部有一些计算可以对租赁更新期进行假设。
区
如果您已将Eureka客户端部署到多个区域,您可能希望这些客户端在使用另一个区域中的服务之前,利用同一区域内的服务。为此,您需要正确配置您的Eureka客户端。
首先,您需要确保将Eureka服务器部署到每个区域,并且它们是彼此的对等体。有关详细信息,请参阅区域和区域部分。
接下来,您需要告知Eureka您的服务所在的区域。您可以使用metadataMap属性来执行此操作。例如,如果service 1部署到zone 1和zone 2,则需要在service 1中设置以下Eureka属性
1区服务1
eureka.instance.metadataMap.zone = zone1
eureka.client.preferSameZoneEureka = true
第2区的服务1
eureka.instance.metadataMap.zone = zone2
eureka.client.preferSameZoneEureka = true
服务发现:Eureka服务器
如何包含Eureka服务器
要在项目中包含Eureka服务器,请使用组org.springframework.cloud和工件idspring-cloud-starter-eureka-server的启动器。有关使用当前的Spring Cloud发布列表设置构建系统的详细信息,请参阅Spring Cloud项目页面。
如何运行Eureka服务器
示例eureka服务器;
@SpringBootApplication
@EnableEurekaServer
public class Application {
public static void main(String[] args) {
new SpringApplicationBuilder(Application.class).web(true).run(args);
}
}
服务器具有一个带有UI的主页,并且根据/eureka/*下的正常Eureka功能的HTTP API端点。
Eureka背景阅读:看助焊剂电容和谷歌小组讨论。
小费
由于Gradle的依赖关系解决规则和父母的bom功能缺乏,只要依靠spring-cloud-starter-eureka-server就可能导致应用程序启动失败。要解决这个问题,必须添加Spring Boot Gradle插件,并且必须导入Spring云启动器父母bom:
的build.gradle
buildscript {
dependencies {
classpath("org.springframework.boot:spring-boot-gradle-plugin:1.3.5.RELEASE")
}
}
apply plugin: "spring-boot"
dependencyManagement {
imports {
mavenBom "org.springframework.cloud:spring-cloud-dependencies:Brixton.RELEASE"
}
}
高可用性,区域和地区
Eureka服务器没有后端存储,但是注册表中的服务实例都必须发送心跳以保持其注册更新(因此可以在内存中完成)。客户端还具有eureka注册的内存缓存(因此,他们不必为注册表提供每个服务请求)。
默认情况下,每个Eureka服务器也是一个Eureka客户端,并且需要(至少一个)服务URL来定位对等体。如果您不提供该服务将运行和工作,但它将淋浴您的日志与大量的噪音无法注册对等体。
关于区域和区域的客户端Ribbon支持的详细信息,请参见下文。
独立模式
只要存在某种监视器或弹性运行时间(例如Cloud Foundry),两个高速缓存(客户机和服务器)和心跳的组合使独立的Eureka服务器对故障具有相当的弹性。在独立模式下,您可能更喜欢关闭客户端行为,因此不会继续尝试并且无法访问其对等体。例:
application.yml(Standalone Eureka Server)
server:
port: 8761
eureka:
instance:
hostname: localhost
client:
registerWithEureka: false
fetchRegistry: false
serviceUrl:
defaultZone: http://${eureka.instance.hostname}:${server.port}/eureka/
请注意,serviceUrl指向与本地实例相同的主机。
同行意识
通过运行多个实例并请求他们相互注册,可以使Eureka更具弹性和可用性。事实上,这是默认的行为,所以你需要做的只是为对方添加一个有效的serviceUrl,例如
application.yml(Two Peer Aware Eureka服务器)
---
spring:
profiles: peer1
eureka:
instance:
hostname: peer1
client:
serviceUrl:
defaultZone: http://peer2/eureka/
---
spring:
profiles: peer2
eureka:
instance:
hostname: peer2
client:
serviceUrl:
defaultZone: http://peer1/eureka/
在这个例子中,我们有一个YAML文件,可以通过在不同的Spring配置文件中运行,在2台主机(peer1和peer2)上运行相同的服务器。您可以使用此配置来测试单个主机上的对等体感知(通过操作/etc/hosts来解析主机名,在生产中没有太多价值)。事实上,如果您在一台知道自己的主机名的机器上运行(默认情况下使用java.net.InetAddress查找),则不需要eureka.instance.hostname。
您可以向系统添加多个对等体,只要它们至少一个边缘彼此连接,则它们将在它们之间同步注册。如果对等体在物理上分离(在数据中心内或多个数据中心之间),则系统原则上可以分裂脑型故障。
喜欢IP地址
在某些情况下,Eureka优先发布服务的IP地址而不是主机名。将eureka.instance.preferIpAddress设置为true,并且当应用程序向eureka注册时,它将使用其IP地址而不是其主机名。
断路器:Hystrix客户端
Netflix的创造了一个调用的库Hystrix实现了断路器图案。在微服务架构中,通常有多层服务调用。
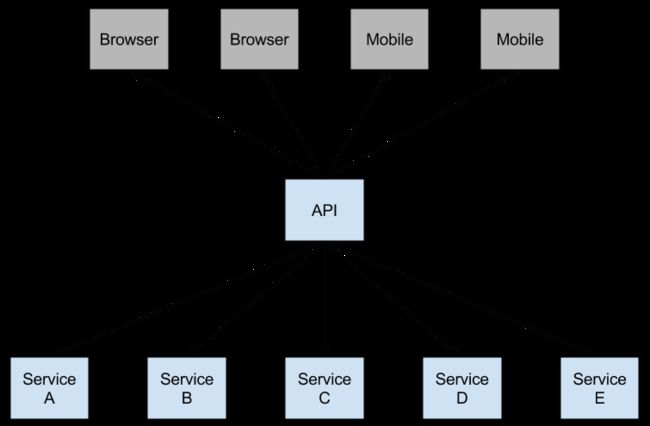
图1.微服务图
较低级别的服务中的服务故障可能导致用户级联故障。当对特定服务的呼叫达到一定阈值时(Hystrix中的默认值为5秒内的20次故障),电路打开,不进行通话。在错误和开路的情况下,开发人员可以提供后备。
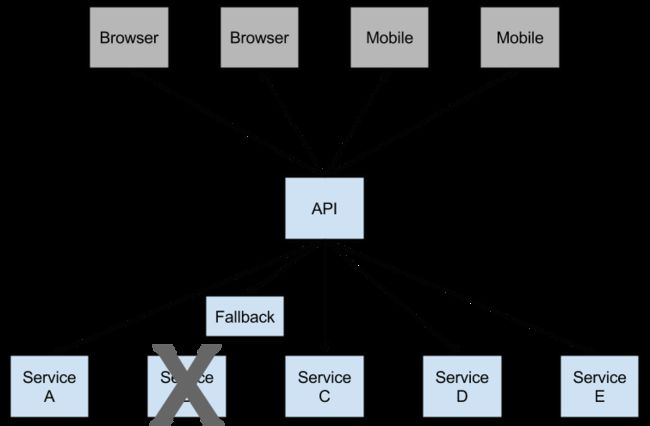
图2. Hystrix回退防止级联故障
开放式电路会停止级联故障,并允许不必要的或失败的服务时间来愈合。回退可以是另一个Hystrix保护的调用,静态数据或一个正常的空值。回退可能被链接,所以第一个回退使得一些其他业务电话又回到静态数据。
如何加入Hystrix
要在项目中包含Hystrix,请使用组org.springframework.cloud和artifact idspring-cloud-starter-hystrix的启动器。有关使用当前的Spring Cloud发布列表设置构建系统的详细信息,请参阅Spring Cloud项目页面。
示例启动应用程序:
@SpringBootApplication
@EnableCircuitBreaker
public class Application {
public static void main(String[] args) {
new SpringApplicationBuilder(Application.class).web(true).run(args);
}
}
@Component
public class StoreIntegration {
@HystrixCommand(fallbackMethod = "defaultStores")
public Object getStores(Map parameters) {
//do stuff that might fail
}
public Object defaultStores(Map parameters) {
return /* something useful */;
}
}
@HystrixCommand由名为“javanica”的Netflix contrib库提供。Spring Cloud在连接到Hystrix断路器的代理中使用该注释自动包装Spring bean。断路器计算何时打开和关闭电路,以及在发生故障时应该做什么。
要配置@HystrixCommand,您可以使用commandProperties属性列出@HystrixProperty注释。请参阅这里了解更多详情。有关可用属性的详细信息,请参阅Hystrix维基。
传播安全上下文或使用Spring范围
如果您希望某些线程本地上下文传播到@HystrixCommand,默认声明将不起作用,因为它在线程池中执行命令(超时)。您可以使用某些配置或直接在注释中使用与使用相同的线程来调用Hystrix,方法是要求使用不同的“隔离策略”。例如:
@HystrixCommand(fallbackMethod = "stubMyService",
commandProperties = {
@HystrixProperty(name="execution.isolation.strategy", value="SEMAPHORE")
}
)
...
如果您使用@SessionScope或@RequestScope,同样的事情也适用。您将知道何时需要执行此操作,因为运行时异常说它找不到范围的上下文。
您还可以将hystrix.shareSecurityContext属性设置为true。这样做会自动配置一个Hystrix并发策略插件钩子,他将SecurityContext从主线程传送到Hystrix命令使用的钩子。Hystrix不允许注册多个hystrix并发策略,因此可以通过将自己的HystrixConcurrencyStrategy声明为Spring bean来实现扩展机制。Spring Cloud将在Spring上下文中查找您的实现,并将其包装在自己的插件中。
健康指标
连接断路器的状态也暴露在呼叫应用程序的/health端点中。
{
"hystrix": {
"openCircuitBreakers": [
"StoreIntegration::getStoresByLocationLink"
],
"status": "CIRCUIT_OPEN"
},
"status": "UP"
}
Hystrix指标流
要使Hystrix指标流包含对spring-boot-starter-actuator的依赖。这将使/hystrix.stream作为管理端点。
org.springframework.boot
spring-boot-starter-actuator
断路器:Hystrix仪表板
Hystrix的主要优点之一是它收集关于每个HystrixCommand的一套指标。Hystrix仪表板以有效的方式显示每个断路器的运行状况。
图3. Hystrix仪表板
Hystrix超时和Ribbon客户
当使用包含Ribbon客户端的Hystrix命令时,您需要确保您的Hystrix超时配置为长于配置的Ribbon超时,包括可能进行的任何潜在的重试。例如,如果您的Ribbon连接超时为一秒钟,并且Ribbon客户端可能会重试该请求三次,那么您的Hystrix超时应该略超过三秒钟。
如何包含Hystrix仪表板
要在项目中包含Hystrix仪表板,请使用组org.springframework.cloud和工件IDspring-cloud-starter-hystrix-dashboard的启动器。有关使用当前的Spring Cloud发布列表设置构建系统的详细信息,请参阅Spring Cloud项目页面。
要运行Hystrix仪表板使用@EnableHystrixDashboard注释您的Spring Boot主类。然后访问/hystrix,并将仪表板指向Hystrix客户端应用程序中的单个实例/hystrix.stream端点。
Turbine
从个人实例看,Hystrix数据在系统整体健康方面不是非常有用。Turbine是将所有相关/hystrix.stream端点聚合到Hystrix仪表板中使用的/turbine.stream的应用程序。个人实例位于Eureka。运行Turbine就像使用@EnableTurbine注释(例如使用spring-cloud-starter-turbine设置类路径)注释主类一样简单。来自Turbine 1维基的所有文档配置属性都适用。唯一的区别是turbine.instanceUrlSuffix不需要预先添加的端口,除非turbine.instanceInsertPort=false自动处理。
注意
默认情况下,Turbine通过在Eureka中查找其homePageUrl条目,然后将/hystrix.stream附加到注册的实例上查找/hystrix.stream端点。这意味着如果spring-boot-actuator在自己的端口上运行(这是默认值),则对/hystrix.stream的调用将失败。要使涡轮机找到正确端口的Hystrix流,您需要向实例的元数据中添加management.port:
eureka:
instance:
metadata-map:
management.port: ${management.port:8081}
配置密钥turbine.appConfig是涡轮机将用于查找实例的尤里卡服务列表。涡轮流然后在Hystrix仪表板中使用如下URL:http://my.turbine.sever:8080/turbine.stream?cluster=;(如果名称为“默认值”,则可以省略群集参数)。cluster参数必须与turbine.aggregator.clusterConfig中的条目相匹配。从eureka返回的值是大写字母,因此如果有一个名为“customers”的Eureka注册了一个应用程序,我们预计此示例可以正常工作:
turbine:
aggregator:
clusterConfig: CUSTOMERS
appConfig: customers
clusterName可以通过turbine.clusterNameExpression中的SPEL表达式以root身份InstanceInfo进行自定义。默认值为appName,这意味着Eureka serviceId最终作为集群密钥(即客户的InstanceInfo具有appName“CUSTOMERS”)。一个不同的例子是turbine.clusterNameExpression=aSGName,它将从AWS ASG名称获取集群名称。另一个例子:
turbine:
aggregator:
clusterConfig: SYSTEM,USER
appConfig: customers,stores,ui,admin
clusterNameExpression: metadata['cluster']
在这种情况下,来自4个服务的集群名称从其元数据映射中提取,并且预期具有包含“SYSTEM”和“USER”的值。
要为所有应用程序使用“默认”集群,您需要一个字符串文字表达式(带单引号,并且如果它在YAML中也使用双引号进行转义):
turbine:
appConfig: customers,stores
clusterNameExpression: "'default'"
Spring Cloud提供了一个spring-cloud-starter-turbine,它具有运行Turbine服务器所需的所有依赖关系。只需创建一个Spring Boot应用程序并用@EnableTurbine注释它。
注意
默认情况下,Spring Cloud允许Turbine使用主机和端口允许每个主机在每个群集中进行多个进程。如果你想建成Turbine本地Netflix的行为,它不会允许每个主机上的多个过程,每簇(关键实例ID是主机名),然后将该属性设置turbine.combineHostPort=false。
Turbine Stream
在某些环境中(例如,在PaaS设置中),从所有分布式Hystrix命令中提取度量的经典Turbine模型不起作用。在这种情况下,您可能希望让Hystrix命令将度量标准推送到Turbine,并且Spring Cloud可以使用消息传递。您需要在客户端上执行的所有操作都为您选择的spring-cloud-netflix-hystrix-stream和spring-cloud-starter-stream-*添加依赖关系(有关经纪人的详细信息,请参阅Spring Cloud Stream文档,以及如何配置客户端凭据,但是应该为当地经纪人开箱即用)。
在服务器端只需创建一个Spring Boot应用程序并使用@EnableTurbineStream进行注释,默认情况下将在8989端口(将您的Hystrix仪表板指向该端口,任何路径)。您可以使用server.port或turbine.stream.port自定义端口。如果类路径中还有spring-boot-starter-web和spring-boot-starter-actuator,那么您可以通过提供不同的management.port在单独端口(默认情况下使用Tomcat)打开Actuator端点。
然后,您可以将Hystrix仪表板指向Turbine Stream服务器,而不是单个Hystrix流。如果Turbine Stream在myhost上的端口8989上运行,则将http://myhost:8989放在Hystrix仪表板中的流输入字段中。电路将以各自的serviceId为前缀,后跟一个点,然后是电路名称。
Spring Cloud提供了一个spring-cloud-starter-turbine-stream,它具有您需要的Turbine Stream服务器运行所需的所有依赖项,只需添加您选择的Stream binder,例如spring-cloud-starter-stream-rabbit。您需要Java 8来运行应用程序,因为它是基于Netty的。
客户端负载平衡器:Ribbon
Ribbon是一个客户端负载均衡器,它可以很好地控制HTTP和TCP客户端的行为。Feign已经使用Ribbon,所以如果您使用@FeignClient,则本节也适用。
Ribbon中的中心概念是指定客户端的概念。每个负载平衡器是组合的组合的一部分,它们一起工作以根据需要联系远程服务器,并且集合具有您将其作为应用程序开发人员(例如使用@FeignClient注释)的名称。Spring Cloud使用RibbonClientConfiguration为每个命名的客户端根据需要创建一个新的合奏作为ApplicationContext。这包含(除其他外)ILoadBalancer,RestClient和ServerListFilter。
如何加入Ribbon
要在项目中包含Ribbon,请使用组org.springframework.cloud和工件IDspring-cloud-starter-ribbon的起始器。有关使用当前的Spring Cloud发布列表设置构建系统的详细信息,请参阅Spring Cloud项目页面。
自定义Ribbon客户端
您可以使用.ribbon.*中的外部属性来配置Ribbon客户端的某些位,这与使用Netflix API本身没有什么不同,只能使用Spring Boot配置文件。本机选项可以在CommonClientConfigKey(功能区内核心部分)中作为静态字段进行检查。
Spring Cloud还允许您通过使用@RibbonClient声明其他配置(位于RibbonClientConfiguration之上)来完全控制客户端。例:
@Configuration
@RibbonClient(name = "foo", configuration = FooConfiguration.class)
public class TestConfiguration {
}
在这种情况下,客户端由RibbonClientConfiguration中已经存在的组件与FooConfiguration中的任何组件组成(后者通常会覆盖前者)。
警告
FooConfiguration必须是@Configuration,但请注意,它不在主应用程序上下文的@ComponentScan中,否则将由所有@RibbonClients共享。如果您使用@ComponentScan(或@SpringBootApplication),则需要采取措施避免包含(例如将其放在一个单独的,不重叠的包中,或者指定要在@ComponentScan)。
Spring Cloud Netflix默认情况下为Ribbon(BeanTypebeanName:ClassName)提供以下bean:
IClientConfigribbonClientConfig:DefaultClientConfigImpl
IRuleribbonRule:ZoneAvoidanceRule
IPingribbonPing:NoOpPing
ServerListribbonServerList:ConfigurationBasedServerList
ServerListFilterribbonServerListFilter:ZonePreferenceServerListFilter
ILoadBalancerribbonLoadBalancer:ZoneAwareLoadBalancer
ServerListUpdaterribbonServerListUpdater:PollingServerListUpdater
创建一个类型的bean并将其放置在@RibbonClient配置(例如上面的FooConfiguration)中)允许您覆盖所描述的每个bean。例:
@Configuration
public class FooConfiguration {
@Bean
public IPing ribbonPing(IClientConfig config) {
return new PingUrl();
}
}
这用PingUrl代替NoOpPing。
使用属性自定义Ribbon客户端
从版本1.2.0开始,Spring Cloud Netflix现在支持使用属性与Ribbon文档兼容来自定义Ribbon客户端。
这允许您在不同环境中更改启动时的行为。
支持的属性如下所示,应以.ribbon.为前缀:
NFLoadBalancerClassName:应实施ILoadBalancer
NFLoadBalancerRuleClassName:应实施IRule
NFLoadBalancerPingClassName:应实施IPing
NIWSServerListClassName:应实施ServerList
NIWSServerListFilterClassName应实施ServerListFilter
注意
在这些属性中定义的类优先于使用@RibbonClient(configuration=MyRibbonConfig.class)定义的bean和由Spring Cloud Netflix提供的默认值。
要设置服务名称users的IRule,您可以设置以下内容:
application.yml
users:
ribbon:
NFLoadBalancerRuleClassName: com.netflix.loadbalancer.WeightedResponseTimeRule
有关Ribbon提供的实现,请参阅Ribbon文档。
在Eureka中使用Ribbon
当Eureka与Ribbon结合使用(即两者都在类路径上)时,ribbonServerList将被扩展为DiscoveryEnabledNIWSServerList,扩展名为Eureka的服务器列表。它还用NIWSDiscoveryPing替换IPing接口,代理到Eureka以确定服务器是否启动。默认情况下安装的ServerList是一个DomainExtractingServerList,其目的是使物理元数据可用于负载平衡器,而不使用AWS AMI元数据(这是Netflix依赖的)。默认情况下,服务器列表将使用实例元数据(如远程客户端集合eureka.instance.metadataMap.zone)中提供的“区域”信息构建,如果缺少,则可以使用服务器主机名中的域名作为代理用于区域(如果设置了标志approximateZoneFromHostname)。一旦区域信息可用,它可以在ServerListFilter中使用。默认情况下,它将用于定位与客户端相同区域的服务器,因为默认值为ZonePreferenceServerListFilter。默认情况下,客户端的区域与远程实例的方式相同,即通过eureka.instance.metadataMap.zone。
注意
设置客户端区域的正统“archaius”方式是通过一个名为“@zone”的配置属性,如果可用,Spring Cloud将优先使用所有其他设置(请注意,该键必须被引用)在YAML配置中)。
注意
如果没有其他的区域数据源,则基于客户端配置(与实例配置相反)进行猜测。我们将eureka.client.availabilityZones(从区域名称映射到区域列表),并将实例自己的区域的第一个区域(即eureka.client.region,其默认为“us-east-1”为与本机Netflix的兼容性)。
示例:如何使用Ribbon不使用Eureka
Eureka是一种方便的方式来抽象远程服务器的发现,因此您不必在客户端中对其URL进行硬编码,但如果您不想使用它,Ribbon和Feign仍然是适用的。假设您已经为“商店”申请了@RibbonClient,并且Eureka未被使用(甚至不在类路径上)。Ribbon客户端默认为已配置的服务器列表,您可以提供这样的配置
application.yml
stores:
ribbon:
listOfServers: example.com,google.com
示例:在Ribbon中禁用Eureka使用
设置属性ribbon.eureka.enabled = false将明确禁用在Ribbon中使用Eureka。
application.yml
ribbon:
eureka:
enabled: false
直接使用Ribbon API
您也可以直接使用LoadBalancerClient。例:
public class MyClass {
@Autowired
private LoadBalancerClient loadBalancer;
public void doStuff() {
ServiceInstance instance = loadBalancer.choose("stores");
URI storesUri = URI.create(String.format("http://%s:%s", instance.getHost(), instance.getPort()));
// ... do something with the URI
}
}
缓存Ribbon配置
每个Ribbon命名的客户端都有一个相应的子应用程序上下文,Spring Cloud维护,这个应用程序上下文在第一个请求中被延迟加载到命名的客户端。可以通过指定Ribbon客户端的名称,在启动时,可以更改此延迟加载行为,从而热切加载这些子应用程序上下文。
application.yml
ribbon:
eager-load:
enabled: true
clients: client1, client2, client3
声明性REST客户端:Feign
Feign是一个声明式的Web服务客户端。这使得Web服务客户端的写入更加方便要使用Feign创建一个界面并对其进行注释。它具有可插入注释支持,包括Feign注释和JAX-RS注释。Feign还支持可插拔编码器和解码器。Spring Cloud增加了对Spring MVC注释的支持,并使用Spring Web中默认使用的HttpMessageConverters。Spring Cloud集成Ribbon和Eureka以在使用Feign时提供负载均衡的http客户端。
如何加入Feign
要在您的项目中包含Feign,请使用组org.springframework.cloud和工件IDspring-cloud-starter-feign的启动器。有关使用当前的Spring Cloud发布列表设置构建系统的详细信息,请参阅Spring Cloud项目页面。
示例spring boot应用
@Configuration
@ComponentScan
@EnableAutoConfiguration
@EnableEurekaClient
@EnableFeignClients
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}
StoreClient.java
@FeignClient("stores")
public interface StoreClient {
@RequestMapping(method = RequestMethod.GET, value = "/stores")
List getStores();
@RequestMapping(method = RequestMethod.POST, value = "/stores/{storeId}", consumes = "application/json")
Store update(@PathVariable("storeId") Long storeId, Store store);
}
在@FeignClient注释中,String值(以上“存储”)是一个任意的客户端名称,用于创建Ribbon负载平衡器(有关Ribbon支持的详细信息,请参阅下文))。您还可以使用url属性(绝对值或只是主机名)指定URL。应用程序上下文中的bean的名称是该接口的完全限定名称。要指定您自己的别名值,您可以使用@FeignClient注释的qualifier值。
以上的Ribbon客户端将会发现“商店”服务的物理地址。如果您的应用程序是Eureka客户端,那么它将解析Eureka服务注册表中的服务。如果您不想使用Eureka,您可以简单地配置外部配置中的服务器列表(例如,参见上文)。
覆盖Feign默认值
Spring Cloud的Feign支持的中心概念是指定的客户端。每个假装客户端都是组合的组件的一部分,它们一起工作以根据需要联系远程服务器,并且该集合具有您将其作为应用程序开发人员使用@FeignClient注释的名称。Spring Cloud根据需要,使用FeignClientsConfiguration为每个已命名的客户端创建一个新的集合ApplicationContext。这包含(除其他外)feign.Decoder,feign.Encoder和feign.Contract。
Spring Cloud可以通过使用@FeignClient声明额外的配置(FeignClientsConfiguration)来完全控制假客户端。例:
@FeignClient(name = "stores", configuration = FooConfiguration.class)
public interface StoreClient {
//..
}
在这种情况下,客户端由FeignClientsConfiguration中的组件与FooConfiguration中的任何组件组成(后者将覆盖前者)。
注意
FooConfiguration不需要使用@Configuration注释。但是,如果是,则请注意将其从任何@ComponentScan中排除,否则将包含此配置,因为它将成为feign.Decoder,feign.Encoder,feign.Contract等的默认来源,指定时。这可以通过将其放置在任何@ComponentScan或@SpringBootApplication的单独的不重叠的包中,或者可以在@ComponentScan中明确排除。
注意
serviceId属性现在已被弃用,有利于name属性。
警告
以前,使用url属性,不需要name属性。现在需要使用name。
name和url属性支持占位符。
@FeignClient(name = "${feign.name}", url = "${feign.url}")
public interface StoreClient {
//..
}
Spring Cloud Netflix默认为feign(BeanTypebeanName:ClassName)提供以下bean:
DecoderfeignDecoder:ResponseEntityDecoder(其中包含SpringDecoder)
EncoderfeignEncoder:SpringEncoder
LoggerfeignLogger:Slf4jLogger
ContractfeignContract:SpringMvcContract
Feign.BuilderfeignBuilder:HystrixFeign.Builder
ClientfeignClient:如果Ribbon启用,则为LoadBalancerFeignClient,否则将使用默认的feign客户端。
可以通过将feign.okhttp.enabled或feign.httpclient.enabled设置为true,并将它们放在类路径上来使用OkHttpClient和ApacheHttpClient feign客户端。
Spring Cloud Netflix默认情况下不提供以下bean,但是仍然从应用程序上下文中查找这些类型的bean以创建假客户机:
Logger.Level
Retryer
ErrorDecoder
Request.Options
Collection
SetterFactory
创建一个类型的bean并将其放置在@FeignClient配置(例如上面的FooConfiguration)中)允许您覆盖所描述的每个bean。例:
@Configuration
public class FooConfiguration {
@Bean
public Contract feignContract() {
return new feign.Contract.Default();
}
@Bean
public BasicAuthRequestInterceptor basicAuthRequestInterceptor() {
return new BasicAuthRequestInterceptor("user", "password");
}
}
这将SpringMvcContract替换为feign.Contract.Default,并将RequestInterceptor添加到RequestInterceptor的集合中。
可以在@EnableFeignClients属性defaultConfiguration中以与上述相似的方式指定默认配置。不同之处在于,此配置将适用于所有假客户端。
注意
如果您需要在RequestInterceptor`s you will need to either set the thread isolation strategy for Hystrix to `SEMAPHORE中使用ThreadLocal绑定变量,或在Feign中禁用Hystrix。
application.yml
# To disable Hystrix in Feign
feign:
hystrix:
enabled: false
# To set thread isolation to SEMAPHORE
hystrix:
command:
default:
execution:
isolation:
strategy: SEMAPHORE
手动创建Feign客户端
在某些情况下,可能需要以上述方法不可能自定义您的Feign客户端。在这种情况下,您可以使用Feign Builder API创建客户端。下面是一个创建两个具有相同接口的Feign客户端的示例,但是使用单独的请求拦截器配置每个客户端。
@Import(FeignClientsConfiguration.class)
class FooController {
private FooClient fooClient;
private FooClient adminClient;
@Autowired
public FooController(
Decoder decoder, Encoder encoder, Client client) {
this.fooClient = Feign.builder().client(client)
.encoder(encoder)
.decoder(decoder)
.requestInterceptor(new BasicAuthRequestInterceptor("user", "user"))
.target(FooClient.class, "http://PROD-SVC");
this.adminClient = Feign.builder().client(client)
.encoder(encoder)
.decoder(decoder)
.requestInterceptor(new BasicAuthRequestInterceptor("admin", "admin"))
.target(FooClient.class, "http://PROD-SVC");
}
}
注意
在上面的例子中,FeignClientsConfiguration.class是Spring Cloud Netflix提供的默认配置。
注意
PROD-SVC是客户端将要求的服务的名称。
Feign Hystrix支持
如果Hystrix在类路径上,feign.hystrix.enabled=true,Feign将用断路器包装所有方法。还可以返回com.netflix.hystrix.HystrixCommand。这样就可以使用无效模式(调用.toObservable()或.observe()或异步使用(调用.queue()))。
要在每个客户端基础上禁用Hystrix支持创建一个带有“原型”范围的香草Feign.Builder,例如:
@Configuration
public class FooConfiguration {
@Bean
@Scope("prototype")
public Feign.Builder feignBuilder() {
return Feign.builder();
}
}
警告
在Spring Cloud达尔斯顿发布之前,如果Hystrix在类路径Feign中默认将所有方法包装在断路器中。这种默认行为在Spring Cloud达尔斯顿改变了赞成选择加入的方式。
Feign Hystrix回退
Hystrix支持回退的概念:当电路断开或出现错误时执行的默认代码路径。要为给定的@FeignClient启用回退,请将fallback属性设置为实现回退的类名。
@FeignClient(name = "hello", fallback = HystrixClientFallback.class)
protected interface HystrixClient {
@RequestMapping(method = RequestMethod.GET, value = "/hello")
Hello iFailSometimes();
}
static class HystrixClientFallback implements HystrixClient {
@Override
public Hello iFailSometimes() {
return new Hello("fallback");
}
}
如果需要访问导致回退触发的原因,可以使用@FeignClient内的fallbackFactory属性。
@FeignClient(name = "hello", fallbackFactory = HystrixClientFallbackFactory.class)
protected interface HystrixClient {
@RequestMapping(method = RequestMethod.GET, value = "/hello")
Hello iFailSometimes();
}
@Component
static class HystrixClientFallbackFactory implements FallbackFactory {
@Override
public HystrixClient create(Throwable cause) {
return new HystrixClientWithFallBackFactory() {
@Override
public Hello iFailSometimes() {
return new Hello("fallback; reason was: " + cause.getMessage());
}
};
}
}
警告
在Feign中执行回退以及Hystrix回退的工作方式存在局限性。当前返回com.netflix.hystrix.HystrixCommand和rx.Observable的方法目前不支持回退。
Feign和@Primary
当使用Feign与Hystrix回退时,在同一类型的ApplicationContext中有多个bean。这将导致@Autowired不起作用,因为没有一个bean,或者标记为主。要解决这个问题,Spring Cloud Netflix将所有Feign实例标记为@Primary,所以Spring Framework将知道要注入哪个bean。在某些情况下,这可能是不可取的。要关闭此行为,将@FeignClient的primary属性设置为false。
@FeignClient(name = "hello", primary = false)
public interface HelloClient {
// methods here
}
Feign继承支持
Feign通过单继承接口支持样板apis。这样就可以将常用操作分成方便的基本界面。
UserService.java
public interface UserService {
@RequestMapping(method = RequestMethod.GET, value ="/users/{id}")
User getUser(@PathVariable("id") long id);
}
UserResource.java
@RestController
public class UserResource implements UserService {
}
UserClient.java
package project.user;
@FeignClient("users")
public interface UserClient extends UserService {
}
注意
通常不建议在服务器和客户端之间共享接口。它引入了紧耦合,并且实际上并不适用于当前形式的Spring MVC(方法参数映射不被继承)。
Feign请求/响应压缩
您可以考虑为Feign请求启用请求或响应GZIP压缩。您可以通过启用其中一个属性来执行此操作:
feign.compression.request.enabled=true
feign.compression.response.enabled=true
Feign请求压缩为您提供与您为Web服务器设置的设置相似的设置:
feign.compression.request.enabled=true
feign.compression.request.mime-types=text/xml,application/xml,application/json
feign.compression.request.min-request-size=2048
这些属性可以让您对压缩介质类型和最小请求阈值长度有选择性。
Feign日志记录
为每个创建的Feign客户端创建一个记录器。默认情况下,记录器的名称是用于创建Feign客户端的接口的完整类名。Feign日志记录仅响应DEBUG级别。
application.yml
logging.level.project.user.UserClient: DEBUG
您可以为每个客户端配置的Logger.Level对象告诉Feign记录多少。选择是:
NONE,无记录(DEFAULT)。
BASIC,只记录请求方法和URL以及响应状态代码和执行时间。
HEADERS,记录基本信息以及请求和响应标头。
FULL,记录请求和响应的头文件,正文和元数据。
例如,以下将Logger.Level设置为FULL:
@Configuration
public class FooConfiguration {
@Bean
Logger.Level feignLoggerLevel() {
return Logger.Level.FULL;
}
}
外部配置:Archaius
Netflix客户端配置库Archaius它是所有Netflix OSS组件用于配置的库。Archaius是Apache Commons Configuration项目的扩展。它允许通过轮询源进行更改或将源更改推送到客户端来进行配置更新。Archaius使用Dynamic Property类作为属性的句柄。
Archaius示例
class ArchaiusTest {
DynamicStringProperty myprop = DynamicPropertyFactory
.getInstance()
.getStringProperty("my.prop");
void doSomething() {
OtherClass.someMethod(myprop.get());
}
}
Archaius具有自己的一组配置文件和加载优先级。Spring应用程序一般不应直接使用Archaius,但本地仍然需要配置Netflix工具。Spring Cloud具有Spring环境桥,所以Archaius可以从Spring环境读取属性。这允许Spring Boot项目使用正常的配置工具链,同时允许他们在文档中大部分配置Netflix工具。
路由器和过滤器:Zuul
路由在微服务体系结构的一个组成部分。例如,/可以映射到您的Web应用程序,/api/users映射到用户服务,并将/api/shop映射到商店服务。Zuul是Netflix的基于JVM的路由器和服务器端负载均衡器。
Netflix使用Zuul进行以下操作:
认证
洞察
压力测试
金丝雀测试
动态路由
服务迁移
负载脱落
安全
静态响应处理
主动/主动流量管理
Zuul的规则引擎允许基本上写任何JVM语言编写规则和过滤器,内置Java和Groovy。
注意
配置属性zuul.max.host.connections已被两个新属性zuul.host.maxTotalConnections和zuul.host.maxPerRouteConnections替换,分别默认为200和20。
注意
所有路由的默认Hystrix隔离模式(ExecutionIsolationStrategy)为SEMAPHORE。如果此隔离模式是首选,则zuul.ribbonIsolationStrategy可以更改为THREAD。
如何加入Zuul
要在您的项目中包含Zuul,请使用组org.springframework.cloud和artifact idspring-cloud-starter-zuul的启动器。有关使用当前的Spring Cloud发布列表设置构建系统的详细信息,请参阅Spring Cloud项目页面。
嵌入式Zuul反向代理
Spring Cloud已经创建了一个嵌入式Zuul代理,以简化UI应用程序想要代理对一个或多个后端服务的呼叫的非常常见的用例的开发。此功能对于用户界面对其所需的后端服务进行代理是有用的,避免了对所有后端独立管理CORS和验证问题的需求。
要启用它,使用@EnableZuulProxy注释Spring Boot主类,并将本地调用转发到相应的服务。按照惯例,具有ID“用户”的服务将接收来自位于/users(具有前缀stripped)的代理的请求。代理使用Ribbon来定位一个通过发现转发的实例,并且所有请求都以hystrix命令执行,所以故障将显示在Hystrix指标中,一旦电路打开,代理将不会尝试联系服务。
注意
Zuul启动器不包括发现客户端,因此对于基于服务ID的路由,您还需要在类路径中提供其中一个路由(例如Eureka)。
要跳过自动添加的服务,请将zuul.ignored-services设置为服务标识模式列表。如果一个服务匹配一个被忽略的模式,而且包含在明确配置的路由映射中,那么它将被无符号。例:
application.yml
zuul:
ignoredServices: '*'
routes:
users: /myusers/**
在此示例中,除“用户”之外,所有服务都被忽略。
要扩充或更改代理路由,可以添加如下所示的外部配置:
application.yml
zuul:
routes:
users: /myusers/**
这意味着对“/ myusers”的http呼叫转发到“用户”服务(例如“/ myusers / 101”转发到“/ 101”)。
要获得对路由的更细粒度的控制,您可以独立地指定路径和serviceId:
application.yml
zuul:
routes:
users:
path: /myusers/**
serviceId: users_service
这意味着对“/ myusers”的http呼叫转发到“users_service”服务。路由必须有一个“路径”,可以指定为蚂蚁样式模式,所以“/ myusers / *”只匹配一个级别,但“/ myusers / **”分层匹配。
后端的位置可以被指定为“serviceId”(用于发现的服务)或“url”(对于物理位置),例如
application.yml
zuul:
routes:
users:
path: /myusers/**
url: http://example.com/users_service
这些简单的URL路由不会被执行为HystrixCommand,也不能使用Ribbon对多个URL进行负载平衡。为此,请指定service-route并为serviceId配置Ribbon客户端(目前需要在Ribbon中禁用Eureka支持:详见上文),例如
application.yml
zuul:
routes:
users:
path: /myusers/**
serviceId: users
ribbon:
eureka:
enabled: false
users:
ribbon:
listOfServers: example.com,google.com
您可以使用regexmapper在serviceId和路由之间提供约定。它使用名为group的正则表达式从serviceId中提取变量并将它们注入到路由模式中。
ApplicationConfiguration.java
@Bean
public PatternServiceRouteMapper serviceRouteMapper() {
return new PatternServiceRouteMapper(
"(?^.+)-(?v.+$)",
"${version}/${name}");
}
这意味着serviceId“myusers-v1”将被映射到路由“/ v1 / myusers / **”。任何正则表达式都被接受,但所有命名组都必须存在于servicePattern和routePattern中。如果servicePattern与serviceId不匹配,则使用默认行为。在上面的示例中,serviceId“myusers”将被映射到路由“/ myusers / **”(检测不到版本)此功能默认禁用,仅适用于已发现的服务。
要为所有映射添加前缀,请将zuul.prefix设置为一个值,例如/api。默认情况下,请求被转发之前,代理前缀被删除(使用zuul.stripPrefix=false关闭此行为)。您还可以关闭从各路线剥离服务特定的前缀,例如
application.yml
zuul:
routes:
users:
path: /myusers/**
stripPrefix: false
注意
zuul.stripPrefix仅适用于zuul.prefix中设置的前缀。它对给定路由path中定义的前缀有影响。
在本示例中,对“/ myusers / 101”的请求将转发到“/ myusers / 101”上的“users”服务。
zuul.routes条目实际上绑定到类型为ZuulProperties的对象。如果您查看该对象的属性,您将看到它还具有“可重试”标志。将该标志设置为“true”使Ribbon客户端自动重试失败的请求(如果需要,可以使用Ribbon客户端配置修改重试操作的参数)。
默认情况下,将X-Forwarded-Host标头添加到转发的请求中。关闭setzuul.addProxyHeaders = false。默认情况下,前缀路径被删除,对后端的请求会拾取一个标题“X-Forwarded-Prefix”(上述示例中的“/ myusers”)。
如果您设置默认路由(“/”),则@EnableZuulProxy的应用程序可以作为独立服务器,例如zuul.route.home: /将路由所有流量(即“/ **”)到“home”服务。
如果需要更细粒度的忽略,可以指定要忽略的特定模式。在路由位置处理开始时评估这些模式,这意味着前缀应包含在模式中以保证匹配。忽略的模式跨越所有服务,并取代任何其他路由规范。
application.yml
zuul:
ignoredPatterns: /**/admin/**
routes:
users: /myusers/**
这意味着诸如“/ myusers / 101”的所有呼叫将被转发到“用户”服务上的“/ 101”。但是包含“/ admin /”的呼叫将无法解决。
警告
如果您需要您的路由保留订单,则需要使用YAML文件,因为使用属性文件将会丢失订购。例如:
application.yml
zuul:
routes:
users:
path: /myusers/**
legacy:
path: /**
如果要使用属性文件,则legacy路径可能会在users路径前面展开,从而使users路径不可达。
Zuul Http客户端
zuul使用的默认HTTP客户端现在由Apache HTTP Client支持,而不是不推荐使用的RibbonRestClient。要分别使用RestClient或使用okhttp3.OkHttpClient集合ribbon.restclient.enabled=true或ribbon.okhttp.enabled=true。
Cookie和敏感标题
在同一个系统中的服务之间共享标题是可行的,但是您可能不希望敏感标头泄漏到外部服务器的下游。您可以在路由配置中指定被忽略头文件列表。Cookies起着特殊的作用,因为它们在浏览器中具有明确的语义,并且它们总是被视为敏感的。如果代理的消费者是浏览器,则下游服务的cookie也会导致用户出现问题,因为它们都被混淆(所有下游服务看起来都是来自同一个地方)。
如果您对服务的设计非常谨慎,例如,如果只有一个下游服务设置了Cookie,那么您可能可以让他们从后台一直到调用者。另外,如果您的代理设置cookie和所有后台服务都是同一系统的一部分,那么简单地共享它们就可以自然(例如使用Spring Session将它们链接到一些共享状态)。除此之外,由下游服务设置的任何Cookie可能对呼叫者来说都不是很有用,因此建议您将(至少)“Set-Cookie”和“Cookie”设置为不属于您的域名。即使是属于您域名的路线,请尝试仔细考虑允许Cookie在代理之间流动的含义。
灵敏头可以配置为每个路由的逗号分隔列表,例如
application.yml
zuul:
routes:
users:
path: /myusers/**
sensitiveHeaders: Cookie,Set-Cookie,Authorization
url: https://downstream
注意
这是sensitiveHeaders的默认值,因此您不需要设置它,除非您希望它不同。注意这是Spring Cloud Netflix 1.1中的新功能(1.0中,用户无法控制标题,所有Cookie都在两个方向上流动)。
sensitiveHeaders是一个黑名单,默认值不为空,所以要使Zuul发送所有标题(“被忽略”除外),您必须将其显式设置为空列表。如果您要将Cookie或授权标头传递到后端,这是必要的。例:
application.yml
zuul:
routes:
users:
path: /myusers/**
sensitiveHeaders:
url: https://downstream
也可以通过设置zuul.sensitiveHeaders来全局设置敏感标题。如果在路由上设置sensitiveHeaders,则将覆盖全局sensitiveHeaders设置。
被忽略的标题
除了每个路由的敏感标头,您还可以为与下游服务交互期间应该丢弃的值(请求和响应)设置全局值为zuul.ignoredHeaders。默认情况下,如果Spring安全性不在类路径上,则它们是空的,否则它们被初始化为由Spring Security指定的一组众所周知的“安全性”头(例如涉及缓存)。在这种情况下的假设是下游服务可能也添加这些头,我们希望代理的值。为了不丢弃这些众所周知的安全标头,只要Spring安全性在类路径上,您可以将zuul.ignoreSecurityHeaders设置为false。如果您禁用Spring安全性中的HTTP安全性响应头,并希望由下游服务提供的值,这可能很有用
路线端点
如果您在Spring Boot执行器中使用@EnableZuulProxy,您将启用(默认情况下)另一个端点,通过HTTP可用/routes。到此端点的GET将返回映射路由的列表。POST将强制刷新现有路由(例如,如果服务目录中有更改)。您可以通过将endpoints.routes.enabled设置为false来禁用此端点。
注意
路由应自动响应服务目录中的更改,但POST到/路由是强制更改立即发生的一种方式。
扼杀模式和本地前进
迁移现有应用程序或API时的常见模式是“扼杀”旧端点,用不同的实现慢慢替换它们。Zuul代理是一个有用的工具,因为您可以使用它来处理来自旧端点的客户端的所有流量,但将一些请求重定向到新端点。
示例配置:
application.yml
zuul:
routes:
first:
path: /first/**
url: http://first.example.com
second:
path: /second/**
url: forward:/second
third:
path: /third/**
url: forward:/3rd
legacy:
path: /**
url: http://legacy.example.com
在这个例子中,我们扼杀了“遗留”应用程序,该应用程序映射到所有与其他模式不匹配的请求。/first/**中的路径已被提取到具有外部URL的新服务中。并且/second/**中的路径被转发,以便它们可以在本地处理,例如具有正常的Spring@RequestMapping。/third/**中的路径也被转发,但具有不同的前缀(即/third/foo转发到/3rd/foo)。
注意
被忽略的模式并不完全被忽略,它们只是不被代理处理(因此它们也被有效地转发到本地)。
通过Zuul上传文件
如果您@EnableZuulProxy您可以使用代理路径上传文件,只要文件很小,它就应该工作。对于大文件,有一个替代路径绕过“/ zuul / *”中的SpringDispatcherServlet(以避免多部分处理)。也就是说,如果zuul.routes.customers=/customers/**则可以将大文件发送到“/ zuul / customers / *”。servlet路径通过zuul.servletPath进行外部化。如果代理路由引导您通过Ribbon负载均衡器,例如,超大文件也将需要提升超时设置
application.yml
hystrix.command.default.execution.isolation.thread.timeoutInMilliseconds: 60000
ribbon:
ConnectTimeout: 3000
ReadTimeout: 60000
请注意,要使用大型文件进行流式传输,您需要在请求中使用分块编码(某些浏览器默认情况下不会执行)。例如在命令行:
$ curl -v -H "Transfer-Encoding: chunked" \
-F "[email protected]" localhost:9999/zuul/simple/file
查询字符串编码
处理传入的请求时,查询参数被解码,因此可以在Zuul过滤器中进行修改。然后在路由过滤器中构建后端请求时重新编码它们。如果使用Javascript的encodeURIComponent()方法编码,结果可能与原始输入不同。虽然这在大多数情况下不会出现任何问题,但一些Web服务器可以用复杂查询字符串的编码来挑选。
要强制查询字符串的原始编码,可以将特殊标志传递给ZuulProperties,以便查询字符串与HttpServletRequest::getQueryString方法相同:
application.yml
zuul:
forceOriginalQueryStringEncoding: true
注意:此特殊标志仅适用于SimpleHostRoutingFilter,您可以使用RequestContext.getCurrentContext().setRequestQueryParams(someOverriddenParameters)轻松覆盖查询参数,因为查询字符串现在直接在原始的HttpServletRequest上获取。
普通嵌入Zuul
如果您使用@EnableZuulServer(而不是@EnableZuulProxy),您也可以运行不带代理的Zuul服务器,或者有选择地切换代理平台的部分。您添加到ZuulFilter类型的应用程序的任何bean都将自动安装,与@EnableZuulProxy一样,但不会自动添加任何代理过滤器。
在这种情况下,仍然通过配置“zuul.routes。*”来指定进入Zuul服务器的路由,但没有服务发现和代理,所以“serviceId”和“url”设置将被忽略。例如:
application.yml
zuul:
routes:
api: /api/**
将“/ api / **”中的所有路径映射到Zuul过滤器链。
禁用Zuul过滤器
Spring Cloud的Zuul在代理和服务器模式下默认启用了多个ZuulFilterbean。有关启用的可能过滤器,请参阅zuul过滤器包。如果要禁用它,只需设置zuul...disable=true。按照惯例,filters之后的包是Zuul过滤器类型。例如,禁用org.springframework.cloud.netflix.zuul.filters.post.SendResponseFilter设置zuul.SendResponseFilter.post.disable=true。
为路线提供Hystrix回退
当Zuul中给定路由的电路跳闸时,您可以通过创建类型为ZuulFallbackProvider的bean来提供回退响应。在这个bean中,您需要指定回退的路由ID,并提供返回的ClientHttpResponse作为后备。这是一个非常简单的ZuulFallbackProvider实现。
class MyFallbackProvider implements ZuulFallbackProvider {
@Override
public String getRoute() {
return "customers";
}
@Override
public ClientHttpResponse fallbackResponse() {
return new ClientHttpResponse() {
@Override
public HttpStatus getStatusCode() throws IOException {
return HttpStatus.OK;
}
@Override
public int getRawStatusCode() throws IOException {
return 200;
}
@Override
public String getStatusText() throws IOException {
return "OK";
}
@Override
public void close() {
}
@Override
public InputStream getBody() throws IOException {
return new ByteArrayInputStream("fallback".getBytes());
}
@Override
public HttpHeaders getHeaders() {
HttpHeaders headers = new HttpHeaders();
headers.setContentType(MediaType.APPLICATION_JSON);
return headers;
}
};
}
}
这里是路由配置的样子。
zuul:
routes:
customers: /customers/**
如果您希望为所有路由提供默认的回退,您可以创建一个类型为ZuulFallbackProvider的bean,并且getRoute方法返回*或null。
class MyFallbackProvider implements ZuulFallbackProvider {
@Override
public String getRoute() {
return "*";
}
@Override
public ClientHttpResponse fallbackResponse() {
return new ClientHttpResponse() {
@Override
public HttpStatus getStatusCode() throws IOException {
return HttpStatus.OK;
}
@Override
public int getRawStatusCode() throws IOException {
return 200;
}
@Override
public String getStatusText() throws IOException {
return "OK";
}
@Override
public void close() {
}
@Override
public InputStream getBody() throws IOException {
return new ByteArrayInputStream("fallback".getBytes());
}
@Override
public HttpHeaders getHeaders() {
HttpHeaders headers = new HttpHeaders();
headers.setContentType(MediaType.APPLICATION_JSON);
return headers;
}
};
}
}
Zuul开发人员指南
有关Zuul如何工作的一般概述,请参阅Zuul维基。
Zuul Servlet
Zuul被实现为Servlet。对于一般情况,Zuul嵌入到Spring调度机制中。这允许Spring MVC控制路由。在这种情况下,Zuul被配置为缓冲请求。如果需要通过Zuul不缓冲请求(例如大文件上传),Servlet也将安装在Spring调度程序之外。默认情况下,它位于/zuul。可以使用zuul.servlet-path属性更改此路径。
Zuul RequestContext
要在过滤器之间传递信息,Zuul使用aRequestContext。其数据按照每个请求的ThreadLocal进行。关于路由请求,错误以及实际HttpServletRequest和HttpServletResponse的路由信息。RequestContext扩展ConcurrentHashMap,所以任何东西都可以存储在上下文中。FilterConstants包含由Spring Cloud Netflix安装的过滤器使用的密钥(稍后再安装)。
@EnableZuulProxy与@EnableZuulServer
Spring Cloud Netflix根据使用何种注释来启用Zuul安装多个过滤器。@EnableZuulProxy是@EnableZuulServer的超集。换句话说,@EnableZuulProxy包含@EnableZuulServer安装的所有过滤器。“代理”中的其他过滤器启用路由功能。如果你想要一个“空白”Zuul,你应该使用@EnableZuulServer。
@EnableZuulServer过滤器
创建从Spring Boot配置文件加载路由定义的SimpleRouteLocator。
安装了以下过滤器(正常Spring豆类):
前置过滤器
ServletDetectionFilter:检测请求是否通过Spring调度程序。使用键FilterConstants.IS_DISPATCHER_SERVLET_REQUEST_KEY设置布尔值。
FormBodyWrapperFilter:解析表单数据,并对下游请求进行重新编码。
DebugFilter:如果设置debug请求参数,则此过滤器将RequestContext.setDebugRouting()和RequestContext.setDebugRequest()设置为true。
路由过滤器
SendForwardFilter:此过滤器使用ServletRequestDispatcher转发请求。转发位置存储在RequestContext属性FilterConstants.FORWARD_TO_KEY中。这对于转发到当前应用程序中的端点很有用。
过滤器:
SendResponseFilter:将代理请求的响应写入当前响应。
错误过滤器:
SendErrorFilter:如果RequestContext.getThrowable()不为null,则转发到/错误(默认情况下)。可以通过设置error.path属性来更改默认转发路径(/error)。
@EnableZuulProxy过滤器
创建从DiscoveryClient(如Eureka)以及属性加载路由定义的DiscoveryClientRouteLocator。每个serviceId从DiscoveryClient创建路由。随着新服务的添加,路由将被刷新。
除了上述过滤器之外,还安装了以下过滤器(正常Spring豆类):
前置过滤器
PreDecorationFilter:此过滤器根据提供的RouteLocator确定在哪里和如何路由。它还为下游请求设置各种与代理相关的头。
路由过滤器
RibbonRoutingFilter:此过滤器使用Ribbon,Hystrix和可插拔HTTP客户端发送请求。服务ID位于RequestContext属性FilterConstants.SERVICE_ID_KEY中。此过滤器可以使用不同的HTTP客户端。他们是:
ApacheHttpClient。这是默认的客户端。
SquareupOkHttpClientv3。通过在类路径上设置com.squareup.okhttp3:okhttp库并设置ribbon.okhttp.enabled=true来启用此功能。
Netflix Ribbon HTTP客户端。这可以通过设置ribbon.restclient.enabled=true来启用。这个客户端有限制,比如它不支持PATCH方法,还有内置的重试。
SimpleHostRoutingFilter:此过滤器通过Apache HttpClient发送请求到预定的URL。URL位于RequestContext.getRouteHost()。
自定义Zuul过滤示例
以下大部分以下“如何撰写”示例都包含示例Zuul过滤器项目。还有一些操作该存储库中的请求或响应正文的例子。
如何编写预过滤器
前置过滤器用于设置RequestContext中的数据,用于下游的过滤器。主要用例是设置路由过滤器所需的信息。
public class QueryParamPreFilter extends ZuulFilter {
@Override
public int filterOrder() {
return PRE_DECORATION_FILTER_ORDER - 1; // run before PreDecoration
}
@Override
public String filterType() {
return PRE_TYPE;
}
@Override
public boolean shouldFilter() {
RequestContext ctx = RequestContext.getCurrentContext();
return !ctx.containsKey(FORWARD_TO_KEY) // a filter has already forwarded
&& !ctx.containsKey(SERVICE_ID_KEY); // a filter has already determined serviceId
}
@Override
public Object run() {
RequestContext ctx = RequestContext.getCurrentContext();
HttpServletRequest request = ctx.getRequest();
if (request.getParameter("foo") != null) {
// put the serviceId in `RequestContext`
ctx.put(SERVICE_ID_KEY, request.getParameter("foo"));
}
return null;
}
}
上面的过滤器从foo请求参数填充SERVICE_ID_KEY。实际上,做这种直接映射并不是一个好主意,而是从foo的值来查看服务ID。
现在填写SERVICE_ID_KEY,PreDecorationFilter将不会运行,RibbonRoutingFilter将会。如果您想要路由到完整的网址,请改用ctx.setRouteHost(url)。
要修改路由过滤器将转发的路径,请设置REQUEST_URI_KEY。
如何编写路由过滤器
路由过滤器在预过滤器之后运行,并用于向其他服务发出请求。这里的大部分工作是将请求和响应数据转换到客户端所需的模型。
public class OkHttpRoutingFilter extends ZuulFilter {
@Autowired
private ProxyRequestHelper helper;
@Override
public String filterType() {
return ROUTE_TYPE;
}
@Override
public int filterOrder() {
return SIMPLE_HOST_ROUTING_FILTER_ORDER - 1;
}
@Override
public boolean shouldFilter() {
return RequestContext.getCurrentContext().getRouteHost() != null
&& RequestContext.getCurrentContext().sendZuulResponse();
}
@Override
public Object run() {
OkHttpClient httpClient = new OkHttpClient.Builder()
// customize
.build();
RequestContext context = RequestContext.getCurrentContext();
HttpServletRequest request = context.getRequest();
String method = request.getMethod();
String uri = this.helper.buildZuulRequestURI(request);
Headers.Builder headers = new Headers.Builder();
Enumeration headerNames = request.getHeaderNames();
while (headerNames.hasMoreElements()) {
String name = headerNames.nextElement();
Enumeration values = request.getHeaders(name);
while (values.hasMoreElements()) {
String value = values.nextElement();
headers.add(name, value);
}
}
InputStream inputStream = request.getInputStream();
RequestBody requestBody = null;
if (inputStream != null && HttpMethod.permitsRequestBody(method)) {
MediaType mediaType = null;
if (headers.get("Content-Type") != null) {
mediaType = MediaType.parse(headers.get("Content-Type"));
}
requestBody = RequestBody.create(mediaType, StreamUtils.copyToByteArray(inputStream));
}
Request.Builder builder = new Request.Builder()
.headers(headers.build())
.url(uri)
.method(method, requestBody);
Response response = httpClient.newCall(builder.build()).execute();
LinkedMultiValueMap responseHeaders = new LinkedMultiValueMap<>();
for (Map.Entry> entry : response.headers().toMultimap().entrySet()) {
responseHeaders.put(entry.getKey(), entry.getValue());
}
this.helper.setResponse(response.code(), response.body().byteStream(),
responseHeaders);
context.setRouteHost(null); // prevent SimpleHostRoutingFilter from running
return null;
}
}
上述过滤器将Servlet请求信息转换为OkHttp3请求信息,执行HTTP请求,然后将OkHttp3响应信息转换为Servlet响应。警告:此过滤器可能有错误,但功能不正确。
如何编写过滤器
后置过滤器通常操纵响应。在下面的过滤器中,我们添加一个随机UUID作为X-Foo头。其他操作,如转换响应体,要复杂得多,计算密集。
public class AddResponseHeaderFilter extends ZuulFilter {
@Override
public String filterType() {
return POST_TYPE;
}
@Override
public int filterOrder() {
return SEND_RESPONSE_FILTER_ORDER - 1;
}
@Override
public boolean shouldFilter() {
return true;
}
@Override
public Object run() {
RequestContext context = RequestContext.getCurrentContext();
HttpServletResponse servletResponse = context.getResponse();
servletResponse.addHeader("X-Foo", UUID.randomUUID().toString());
return null;
}
}
Zuul错误如何工作
如果在Zuul过滤器生命周期的任何部分抛出异常,则会执行错误过滤器。SendErrorFilter只有RequestContext.getThrowable()不是null才会运行。然后在请求中设置特定的javax.servlet.error.*属性,并将请求转发到Spring Boot错误页面。
Zuul渴望应用程序上下文加载
Zuul内部使用Ribbon调用远程URL,并且Ribbon客户端默认在第一次调用时由Spring Cloud加载。可以使用以下配置更改Zuul的此行为,并将导致在应用程序启动时,子Ribbon相关的应用程序上下文正在加载。
application.yml
zuul:
ribbon:
eager-load:
enabled: true
Polyglot支持Sidecar
你有没有非jvm的语言你想利用Eureka,Ribbon和配置服务器?Netflix Prana启发了Spring Cloud Netflix Sidecar。它包含一个简单的http api来获取给定服务的所有实例(即主机和端口)。您还可以通过从Eureka获取其路由条目的嵌入式Zuul代理来代理服务调用。可以通过主机查找或通过Zuul代理访问Spring Cloud Config服务器。非jvm应用程序应该执行健康检查,以便Sidecar可以向应用程序启动或关闭时向eureka报告。
要在项目中包含Sidecar,使用组org.springframework.cloud和artifact idspring-cloud-netflix-sidecar的依赖关系。
要启用Sidecar,请使用@EnableSidecar创建Spring Boot应用程序。此注释包括@EnableCircuitBreaker,@EnableDiscoveryClient和@EnableZuulProxy。在与非jvm应用程序相同的主机上运行生成的应用程序。
要配置侧车将sidecar.port和sidecar.health-uri添加到application.yml。sidecar.port属性是非jvm应用程序正在侦听的端口。这样,Sidecar可以使用Eureka正确注册该应用。sidecar.health-uri是可以在非jvm应用程序上访问的,可以模拟Spring Boot健康指标。它应该返回一个json文档,如下所示:
健康-URI文档
{
"status":"UP"
}
以下是Sidecar应用程序的application.yml示例:
application.yml
server:
port: 5678
spring:
application:
name: sidecar
sidecar:
port: 8000
health-uri: http://localhost:8000/health.json
DiscoveryClient.getInstances()方法的api为/hosts/{serviceId}。以下是/hosts/customers在不同主机上返回两个实例的示例响应。这个api可以访问http://localhost:5678/hosts/{serviceId}的非jvm应用程序(如果侧面在端口5678上)。
/主机/客户
[
{
"host": "myhost",
"port": 9000,
"uri": "http://myhost:9000",
"serviceId": "CUSTOMERS",
"secure": false
},
{
"host": "myhost2",
"port": 9000,
"uri": "http://myhost2:9000",
"serviceId": "CUSTOMERS",
"secure": false
}
]
Zuul代理自动将eureka中已知的每个服务的路由添加到/,因此客户服务可在/customers获得。非jvm应用程序可以通过http://localhost:5678/customers访问客户服务(假设边界正在侦听端口5678)。
如果配置服务器已注册到Eureka,则非jvm应用程序可以通过Zuul代理访问它。如果ConfigServer的serviceId为configserver且端口5678为Sidecar,则可以在http:// localhost:5678 / configserver
非jvm应用程序可以利用Config Server返回YAML文档的功能。例如,调用http://sidecar.local.spring.io:5678/configserver/default-master.yml可能会导致一个YAML文档,如下所示
eureka:
client:
serviceUrl:
defaultZone: http://localhost:8761/eureka/
password: password
info:
description: Spring Cloud Samples
url: https://github.com/spring-cloud-samples
RxJava与Spring MVC
Spring Cloud Netflix包括RxJava。
RxJava是Reactive Extensions的Java VM实现:用于通过使用observable序列来构建异步和基于事件的程序的库。
Spring Cloud Netflix支持从Spring MVC控制器返回rx.Single对象。它还支持对服务器发送事件(SSE)使用rx.Observable对象。如果您的内部API已经使用RxJava构建(参见Feign Hystrix支持示例),这可能非常方便。
以下是使用rx.Single的一些示例:
@RequestMapping(method = RequestMethod.GET, value = "/single")
public Single single() {
return Single.just("single value");
}
@RequestMapping(method = RequestMethod.GET, value = "/singleWithResponse")
public ResponseEntity> singleWithResponse() {
return new ResponseEntity<>(Single.just("single value"),
HttpStatus.NOT_FOUND);
}
@RequestMapping(method = RequestMethod.GET, value = "/singleCreatedWithResponse")
public Single> singleOuterWithResponse() {
return Single.just(new ResponseEntity<>("single value", HttpStatus.CREATED));
}
@RequestMapping(method = RequestMethod.GET, value = "/throw")
public Single error() {
return Single.error(new RuntimeException("Unexpected"));
}
如果您有Observable而不是单个,则可以使用.toSingle()或.toList().toSingle()。这里有些例子:
@RequestMapping(method = RequestMethod.GET, value = "/single")
public Single single() {
return Observable.just("single value").toSingle();
}
@RequestMapping(method = RequestMethod.GET, value = "/multiple")
public Single> multiple() {
return Observable.just("multiple", "values").toList().toSingle();
}
@RequestMapping(method = RequestMethod.GET, value = "/responseWithObservable")
public ResponseEntity> responseWithObservable() {
Observable observable = Observable.just("single value");
HttpHeaders headers = new HttpHeaders();
headers.setContentType(APPLICATION_JSON_UTF8);
return new ResponseEntity<>(observable.toSingle(), headers, HttpStatus.CREATED);
}
@RequestMapping(method = RequestMethod.GET, value = "/timeout")
public Observable timeout() {
return Observable.timer(1, TimeUnit.MINUTES).map(new Func1() {
@Override
public String call(Long aLong) {
return "single value";
}
});
}
如果您有流式端点和客户端,SSE可以是一个选项。要将rx.Observable转换为SpringSseEmitter使用RxResponse.sse()。这里有些例子:
@RequestMapping(method = RequestMethod.GET, value = "/sse")
public SseEmitter single() {
return RxResponse.sse(Observable.just("single value"));
}
@RequestMapping(method = RequestMethod.GET, value = "/messages")
public SseEmitter messages() {
return RxResponse.sse(Observable.just("message 1", "message 2", "message 3"));
}
@RequestMapping(method = RequestMethod.GET, value = "/events")
public SseEmitter event() {
return RxResponse.sse(APPLICATION_JSON_UTF8,
Observable.just(new EventDto("Spring io", getDate(2016, 5, 19)),
new EventDto("SpringOnePlatform", getDate(2016, 8, 1))));
}
指标:Spectator,Servo和Atlas
当一起使用时,Spectator / Servo和Atlas提供了近乎实时的操作洞察平台。
Netflix的度量收集库Spectator和ServoAtlas是用于管理维度时间序列数据的Netflix指标后端。
Servo为Netflix服务了好几年,仍然可以使用,但逐渐被淘汰出局Spectator,这只适用于Java 8. Spring Cloud Netflix提供了支持,但Java 8鼓励基于应用的应用程序使用Spectator。
维度与层次度量
Spring Boot执行器指标是层次结构,指标只能由名称分隔。这些名称通常遵循将密钥/值属性对(维)嵌入到以句点分隔的名称中的命名约定。考虑以下两个端点(root和star-star)的指标:
{
"counter.status.200.root": 20,
"counter.status.400.root": 3,
"counter.status.200.star-star": 5,
}
第一个指标给出了每单位时间内针对根端点的成功请求的归一化计数。但是如果系统有20个端点,并且想要获得针对所有端点的成功请求计数呢?一些分级度量后端将允许您指定一个通配符,例如counter.status.200.,它将读取所有20个指标并聚合结果。或者,您可以提供HandlerInterceptorAdapter拦截并记录所有成功请求的counter.status.200.all等指标,而不考虑端点,但现在您必须编写20 + 1个不同的指标。同样,如果您想知道服务中所有端点的成功请求总数,您可以指定一个通配符,例如counter.status.2.*。
即使在分级度量后端的通配符支持的情况下,命名一致性也是困难的。具体来说,这些标签在名称字符串中的位置可能会随着时间而滑落,从而导致查询错例如,假设我们为上述HTTP方法添加了一个额外的维度。那么counter.status.200.root成为counter.status.200.method.get.root等等。我们的counter.status.200.*突然不再具有相同的语义。此外,如果新的维度在整个代码库中不均匀地应用,某些查询可能会变得不可能。这可以很快失控。
Netflix指标被标记(又称维度)。每个指标都有一个名称,但是这个单一的命名度量可以包含多个统计信息和“标签”键/值对,这允许更多的查询灵活性。实际上统计本身就是记录在一个特殊的标签上。
使用Netflix Servo或Spectator记录,上述根端点的计时器包含每个状态码的4个统计信息,其中计数统计信息与Spring Boot执行器计数器相同。如果到目前为止,我们遇到了HTTP 200和400,将有8个可用数据点:
{
"root(status=200,stastic=count)": 20,
"root(status=200,stastic=max)": 0.7265630630000001,
"root(status=200,stastic=totalOfSquares)": 0.04759702862580789,
"root(status=200,stastic=totalTime)": 0.2093076914666667,
"root(status=400,stastic=count)": 1,
"root(status=400,stastic=max)": 0,
"root(status=400,stastic=totalOfSquares)": 0,
"root(status=400,stastic=totalTime)": 0,
}
默认度量集合
没有任何附加依赖或配置,基于Spring Cloud的服务将自动配置ServoMonitorRegistry,并开始收集每个Spring MVC请求的指标。默认情况下,将为每个MVC请求记录名称为rest的Servo定时器,其标记为:
HTTP方法
HTTP状态(例如200,400,500)
URI(如果URI为空,则为“root”),为Atlas
异常类名称,如果请求处理程序抛出异常
如果在请求上设置了匹配netflix.metrics.rest.callerHeader的密钥的请求头,则呼叫者。netflix.metrics.rest.callerHeader没有默认键。如果您希望收集来电者信息,则必须将其添加到应用程序属性中。
设置netflix.metrics.rest.metricName属性将度量值的名称从rest更改为您提供的名称。
如果Spring AOP已启用,并且org.aspectj:aspectjweaver存在于您的运行时类路径上,则Spring Cloud还将收集每个使用RestTemplate进行的客户端调用的指标。将为每个具有以下标签的MVC请求记录名称为restclient的Servo定时器:
HTTP方法
HTTP状态(例如200,400,500),如果响应返回为空,则为“CLIENT_ERROR”;如果在执行RestTemplate方法期间发生IOException,则为“IO_ERROR”
URI,为Atlas
客户名称
警告
避免在RestTemplate内使用硬编码的url参数。定位动态端点时使用URL变量。这将避免ServoMonitorCache将每个网址视为唯一密钥的潜在“GC覆盖限制达到”问题。
// recommended
String orderid = "1";
restTemplate.getForObject("http://testeurekabrixtonclient/orders/{orderid}", String.class, orderid)
// avoid
restTemplate.getForObject("http://testeurekabrixtonclient/orders/1", String.class)
指标集:Spectator
要启用Spectator指标,请在spring-boot-starter-spectator上包含依赖关系:
org.springframework.cloud
spring-cloud-starter-spectator
在Spectator说明中,仪表是一个命名,打字和标记的配置,而指标表示给定仪表在某个时间点的值。Spectator米由注册表创建和控制,注册表目前有几个不同的实现。Spectator提供4米类型:计数器,定时器,量规和分配摘要。
Spring Cloud Spectator集成为您配置可注入的com.netflix.spectator.api.Registry实例。具体来说,它配置一个ServoRegistry实例,以统一REST度量标准的集合,并将度量标准导出到Servo API下的Atlas后端。实际上,这意味着您的代码可能会使用Servo显示器和Spectator米的混合,并且都将由Spring Boot ActuatorMetricReader实例舀取,并将两者都发送到Atlas后端
Spectator柜台
计数器用于测量某些事件发生的速率。
// create a counter with a name and a set of tags
Counter counter = registry.counter("counterName", "tagKey1", "tagValue1", ...);
counter.increment(); // increment when an event occurs
counter.increment(10); // increment by a discrete amount
计数器记录单个时间归一化统计量。
Spectator计时器
一个计时器用于测量一些事件需要多长时间。Spring Cloud自动记录Spring MVC请求和有条件RestTemplate请求的定时器,稍后可用于为请求相关指标创建仪表板,如延迟:
图4.请求延迟
// create a timer with a name and a set of tags
Timer timer = registry.timer("timerName", "tagKey1", "tagValue1", ...);
// execute an operation and time it at the same time
T result = timer.record(() -> fooReturnsT());
// alternatively, if you must manually record the time
Long start = System.nanoTime();
T result = fooReturnsT();
timer.record(System.nanoTime() - start, TimeUnit.NANOSECONDS);
计时器同时记录4个统计信息:count,max,totalOfSquares和totalTime。如果您在每次记录时间时在计数器上调用了increment()一次,计数统计量将始终与计数器提供的单个归一化值相匹配,因此对于单个操作,不需要单独计数和分时。
对于长时间运行的操作,Spectator提供了一个特殊的LongTaskTimer。
Spectator量规
量规用于确定一些当前值,如队列的大小或处于运行状态的线程数。由于仪表被采样,它们不提供关于这些值在样品之间如何波动的信息。
仪器的正常使用包括在初始化中使用标识符注册仪表,对要采样的对象的引用,以及基于对象获取或计算数值的功能。对对象的引用被单独传递,Spectator注册表将保留对该对象的弱引用。如果对象被垃圾回收,则Spectator将自动删除注册。见注Spectator是关于潜在的内存泄漏的文件中,如果这个API被滥用。
// the registry will automatically sample this gauge periodically
registry.gauge("gaugeName", pool, Pool::numberOfRunningThreads);
// manually sample a value in code at periodic intervals -- last resort!
registry.gauge("gaugeName", Arrays.asList("tagKey1", "tagValue1", ...), 1000);
Spectator分发摘要
分发摘要用于跟踪事件的分布情况。它类似于一个计时器,但更普遍的是,大小不一定是一段时间。例如,分发摘要可用于测量服务器的请求的有效载荷大小。
// the registry will automatically sample this gauge periodically
DistributionSummary ds = registry.distributionSummary("dsName", "tagKey1", "tagValue1", ...);
ds.record(request.sizeInBytes());
指标集:Servo
警告
如果您的代码在Java 8上编译,请使用Spectator而不是Servo,因为Spectator注定要从长期来替换Servo。
在Servo语言中,监视器是一个命名,键入和标记的配置,而指标表示给定监视器在某个时间点的值。Servo显示器在逻辑上相当于Spectator米。Servo显示器由MonitorRegistry创建和控制。尽管有上述警告,Servo确实具有比Spectator有米的更广泛的监视器选项。
Spring Cloud集成为您配置可注入的com.netflix.servo.MonitorRegistry实例。在Servo中创建了相应的Monitor类型后,记录数据的过程完全类似于Spectator。
创建Servo显示器
如果您正在使用由Spring Cloud提供的ServoMonitorRegistry实例(具体来说是DefaultMonitorRegistry的实例),则Servo提供了用于检索计数器和计时器的便利类。这些便利类确保每个唯一的名称和标签组合只注册一个Monitor。
要在Servo中手动创建监视器类型,特别是对于不提供方便方法的异域监视器类型,通过提供MonitorConfig实例来实例化适当的类型:
MonitorConfig config = MonitorConfig.builder("timerName").withTag("tagKey1", "tagValue1").build();
// somewhere we should cache this Monitor by MonitorConfig
Timer timer = new BasicTimer(config);
monitorRegistry.register(timer);
指标后端:Atlas
Netflix开发了Atlas来管理维度时间序列数据,实现近实时操作洞察。Atlas具有内存中数据存储功能,可以非常快速地收集和报告大量的指标。
Atlas捕获操作情报。而商业智能是收集的数据,用于分析一段时间内的趋势,操作情报提供了系统中目前发生的情况。
Spring Cloud提供了一个spring-cloud-starter-atlas,它具有您需要的所有依赖关系。然后只需使用@EnableAtlas注释您的Spring Boot应用程序,并为您运行的Atlas服务器提供netflix.atlas.uri属性的位置。
全球标签
您可以通过Spring Cloud向发送到Atlas后端的每个度量标准添加标签。全局标签可用于按应用程序名称,环境,区域等分隔度量。
实现AtlasTagProvider的每个bean将贡献全局标签列表:
@Bean
AtlasTagProvider atlasCommonTags(
@Value("${spring.application.name}") String appName) {
return () -> Collections.singletonMap("app", appName);
}
使用Atlas
要引导内存独立的Atlas实例:
$ curl -LO https://github.com/Netflix/atlas/releases/download/v1.4.2/atlas-1.4.2-standalone.jar
$ java -jar atlas-1.4.2-standalone.jar
小费
运行在r3.2xlarge(61GB RAM)上的Atlas独立节点可以在给定的6小时窗口内每分钟处理大约200万个度量值。
一旦运行,您收集了少量指标,请通过在Atlas服务器上列出代码来验证您的设置是否正确:
$ curl http://ATLAS/api/v1/tags
小费
在针对您的服务执行多个请求后,您可以通过在浏览器中粘贴以下URL来收集关于每个请求的请求延迟的一些非常基本的信息:http://ATLAS/api/v1/graph?q=name,rest,:eq,:avg
Atlas wiki包含各种场景样本查询的汇编。
确保使用双指数平滑来查看警报原理和文档,以生成动态警报阈值。
重试失败的请求
Spring Cloud Netflix提供了多种方式来进行HTTP请求。您可以使用负载平衡RestTemplate,Ribbon或Feign。无论您如何选择HTTP请求,始终有可能失败的请求。当请求失败时,您可能希望自动重试该请求。要在使用Sping Cloud Netflix时完成此操作,您需要在应用程序的类路径中包含Spring重试。当Spring重试出现负载平衡RestTemplates时,Feign和Zuul将自动重试任何失败的请求(假设配置允许)。
组态
随时Ribbon与Spring重试一起使用,您可以通过配置某些Ribbon属性来控制重试功能。您可以使用的属性是client.ribbon.MaxAutoRetries,client.ribbon.MaxAutoRetriesNextServer和client.ribbon.OkToRetryOnAllOperations。请参阅Ribbon文档,了解属性的具体内容。
此外,您可能希望在响应中返回某些状态代码时重试请求。您可以列出您希望Ribbon客户端使用属性clientName.ribbon.retryableStatusCodes重试的响应代码。例如
clientName:
ribbon:
retryableStatusCodes: 404,502
您还可以创建一个类型为LoadBalancedRetryPolicy的bean,并实现retryableStatusCode方法来确定是否要重试发出状态代码的请求。
Zuul
您可以通过将zuul.retryable设置为false来关闭Zuul的重试功能。您还可以通过将zuul.routes.routename.retryable设置为false,以路由方式禁用重试功能。
Spring Cloud Stream
本节将详细介绍如何使用Spring Cloud Stream。它涵盖了创建和运行流应用程序等主题。
介绍Spring Cloud Stream
Spring Cloud Stream是构建消息驱动的微服务应用程序的框架。Spring Cloud Stream基于Spring Boot建立独立的生产级Spring应用程序,并使用Spring Integration提供与消息代理的连接。它提供了来自几家供应商的中间件的意见配置,介绍了持久发布订阅语义,消费者组和分区的概念。
您可以将@EnableBinding注释添加到应用程序,以便立即连接到消息代理,并且可以将@StreamListener添加到方法中,以使其接收流处理的事件。以下是接收外部消息的简单接收器应用程序。
@SpringBootApplication
@EnableBinding(Sink.class)
public class VoteRecordingSinkApplication {
public static void main(String[] args) {
SpringApplication.run(VoteRecordingSinkApplication.class, args);
}
@StreamListener(Sink.INPUT)
public void processVote(Vote vote) {
votingService.recordVote(vote);
}
}
@EnableBinding注释需要一个或多个接口作为参数(在这种情况下,该参数是单个Sink接口)。接口声明输入和/或输出通道。Spring Cloud Stream提供了接口Source,Sink和Processor;您还可以定义自己的界面。
以下是Sink接口的定义:
public interface Sink {
String INPUT = "input";
@Input(Sink.INPUT)
SubscribableChannel input();
}
@Input注释标识输入通道,通过该输入通道接收到的消息进入应用程序;@Output注释标识输出通道,发布的消息将通过该通道离开应用程序。@Input和@Output注释可以使用频道名称作为参数;如果未提供名称,将使用注释方法的名称。
Spring Cloud Stream将为您创建一个界面的实现。您可以在应用程序中通过自动连接来使用它,如下面的测试用例示例。
@RunWith(SpringJUnit4ClassRunner.class)
@SpringApplicationConfiguration(classes = VoteRecordingSinkApplication.class)
@WebAppConfiguration
@DirtiesContext
public class StreamApplicationTests {
@Autowired
private Sink sink;
@Test
public void contextLoads() {
assertNotNull(this.sink.input());
}
}
主要概念
Spring Cloud Stream提供了一些简化了消息驱动的微服务应用程序编写的抽象和原语。本节概述了以下内容:
Spring Cloud Stream的应用模型
Binder抽象
持续的发布 - 订阅支持
消费者群体支持
分区支持
一个可插拔的Binder API
应用模型
一个Spring Cloud Stream应用程序由一个中间件中立的核心组成。该应用程序通过Spring Cloud Stream注入到其中的输入和输出通道与外界进行通信。渠道通过中间件特定的Binder实现连接到外部经纪人。
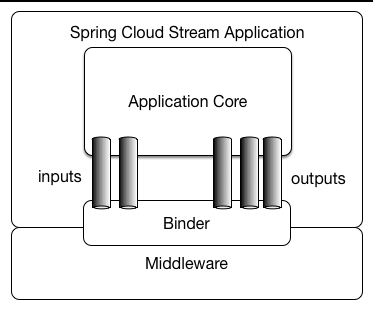
图5. Spring Cloud Stream应用
胖JAR
Spring Cloud Stream应用程序可以在独立模式下从IDE运行进行测试。要在生产中运行Spring Cloud Stream应用程序,您可以使用为Maven或Gradle提供的标准Spring Boot工具创建可执行文件(或“胖”)JAR。
Binder抽象
Spring Cloud Stream为Kafka和Rabbit MQ提供Binder实现。Spring Cloud Stream还包括一个TestSupportBinder,它保留了一个未修改的通道,以便测试可以直接和可靠地与通道进行交互。您可以使用可扩展API编写自己的Binder。
Spring Cloud Stream使用Spring Boot进行配置,Binder抽象使得Spring Cloud Stream应用程序可以灵活地连接到中间件。例如,部署者可以在运行时动态地选择通道连接的目的地(例如,Kafka主题或RabbitMQ交换)。可以通过外部配置属性和Spring Boot(包括应用程序参数,环境变量和application.yml或application.properties文件)支持的任何形式提供此类配置。在引入Spring Cloud Stream部分的接收器示例中,将应用程序属性spring.cloud.stream.bindings.input.destination设置为raw-sensor-data将使其从raw-sensor-dataKafka主题或从绑定到raw-sensor-dataRabbitMQ交换。
Spring Cloud Stream自动检测并使用类路径中找到的binder。您可以使用相同的代码轻松使用不同类型的中间件:在构建时只包含不同的绑定器。对于更复杂的用例,您还可以在应用程序中打包多个绑定器,并在运行时选择绑定器,甚至是否为不同的通道使用不同的绑定器。
持续发布 - 订阅支持
应用之间的通信遵循发布订阅模式,其中通过共享主题广播数据。这可以在下图中看到,它显示了一组交互式的Spring Cloud Stream应用程序的典型部署。
图6. Spring Cloud Stream Publish-Subscribe
传感器向HTTP端点报告的数据将发送到名为raw-sensor-data的公共目标。从目的地,它由微服务应用程序独立处理,该应用程序计算时间窗口平均值,以及另一个将原始数据导入HDFS的微服务应用程序。为了处理数据,两个应用程序在运行时将主题声明为它们的输入。
发布订阅通信模型降低了生产者和消费者的复杂性,并允许将新应用程序添加到拓扑中,而不会中断现有流。例如,在平均计算应用程序的下游,您可以添加一个计算显示和监视的最高温度值的应用程序。然后,您可以添加另一个解释相同的故障检测平均流程的应用程序。通过共享主题而不是点对点队列进行所有通信可以减少微服务之间的耦合。
虽然发布订阅消息的概念不是新的,但是Spring Cloud Stream需要额外的步骤才能使其成为其应用模型的一个有意义的选择。通过使用本地中间件支持,Spring Cloud Stream还简化了在不同平台上使用发布订阅模型。
消费群体
虽然发布订阅模型可以轻松地通过共享主题连接应用程序,但通过创建给定应用程序的多个实例来扩展的能力同样重要。当这样做时,应用程序的不同实例被放置在竞争的消费者关系中,其中只有一个实例预期处理给定消息。
Spring Cloud Stream通过消费者组的概念来模拟此行为。(Spring Cloud Stream消费者组与Kafka消费者组相似并受到启发。)每个消费者绑定可以使用spring.cloud.stream.bindings..group属性来指定组名称。对于下图所示的消费者,此属性将设置为spring.cloud.stream.bindings..group=hdfsWrite或spring.cloud.stream.bindings..group=average。
图7. Spring Cloud Stream消费者组
订阅给定目标的所有组都会收到已发布数据的副本,但每个组中只有一个成员从该目的地接收给定的消息。默认情况下,当未指定组时,Spring Cloud Stream将应用程序分配给与所有其他消费者组发布 - 订阅关系的匿名独立单个成员消费者组。
耐久力
符合Spring Cloud Stream的有意义的应用模式,消费者群体订阅是持久的。也就是说,绑定实现确保组预订是持久的,一旦已经创建了一个组的至少一个订阅,即使组中的所有应用程序都被停止,组也将接收消息。
注意
匿名订阅本质上是不耐用的。对于某些binder实现(例如RabbitMQ),可以具有非持久组的订阅。
通常,当将应用绑定到给定目的地时,最好始终指定消费者组。在扩展Spring Cloud Stream应用程序时,必须为每个输入绑定指定一个使用者组。这样可以防止应用程序的实例收到重复的消息(除非需要这种行为,这是不寻常的)。
分区支持
Spring Cloud Stream提供对给定应用程序的多个实例之间的分区数据的支持。在分区场景中,物理通信介质(例如,代理主题)被视为被构造成多个分区。一个或多个生产者应用程序实例将数据发送到多个消费者应用程序实例,并确保由共同特征标识的数据由相同的消费者实例处理。
Spring Cloud Stream提供了统一方式实现分区处理用例的通用抽象。因此,无论代理本身是否自然分区(例如Kafka)(例如RabbitMQ),分区可以被使用。
图8. Spring Cloud Stream分区
分区是状态处理中的一个关键概念,无论是性能还是一致性原因,它都是批评性的,以确保所有相关数据一起处理。例如,在时间平均计算示例中,重要的是所有给定传感器的所有测量都由相同的应用实例进行处理。
注意
要设置分区处理方案,您必须同时配置数据生成和数据消耗结束。
编程模型
本节介绍Spring Cloud Stream的编程模型。Spring Cloud Stream提供了许多预定义的注释,用于声明绑定的输入和输出通道,以及如何收听频道。
声明和绑定频道
触发绑定@EnableBinding
您可以将Spring应用程序转换为Spring Cloud Stream应用程序,将@EnableBinding注释应用于应用程序的配置类之一。@EnableBinding注释本身使用@Configuration进行元注释,并触发Spring Cloud Stream基础架构的配置:
...
@Import(...)
@Configuration
@EnableIntegration
public @interface EnableBinding {
...
Class[] value() default {};
}
@EnableBinding注释可以将一个或多个接口类作为参数,这些接口类包含表示可绑定组件(通常是消息通道)的方法。
注意
在Spring Cloud Stream 1.0中,唯一支持的可绑定组件是Spring消息传递MessageChannel及其扩展名SubscribableChannel和PollableChannel。未来版本应该使用相同的机制将此支持扩展到其他类型的组件。在本文档中,我们将继续参考渠道。
@Input和@Output
Spring Cloud Stream应用程序可以在接口中定义任意数量的输入和输出通道为@Input和@Output方法:
public interface Barista {
@Input
SubscribableChannel orders();
@Output
MessageChannel hotDrinks();
@Output
MessageChannel coldDrinks();
}
使用此接口作为参数@EnableBinding将分别触发三个绑定的通道名称为orders,hotDrinks和coldDrinks。
@EnableBinding(Barista.class)
public class CafeConfiguration {
...
}
自定义频道名称
使用@Input和@Output注释,您可以指定频道的自定义频道名称,如以下示例所示:
public interface Barista {
...
@Input("inboundOrders")
SubscribableChannel orders();
}
在这个例子中,创建的绑定通道将被命名为inboundOrders。
Source,Sink和Processor
为了方便寻址最常见的用例,涉及输入通道,输出通道或两者,Spring Cloud Stream提供了开箱即用的三个预定义接口。
Source可用于具有单个出站通道的应用程序。
public interface Source {
String OUTPUT = "output";
@Output(Source.OUTPUT)
MessageChannel output();
}
Sink可用于具有单个入站通道的应用程序。
public interface Sink {
String INPUT = "input";
@Input(Sink.INPUT)
SubscribableChannel input();
}
Processor可用于具有入站通道和出站通道的应用程序。
public interface Processor extends Source, Sink {
}
Spring Cloud Stream不为任何这些接口提供特殊处理;它们只是开箱即用。
访问绑定通道
注入绑定界面
对于每个绑定接口,Spring Cloud Stream将生成一个实现该接口的bean。调用其中一个bean的@Input注释或@Output注释方法将返回相关的绑定通道。
以下示例中的bean在调用其hello方法时在输出通道上发送消息。它在注入的Sourcebean上调用output()来检索目标通道。
@Component
public class SendingBean {
private Source source;
@Autowired
public SendingBean(Source source) {
this.source = source;
}
public void sayHello(String name) {
source.output().send(MessageBuilder.withPayload(name).build());
}
}
直接注入渠道
绑定通道也可以直接注入:
@Component
public class SendingBean {
private MessageChannel output;
@Autowired
public SendingBean(MessageChannel output) {
this.output = output;
}
public void sayHello(String name) {
output.send(MessageBuilder.withPayload(name).build());
}
}
如果在声明注释上定制了通道的名称,则应使用该名称而不是方法名称。给出以下声明:
public interface CustomSource {
...
@Output("customOutput")
MessageChannel output();
}
通道将被注入,如下例所示:
@Component
public class SendingBean {
private MessageChannel output;
@Autowired
public SendingBean(@Qualifier("customOutput") MessageChannel output) {
this.output = output;
}
public void sayHello(String name) {
this.output.send(MessageBuilder.withPayload(name).build());
}
}
生产和消费消息
您可以使用Spring Integration注解或Spring Cloud Stream的@StreamListener注释编写Spring Cloud Stream应用程序。@StreamListener注释在其他Spring消息传递注释(例如@MessageMapping,@JmsListener,@RabbitListener等)之后建模,但添加内容类型管理和类型强制功能。
本地Spring Integration支持
由于Spring Cloud Stream基于Spring Integration,Stream完全继承了Integration的基础和基础架构以及组件本身。例如,您可以将Source的输出通道附加到MessageSource:
@EnableBinding(Source.class)
public class TimerSource {
@Value("${format}")
private String format;
@Bean
@InboundChannelAdapter(value = Source.OUTPUT, poller = @Poller(fixedDelay = "${fixedDelay}", maxMessagesPerPoll = "1"))
public MessageSource timerMessageSource() {
return () -> new GenericMessage<>(new SimpleDateFormat(format).format(new Date()));
}
}
或者您可以在变压器中使用处理器的通道:
@EnableBinding(Processor.class)
public class TransformProcessor {
@Transformer(inputChannel = Processor.INPUT, outputChannel = Processor.OUTPUT)
public Object transform(String message) {
return message.toUpperCase();
}
}
Spring Integration错误通道支持
Spring Cloud Stream支持发布Spring Integration全局错误通道收到的错误消息。发送到errorChannel的错误消息可以通过为名为error的出站目标配置绑定,将其发布到代理的特定目标。例如,要将错误消息发布到名为“myErrors”的代理目标,请提供以下属性:spring.cloud.stream.bindings.error.destination=myErrors
使用@StreamListener进行自动内容类型处理
Spring Integration支持Spring Cloud Stream提供自己的@StreamListener注释,以其他Spring消息传递注释(例如@MessageMapping,@JmsListener,@RabbitListener等) )。@StreamListener注释提供了一种更简单的处理入站邮件的模型,特别是在处理涉及内容类型管理和类型强制的用例时。
Spring Cloud Stream提供了一种可扩展的MessageConverter机制,用于通过绑定通道处理数据转换,并且在这种情况下,将调度到使用@StreamListener注释的方法。以下是处理外部Vote事件的应用程序的示例:
@EnableBinding(Sink.class)
public class VoteHandler {
@Autowired
VotingService votingService;
@StreamListener(Sink.INPUT)
public void handle(Vote vote) {
votingService.record(vote);
}
}
当考虑String有效载荷和contentType标题application/json的入站Message时,可以看到@StreamListener和Spring Integration@ServiceActivator之间的区别。在@StreamListener的情况下,MessageConverter机制将使用contentType标头将String有效载荷解析为Vote对象。
与其他Spring消息传递方法一样,方法参数可以用@Payload,@Headers和@Header注释。
注意
对于返回数据的方法,您必须使用@SendTo注释来指定方法返回的数据的输出绑定目的地:
@EnableBinding(Processor.class)
public class TransformProcessor {
@Autowired
VotingService votingService;
@StreamListener(Processor.INPUT)
@SendTo(Processor.OUTPUT)
public VoteResult handle(Vote vote) {
return votingService.record(vote);
}
}
使用@StreamListener将消息分派到多个方法
自1.2版本以来,Spring Cloud Stream支持根据条件向在输入通道上注册的多个@StreamListener方法发送消息。
为了有资格支持有条件的调度,一种方法必须满足以下条件:
它不能返回值
它必须是一个单独的消息处理方法(不支持的反应API方法)
条件通过注释的condition属性中的SpEL表达式指定,并为每个消息进行评估。匹配条件的所有处理程序将在同一个线程中被调用,并且不必对调用发生的顺序做出假设。
使用@StreamListener具有调度条件的示例可以在下面看到。在此示例中,带有值为foo的标题type的所有消息将被分派到receiveFoo方法,所有带有值为bar的标题type的消息将被分派到receiveBar方法。
@EnableBinding(Sink.class)
@EnableAutoConfiguration
public static class TestPojoWithAnnotatedArguments {
@StreamListener(target = Sink.INPUT, condition = "headers['type']=='foo'")
public void receiveFoo(@Payload FooPojo fooPojo) {
// handle the message
}
@StreamListener(target = Sink.INPUT, condition = "headers['type']=='bar'")
public void receiveBar(@Payload BarPojo barPojo) {
// handle the message
}
}
注意
仅通过@StreamListener条件进行调度仅对单个消息的处理程序支持,而不适用于无效编程支持(如下所述)。
反应式编程支持
Spring Cloud Stream还支持使用反应性API,其中将传入和传出数据作为连续数据流处理。通过spring-cloud-stream-reactive提供对反应性API的支持,需要将其明确添加到您的项目中。
具有反应性API的编程模型是声明式的,而不是指定如何处理每个单独的消息,您可以使用描述从入站到出站数据流的功能转换的运算符。
Spring Cloud Stream支持以下反应性API:
反应堆
RxJava 1.x
将来,它旨在支持基于活动流的更通用的模型。
反应式编程模型还使用@StreamListener注释来设置反应处理程序。差异在于:
@StreamListener注释不能指定输入或输出,因为它们作为参数提供,并从方法返回值;
必须使用@Input和@Output注释方法的参数,指示输入和分别输出的数据流连接到哪个输入或输出;
方法的返回值(如果有的话)将用@Output注释,表示要发送数据的输入。
注意
反应式编程支持需要Java 1.8。
注意
截至Spring Cloud Stream 1.1.1及更高版本(从布鲁克林发行版开始列出),反应式编程支持需要使用Reactor 3.0.4.RELEASE和更高版本。不支持早期的Reactor版本(包括3.0.1.RELEASE,3.0.2.RELEASE和3.0.3.RELEASE)。spring-cloud-stream-reactive将会过渡地检索正确的版本,但项目结构有可能将io.projectreactor:reactor-core的版本管理到较早版本,特别是在使用Maven时。对于通过Spring Initializr(Spring Boot 1.x)生成的项目,这将覆盖Reactor版本为2.0.8.RELEASE。在这种情况下,您必须确保释放正确版本的工件。这可以通过在io.projectreactor:reactor-core上直接依赖于3.0.4.RELEASE或更高版本的项目来简单地实现。
注意
术语reactive的使用目前指的是正在使用的反应性API,而不是执行模型是无效的(即,绑定的端点仍然使用“推”而不是“拉”模型)。虽然通过使用Reactor提供了一些背压支持,但我们希望长期以来通过使用连接的中间件的本机反应客户端来支持完全无反应的管道。
基于反应器的处理程序
基于反应器的处理程序可以具有以下参数类型:
对于用@Input注释的参数,它支持反应器类型Flux。入站通量的参数化遵循与单个消息处理相同的规则:它可以是整个Message,一个可以是Message有效负载的POJO,也可以是一个POJO基于Message内容类型头的转换。提供多个输入;
对于使用Output注释的参数,它支持将方法生成的Flux与输出连接的类型FluxSender。一般来说,仅当方法可以有多个输出时才建议指定输出作为参数;
基于反应器的处理程序支持Flux的返回类型,其中必须使用@Output注释。当单个输出通量可用时,我们建议使用该方法的返回值。
这是一个简单的基于反应器的处理器的例子。
@EnableBinding(Processor.class)
@EnableAutoConfiguration
public static class UppercaseTransformer {
@StreamListener
@Output(Processor.OUTPUT)
public Flux receive(@Input(Processor.INPUT) Flux input) {
return input.map(s -> s.toUpperCase());
}
}
使用输出参数的同一个处理器如下所示:
@EnableBinding(Processor.class)
@EnableAutoConfiguration
public static class UppercaseTransformer {
@StreamListener
public void receive(@Input(Processor.INPUT) Flux input,
@Output(Processor.OUTPUT) FluxSender output) {
output.send(input.map(s -> s.toUpperCase()));
}
}
RxJava 1.x支持
RxJava 1.x处理程序遵循与基于反应器的规则相同的规则,但将使用Observable和ObservableSender参数和返回类型。
所以上面的第一个例子会变成:
@EnableBinding(Processor.class)
@EnableAutoConfiguration
public static class UppercaseTransformer {
@StreamListener
@Output(Processor.OUTPUT)
public Observable receive(@Input(Processor.INPUT) Observable input) {
return input.map(s -> s.toUpperCase());
}
}
上面的第二个例子将会变成:
@EnableBinding(Processor.class)
@EnableAutoConfiguration
public static class UppercaseTransformer {
@StreamListener
public void receive(@Input(Processor.INPUT) Observable input,
@Output(Processor.OUTPUT) ObservableSender output) {
output.send(input.map(s -> s.toUpperCase()));
}
}
聚合
Spring Cloud Stream支持将多个应用程序聚合在一起,直接连接其输入和输出通道,并避免通过代理交换消息的额外成本。从版本1.0的Spring Cloud Stream开始,仅对以下类型的应用程序支持聚合:
来源- 具有名为output的单个输出通道的应用程序,通常具有类型为org.springframework.cloud.stream.messaging.Source的单个绑定
接收器- 具有名为input的单个输入通道的应用程序,通常具有类型为org.springframework.cloud.stream.messaging.Sink的单个绑定
处理器- 具有名为input的单个输入通道和名为output的单个输出通道的应用程序,通常具有类型为org.springframework.cloud.stream.messaging.Processor的单个绑定。
它们可以通过创建一系列互连的应用程序来聚合在一起,其中序列中的元素的输出通道连接到下一个元素的输入通道(如果存在)。序列可以从源或处理器开始,它可以包含任意数量的处理器,并且必须以处理器或接收器结束。
根据起始和结束元素的性质,序列可以具有一个或多个可绑定的信道,如下所示:
如果序列从源头开始并以sink结束,则应用程序之间的所有通信都是直接的,并且不会绑定任何通道
如果序列以处理器开始,则其输入通道将成为聚合的input通道,并将相应地进行绑定
如果序列以处理器结束,则其输出通道将成为聚合的output通道,并将相应地进行绑定
使用AggregateApplicationBuilder实用程序类执行聚合,如以下示例所示。我们考虑一个项目,我们有源,处理器和汇点,可以在项目中定义,或者可以包含在项目的依赖之一中。
注意
如果配置类使用@SpringBootApplication,聚合应用程序中的每个组件(源,宿或处理器)必须在单独的包中提供。这是为了避免应用程序之间的串扰,由于在同一个包内的配置类上由@SpringBootApplication执行的类路径扫描。在下面的示例中,可以看到,Source,Processor和Sink应用程序类分组在单独的包中。一个可能的替代方法是在单独的@Configuration类中提供源,宿或处理器配置,避免使用@SpringBootApplication/@ComponentScan并使用它们进行聚合。
package com.app.mysink;
@SpringBootApplication
@EnableBinding(Sink.class)
public class SinkApplication {
private static Logger logger = LoggerFactory.getLogger(SinkApplication.class);
@ServiceActivator(inputChannel=Sink.INPUT)
public void loggerSink(Object payload) {
logger.info("Received: " + payload);
}
}
package com.app.myprocessor;
@SpringBootApplication
@EnableBinding(Processor.class)
public class ProcessorApplication {
@Transformer
public String loggerSink(String payload) {
return payload.toUpperCase();
}
}
package com.app.mysource;
@SpringBootApplication
@EnableBinding(Source.class)
public class SourceApplication {
@Bean
@InboundChannelAdapter(value = Source.OUTPUT)
public String timerMessageSource() {
return new SimpleDateFormat().format(new Date());
}
}
每个配置可以用于运行一个单独的组件,但在这种情况下,它们可以聚合在一起,如下所示:
package com.app;
@SpringBootApplication
public class SampleAggregateApplication {
public static void main(String[] args) {
new AggregateApplicationBuilder()
.from(SourceApplication.class).args("--fixedDelay=5000")
.via(ProcessorApplication.class)
.to(SinkApplication.class).args("--debug=true").run(args);
}
}
该序列的起始组件作为from()方法的参数提供。序列的结尾部分作为to()方法的参数提供。中间处理器作为via()方法的参数提供。同一类型的多个处理器可以一起链接(例如,用于具有不同配置的流水线转换)。对于每个组件,构建器可以为Spring Boot配置提供运行时参数。
配置聚合应用程序
Spring Cloud Stream支持使用'namespace'作为前缀向聚合应用程序内的各个应用程序传递属性。
命名空间可以为应用程序设置如下:
@SpringBootApplication
public class SampleAggregateApplication {
public static void main(String[] args) {
new AggregateApplicationBuilder()
.from(SourceApplication.class).namespace("source").args("--fixedDelay=5000")
.via(ProcessorApplication.class).namespace("processor1")
.to(SinkApplication.class).namespace("sink").args("--debug=true").run(args);
}
}
一旦为单个应用程序设置了“命名空间”,则可以使用任何支持的属性源(命令行,环境属性等)将具有namespace作为前缀的应用程序属性传递到聚合应用程序,
例如,要覆盖“source”和“sink”应用程序的默认fixedDelay和debug属性:
java -jar target/MyAggregateApplication-0.0.1-SNAPSHOT.jar --source.fixedDelay=10000 --sink.debug=false
为非自包含聚合应用程序配置绑定服务属性
非自包含聚合应用程序通过聚合应用程序的入站/出站组件(通常为消息通道)中的一个或两者绑定到外部代理,而聚合应用程序内的应用程序是直接绑定的。例如:源应用程序的输出和处理器应用程序的输入是直接绑定的,而处理器的输出通道绑定到代理的外部目的地。当传递非自包含聚合应用程序的绑定服务属性时,需要将绑定服务属性传递给聚合应用程序,而不是将它们设置为单个子应用程序的“args”。例如,
@SpringBootApplication
public class SampleAggregateApplication {
public static void main(String[] args) {
new AggregateApplicationBuilder()
.from(SourceApplication.class).namespace("source").args("--fixedDelay=5000")
.via(ProcessorApplication.class).namespace("processor1").args("--debug=true").run(args);
}
}
需要将绑定属性--spring.cloud.stream.bindings.output.destination=processor-output指定为外部配置属性(cmdline arg等)之一。
Binders
Spring Cloud Stream提供了一个Binder抽象,用于连接到外部中间件的物理目标。本节提供有关Binder SPI,其主要组件和实现特定详细信息背后的主要概念的信息。
生产者和消费者
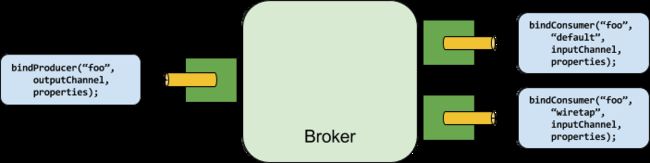
图9.生产者和消费者
甲生产者是将消息发送到信道的任何组分。该通道可以通过该代理的Binder实现绑定到外部消息代理。当调用bindProducer()方法时,第一个参数是代理中目标的名称,第二个参数是生成器将发送消息的本地通道实例,第三个参数包含属性(如分区键表达式)在为该通道创建的适配器中使用。
甲消费者的是,从一个信道接收的消息的任何组分。与生产者一样,消费者的频道可以绑定到外部消息代理。当调用bindConsumer()方法时,第一个参数是目标名称,第二个参数提供消费者逻辑组的名称。由给定目的地的消费者绑定表示的每个组接收生产者发送到该目的地的每个消息的副本(即,发布 - 订阅语义)。如果有多个使用相同组名称的消费者实例绑定,那么消息将在这些消费者实例之间进行负载平衡,以便生产者发送的每个消息仅由每个组中的单个消费者实例消耗(即排队语义)。
Binder SPI
Binder SPI包括许多接口,即插即用实用程序类和发现策略,提供可插拔机制连接到外部中间件。
SPI的关键点是Binder接口,它是将输入和输出连接到外部中间件的策略。
public interface Binder {
Binding bindConsumer(String name, String group, T inboundBindTarget, C consumerProperties);
Binding bindProducer(String name, T outboundBindTarget, P producerProperties);
}
界面参数化,提供多个扩展点:
输入和输出绑定目标 - 从版本1.0开始,只支持MessageChannel,但是这个目标是将来用作扩展点;
扩展的消费者和生产者属性 - 允许特定的Binder实现来添加可以以类型安全的方式支持的补充属性。
典型的绑定实现包括以下内容
一个实现Binder接口的类;
一个Spring@Configuration类,与中间件连接基础架构一起创建上述类型的bean;
在类路径中找到的包含一个或多个绑定器定义的META-INF/spring.binders文件,例如
kafka:\
org.springframework.cloud.stream.binder.kafka.config.KafkaBinderConfiguration
Binder检测
Spring Cloud Stream依赖于Binder SPI的实现来执行将通道连接到消息代理的任务。每个Binder实现通常连接到一种类型的消息系统。
类路径检测
默认情况下,Spring Cloud Stream依赖于Spring Boot的自动配置来配置绑定过程。如果在类路径中找到单个Binder实现,则Spring Cloud Stream将自动使用。例如,一个旨在绑定到RabbitMQ的Spring Cloud Stream项目可以简单地添加以下依赖项:
org.springframework.cloud
spring-cloud-stream-binder-rabbit
对于其他绑定依赖关系的特定maven坐标,请参阅该binder实现的文档。
Classpath上有多个Binders
当类路径中存在多个绑定器时,应用程序必须指明每个通道绑定将使用哪个绑定器。每个binder配置都包含一个META-INF/spring.binders,它是一个简单的属性文件:
rabbit:\
org.springframework.cloud.stream.binder.rabbit.config.RabbitServiceAutoConfiguration
对于其他提供的绑定实现(例如Kafka),存在类似的文件,并且预期自定义绑定实现也可以提供它们。键代表binder实现的标识名称,而该值是以逗号分隔的配置类列表,每个配置类都包含唯一的一个类型为org.springframework.cloud.stream.binder.Binder的bean定义。
可以使用spring.cloud.stream.defaultBinder属性(例如spring.cloud.stream.defaultBinder=rabbit)全局执行Binder选择,或通过在每个通道绑定上配置binder来单独执行。例如,从Kafka读取并写入RabbitMQ的处理器应用程序(分别具有用于读/写的名称为input和output的通道)可以指定以下配置:
spring.cloud.stream.bindings.input.binder=kafka
spring.cloud.stream.bindings.output.binder=rabbit
连接到多个系统
默认情况下,绑定器共享应用程序的Spring Boot自动配置,以便在类路径中找到每个绑定器的一个实例。如果您的应用程序连接到同一类型的多个代理,则可以指定多个绑定器配置,每个具有不同的环境设置。
注意
打开显式绑定器配置将完全禁用默认绑定器配置过程。如果这样做,所有使用的绑定器都必须包含在配置中。打算透明使用Spring Cloud Stream的框架可能会创建可以通过名称引用的binder配置,但不会影响默认的绑定器配置。为此,绑定器配置可能将其defaultCandidate标志设置为false,例如spring.cloud.stream.binders..defaultCandidate=false。这表示将独立于默认binder配置过程存在的配置。
例如,这是连接到两个RabbitMQ代理实例的处理器应用程序的典型配置:
spring:
cloud:
stream:
bindings:
input:
destination: foo
binder: rabbit1
output:
destination: bar
binder: rabbit2
binders:
rabbit1:
type: rabbit
environment:
spring:
rabbitmq:
host:
rabbit2:
type: rabbit
environment:
spring:
rabbitmq:
host:
Binder配置属性
创建自定义绑定器配置时,以下属性可用。它们必须以spring.cloud.stream.binders.为前缀。
类型
粘合剂类型。它通常引用在类路径中找到的绑定器之一,特别是META-INF/spring.binders文件中的键。
默认情况下,它具有与配置名称相同的值。
inheritEnvironment
配置是否会继承应用程序本身的环境。
默认true。
环境
一组可用于自定义绑定环境的属性的根。配置此配置后,创建绑定器的上下文不是应用程序上下文的子级。这允许粘合剂组分和应用组分之间的完全分离。
默认empty。
defaultCandidate
粘合剂配置是否被认为是默认的粘合剂的候选者,或者仅在明确引用时才能使用。这允许添加binder配置,而不会干扰默认处理。
默认true。
配置选项
Spring Cloud Stream支持常规配置选项以及绑定和绑定器的配置。一些绑定器允许额外的绑定属性来支持中间件特定的功能。
可以通过Spring Boot支持的任何机制将配置选项提供给Spring Cloud Stream应用程序。这包括应用程序参数,环境变量和YAML或.properties文件。
Spring Cloud Stream Properties
spring.cloud.stream.instanceCount
应用程序部署实例的数量。必须设置分区,如果使用Kafka。
默认值:1。
spring.cloud.stream.instanceIndex
应用程序的实例索引:从0到instanceCount- 1的数字。用于分区和使用Kafka。在Cloud Foundry中自动设置以匹配应用程序的实例索引。
spring.cloud.stream.dynamicDestinations
可以动态绑定的目标列表(例如,在动态路由方案中)。如果设置,只能列出目的地。
默认值:空(允许任何目的地绑定)。
spring.cloud.stream.defaultBinder
如果配置了多个绑定器,则使用默认的binder。请参阅Classpath上的Multiple Binders。
默认值:空。
spring.cloud.stream.overrideCloudConnectors
此属性仅适用于cloud配置文件激活且Spring Cloud连接器随应用程序一起提供。如果属性为false(默认值),绑定器将检测适合的绑定服务(例如,在Cloud Foundry中为RabbitMQ绑定器绑定的RabbitMQ服务),并将使用它来创建连接(通常通过Spring Cloud连接器)。当设置为true时,此属性指示绑定器完全忽略绑定的服务,并依赖Spring Boot属性(例如,依赖于RabbitMQ绑定器环境中提供的spring.rabbitmq.*属性)。当连接到多个系统时,此属性的典型用法将嵌套在定制环境中。
默认值:false。
绑定Properties
绑定属性使用格式spring.cloud.stream.bindings..=提供。表示正在配置的通道的名称(例如Source的output)。
为了避免重复,Spring Cloud Stream支持所有通道的设置值,格式为spring.cloud.stream.default.=。
在下面的内容中,我们指出我们在哪里省略了spring.cloud.stream.bindings..前缀,并且只关注属性名称,但有一个理解,前缀将被包含在运行时。
Properties使用Spring Cloud Stream
以下绑定属性可用于输入和输出绑定,并且必须以spring.cloud.stream.bindings..为前缀,例如spring.cloud.stream.bindings.input.destination=ticktock。
可以使用前缀spring.cloud.stream.default设置默认值,例如spring.cloud.stream.default.contentType=application/json。
目的地
绑定中间件上的通道的目标目标(例如,RabbitMQ交换或Kafka主题)。如果通道绑定为消费者,则可以将其绑定到多个目标,并且目标名称可以指定为逗号分隔的字符串值。如果未设置,则使用通道名称。此属性的默认值不能被覆盖。
组
渠道的消费群体。仅适用于入站绑定。参见消费者群体。
默认值:null(表示匿名消费者)。
内容类型
频道的内容类型。
默认值:null(以便不执行类型强制)。
粘合剂
这种绑定使用的粘合剂。有关详细信息,请参阅Classpath上的Multiple Binders。
默认值:null(默认的binder将被使用,如果存在)。
消费者物业
以下绑定属性仅适用于输入绑定,并且必须以spring.cloud.stream.bindings..consumer.为前缀,例如spring.cloud.stream.bindings.input.consumer.concurrency=3。
默认值可以使用前缀spring.cloud.stream.default.consumer设置,例如spring.cloud.stream.default.consumer.headerMode=raw。
并发
入站消费者的并发性。
默认值:1。
分区
消费者是否从分区生产者接收数据。
默认值:false。
headerMode
设置为raw时,禁用输入头文件解析。仅适用于不支持消息头的消息中间件,并且需要头部嵌入。入站数据来自外部Spring Cloud Stream应用程序时很有用。
默认值:embeddedHeaders。
maxAttempts
如果处理失败,则尝试处理消息的次数(包括第一个)。设置为1以禁用重试。
默认值:3。
backOffInitialInterval
退避初始间隔重试。
默认值:1000。
backOffMaxInterval
最大回退间隔。
默认值:10000。
backOffMultiplier
退避倍数。
默认值:2.0。
instanceIndex
当设置为大于等于零的值时,允许自定义此消费者的实例索引(如果与spring.cloud.stream.instanceIndex不同)。设置为负值时,它将默认为spring.cloud.stream.instanceIndex。
默认值:-1。
instanceCount
当设置为大于等于零的值时,允许自定义此消费者的实例计数(如果与spring.cloud.stream.instanceCount不同)。当设置为负值时,它将默认为spring.cloud.stream.instanceCount。
默认值:-1。
制作人Properties
以下绑定属性仅可用于输出绑定,并且必须以spring.cloud.stream.bindings..producer.为前缀,例如spring.cloud.stream.bindings.input.producer.partitionKeyExpression=payload.id。
默认值可以使用前缀spring.cloud.stream.default.producer设置,例如spring.cloud.stream.default.producer.partitionKeyExpression=payload.id。
partitionKeyExpression
一个确定如何分配出站数据的SpEL表达式。如果设置,或者如果设置了partitionKeyExtractorClass,则该通道上的出站数据将被分区,并且partitionCount必须设置为大于1的值才能生效。这两个选项是相互排斥的。请参阅分区支持。
默认值:null。
partitionKeyExtractorClass
一个PartitionKeyExtractorStrategy实现。如果设置,或者如果设置了partitionKeyExpression,则该通道上的出站数据将被分区,并且partitionCount必须设置为大于1的值才能生效。这两个选项是相互排斥的。请参阅分区支持。
默认值:null。
partitionSelectorClass
一个PartitionSelectorStrategy实现。与partitionSelectorExpression相互排斥。如果没有设置,则分区将被选为hashCode(key) % partitionCount,其中key通过partitionKeyExpression或partitionKeyExtractorClass计算。
默认值:null。
partitionSelectorExpression
用于自定义分区选择的SpEL表达式。与partitionSelectorClass相互排斥。如果没有设置,则分区将被选为hashCode(key) % partitionCount,其中key通过partitionKeyExpression或partitionKeyExtractorClass计算。
默认值:null。
partitionCount
如果启用分区,则数据的目标分区数。如果生产者被分区,则必须设置为大于1的值。在Kafka,解释为提示;而是使用更大的和目标主题的分区计数。
默认值:1。
requiredGroups
生成者必须确保消息传递的组合的逗号分隔列表,即使它们在创建之后启动(例如,通过在RabbitMQ中预先创建持久队列)。
headerMode
设置为raw时,禁用输出上的标题嵌入。仅适用于不支持消息头的消息中间件,并且需要头部嵌入。生成非Spring Cloud Stream应用程序的数据时很有用。
默认值:embeddedHeaders。
useNativeEncoding
当设置为true时,出站消息由客户端库直接序列化,必须相应配置(例如设置适当的Kafka生产者值序列化程序)。当使用此配置时,出站消息编组不是基于绑定的contentType。当使用本地编码时,消费者有责任使用适当的解码器(例如:Kafka消费者价值解串器)来对入站消息进行反序列化。此外,当使用本机编码/解码时,headerMode属性将被忽略,标题不会嵌入到消息中。
默认值:false。
使用动态绑定目的地
除了通过@EnableBinding定义的通道之外,Spring Cloud Stream允许应用程序将消息发送到动态绑定的目的地。这是有用的,例如,当目标目标需要在运行时确定。应用程序可以使用@EnableBinding注册自动注册的BinderAwareChannelResolverbean。
属性“spring.cloud.stream.dynamicDestinations”可用于将动态目标名称限制为预先已知的集合(白名单)。如果属性未设置,任何目的地都可以动态绑定。
可以直接使用BinderAwareChannelResolver,如以下示例所示,其中REST控制器使用路径变量来确定目标通道。
@EnableBinding
@Controller
public class SourceWithDynamicDestination {
@Autowired
private BinderAwareChannelResolver resolver;
@RequestMapping(path = "/{target}", method = POST, consumes = "*/*")
@ResponseStatus(HttpStatus.ACCEPTED)
public void handleRequest(@RequestBody String body, @PathVariable("target") target,
@RequestHeader(HttpHeaders.CONTENT_TYPE) Object contentType) {
sendMessage(body, target, contentType);
}
private void sendMessage(String body, String target, Object contentType) {
resolver.resolveDestination(target).send(MessageBuilder.createMessage(body,
new MessageHeaders(Collections.singletonMap(MessageHeaders.CONTENT_TYPE, contentType))));
}
}
在默认端口8080上启动应用程序后,发送以下数据时:
curl -H "Content-Type: application/json" -X POST -d "customer-1" http://localhost:8080/customers
curl -H "Content-Type: application/json" -X POST -d "order-1" http://localhost:8080/orders
目的地的客户和“订单”是在经纪人中创建的(例如:在Rabbit的情况下进行交换,或者在Kafka的情况下为主题),其名称为“客户”和“订单”,数据被发布到适当的目的地。
BinderAwareChannelResolver是通用的Spring IntegrationDestinationResolver,可以注入其他组件。例如,在使用基于传入JSON消息的target字段的SpEL表达式的路由器中。
@EnableBinding
@Controller
public class SourceWithDynamicDestination {
@Autowired
private BinderAwareChannelResolver resolver;
@RequestMapping(path = "/", method = POST, consumes = "application/json")
@ResponseStatus(HttpStatus.ACCEPTED)
public void handleRequest(@RequestBody String body, @RequestHeader(HttpHeaders.CONTENT_TYPE) Object contentType) {
sendMessage(body, contentType);
}
private void sendMessage(Object body, Object contentType) {
routerChannel().send(MessageBuilder.createMessage(body,
new MessageHeaders(Collections.singletonMap(MessageHeaders.CONTENT_TYPE, contentType))));
}
@Bean(name = "routerChannel")
public MessageChannel routerChannel() {
return new DirectChannel();
}
@Bean
@ServiceActivator(inputChannel = "routerChannel")
public ExpressionEvaluatingRouter router() {
ExpressionEvaluatingRouter router =
new ExpressionEvaluatingRouter(new SpelExpressionParser().parseExpression("payload.target"));
router.setDefaultOutputChannelName("default-output");
router.setChannelResolver(resolver);
return router;
}
}
内容类型和转换
要允许您传播关于已生成消息的内容类型的信息,默认情况下,Spring Cloud Stream附加contentType标头到出站消息。对于不直接支持头文件的中间件,Spring Cloud Stream提供了自己的自动将邮件包裹在自己的信封中的机制。对于支持头文件的中间件,Spring Cloud Stream应用程序可以从非Spring Cloud Stream应用程序接收具有给定内容类型的消息。
Spring Cloud Stream可以通过两种方式处理基于此信息的消息:
通过其入站和出站渠道的contentType设置
通过对@StreamListener注释的方法执行的参数映射
Spring Cloud Stream允许您使用绑定的spring.cloud.stream.bindings..content-type属性声明性地配置输入和输出的类型转换。请注意,一般类型转换也可以通过在应用程序中使用变压器轻松实现。目前,Spring Cloud Stream本机支持流中常用的以下类型转换:
来自/从POJO的JSON
JSON/从org.springframework.tuple.Tuple
对象到/来自byte []:用于远程传输的原始字节序列化,应用程序发出的字节,或使用Java序列化转换为字节(要求对象为Serializable)
字符串到/来自byte []
对象到纯文本(调用对象的toString()方法)
其中JSON表示包含JSON的字节数组或字符串有效负载。目前,对象可以从JSON字节数组或字符串转换。转换为JSON总是产生一个String。
如果在出站通道上没有设置content-type属性,则Spring Cloud Stream将使用基于Kryo序列化框架的序列化程序对有效负载进行序列化。在目的地反序列化消息需要在接收者的类路径上存在有效载荷类。
MIME类型
content-type值被解析为媒体类型,例如application/json或text/plain;charset=UTF-8。MIME类型对于指示如何转换为String或byte []内容特别有用。Spring Cloud Stream还使用MIME类型格式来表示Java类型,使用具有type参数的一般类型application/x-java-object。例如,application/x-java-object;type=java.util.Map或application/x-java-object;type=com.bar.Foo可以设置为输入绑定的content-type属性。此外,Spring Cloud Stream提供自定义MIME类型,特别是application/x-spring-tuple来指定元组。
MIME类型和Java类型
类型转换Spring Cloud Stream提供的开箱即用如下表所示:“源有效载荷”是指转换前的有效载荷,“目标有效载荷”是指转换后的“有效载荷”。类型转换可以在“生产者”一侧(输出)或“消费者”一侧(输入)上进行。
来源有效载荷目标有效载荷content-type标题(来源讯息)content-type标题(转换后)注释
POJO
JSON String
ignored
application/json
Tuple
JSON String
ignored
application/json
JSON是为Tuple量身定制的
POJO
String (toString())
ignored
text/plain, java.lang.String
POJO
byte[] (java.io serialized)
ignored
application/x-java-serialized-object
JSON byte[] or String
POJO
application/json (or none)
application/x-java-object
byte[] or String
Serializable
application/x-java-serialized-object
application/x-java-object
JSON byte[] or String
Tuple
application/json (or none)
application/x-spring-tuple
byte[]
String
any
text/plain, java.lang.String
将应用在content-type头中指定的任何Charset
String
byte[]
any
application/octet-stream
将应用在content-type头中指定的任何Charset
注意
转换适用于需要类型转换的有效内容。例如,如果应用程序生成带有outputType = application / json的XML字符串,则该有效载荷将不会从XML转换为JSON。这是因为发送到出站通道的有效载荷已经是一个String,所以在运行时不会应用转换。同样重要的是要注意,当使用默认的序列化机制时,必须在发送和接收应用程序之间共享有效负载类,并且与二进制内容兼容。当应用程序代码在两个应用程序中独立更改时,这可能会产生问题,因为二进制格式和代码可能会变得不兼容。
小费
虽然入站和出站渠道都支持转换,但特别推荐将其用于转发出站邮件。对于入站邮件的转换,特别是当目标是POJO时,@StreamListener支持将自动执行转换。
自定义邮件转换
除了支持开箱即用的转换,Spring Cloud Stream还支持注册您自己的邮件转换实现。这允许您以各种自定义格式(包括二进制)发送和接收数据,并将其与特定的contentTypes关联。Spring Cloud Stream将所有类型为org.springframework.messaging.converter.MessageConverter的bean注册为自定义消息转换器以及开箱即用消息转换器。
如果您的消息转换器需要使用特定的content-type和目标类(用于输入和输出),则消息转换器需要扩展org.springframework.messaging.converter.AbstractMessageConverter。对于使用@StreamListener的转换,实现org.springframework.messaging.converter.MessageConverter的消息转换器就足够了。
以下是在Spring Cloud Stream应用程序中创建消息转换器bean(内容类型为application/bar)的示例:
@EnableBinding(Sink.class)
@SpringBootApplication
public static class SinkApplication {
...
@Bean
public MessageConverter customMessageConverter() {
return new MyCustomMessageConverter();
}
public class MyCustomMessageConverter extends AbstractMessageConverter {
public MyCustomMessageConverter() {
super(new MimeType("application", "bar"));
}
@Override
protected boolean supports(Class clazz) {
return (Bar.class == clazz);
}
@Override
protected Object convertFromInternal(Message message, Class targetClass, Object conversionHint) {
Object payload = message.getPayload();
return (payload instanceof Bar ? payload : new Bar((byte[]) payload));
}
}
Spring Cloud Stream还为基于Avro的转换器和模式演进提供支持。详情请参阅具体章节。
@StreamListener和讯息转换
@StreamListener注释提供了一种方便的方式来转换传入的消息,而不需要指定输入通道的内容类型。在使用@StreamListener注释的方法的调度过程中,如果参数需要转换,将自动应用转换。
例如,让我们考虑一个带有{"greeting":"Hello, world"}的String内容的消息,并且在输入通道上收到application/json的application/json标题。让我们考虑接收它的以下应用程序:
public class GreetingMessage {
String greeting;
public String getGreeting() {
return greeting;
}
public void setGreeting(String greeting) {
this.greeting = greeting;
}
}
@EnableBinding(Sink.class)
@EnableAutoConfiguration
public static class GreetingSink {
@StreamListener(Sink.INPUT)
public void receive(Greeting greeting) {
// handle Greeting
}
}
该方法的参数将自动填充包含JSON字符串的未编组形式的POJO。
Schema进化支持
Spring Cloud Stream通过其spring-cloud-stream-schema模块为基于模式的消息转换器提供支持。目前,基于模式的消息转换器开箱即用的唯一序列化格式是Apache Avro,在将来的版本中可以添加更多的格式。
Apache Avro讯息转换器
spring-cloud-stream-schema模块包含可用于Apache Avro序列化的两种类型的消息转换器:
使用序列化/反序列化对象的类信息的转换器,或者启动时已知位置的模式;
转换器使用模式注册表 - 他们在运行时定位模式,以及随着域对象的发展动态注册新模式。
具有模式支持的转换器
AvroSchemaMessageConverter支持使用预定义模式或使用类中可用的模式信息(反射或包含在SpecificRecord)中的序列化和反序列化消息。如果转换的目标类型是GenericRecord,则必须设置模式。
对于使用它,您可以简单地将其添加到应用程序上下文中,可选地指定一个或多个MimeTypes将其关联。默认MimeType为application/avro。
以下是在注册Apache AvroMessageConverter的宿应用程序中进行配置的示例,而不需要预定义的模式:
@EnableBinding(Sink.class)
@SpringBootApplication
public static class SinkApplication {
...
@Bean
public MessageConverter userMessageConverter() {
return new AvroSchemaMessageConverter(MimeType.valueOf("avro/bytes"));
}
}
相反,这里是一个应用程序,注册一个具有预定义模式的转换器,可以在类路径中找到:
@EnableBinding(Sink.class)
@SpringBootApplication
public static class SinkApplication {
...
@Bean
public MessageConverter userMessageConverter() {
AvroSchemaMessageConverter converter = new AvroSchemaMessageConverter(MimeType.valueOf("avro/bytes"));
converter.setSchemaLocation(new ClassPathResource("schemas/User.avro"));
return converter;
}
}
为了了解模式注册表客户端转换器,我们将首先描述模式注册表支持。
Schema注册表支持
大多数序列化模型,特别是旨在跨不同平台和语言进行可移植性的序列化模型,依赖于描述数据如何在二进制有效载荷中被序列化的模式。为了序列化数据然后解释它,发送方和接收方都必须访问描述二进制格式的模式。在某些情况下,可以从序列化的有效载荷类型或从反序列化时的目标类型中推断出模式,但是在许多情况下,应用程序可以从访问描述二进制数据格式的显式模式中受益。模式注册表允许您以文本格式(通常为JSON)存储模式信息,并使该信息可访问需要它的各种应用程序以二进制格式接收和发送数据。一个模式可以作为一个元组引用,它由
作为模式的逻辑名称的主题;
模式版本;
描述数据的二进制格式的模式格式。
Schema注册服务器
Spring Cloud Stream提供了模式注册表服务器实现。为了使用它,您可以简单地将spring-cloud-stream-schema-server工件添加到项目中,并使用@EnableSchemaRegistryServer注释,将模式注册表服务器REST控制器添加到应用程序中。此注释旨在与Spring Boot Web应用程序一起使用,服务器的监听端口由server.port设置控制。spring.cloud.stream.schema.server.path设置可用于控制模式服务器的根路径(特别是嵌入其他应用程序时)。spring.cloud.stream.schema.server.allowSchemaDeletion布尔设置可以删除模式。默认情况下,这是禁用的。
模式注册表服务器使用关系数据库来存储模式。默认情况下,它使用一个嵌入式数据库。您可以使用Spring Boot SQL数据库和JDBC配置选项自定义模式存储。
启用模式注册表的Spring Boot应用程序如下所示:
@SpringBootApplication
@EnableSchemaRegistryServer
public class SchemaRegistryServerApplication {
public static void main(String[] args) {
SpringApplication.run(SchemaRegistryServerApplication.class, args);
}
}
Schema注册服务器API
Schema注册服务器API由以下操作组成:
POST /
注册一个新的架构
接受具有以下字段的JSON有效载荷:
subject模式主题;
format模式格式;
definition模式定义。
响应是JSON格式的模式对象,包含以下字段:
id模式标识;
subject模式主题;
format模式格式;
version模式版本;
definition模式定义。
GET /{subject}/{format}/{version}
根据其主题,格式和版本检索现有模式。
响应是JSON格式的模式对象,包含以下字段:
id模式标识;
subject模式主题;
format模式格式;
version模式版本;
definition模式定义。
GET /{subject}/{format}
根据其主题和格式检索现有模式的列表。
响应是JSON格式的每个模式对象的模式列表,包含以下字段:
id模式标识;
subject模式主题;
format模式格式;
version模式版本;
definition模式定义。
GET /schemas/{id}
通过其id来检索现有的模式。
响应是JSON格式的模式对象,包含以下字段:
id模式标识;
subject模式主题;
format模式格式;
version模式版本;
definition模式定义。
DELETE /{subject}/{format}/{version}
按其主题,格式和版本删除现有模式。
DELETE /schemas/{id}
按其ID删除现有模式。
DELETE /{subject}
按其主题删除现有模式。
注意
本说明仅适用于Spring Cloud Stream 1.1.0.RELEASE的用户。Spring Cloud Stream 1.1.0.RELEASE使用表名schema存储Schema对象,这是一些数据库实现中的关键字。为了避免将来发生任何冲突,从1.1.1.RELEASE开始,我们选择了存储表的名称SCHEMA_REPOSITORY。建议任何正在升级的Spring Cloud Stream 1.1.0.RELEASE用户在升级之前将其现有模式迁移到新表。
Schema注册表客户端
与模式注册表服务器交互的客户端抽象是SchemaRegistryClient接口,具有以下结构:
public interface SchemaRegistryClient {
SchemaRegistrationResponse register(String subject, String format, String schema);
String fetch(SchemaReference schemaReference);
String fetch(Integer id);
}
Spring Cloud Stream提供了开箱即用的实现,用于与其自己的模式服务器交互,以及与Confluent Schema注册表进行交互。
可以使用@EnableSchemaRegistryClient配置Spring Cloud Stream模式注册表的客户端,如下所示:
@EnableBinding(Sink.class)
@SpringBootApplication
@EnableSchemaRegistryClient
public static class AvroSinkApplication {
...
}
注意
优化了默认转换器,以缓存来自远程服务器的模式,而且还会非常昂贵的parse()和toString()方法。因此,它使用不缓存响应的DefaultSchemaRegistryClient。如果您打算直接在代码上使用客户端,您可以请求一个也缓存要创建的响应的bean。为此,只需将属性spring.cloud.stream.schemaRegistryClient.cached=true添加到应用程序属性中即可。
Schema注册表客户端属性
Schema注册表客户端支持以下属性:
spring.cloud.stream.schemaRegistryClient.endpoint
模式服务器的位置。在设置时使用完整的URL,包括协议(http或https),端口和上下文路径。
默认
http://localhost:8990/
spring.cloud.stream.schemaRegistryClient.cached
客户端是否应缓存模式服务器响应。通常设置为false,因为缓存发生在消息转换器中。使用模式注册表客户端的客户端应将其设置为true。
默认
true
Avro Schema注册表客户端消息转换器
对于在应用程序上下文中注册了SchemaRegistryClientbean的Spring Boot应用程序,Spring Cloud Stream将自动配置使用模式注册表客户端进行模式管理的Apache Avro消息转换器。这简化了模式演进,因为接收消息的应用程序可以轻松访问可与自己的读取器模式进行协调的写入器模式。
对于出站邮件,如果频道的内容类型设置为application/*+avro,MessageConverter将被激活,例如:
spring.cloud.stream.bindings.output.contentType=application/*+avro
在出站转换期间,消息转换器将尝试基于其类型推断出站消息的模式,并使用SchemaRegistryClient根据有效载荷类型将其注册到主题。如果已经找到相同的模式,那么将会检索对它的引用。如果没有,则将注册模式并提供新的版本号。该消息将使用application/[prefix].[subject].v[version]+avro的方案contentType头发送,其中prefix是可配置的,并且从有效载荷类型推导出subject。
例如,类型为User的消息可以作为内容类型为application/vnd.user.v2+avro的二进制有效载荷发送,其中user是主题,2是版本号。
当接收到消息时,转换器将从传入消息的头部推断出模式引用,并尝试检索它。该模式将在反序列化过程中用作写入器模式。
Avro Schema注册表消息转换器属性
如果您已通过设置spring.cloud.stream.bindings.output.contentType=application/*+avro启用基于Avro的模式注册表客户端,则可以使用以下属性自定义注册的行为。
spring.cloud.stream.schema.avro.dynamicSchemaGenerationEnabled
如果您希望转换器使用反射从POJO推断Schema,则启用。
默认
false
spring.cloud.stream.schema.avro.readerSchema
Avro通过查看编写器模式(源有效载荷)和读取器模式(应用程序有效负载)来比较模式版本,查看Avro文档以获取更多信息。如果设置,这将覆盖模式服务器上的任何查找,并将本地模式用作读取器模式。
默认
null
spring.cloud.stream.schema.avro.schemaLocations
使用Schema服务器注册此属性中列出的任何.avsc文件。
默认
empty
spring.cloud.stream.schema.avro.prefix
要在Content-Type头上使用的前缀。
默认
vnd
Schema注册和解决
为了更好地了解Spring Cloud Stream注册和解决新模式以及其使用Avro模式比较功能,我们将提供两个单独的子部分:一个用于注册,一个用于解析模式。
Schema注册流程(序列化)
注册过程的第一部分是从通过信道发送的有效载荷中提取模式。Avro类型,如SpecificRecord或GenericRecord已经包含一个模式,可以从实例中立即检索。在POJO的情况下,如果属性spring.cloud.stream.schema.avro.dynamicSchemaGenerationEnabled设置为true(默认),则会推断出一个模式。
图10. Schema Writer Resolution Process
一旦获得了架构,转换器就会从远程服务器加载其元数据(版本)。首先,它查询本地缓存,如果没有找到它,则将数据提交到将使用版本控制信息回复的服务器。转换器将始终缓存结果,以避免为每个需要序列化的新消息查询Schema服务器的开销。
图11. Schema注册流程
使用模式版本信息,转换器设置消息的contentType头,以携带版本信息,如application/vnd.user.v1+avro
Schema解析过程(反序列化)
当读取包含版本信息的消息(即,具有上述方案的contentType标头)时,转换器将查询Schema服务器以获取消息的写入器架构。一旦找到传入消息的正确架构,它就会检索读取器架构,并使用Avro的架构解析支持将其读入读取器定义(设置默认值和缺少的属性)。
图12. Schema阅读决议程序
注意
了解编写器架构(写入消息的应用程序)和读取器架构(接收应用程序)之间的区别很重要。请花点时间阅读Avro术语并了解此过程。Spring Cloud Stream将始终提取writer模式以确定如何读取消息。如果您想要Avro的架构演进支持工作,您需要确保为您的应用程序正确设置了readerSchema。
应用间通信
连接多个应用程序实例
虽然Spring Cloud Stream使个人Spring Boot应用程序轻松连接到消息传递系统,但是Spring Cloud Stream的典型场景是创建多应用程序管道,其中微服务应用程序将数据发送给彼此。您可以通过将相邻应用程序的输入和输出目标相关联来实现此场景。
假设设计要求时间源应用程序将数据发送到日志接收应用程序,则可以在两个应用程序中使用名为ticktock的公共目标进行绑定。
时间来源(具有频道名称output)将设置以下属性:
spring.cloud.stream.bindings.output.destination=ticktock
日志接收器(通道名称为input)将设置以下属性:
spring.cloud.stream.bindings.input.destination=ticktock
实例索引和实例计数
当扩展Spring Cloud Stream应用程序时,每个实例都可以接收有关同一个应用程序的其他实例数量以及自己的实例索引的信息。Spring Cloud Stream通过spring.cloud.stream.instanceCount和spring.cloud.stream.instanceIndex属性执行此操作。例如,如果HDFS宿应用程序有三个实例,则所有三个实例将spring.cloud.stream.instanceCount设置为3,并且各个应用程序将spring.cloud.stream.instanceIndex设置为0,1和2。
当通过Spring Cloud数据流部署Spring Cloud Stream应用程序时,这些属性将自动配置;当Spring Cloud Stream应用程序独立启动时,必须正确设置这些属性。默认情况下,spring.cloud.stream.instanceCount为1,spring.cloud.stream.instanceIndex为0。
在放大的情况下,这两个属性的正确配置对于解决分区行为(见下文)一般很重要,并且某些绑定器(例如,Kafka binder)总是需要这两个属性,以确保该数据在多个消费者实例之间正确分割。
分区
配置输出绑定进行分区
输出绑定被配置为通过设置其唯一的一个partitionKeyExpression或partitionKeyExtractorClass属性以及其partitionCount属性来发送分区数据。例如,以下是一个有效和典型的配置:
spring.cloud.stream.bindings.output.producer.partitionKeyExpression=payload.id
spring.cloud.stream.bindings.output.producer.partitionCount=5
基于上述示例配置,使用以下逻辑将数据发送到目标分区。
基于partitionKeyExpression,为发送到分区输出通道的每个消息计算分区密钥的值。partitionKeyExpression是一个Spel表达式,它根据出站消息进行评估,以提取分区键。
如果SpEL表达式不足以满足您的需要,您可以通过将属性partitionKeyExtractorClass设置为实现org.springframework.cloud.stream.binder.PartitionKeyExtractorStrategy接口的类来计算分区键值。虽然Spel表达式通常足够,但更复杂的情况可能会使用自定义实现策略。在这种情况下,属性“partitionKeyExtractorClass”可以设置如下:
spring.cloud.stream.bindings.output.producer.partitionKeyExtractorClass=com.example.MyKeyExtractor
spring.cloud.stream.bindings.output.producer.partitionCount=5
一旦计算了消息密钥,分区选择过程将确定目标分区为0和partitionCount - 1之间的值。在大多数情况下,默认计算基于公式key.hashCode() % partitionCount。这可以通过设置要针对'key'(通过partitionSelectorExpression属性)进行评估的Spel表达式或通过设置org.springframework.cloud.stream.binder.PartitionSelectorStrategy实现(通过partitionSelectorClass属性))进行自定义。
“partitionSelectorExpression”和“partitionSelectorClass”的绑定级属性可以类似于上述示例中指定的“partitionKeyExpression”和“partitionKeyExtractorClass”属性的类型。可以为更高级的场景配置其他属性,如以下部分所述。
Spring - 管理的自定义PartitionKeyExtractorClass实现
在上面的示例中,MyKeyExtractor之类的自定义策略由Spring Cloud Stream直接实例化。在某些情况下,必须将这样的自定义策略实现创建为Spring bean,以便能够由Spring管理,以便它可以执行依赖注入,属性绑定等。可以通过将其配置为应用程序上下文中的@Bean,并使用完全限定类名作为bean的名称,如以下示例所示。
@Bean(name="com.example.MyKeyExtractor")
public MyKeyExtractor extractor() {
return new MyKeyExtractor();
}
作为Spring bean,自定义策略从Spring bean的完整生命周期中受益。例如,如果实现需要直接访问应用程序上下文,则可以实现“ApplicationContextAware”。
配置输入绑定进行分区
输入绑定(通道名称为input)被配置为通过在应用程序本身设置其partitioned属性以及instanceIndex和instanceCount属性来接收分区数据,如以下示例:
spring.cloud.stream.bindings.input.consumer.partitioned=true
spring.cloud.stream.instanceIndex=3
spring.cloud.stream.instanceCount=5
instanceCount值表示数据需要分区的应用程序实例的总数,instanceIndex必须是0和instanceCount - 1之间的多个实例的唯一值。实例索引帮助每个应用程序实例识别从其接收数据的唯一分区(或者在Kafka的分区集合的情况下)。重要的是正确设置两个值,以确保所有数据都被使用,并且应用程序实例接收到互斥数据集。
虽然使用多个实例进行分区数据处理的场景可能会在独立情况下进行复杂化,但是通过将输入和输出值正确填充并依赖于运行时基础架构,Spring Cloud数据流可以显着简化流程。提供有关实例索引和实例计数的信息。
测试
Spring Cloud Stream支持测试您的微服务应用程序,而无需连接到消息系统。您可以使用spring-cloud-stream-test-support库提供的TestSupportBinder,可以将其作为测试依赖项添加到应用程序中:
org.springframework.cloud
spring-cloud-stream-test-support
test
注意
TestSupportBinder使用Spring Boot自动配置机制取代类路径中找到的其他绑定。因此,添加binder作为依赖关系时,请确保正在使用test范围。
TestSupportBinder允许用户与绑定的频道进行交互,并检查应用程序发送和接收的消息
对于出站消息通道,TestSupportBinder注册单个订户,并将应用程序发送的消息保留在MessageCollector中。它们可以在测试过程中被检索,并对它们做出断言。
用户还可以将消息发送到入站消息通道,以便消费者应用程序可以使用消息。以下示例显示了如何在处理器上测试输入和输出通道。
@RunWith(SpringRunner.class)
@SpringBootTest(webEnvironment= SpringBootTest.WebEnvironment.RANDOM_PORT)
public class ExampleTest {
@Autowired
private Processor processor;
@Autowired
private MessageCollector messageCollector;
@Test
@SuppressWarnings("unchecked")
public void testWiring() {
Message message = new GenericMessage<>("hello");
processor.input().send(message);
Message received = (Message) messageCollector.forChannel(processor.output()).poll();
assertThat(received.getPayload(), equalTo("hello world"));
}
@SpringBootApplication
@EnableBinding(Processor.class)
public static class MyProcessor {
@Autowired
private Processor channels;
@Transformer(inputChannel = Processor.INPUT, outputChannel = Processor.OUTPUT)
public String transform(String in) {
return in + " world";
}
}
}
在上面的示例中,我们正在创建一个具有输入和输出通道的应用程序,通过Processor接口绑定。绑定的接口被注入测试,所以我们可以访问这两个通道。我们正在输入频道发送消息,我们使用Spring Cloud Stream测试支持提供的MessageCollector来捕获消息已经被发送到输出通道。收到消息后,我们可以验证组件是否正常工作。
健康指标
Spring Cloud Stream为粘合剂提供健康指标。它以binders的名义注册,可以通过设置management.health.binders.enabled属性启用或禁用。
指标发射器
Spring Cloud Stream提供了一个名为spring-cloud-stream-metrics的模块,可以用来从Spring Boot度量端点到命名通道发出任何可用度量。该模块允许运营商从流应用收集指标,而不依赖轮询其端点。
当您设置度量绑定的目标名称(例如spring.cloud.stream.bindings.applicationMetrics.destination=)时,该模块将被激活。可以以与任何其他生成器绑定相似的方式配置applicationMetrics。applicationMetrics的contentType默认设置为application/json。
以下属性可用于自定义度量标准的排放:
spring.cloud.stream.metrics.key
要发射的度量的名称。应该是每个应用程序的唯一值。
默认
${spring.application.name:${vcap.application.name:${spring.config.name:application}}}
spring.cloud.stream.metrics.prefix
前缀字符串,以前缀到度量键。
默认值:``
spring.cloud.stream.metrics.properties
就像includes选项一样,它允许将白名单应用程序属性添加到度量有效负载
默认值:null。
有关度量导出过程的详细概述,请参见Spring Boot参考文档。Spring Cloud Stream提供了一个名为application的指标导出器,可以通过常规Spring Boot指标配置属性进行配置。
可以通过使用出口商的全局Spring Boot配置设置或使用特定于导出器的属性来配置导出器。要使用全局配置设置,属性应以spring.metric.export为前缀(例如spring.metric.export.includes=integration**)。这些配置选项将适用于所有出口商(除非它们的配置不同)。或者,如果要使用与其他出口商不同的配置设置(例如,限制发布的度量数量),则可以使用前缀spring.metrics.export.triggers.application配置Spring Cloud Stream提供的度量导出器(例如spring.metrics.export.triggers.application.includes=integration**)。
注意
由于Spring Boot的轻松约束,所包含的属性的值可能与原始值稍有不同。
作为经验法则,度量导出器将尝试使用点符号(例如JAVA_HOME成为java.home)以一致的格式标准化所有属性。
规范化的目标是使下游用户能够始终如一地接收属性名称,无论它们如何设置在受监视的应用程序上(--spring.application.name或SPRING_APPLICATION_NAME始终会生成spring.application.name)。
以下是通过以下命令以JSON格式发布到频道的数据的示例:
java -jar time-source.jar \
--spring.cloud.stream.bindings.applicationMetrics.destination=someMetrics \
--spring.cloud.stream.metrics.properties=spring.application** \
--spring.metrics.export.includes=integration.channel.input**,integration.channel.output**
得到的JSON是:
{
"name":"time-source",
"metrics":[
{
"name":"integration.channel.output.errorRate.mean",
"value":0.0,
"timestamp":"2017-04-11T16:56:35.790Z"
},
{
"name":"integration.channel.output.errorRate.max",
"value":0.0,
"timestamp":"2017-04-11T16:56:35.790Z"
},
{
"name":"integration.channel.output.errorRate.min",
"value":0.0,
"timestamp":"2017-04-11T16:56:35.790Z"
},
{
"name":"integration.channel.output.errorRate.stdev",
"value":0.0,
"timestamp":"2017-04-11T16:56:35.790Z"
},
{
"name":"integration.channel.output.errorRate.count",
"value":0.0,
"timestamp":"2017-04-11T16:56:35.790Z"
},
{
"name":"integration.channel.output.sendCount",
"value":6.0,
"timestamp":"2017-04-11T16:56:35.790Z"
},
{
"name":"integration.channel.output.sendRate.mean",
"value":0.994885872292989,
"timestamp":"2017-04-11T16:56:35.790Z"
},
{
"name":"integration.channel.output.sendRate.max",
"value":1.006247080013156,
"timestamp":"2017-04-11T16:56:35.790Z"
},
{
"name":"integration.channel.output.sendRate.min",
"value":1.0012035220116378,
"timestamp":"2017-04-11T16:56:35.790Z"
},
{
"name":"integration.channel.output.sendRate.stdev",
"value":6.505181111084848E-4,
"timestamp":"2017-04-11T16:56:35.790Z"
},
{
"name":"integration.channel.output.sendRate.count",
"value":6.0,
"timestamp":"2017-04-11T16:56:35.790Z"
}
],
"createdTime":"2017-04-11T20:56:35.790Z",
"properties":{
"spring.application.name":"time-source",
"spring.application.index":"0"
}
}
样品
对于Spring Cloud Stream示例,请参阅GitHub上的spring-cloud-stream样本存储库。
入门
要开始创建Spring Cloud Stream应用程序,请访问Spring Initializr并创建一个名为“GreetingSource”的新Maven项目。在下拉菜单中选择Spring Boot {supported-spring-boot-version}。在“搜索依赖关系”文本框中键入Stream Rabbit或Stream Kafka,具体取决于您要使用的binder。
接下来,在与GreetingSourceApplication类相同的包中创建一个新类GreetingSource。给它以下代码:
import org.springframework.cloud.stream.annotation.EnableBinding;
import org.springframework.cloud.stream.messaging.Source;
import org.springframework.integration.annotation.InboundChannelAdapter;
@EnableBinding(Source.class)
public class GreetingSource {
@InboundChannelAdapter(Source.OUTPUT)
public String greet() {
return "hello world " + System.currentTimeMillis();
}
}
@EnableBinding注释是触发Spring Integration基础架构组件的创建。具体来说,它将创建一个Kafka连接工厂,一个Kafka出站通道适配器,并在Source界面中定义消息通道:
public interface Source {
String OUTPUT = "output";
@Output(Source.OUTPUT)
MessageChannel output();
}
自动配置还创建一个默认轮询器,以便每秒调用greet()方法一次。标准的Spring Integration@InboundChannelAdapter注释使用返回值作为消息的有效内容向源的输出通道发送消息。
要测试驱动此设置,请运行Kafka消息代理。一个简单的方法是使用Docker镜像:
# On OS X
$ docker run -p 2181:2181 -p 9092:9092 --env ADVERTISED_HOST=`docker-machine ip \`docker-machine active\`` --env ADVERTISED_PORT=9092 spotify/kafka
# On Linux
$ docker run -p 2181:2181 -p 9092:9092 --env ADVERTISED_HOST=localhost --env ADVERTISED_PORT=9092 spotify/kafka
构建应用程序:
./mvnw clean package
消费者应用程序以类似的方式进行编码。返回Initializr并创建另一个名为LoggingSink的项目。然后在与类LoggingSinkApplication相同的包中创建一个新类LoggingSink,并使用以下代码:
import org.springframework.cloud.stream.annotation.EnableBinding;
import org.springframework.cloud.stream.annotation.StreamListener;
import org.springframework.cloud.stream.messaging.Sink;
@EnableBinding(Sink.class)
public class LoggingSink {
@StreamListener(Sink.INPUT)
public void log(String message) {
System.out.println(message);
}
}
构建应用程序:
./mvnw clean package
要将GreetingSource应用程序连接到LoggingSink应用程序,每个应用程序必须共享相同的目标名称。启动这两个应用程序如下所示,您将看到消费者应用程序打印“hello world”和时间戳到控制台:
cd GreetingSource
java -jar target/GreetingSource-0.0.1-SNAPSHOT.jar --spring.cloud.stream.bindings.output.destination=mydest
cd LoggingSink
java -jar target/LoggingSink-0.0.1-SNAPSHOT.jar --server.port=8090 --spring.cloud.stream.bindings.input.destination=mydest
(不同的服务器端口可以防止两个应用程序中用于维护Spring Boot执行器端点的HTTP端口的冲突。)
LoggingSink应用程序的输出将如下所示:
[ main] s.b.c.e.t.TomcatEmbeddedServletContainer : Tomcat started on port(s): 8090 (http)
[ main] com.example.LoggingSinkApplication : Started LoggingSinkApplication in 6.828 seconds (JVM running for 7.371)
hello world 1458595076731
hello world 1458595077732
hello world 1458595078733
hello world 1458595079734
hello world 1458595080735
Binder实施
Apache Kafka Binder
用法
对于使用Apache Kafka绑定器,您只需要使用以下Maven坐标将其添加到您的Spring Cloud Stream应用程序:
org.springframework.cloud
spring-cloud-stream-binder-kafka
或者,您也可以使用Spring Cloud Stream Kafka Starter。
org.springframework.cloud
spring-cloud-starter-stream-kafka
Apache Kafka Binder概述
以下可以看到Apache Kafka绑定器操作的简化图。
图13. Kafka Binder
Apache Kafka Binder实现将每个目标映射到Apache Kafka主题。消费者组织直接映射到相同的Apache Kafka概念。分区也直接映射到Apache Kafka分区。
配置选项
本节包含Apache Kafka绑定器使用的配置选项。
有关binder的常见配置选项和属性,请参阅核心文档。
Kafka Binder Properties
spring.cloud.stream.kafka.binder.brokers
Kafka活页夹将连接的经纪人列表。
默认值:localhost。
spring.cloud.stream.kafka.binder.defaultBrokerPort
brokers允许使用或不使用端口信息指定的主机(例如,host1,host2:port2)。当在代理列表中没有配置端口时,这将设置默认端口。
默认值:9092。
spring.cloud.stream.kafka.binder.zkNodes
Kafka绑定器可以连接的ZooKeeper节点列表。
默认值:localhost。
spring.cloud.stream.kafka.binder.defaultZkPort
zkNodes允许使用或不使用端口信息指定的主机(例如,host1,host2:port2)。当在节点列表中没有配置端口时,这将设置默认端口。
默认值:2181。
spring.cloud.stream.kafka.binder.configuration
客户端属性(生产者和消费者)的密钥/值映射传递给由绑定器创建的所有客户端。由于这些属性将被生产者和消费者使用,所以使用应该限于常见的属性,特别是安全设置。
默认值:空地图。
spring.cloud.stream.kafka.binder.headers
将由活页夹传送的自定义标题列表。
默认值:空。
spring.cloud.stream.kafka.binder.offsetUpdateTimeWindow
以毫秒为单位的频率(以毫秒为单位)保存偏移量。0忽略。
默认值:10000。
spring.cloud.stream.kafka.binder.offsetUpdateCount
频率,更新次数,哪些消耗的偏移量会持续存在。0忽略。与offsetUpdateTimeWindow相互排斥。
默认值:0。
spring.cloud.stream.kafka.binder.requiredAcks
经纪人所需的acks数量。
默认值:1。
spring.cloud.stream.kafka.binder.minPartitionCount
只有设置autoCreateTopics或autoAddPartitions才有效。绑定器在其生成/消耗数据的主题上配置的全局最小分区数。它可以由生产者的partitionCount设置或生产者的instanceCount*concurrency设置的值替代(如果更大)。
默认值:1。
spring.cloud.stream.kafka.binder.replicationFactor
如果autoCreateTopics处于活动状态,则自动创建主题的复制因子。
默认值:1。
spring.cloud.stream.kafka.binder.autoCreateTopics
如果设置为true,绑定器将自动创建新主题。如果设置为false,则绑定器将依赖于已配置的主题。在后一种情况下,如果主题不存在,则绑定器将无法启动。值得注意的是,此设置与代理的auto.topic.create.enable设置无关,并不影响它:如果服务器设置为自动创建主题,则可以将其创建为元数据检索请求的一部分,并使用默认代理设置。
默认值:true。
spring.cloud.stream.kafka.binder.autoAddPartitions
如果设置为true,则绑定器将根据需要创建新的分区。如果设置为false,则绑定器将依赖于已配置的主题的分区大小。如果目标主题的分区计数小于预期值,则绑定器将无法启动。
默认值:false。
spring.cloud.stream.kafka.binder.socketBufferSize
Kafka消费者使用的套接字缓冲区的大小(以字节为单位)。
默认值:2097152。
Kafka消费者Properties
以下属性仅适用于Kafka消费者,必须以spring.cloud.stream.kafka.bindings..consumer.为前缀。
autoRebalanceEnabled
当true,主题分区将在消费者组的成员之间自动重新平衡。当false根据spring.cloud.stream.instanceCount和spring.cloud.stream.instanceIndex为每个消费者分配一组固定的分区。这需要在每个启动的实例上适当地设置spring.cloud.stream.instanceCount和spring.cloud.stream.instanceIndex属性。在这种情况下,属性spring.cloud.stream.instanceCount通常必须大于1。
默认值:true。
autoCommitOffset
是否在处理邮件时自动提交偏移量。如果设置为false,则入站消息中将显示带有org.springframework.kafka.support.Acknowledgment类型的密钥kafka_acknowledgment的报头。应用程序可以使用此标头来确认消息。有关详细信息,请参阅示例部分。当此属性设置为false时,Kafka binder将ack模式设置为org.springframework.kafka.listener.AbstractMessageListenerContainer.AckMode.MANUAL。
默认值:true。
autoCommitOnError
只有autoCommitOffset设置为true才有效。如果设置为false,它会禁止导致错误的邮件的自动提交,并且只会为成功的邮件执行提交,允许流在上次成功处理的邮件中自动重播,以防持续发生故障。如果设置为true,它将始终自动提交(如果启用了自动提交)。如果没有设置(默认),它实际上具有与enableDlq相同的值,如果它们被发送到DLQ,则自动提交错误的消息,否则不提交它们。
默认值:未设置。
recoveryInterval
连接恢复尝试之间的间隔,以毫秒为单位。
默认值:5000。
resetOffsets
是否将消费者的偏移量重置为startOffset提供的值。
默认值:false。
开始偏移
新组的起始偏移量,或resetOffsets为true时的起始偏移量。允许的值:earliest,latest。如果消费者组被明确设置为消费者'绑定'(通过spring.cloud.stream.bindings..group),那么'startOffset'设置为earliest;否则对于anonymous消费者组,设置为latest。
默认值:null(相当于earliest)。
enableDlq
当设置为true时,它将为消费者发送启用DLQ行为。默认情况下,导致错误的邮件将转发到名为error..的主题。DLQ主题名称可以通过属性dlqName配置。对于错误数量相对较少并且重播整个原始主题可能太麻烦的情况,这为更常见的Kafka重播场景提供了另一种选择。
默认值:false。
组态
使用包含通用Kafka消费者属性的键/值对映射。
默认值:空地图。
dlqName
接收错误消息的DLQ主题的名称。
默认值:null(如果未指定,将导致错误的消息将转发到名为error..的主题)。
Kafka生产者Properties
以下属性仅适用于Kafka生产者,必须以spring.cloud.stream.kafka.bindings..producer.为前缀。
缓冲区大小
上限(以字节为单位),Kafka生产者将在发送之前尝试批量的数据量。
默认值:16384。
同步
生产者是否是同步的
默认值:false。
batchTimeout
生产者在发送之前等待多长时间,以便允许更多消息在同一批次中累积。(通常,生产者根本不等待,并且简单地发送在先前发送进行中累积的所有消息。)非零值可能会以延迟为代价增加吞吐量。
默认值:0。
组态
使用包含通用Kafka生产者属性的键/值对映射。
默认值:空地图。
注意
Kafka绑定器将使用生产者的partitionCount设置作为提示,以创建具有给定分区计数的主题(与minPartitionCount一起使用,最多两个为正在使用的值) 。配置绑定器的minPartitionCount和应用程序的partitionCount时要小心,因为将使用较大的值。如果一个主题已经存在较小的分区计数,并且autoAddPartitions被禁用(默认值),则绑定器将无法启动。如果一个主题已经存在较小的分区计数,并且启用了autoAddPartitions,则会添加新的分区。如果一个主题已经存在的分区数量大于(minPartitionCount和partitionCount)的最大值,则将使用现有的分区计数。
用法示例
在本节中,我们举例说明了上述属性在具体情况下的使用。
示例:设置autoCommitOffsetfalse并依赖手动确认。
该示例说明了如何在消费者应用程序中手动确认偏移量。
此示例要求spring.cloud.stream.kafka.bindings.input.consumer.autoCommitOffset设置为false。使用相应的输入通道名称作为示例。
@SpringBootApplication
@EnableBinding(Sink.class)
public class ManuallyAcknowdledgingConsumer {
public static void main(String[] args) {
SpringApplication.run(ManuallyAcknowdledgingConsumer.class, args);
}
@StreamListener(Sink.INPUT)
public void process(Message message) {
Acknowledgment acknowledgment = message.getHeaders().get(KafkaHeaders.ACKNOWLEDGMENT, Acknowledgment.class);
if (acknowledgment != null) {
System.out.println("Acknowledgment provided");
acknowledgment.acknowledge();
}
}
}
示例:安全配置
Apache Kafka 0.9支持客户端和代理商之间的安全连接。要充分利用此功能,请遵循汇编文档中的Apache Kafka文档以及Kafka 0.9安全性指导原则。使用spring.cloud.stream.kafka.binder.configuration选项为绑定器创建的所有客户端设置安全属性。
例如,要将security.protocol设置为SASL_SSL,请设置:
spring.cloud.stream.kafka.binder.configuration.security.protocol=SASL_SSL
所有其他安全属性可以以类似的方式设置。
使用Kerberos时,请按照参考文档中的说明创建和引用JAAS配置。
Spring Cloud Stream支持使用JAAS配置文件并使用Spring Boot属性将JAAS配置信息传递到应用程序。
使用JAAS配置文件
可以通过使用系统属性为Spring Cloud Stream应用程序设置JAAS和(可选)krb5文件位置。以下是使用JAAS配置文件启动带有SASL和Kerberos的Spring Cloud Stream应用程序的示例:
java -Djava.security.auth.login.config=/path.to/kafka_client_jaas.conf -jar log.jar \
--spring.cloud.stream.kafka.binder.brokers=secure.server:9092 \
--spring.cloud.stream.kafka.binder.zkNodes=secure.zookeeper:2181 \
--spring.cloud.stream.bindings.input.destination=stream.ticktock \
--spring.cloud.stream.kafka.binder.configuration.security.protocol=SASL_PLAINTEXT
使用Spring Boot属性
作为使用JAAS配置文件的替代方案,Spring Cloud Stream提供了一种使用Spring Boot属性为Spring Cloud Stream应用程序设置JAAS配置的机制。
以下属性可用于配置Kafka客户端的登录上下文。
spring.cloud.stream.kafka.binder.jaas.loginModule
登录模块名称。在正常情况下不需要设置。
默认值:com.sun.security.auth.module.Krb5LoginModule。
spring.cloud.stream.kafka.binder.jaas.controlFlag
登录模块的控制标志。
默认值:required。
spring.cloud.stream.kafka.binder.jaas.options
使用包含登录模块选项的键/值对映射。
默认值:空地图。
以下是使用Spring Boot配置属性启动带有SASL和Kerberos的Spring Cloud Stream应用程序的示例:
java --spring.cloud.stream.kafka.binder.brokers=secure.server:9092 \
--spring.cloud.stream.kafka.binder.zkNodes=secure.zookeeper:2181 \
--spring.cloud.stream.bindings.input.destination=stream.ticktock \
--spring.cloud.stream.kafka.binder.autoCreateTopics=false \
--spring.cloud.stream.kafka.binder.configuration.security.protocol=SASL_PLAINTEXT \
--spring.cloud.stream.kafka.binder.jaas.options.useKeyTab=true \
--spring.cloud.stream.kafka.binder.jaas.options.storeKey=true \
--spring.cloud.stream.kafka.binder.jaas.options.keyTab=/etc/security/keytabs/kafka_client.keytab \
--spring.cloud.stream.kafka.binder.jaas.options.principal=kafka-client-1@EXAMPLE.COM
这相当于以下JAAS文件:
KafkaClient {
com.sun.security.auth.module.Krb5LoginModule required
useKeyTab=true
storeKey=true
keyTab="/etc/security/keytabs/kafka_client.keytab"
principal="[email protected]";
};
如果所需的主题已经存在于代理上,或将由管理员创建,则自动创建可以被关闭,并且仅需要发送客户端JAAS属性。作为设置spring.cloud.stream.kafka.binder.autoCreateTopics的替代方法,您可以简单地从应用程序中删除代理依赖关系。有关详细信息,请参阅基于绑定器的应用程序的类路径中排除Kafka代理jar。
注意
不要在同一应用程序中混合JAAS配置文件和Spring Boot属性。如果-Djava.security.auth.login.config系统属性已存在,则Spring Cloud Stream将忽略Spring Boot属性。
注意
使用autoCreateTopics和autoAddPartitions如果使用Kerberos,请务必小心。通常应用程序可能使用Kafka和Zookeeper中没有管理权限的主体,并且依赖Spring Cloud Stream创建/修改主题可能会失败。在安全环境中,我们强烈建议您使用Kafka工具管理性地创建主题并管理ACL。
使用绑定器与Apache Kafka 0.10
Spring Cloud Stream Kafka binder中的默认Kafka支持是针对Kafka版本0.10.1.1的。粘合剂还支持连接到其他0.10版本和0.9客户端。为了做到这一点,当你创建包含你的应用程序的项目时,包括spring-cloud-starter-stream-kafka,你通常会对默认的绑定器做。然后将这些依赖项添加到pom.xml文件中的部分的顶部以覆盖依赖关系。
以下是将应用程序降级到0.10.0.1的示例。由于它仍在0.10行,因此可以保留默认的spring-kafka和spring-integration-kafka版本。
org.apache.kafka
kafka_2.11
0.10.0.1
org.slf4j
slf4j-log4j12
org.apache.kafka
kafka-clients
0.10.0.1
这是使用0.9.0.1版本的另一个例子。
org.springframework.kafka
spring-kafka
1.0.5.RELEASE
org.springframework.integration
spring-integration-kafka
2.0.1.RELEASE
org.apache.kafka
kafka_2.11
0.9.0.1
org.slf4j
slf4j-log4j12
org.apache.kafka
kafka-clients
0.9.0.1
注意
以上版本仅为了举例而提供。为获得最佳效果,我们建议您使用最新的0.10兼容版本的项目。
从基于绑定器的应用程序的类路径中排除Kafka代理jar
Apache Kafka Binder使用作为Apache Kafka服务器库一部分的管理实用程序来创建和重新配置主题。如果在运行时不需要包含Apache Kafka服务器库及其依赖关系,因为应用程序将依赖于管理中配置的主题,Kafka binder允许排除Apache Kafka服务器依赖关系从应用程序。
如果您使用上述建议的Kafka依赖关系的非默认版本,则只需要包含kafka代理依赖项。如果您使用默认的Kafka版本,请确保从spring-cloud-starter-stream-kafka依赖关系中排除kafka broker jar,如下所示。
org.springframework.cloud
spring-cloud-starter-stream-kafka
org.apache.kafka
kafka_2.11
如果您排除Apache Kafka服务器依赖关系,并且该主题不在服务器上,那么如果在服务器上启用了自动主题创建,则Apache Kafka代理将创建该主题。请注意,如果您依赖此,则Kafka服务器将使用默认数量的分区和复制因子。另一方面,如果在服务器上禁用自动主题创建,则在运行应用程序之前必须注意创建具有所需数量分区的主题。
如果要完全控制分区的分配方式,请保留默认设置,即不要排除kafka代理程序jar,并确保将spring.cloud.stream.kafka.binder.autoCreateTopics设置为true,这是默认设置。
Dead-Letter主题处理
因为不可能预料到用户如何处理死信消息,所以框架不提供任何标准的机制来处理它们。如果死刑的原因是短暂的,您可能希望将邮件路由到原始主题。但是,如果问题是一个永久性的问题,那可能会导致无限循环。以下spring-boot应用程序是如何将这些消息路由到原始主题的示例,但在三次尝试后将其移动到第三个“停车场”主题。该应用程序只是从死信主题中读取的另一个spring-cloud-stream应用程序。5秒内没有收到消息时终止。
这些示例假定原始目的地是so8400out,而消费者组是so8400。
有几个注意事项
当主应用程序未运行时,请考虑仅运行重新路由。否则,瞬态错误的重试将很快用尽。
或者,使用两阶段方法 - 使用此应用程序路由到第三个主题,另一个则从那里路由到主题。
由于这种技术使用消息标头来跟踪重试,所以它不会与headerMode=raw一起使用。在这种情况下,请考虑将一些数据添加到有效载荷(主应用程序可以忽略)。
必须将x-retries添加到headers属性spring.cloud.stream.kafka.binder.headers=x-retries和主应用程序,以便标头在应用程序之间传输。
由于kafka是发布/订阅,所以重播的消息将被发送给每个消费者组,即使是那些首次成功处理消息的消费者组。
application.properties
spring.cloud.stream.bindings.input.group=so8400replay
spring.cloud.stream.bindings.input.destination=error.so8400out.so8400
spring.cloud.stream.bindings.output.destination=so8400out
spring.cloud.stream.bindings.output.producer.partitioned=true
spring.cloud.stream.bindings.parkingLot.destination=so8400in.parkingLot
spring.cloud.stream.bindings.parkingLot.producer.partitioned=true
spring.cloud.stream.kafka.binder.configuration.auto.offset.reset=earliest
spring.cloud.stream.kafka.binder.headers=x-retries
应用
@SpringBootApplication
@EnableBinding(TwoOutputProcessor.class)
public class ReRouteDlqKApplication implements CommandLineRunner {
private static final String X_RETRIES_HEADER = "x-retries";
public static void main(String[] args) {
SpringApplication.run(ReRouteDlqKApplication.class, args).close();
}
private final AtomicInteger processed = new AtomicInteger();
@Autowired
private MessageChannel parkingLot;
@StreamListener(Processor.INPUT)
@SendTo(Processor.OUTPUT)
public Message reRoute(Message failed) {
processed.incrementAndGet();
Integer retries = failed.getHeaders().get(X_RETRIES_HEADER, Integer.class);
if (retries == null) {
System.out.println("First retry for " + failed);
return MessageBuilder.fromMessage(failed)
.setHeader(X_RETRIES_HEADER, new Integer(1))
.setHeader(BinderHeaders.PARTITION_OVERRIDE,
failed.getHeaders().get(KafkaHeaders.RECEIVED_PARTITION_ID))
.build();
}
else if (retries.intValue() < 3) {
System.out.println("Another retry for " + failed);
return MessageBuilder.fromMessage(failed)
.setHeader(X_RETRIES_HEADER, new Integer(retries.intValue() + 1))
.setHeader(BinderHeaders.PARTITION_OVERRIDE,
failed.getHeaders().get(KafkaHeaders.RECEIVED_PARTITION_ID))
.build();
}
else {
System.out.println("Retries exhausted for " + failed);
parkingLot.send(MessageBuilder.fromMessage(failed)
.setHeader(BinderHeaders.PARTITION_OVERRIDE,
failed.getHeaders().get(KafkaHeaders.RECEIVED_PARTITION_ID))
.build());
}
return null;
}
@Override
public void run(String... args) throws Exception {
while (true) {
int count = this.processed.get();
Thread.sleep(5000);
if (count == this.processed.get()) {
System.out.println("Idle, terminating");
return;
}
}
}
public interface TwoOutputProcessor extends Processor {
@Output("parkingLot")
MessageChannel parkingLot();
}
}
RabbitMQ Binder
用法
对于使用RabbitMQ绑定器,您只需要使用以下Maven坐标将其添加到您的Spring Cloud Stream应用程序:
org.springframework.cloud
spring-cloud-stream-binder-rabbit
或者,您也可以使用Spring Cloud Stream RabbitMQ入门。
org.springframework.cloud
spring-cloud-starter-stream-rabbit
RabbitMQ Binder概述
以下可以看到RabbitMQ活页夹的操作简化图。
图14. RabbitMQ Binder
RabbitMQ Binder实现将每个目的地映射到TopicExchange。对于每个消费者组,Queue将绑定到该TopicExchange。每个消费者实例对其组的Queue具有相应的RabbitMQConsumer实例。对于分区生成器/消费者,队列后缀为分区索引,并使用分区索引作为路由密钥。
使用autoBindDlq选项,您可以选择配置绑定器来创建和配置死信队列(DLQ)(以及死信交换DLX)。死信队列具有目标名称,附有.dlq。如果重试启用(maxAttempts > 1),则会将失败的消息传递到DLQ。如果禁用重试(maxAttempts = 1),则应将requeueRejected设置为false(默认),以使失败的消息将路由到DLQ,而不是重新排队。此外,republishToDlq导致绑定器向DLQ发布失败的消息(而不是拒绝它);这使得能够将标题中的附加信息添加到消息中,例如x-exception-stacktrace头中的堆栈跟踪。此选项不需要重试启用;一次尝试后,您可以重新发布失败的消息。从版本1.2开始,您可以配置重新发布的消息传递模式;见财产republishDeliveryMode。
重要
将requeueRejected设置为true将导致消息被重新排序并重新发送,这可能不是您想要的,除非故障问题是短暂的。一般来说,最好通过将maxAttempts设置为大于1,或将republishToDlq设置为true来启用binder内的重试。
有关这些属性的更多信息,请参阅RabbitMQ Binder Properties。
框架不提供消耗死信消息(或重新路由到主队列)的任何标准机制。Dead-Letter队列处理中描述了一些选项。
注意
在Spring Cloud Stream应用程序中使用多个RabbitMQ绑定器时,禁用“RabbitAutoConfiguration”以避免将RabbitAutoConfiguration应用于两个绑定器的相同配置很重要。
配置选项
本节包含特定于RabbitMQ Binder和绑定频道的设置。
有关通用绑定配置选项和属性,请参阅Spring Cloud Stream核心文档。
RabbitMQ Binder Properties
默认情况下,RabbitMQ binder使用Spring Boot的ConnectionFactory,因此它支持RabbitMQ的所有Spring Boot配置选项。(有关参考,请参阅Spring Boot文档。)RabbitMQ配置选项使用spring.rabbitmq前缀。
除Spring Boot选项之外,RabbitMQ binder还支持以下属性:
spring.cloud.stream.rabbit.binder.adminAddresses
RabbitMQ管理插件网址的逗号分隔列表。仅在nodes包含多个条目时使用。此列表中的每个条目必须在spring.rabbitmq.addresses中具有相应的条目。
默认值:空。
spring.cloud.stream.rabbit.binder.nodes
RabbitMQ节点名称的逗号分隔列表。当多个条目用于查找队列所在的服务器地址时。此列表中的每个条目必须在spring.rabbitmq.addresses中具有相应的条目。
默认值:空。
spring.cloud.stream.rabbit.binder.compressionLevel
压缩绑定的压缩级别。见java.util.zip.Deflater。
默认值:1(BEST_LEVEL)。
RabbitMQ消费者Properties
以下属性仅适用于Rabbit消费者,并且必须以spring.cloud.stream.rabbit.bindings..consumer.为前缀。
acknowledgeMode
确认模式。
默认值:AUTO。
autoBindDlq
是否自动声明DLQ并将其绑定到绑定器DLX。
默认值:false。
bindingRoutingKey
将队列绑定到交换机的路由密钥(如果bindQueue为true)。将附加分区目的地-。
默认值:#。
bindQueue
是否将队列绑定到目的地交换机?如果您已经设置了自己的基础设施并且先前已经创建/绑定了队列,请设置为false。
默认值:true。
deadLetterQueueName
DLQ的名称
默认值:prefix+destination.dlq
deadLetterExchange
分配给队列的DLX;如果autoBindDlq为true
默认值:'prefix + DLX'
deadLetterRoutingKey
一个死信路由密钥分配给队列;如果autoBindDlq为true
默认值:destination
declareExchange
是否为目的地申报交换。
默认值:true。
delayedExchange
是否将交换声明为Delayed Message Exchange- 需要在代理上延迟的消息交换插件。x-delayed-type参数设置为exchangeType。
默认值:false。
dlqDeadLetterExchange
如果DLQ被声明,则将DLX分配给该队列
默认值:none
dlqDeadLetterRoutingKey
如果DLQ被声明,则会将一个死信路由密钥分配给该队列;默认无
默认值:none
dlqExpires
未使用的死信队列被删除多久(ms)
默认值:no expiration
dlqMaxLength
死信队列中的最大消息数
默认值:no limit
dlqMaxLengthBytes
来自所有消息的死信队列中的最大字节数
默认值:no limit
dlqMaxPriority
死信队列中消息的最大优先级(0-255)
默认值:none
dlqTtl
声明(ms)时默认适用于死信队列的时间
默认值:no limit
durableSubscription
订阅是否应该耐用。仅当group也被设置时才有效。
默认值:true。
exchangeAutoDelete
如果declareExchange为真,则交换机是否应该自动删除(删除最后一个队列后删除)。
默认值:true。
exchangeDurable
如果declareExchange为真,则交换应该是否持久(经纪人重新启动)。
默认值:true。
exchangeType
交换类型;非分区目的地的direct,fanout或topicdirect或topic分区目的地。
默认值:topic。
到期
未使用的队列被删除多久(ms)
默认值:no expiration
headerPatterns
要从入站邮件映射的头文件。
默认值:['*'](所有标题)。
maxConcurrency
最大消费者人数
默认值:1。
最长长度
队列中最大消息数
默认值:no limit
maxLengthBytes
来自所有消息的队列中最大字节数
默认:no limit
maxPriority
队列中消息的最大优先级(0-255)
默认
none
预取
预取计数。
默认值:1。
字首
要添加到destination和队列名称的前缀。
默认值:“”。
recoveryInterval
连接恢复尝试之间的间隔,以毫秒为单位。
默认值:5000。
requeueRejected
在重试禁用或重新发布ToDlq是否为false时,是否应重新发送传递失败。
默认值:false。
republishDeliveryMode
当republishToDlq为true时,指定重新发布的邮件的传递模式。
默认值:DeliveryMode.PERSISTENT
republishToDlq
默认情况下,尝试重试后失败的消息将被拒绝。如果配置了死信队列(DLQ),则RabbitMQ将将失败的消息(未更改)路由到DLQ。如果设置为true,则绑定器将重新发布具有附加头的DLQ的失败消息,包括最终失败的原因的异常消息和堆栈跟踪。
默认值:false
交易
是否使用交易渠道。
默认值:false。
TTL
声明(ms)时默认适用于队列的时间
默认值:no limit
txSize
阿克斯之间的交付次数。
默认值:1。
兔子生产者Properties
以下属性仅适用于Rabbit生产者,必须以spring.cloud.stream.rabbit.bindings..producer.为前缀。
autoBindDlq
是否自动声明DLQ并将其绑定到绑定器DLX。
默认值:false。
batchingEnabled
是否启用生产者的消息批处理。
默认值:false。
BATCHSIZE
批量启动时要缓冲的消息数。
默认值:100。
batchBufferLimit
默认值:10000。
batchTimeout
默认值:5000。
bindingRoutingKey
将队列绑定到交换机的路由密钥(如果bindQueue为true)。仅适用于非分区目的地。仅适用于requiredGroups,然后仅提供给这些组。
默认值:#。
bindQueue
是否将队列绑定到目的地交换机?如果您已经设置了自己的基础架构并且先前已经创建/绑定了队列,请设置为false。仅适用于requiredGroups,然后仅提供给这些组。
默认值:true。
压缩
发送时是否应压缩数据。
默认值:false。
deadLetterQueueName
DLQ的名称仅适用于requiredGroups,仅适用于这些组。
默认值:prefix+destination.dlq
deadLetterExchange
分配给队列的DLX;如果autoBindDlq为true只适用于requiredGroups,然后只提供给这些组。
默认值:'prefix + DLX'
deadLetterRoutingKey
一个死信路由密钥分配给队列;如果autoBindDlq为true只适用于requiredGroups,然后只提供给这些组。
默认值:destination
declareExchange
是否为目的地申报交换。
默认值:true。
延迟
评估应用于消息(x-delay头)的延迟的Spel表达式 - 如果交换不是延迟的消息交换,则不起作用。
默认值:Nox-delay头设置。
delayedExchange
是否将交换声明为Delayed Message Exchange- 需要经纪人上的延迟消息交换插件。x-delayed-type参数设置为exchangeType。
默认值:false。
deliveryMode
交货方式。
默认值:PERSISTENT。
dlqDeadLetterExchange
如果DLQ被声明,则分配给该队列的DLX只适用于requiredGroups,然后仅提供给这些组。
默认值:none
dlqDeadLetterRoutingKey
如果DLQ被声明,则会将一个死信路由密钥分配给该队列;默认值none仅在提供requiredGroups时才适用,然后仅适用于这些组。
默认值:none
dlqExpires
未使用的死信队列被删除之前多久(ms)仅适用于requiredGroups,然后仅提供给这些组。
默认值:no expiration
dlqMaxLength
死信队列中的最大消息数仅适用于requiredGroups,仅适用于这些组。
默认值:no limit
dlqMaxLengthBytes
来自所有消息的死信队列中的最大字节数仅适用于requiredGroups,然后仅提供给这些组。
默认值:no limit
dlqMaxPriority
死信队列中消息的最大优先级(0-255)仅适用于requiredGroups,然后仅提供给这些组。
默认值:none
dlqTtl
声明(ms)的默认时间适用于死信队列仅适用于requiredGroups,然后仅提供给这些组。
默认值:no limit
exchangeAutoDelete
如果declareExchange为真,则交换机是否应该自动删除(删除最后一个队列后删除)。
默认值:true。
exchangeDurable
如果declareExchange为真,则交换应该是持久的(经纪人重新启动)。
默认值:true。
exchangeType
交换类型;direct,fanout或topic;direct或topic。
默认值:topic。
到期
在未使用的队列被删除之前多久(ms)仅适用于requiredGroups,然后只提供给这些组。
默认值:no expiration
headerPatterns
要将标头映射到出站邮件的模式。
默认值:['*'](所有标题)。
最长长度
队列中最大消息数仅适用于requiredGroups,仅适用于这些组。
默认值:no limit
maxLengthBytes
来自所有消息的队列中最大字节数仅适用于requiredGroups,仅适用于这些组。
默认值:no limit
maxPriority
队列中消息的最大优先级(0-255)仅适用于requiredGroups,仅适用于这些组。
默认
none
字首
要添加到destination交换机名称的前缀。
默认值:“”。
routingKeyExpression
一个SpEL表达式来确定在发布消息时使用的路由密钥。
默认值:destination或destination-分区目的地。
交易
是否使用交易渠道。
默认值:false。
TTL
声明时默认适用于队列的时间(ms)仅适用于requiredGroups,然后仅适用于这些组。
默认值:no limit
注意
在RabbitMQ的情况下,内容类型头可以由外部应用程序设置。Spring Cloud Stream支持它们作为用于任何类型传输(包括通常不支持头文件的Kafka)的传输的扩展内部协议的一部分)。
重试RabbitMQ Binder
概观
在绑定器中启用重试时,侦听器容器线程将被挂起,以配置任何后退时段。在单个消费者需要严格排序时,这可能很重要,但是对于其他用例,它可以防止在该线程上处理其他消息。使用绑定器重试的另一种方法是设置死机字符随着时间生活在死信队列(DLQ)上,以及DLQ本身的死信配置。有关这里讨论的属性的更多信息,请参阅RabbitMQ Binder Properties。启用此功能的示例配置:
将autoBindDlq设置为true- 绑定器将创建一个DLQ;您可以选择在deadLetterQueueName中指定一个名称
将dlqTtl设置为您要在重新投递之间等待的退出时间
将dlqDeadLetterExchange设置为默认交换 - DLQ的过期消息将被路由到原始队列,因为默认deadLetterRoutingKey是队列名称(destination.group)
要强制一个消息被填字,抛出一个AmqpRejectAndDontRequeueException,或设置requeueRejected到true并抛出任何异常。
循环将继续没有结束,这对于短暂的问题是很好的,但是您可能想在一些尝试后放弃。幸运的是,RabbitMQ提供了x-death标题,允许您确定发生了多少个周期。
在放弃之后确认一则消息,抛出一个ImmediateAcknowledgeAmqpException。
把它放在一起
---
spring.cloud.stream.bindings.input.destination=myDestination
spring.cloud.stream.bindings.input.group=consumerGroup
#disable binder retries
spring.cloud.stream.bindings.input.consumer.max-attempts=1
#dlx/dlq setup
spring.cloud.stream.rabbit.bindings.input.consumer.auto-bind-dlq=true
spring.cloud.stream.rabbit.bindings.input.consumer.dlq-ttl=5000
spring.cloud.stream.rabbit.bindings.input.consumer.dlq-dead-letter-exchange=
---
此配置创建一个与通配符路由密钥#交换主题的队列myDestination.consumerGroup的交换myDestination。它创建一个绑定到具有路由密钥myDestination.consumerGroup的直接交换DLX的DLQ。当消息被拒绝时,它们被路由到DLQ。5秒钟后,消息过期,并使用队列名称作为路由密钥路由到原始队列。
Spring Boot申请
@SpringBootApplication
@EnableBinding(Sink.class)
public class XDeathApplication {
public static void main(String[] args) {
SpringApplication.run(XDeathApplication.class, args);
}
@StreamListener(Sink.INPUT)
public void listen(String in, @Header(name = "x-death", required = false) Map death) {
if (death != null && death.get("count").equals(3L)) {
// giving up - don't send to DLX
throw new ImmediateAcknowledgeAmqpException("Failed after 4 attempts");
}
throw new AmqpRejectAndDontRequeueException("failed");
}
}
请注意,x-death标题中的count属性是Long。
Dead-Letter队列处理
因为不可能预料到用户如何处理死信消息,所以框架不提供任何标准的机制来处理它们。如果死刑的原因是暂时的,您可能希望将邮件路由到原始队列。但是,如果问题是一个永久性的问题,那可能会导致无限循环。以下spring-boot应用程序是如何将这些消息路由到原始队列的示例,但是在三次尝试之后将其移动到第三个“停车场”队列。第二个例子使用RabbitMQ延迟消息交换来向被重新排序的消息引入延迟。在这个例子中,每次尝试的延迟都会增加。这些示例使用@RabbitListener从DLQ接收消息,您也可以在批处理过程中使用RabbitTemplate.receive()。
这些示例假定原始目的地是so8400in,消费者组是so8400。
非分区目的地
前两个示例是目的地未分区。
@SpringBootApplication
public class ReRouteDlqApplication {
private static final String ORIGINAL_QUEUE = "so8400in.so8400";
private static final String DLQ = ORIGINAL_QUEUE + ".dlq";
private static final String PARKING_LOT = ORIGINAL_QUEUE + ".parkingLot";
private static final String X_RETRIES_HEADER = "x-retries";
public static void main(String[] args) throws Exception {
ConfigurableApplicationContext context = SpringApplication.run(ReRouteDlqApplication.class, args);
System.out.println("Hit enter to terminate");
System.in.read();
context.close();
}
@Autowired
private RabbitTemplate rabbitTemplate;
@RabbitListener(queues = DLQ)
public void rePublish(Message failedMessage) {
Integer retriesHeader = (Integer) failedMessage.getMessageProperties().getHeaders().get(X_RETRIES_HEADER);
if (retriesHeader == null) {
retriesHeader = Integer.valueOf(0);
}
if (retriesHeader < 3) {
failedMessage.getMessageProperties().getHeaders().put(X_RETRIES_HEADER, retriesHeader + 1);
this.rabbitTemplate.send(ORIGINAL_QUEUE, failedMessage);
}
else {
this.rabbitTemplate.send(PARKING_LOT, failedMessage);
}
}
@Bean
public Queue parkingLot() {
return new Queue(PARKING_LOT);
}
}
@SpringBootApplication
public class ReRouteDlqApplication {
private static final String ORIGINAL_QUEUE = "so8400in.so8400";
private static final String DLQ = ORIGINAL_QUEUE + ".dlq";
private static final String PARKING_LOT = ORIGINAL_QUEUE + ".parkingLot";
private static final String X_RETRIES_HEADER = "x-retries";
private static final String DELAY_EXCHANGE = "dlqReRouter";
public static void main(String[] args) throws Exception {
ConfigurableApplicationContext context = SpringApplication.run(ReRouteDlqApplication.class, args);
System.out.println("Hit enter to terminate");
System.in.read();
context.close();
}
@Autowired
private RabbitTemplate rabbitTemplate;
@RabbitListener(queues = DLQ)
public void rePublish(Message failedMessage) {
Map headers = failedMessage.getMessageProperties().getHeaders();
Integer retriesHeader = (Integer) headers.get(X_RETRIES_HEADER);
if (retriesHeader == null) {
retriesHeader = Integer.valueOf(0);
}
if (retriesHeader < 3) {
headers.put(X_RETRIES_HEADER, retriesHeader + 1);
headers.put("x-delay", 5000 * retriesHeader);
this.rabbitTemplate.send(DELAY_EXCHANGE, ORIGINAL_QUEUE, failedMessage);
}
else {
this.rabbitTemplate.send(PARKING_LOT, failedMessage);
}
}
@Bean
public DirectExchange delayExchange() {
DirectExchange exchange = new DirectExchange(DELAY_EXCHANGE);
exchange.setDelayed(true);
return exchange;
}
@Bean
public Binding bindOriginalToDelay() {
return BindingBuilder.bind(new Queue(ORIGINAL_QUEUE)).to(delayExchange()).with(ORIGINAL_QUEUE);
}
@Bean
public Queue parkingLot() {
return new Queue(PARKING_LOT);
}
}
分区目的地
对于分区目的地,所有分区都有一个DLQ,我们从头部确定原始队列。
republishToDlq = FALSE
当republishToDlq为false时,RabbitMQ将消息发布到DLX / DLQ,其中包含有关原始目的地信息的x-death标题。
@SpringBootApplication
public class ReRouteDlqApplication {
private static final String ORIGINAL_QUEUE = "so8400in.so8400";
private static final String DLQ = ORIGINAL_QUEUE + ".dlq";
private static final String PARKING_LOT = ORIGINAL_QUEUE + ".parkingLot";
private static final String X_DEATH_HEADER = "x-death";
private static final String X_RETRIES_HEADER = "x-retries";
public static void main(String[] args) throws Exception {
ConfigurableApplicationContext context = SpringApplication.run(ReRouteDlqApplication.class, args);
System.out.println("Hit enter to terminate");
System.in.read();
context.close();
}
@Autowired
private RabbitTemplate rabbitTemplate;
@SuppressWarnings("unchecked")
@RabbitListener(queues = DLQ)
public void rePublish(Message failedMessage) {
Map headers = failedMessage.getMessageProperties().getHeaders();
Integer retriesHeader = (Integer) headers.get(X_RETRIES_HEADER);
if (retriesHeader == null) {
retriesHeader = Integer.valueOf(0);
}
if (retriesHeader < 3) {
headers.put(X_RETRIES_HEADER, retriesHeader + 1);
List> xDeath = (List>) headers.get(X_DEATH_HEADER);
String exchange = (String) xDeath.get(0).get("exchange");
List routingKeys = (List) xDeath.get(0).get("routing-keys");
this.rabbitTemplate.send(exchange, routingKeys.get(0), failedMessage);
}
else {
this.rabbitTemplate.send(PARKING_LOT, failedMessage);
}
}
@Bean
public Queue parkingLot() {
return new Queue(PARKING_LOT);
}
}
republishToDlq =真
当republishToDlq为true时,重新发布恢复器将原始交换和路由密钥添加到标题。
@SpringBootApplication
public class ReRouteDlqApplication {
private static final String ORIGINAL_QUEUE = "so8400in.so8400";
private static final String DLQ = ORIGINAL_QUEUE + ".dlq";
private static final String PARKING_LOT = ORIGINAL_QUEUE + ".parkingLot";
private static final String X_RETRIES_HEADER = "x-retries";
private static final String X_ORIGINAL_EXCHANGE_HEADER = RepublishMessageRecoverer.X_ORIGINAL_EXCHANGE;
private static final String X_ORIGINAL_ROUTING_KEY_HEADER = RepublishMessageRecoverer.X_ORIGINAL_ROUTING_KEY;
public static void main(String[] args) throws Exception {
ConfigurableApplicationContext context = SpringApplication.run(ReRouteDlqApplication.class, args);
System.out.println("Hit enter to terminate");
System.in.read();
context.close();
}
@Autowired
private RabbitTemplate rabbitTemplate;
@RabbitListener(queues = DLQ)
public void rePublish(Message failedMessage) {
Map headers = failedMessage.getMessageProperties().getHeaders();
Integer retriesHeader = (Integer) headers.get(X_RETRIES_HEADER);
if (retriesHeader == null) {
retriesHeader = Integer.valueOf(0);
}
if (retriesHeader < 3) {
headers.put(X_RETRIES_HEADER, retriesHeader + 1);
String exchange = (String) headers.get(X_ORIGINAL_EXCHANGE_HEADER);
String originalRoutingKey = (String) headers.get(X_ORIGINAL_ROUTING_KEY_HEADER);
this.rabbitTemplate.send(exchange, originalRoutingKey, failedMessage);
}
else {
this.rabbitTemplate.send(PARKING_LOT, failedMessage);
}
}
@Bean
public Queue parkingLot() {
return new Queue(PARKING_LOT);
}
}
Spring Cloud Bus
Spring Cloud Bus将分布式系统的节点与轻量级消息代理链接。这可以用于广播状态更改(例如配置更改)或其他管理指令。一个关键的想法是,总线就像一个分布式执行器,用于扩展的Spring Boot应用程序,但也可以用作应用程序之间的通信通道。目前唯一的实现是使用AMQP代理作为传输,但是相同的基本功能集(还有一些取决于传输)在其他传输的路线图上。
注意
Spring Cloud根据非限制性Apache 2.0许可证发布。如果您想为文档的这一部分做出贡献,或者发现错误,请在github中找到项目中的源代码和问题跟踪器。
快速开始
Spring Cloud Bus的工作原理是添加Spring Boot自动配置,如果它在类路径中检测到自身。所有您需要做的是启用总线是将spring-cloud-starter-bus-amqp或spring-cloud-starter-bus-kafka添加到您的依赖关系管理中,并且Spring Cloud负责其余部分。确保代理(RabbitMQ或Kafka)可用和配置:在本地主机上运行,您不应该做任何事情,但如果您远程运行使用Spring Cloud连接器或Spring Boot定义经纪人凭据的约定,例如Rabbit
application.yml
spring:
rabbitmq:
host: mybroker.com
port: 5672
username: user
password: secret
总线当前支持向所有节点发送消息,用于特定服务的所有节点(由Eureka定义)。未来可能会添加更多的选择器标准(即,仅数据中心Y中的服务X节点等)。/bus/*执行器命名空间下还有一些http端点。目前有两个实施。第一个/bus/env发送密钥/值对来更新每个节点的Spring环境。第二个,/bus/refresh,将重新加载每个应用程序的配置,就好像他们在他们的/refresh端点上都被ping过。
注意
总线起动器覆盖了Rabbit和Kafka,因为这是两种最常用的实现方式,但是Spring Cloud Stream非常灵活,绑定器将与spring-cloud-bus结合使用。
处理实例
HTTP端点接受“目的地”参数,例如“/ bus / refresh?destination = customers:9000”,其中目的地是ApplicationContextID。如果ID由总线上的一个实例拥有,那么它将处理消息,所有其他实例将忽略它。Spring Boot将ContextIdApplicationContextInitializer中的ID设置为spring.application.name,活动配置文件和server.port的组合。
寻址服务的所有实例
“destination”参数用于SpringPathMatcher(路径分隔符为冒号:)以确定实例是否处理该消息。使用上述示例,“/ bus / refresh?destination = customers:**”将针对“客户”服务的所有实例,而不管配置文件和端口设置为ApplicationContextID。
应用程序上下文ID必须是唯一的
总线尝试从原始ApplicationEvent一次消除处理事件两次,一次从队列中消除。为此,它会检查发送应用程序上下文id,以重新显示当前的应用程序上下文ID。如果服务的多个实例具有相同的应用程序上下文id,则不会处理事件。在本地机器上运行,每个服务将在不同的端口上,这将是应用程序上下文ID的一部分。Cloud Foundry提供了区分的索引。要确保应用程序上下文ID是唯一的,请将spring.application.index设置为服务的每个实例唯一的值。例如,在lattice中,在application.properties中设置spring.application.index=${INSTANCE_INDEX}(如果使用configserver,请设置bootstrap.properties)。
自定义Message Broker
Spring Cloud Bus使用Spring Cloud Stream广播消息,以便获取消息流,只需要在类路径中包含您选择的binder实现。有AMQP(RabbitMQ)和Kafka(spring-cloud-starter-bus-[amqp,kafka])的公共汽车专用起动方便。一般来说,Spring Cloud Stream依赖于用于配置中间件的Spring Boot自动配置约定,因此例如AMQP代理地址可以使用spring.rabbitmq.*配置属性更改。Spring Cloud Bus在spring.cloud.bus.*中具有少量本地配置属性(例如spring.cloud.bus.destination是使用外部中间件的主题的名称)。通常,默认值就足够了。
要更多地了解如何自定义消息代理设置,请参阅Spring Cloud Stream文档。
跟踪Bus Events
可以通过设置spring.cloud.bus.trace.enabled=true来跟踪总线事件(RemoteApplicationEvent的子类)。如果这样做,那么Spring BootTraceRepository(如果存在)将显示每个发送的事件和来自每个服务实例的所有ack。示例(来自/trace端点):
{
"timestamp": "2015-11-26T10:24:44.411+0000",
"info": {
"signal": "spring.cloud.bus.ack",
"type": "RefreshRemoteApplicationEvent",
"id": "c4d374b7-58ea-4928-a312-31984def293b",
"origin": "stores:8081",
"destination": "*:**"
}
},
{
"timestamp": "2015-11-26T10:24:41.864+0000",
"info": {
"signal": "spring.cloud.bus.sent",
"type": "RefreshRemoteApplicationEvent",
"id": "c4d374b7-58ea-4928-a312-31984def293b",
"origin": "customers:9000",
"destination": "*:**"
}
},
{
"timestamp": "2015-11-26T10:24:41.862+0000",
"info": {
"signal": "spring.cloud.bus.ack",
"type": "RefreshRemoteApplicationEvent",
"id": "c4d374b7-58ea-4928-a312-31984def293b",
"origin": "customers:9000",
"destination": "*:**"
}
}
该跟踪显示RefreshRemoteApplicationEvent从customers:9000发送到所有服务,并且已被customers:9000和stores:8081收到(acked)。
为了处理信号,您可以向您的应用添加AckRemoteApplicationEvent和SentApplicationEvent类型的@EventListener(并启用跟踪)。或者您可以利用TraceRepository并从中挖掘数据。
注意
任何总线应用程序都可以跟踪ack,但有时在一个可以对数据进行更复杂查询的中央服务器中执行此操作是有用的。或者将其转发到专门的跟踪服务。
广播自己的Events
总线可以携带任何类型为RemoteApplicationEvent的事件,但默认传输是JSON,并且解串器需要知道哪些类型将提前使用。要注册一个新类型,它需要在org.springframework.cloud.bus.event的子包中。
要自定义事件名称,您可以在自定义类上使用@JsonTypeName,或者依赖默认策略来使用类的简单名称。请注意,生产者和消费者都需要访问类定义。
在自定义包中注册事件
如果您不能或不想为自定义事件使用org.springframework.cloud.bus.event的子包,则必须使用@RemoteApplicationEventScan指定要扫描类型为RemoteApplicationEvent的事件的包。使用@RemoteApplicationEventScan指定的软件包包括子包。
例如,如果您有一个名为FooEvent的自定义事件:
package com.acme;
public class FooEvent extends RemoteApplicationEvent {
...
}
您可以通过以下方式与解串器注册此事件:
package com.acme;
@Configuration
@RemoteApplicationEventScan
public class BusConfiguration {
...
}
没有指定一个值,使用@RemoteApplicationEventScan的类的包将被注册。在这个例子中,com.acme将使用BusConfiguration的包进行注册。
您还可以使用@RemoteApplicationEventScan上的value,basePackages或basePackageClasses属性明确指定要扫描的软件包。例如:
package com.acme;
@Configuration
//@RemoteApplicationEventScan({"com.acme", "foo.bar"})
//@RemoteApplicationEventScan(basePackages = {"com.acme", "foo.bar", "fizz.buzz"})
@RemoteApplicationEventScan(basePackageClasses = BusConfiguration.class)
public class BusConfiguration {
...
}
以上@RemoteApplicationEventScan的所有示例都是等效的,因为com.acme程序包将通过在@RemoteApplicationEventScan上明确指定程序包来注册。请注意,您可以指定要扫描的多个基本软件包。
Spring Cloud Sleuth
Adrian Cole,Spencer Gibb,Marcin Grzejszczak,Dave Syer
Dalston.RELEASE
Spring Cloud Sleuth为Spring Cloud实现分布式跟踪解决方案。
术语
Spring Cloud Sleuth借用了Dapper的术语。
Span:工作的基本单位例如,发送RPC是一个新的跨度,以及向RPC发送响应。Span由跨度的唯一64位ID标识,跨度是其中一部分的跟踪的另一个64位ID。跨度还具有其他数据,例如描述,时间戳记事件,键值注释(标签),导致它们的跨度的ID以及进程ID(通常是IP地址)。
跨距开始和停止,他们跟踪他们的时间信息。创建跨度后,必须在将来的某个时刻停止。
小费
启动跟踪的初始范围称为root span。该跨度的跨度id的值等于跟踪ID。
跟踪:一组spans形成树状结构。例如,如果您正在运行分布式大数据存储,则可能会由put请求形成跟踪。
注释:用于及时记录事件的存在。用于定义请求的开始和停止的一些核心注释是:
cs- 客户端发送 - 客户端已经发出请求。此注释描绘了跨度的开始。
sr- 服务器接收 - 服务器端得到请求,并将开始处理它。如果从此时间戳中减去cs时间戳,则会收到网络延迟。
ss- 服务器发送 - 在完成请求处理后(响应发送回客户端时)注释。如果从此时间戳中减去sr时间戳,则会收到服务器端处理请求所需的时间。
cr- 客户端接收 - 表示跨度的结束。客户端已成功接收到服务器端的响应。如果从此时间戳中减去cs时间戳,则会收到客户端从服务器接收响应所需的整个时间。
可视化Span和Trace将与Zipkin注释一起查看系统:

一个音符的每个颜色表示跨度(7 spans - 从A到G)。如果您在笔记中有这样的信息:
Trace Id = X
Span Id = D
Client Sent
这意味着,当前的跨度痕量-ID设置为X,Span -编号设置为ð。它也发出了客户端发送的事件。
这样,spans的父/子关系的可视化将如下所示:
目的
在以下部分中,将考虑上述图像中的示例。
分布式跟踪与Zipkin
共有7个spans。如果您在Zipkin中查看痕迹,您将在第二个曲目中看到这个数字:
但是,如果您选择特定的跟踪,那么您将看到4 spans:
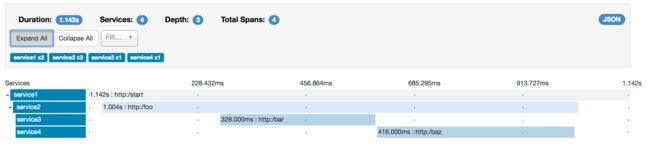
注意
当选择特定的跟踪时,您将看到合并的spans。这意味着如果发送到服务器接收和服务器发送/接收客户端和客户端发送注释的Zipkin有2个spans,那么它们将被显示为一个跨度。
为什么在这种情况下,7和4 spans之间有区别?
2 spans来自http:/start范围。它具有服务器接收(SR)和服务器发送(SS)注释。
2 spans来自service1到service2到http:/foo端点的RPC呼叫。它在service1方面具有客户端发送(CS)和客户端接收(CR)注释。它还在service2方面具有服务器接收(SR)和服务器发送(SS)注释。在物理上有2个spans,但它们形成与RPC调用相关的1个逻辑跨度。
2 spans来自service2到service3到http:/bar端点的RPC呼叫。它在service2方面具有客户端发送(CS)和客户接收(CR)注释。它还具有service3端的服务器接收(SR)和服务器发送(SS)注释。在物理上有2个spans,但它们形成与RPC调用相关的1个逻辑跨度。
2 spans来自service2到service4到http:/baz端点的RPC呼叫。它在service2方面具有客户端发送(CS)和客户接收(CR)注释。它还在service4侧具有服务器接收(SR)和服务器发送(SS)注释。在物理上有2个spans,但它们形成与RPC调用相关的1个逻辑跨度。
因此,如果我们计算spans,http:/start中有1个来自service1的呼叫service2,2(service2)呼叫service3和2(service2)service4。共7个spans。
逻辑上,我们看到Total Spans的信息:4,因为我们有1个跨度与传入请求相关的service1和3spans与RPC调用相关。
可视化错误
Zipkin允许您可视化跟踪中的错误。当异常被抛出并且没有被捕获时,我们在Zipkin可以正确着色的跨度上设置适当的标签。您可以在痕迹列表中看到一条是红色的痕迹。这是因为抛出了一个异常。
如果您点击该轨迹,您将看到类似的图片
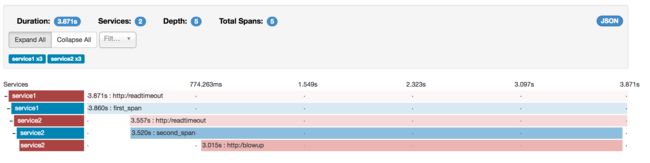
然后,如果您点击其中一个spans,您将看到以下内容
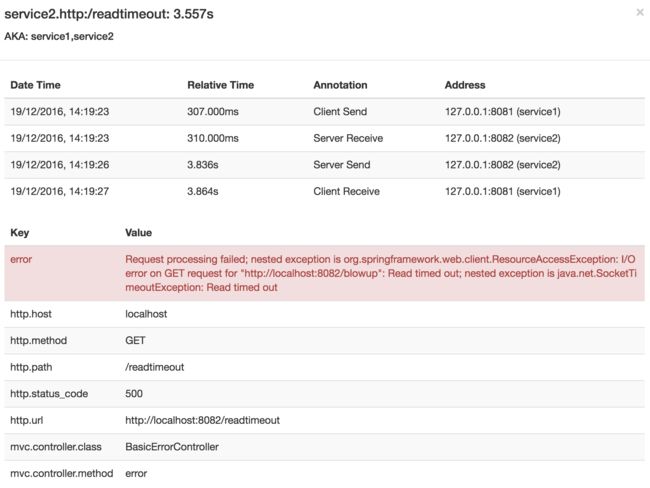
你可以看到,你可以很容易的看到错误的原因和整个stacktrace相关的。
实例

点击Pivotal Web Services图标即可实时查看!点击Pivotal Web Services图标直播!
Zipkin中的依赖图将如下所示:
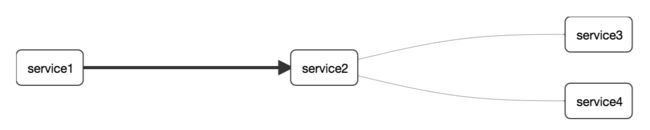

点击Pivotal Web Services图标即可实时查看!点击Pivotal Web Services图标直播!
对数相关
当通过跟踪id等于例如2485ec27856c56f4来对这四个应用程序的日志进行灰名单时,将会得到以下内容:
service1.log:2016-02-26 11:15:47.561 INFO [service1,2485ec27856c56f4,2485ec27856c56f4,true] 68058 --- [nio-8081-exec-1] i.s.c.sleuth.docs.service1.Application : Hello from service1. Calling service2
service2.log:2016-02-26 11:15:47.710 INFO [service2,2485ec27856c56f4,9aa10ee6fbde75fa,true] 68059 --- [nio-8082-exec-1] i.s.c.sleuth.docs.service2.Application : Hello from service2. Calling service3 and then service4
service3.log:2016-02-26 11:15:47.895 INFO [service3,2485ec27856c56f4,1210be13194bfe5,true] 68060 --- [nio-8083-exec-1] i.s.c.sleuth.docs.service3.Application : Hello from service3
service2.log:2016-02-26 11:15:47.924 INFO [service2,2485ec27856c56f4,9aa10ee6fbde75fa,true] 68059 --- [nio-8082-exec-1] i.s.c.sleuth.docs.service2.Application : Got response from service3 [Hello from service3]
service4.log:2016-02-26 11:15:48.134 INFO [service4,2485ec27856c56f4,1b1845262ffba49d,true] 68061 --- [nio-8084-exec-1] i.s.c.sleuth.docs.service4.Application : Hello from service4
service2.log:2016-02-26 11:15:48.156 INFO [service2,2485ec27856c56f4,9aa10ee6fbde75fa,true] 68059 --- [nio-8082-exec-1] i.s.c.sleuth.docs.service2.Application : Got response from service4 [Hello from service4]
service1.log:2016-02-26 11:15:48.182 INFO [service1,2485ec27856c56f4,2485ec27856c56f4,true] 68058 --- [nio-8081-exec-1] i.s.c.sleuth.docs.service1.Application : Got response from service2 [Hello from service2, response from service3 [Hello from service3] and from service4 [Hello from service4]]
如果你使用像一个日志聚合工具Kibana,Splunk的等您可以订购所发生的事件。基巴纳的例子如下所示:
如果你想使用Logstash,这里是Logstash的Grok模式:
filter {
# pattern matching logback pattern
grok {
match => { "message" => "%{TIMESTAMP_ISO8601:timestamp}\s+%{LOGLEVEL:severity}\s+\[%{DATA:service},%{DATA:trace},%{DATA:span},%{DATA:exportable}\]\s+%{DATA:pid}\s+---\s+\[%{DATA:thread}\]\s+%{DATA:class}\s+:\s+%{GREEDYDATA:rest}" }
}
}
注意
如果您想将Grok与Cloud Foundry的日志一起使用,则必须使用此模式:
filter {
# pattern matching logback pattern
grok {
match => { "message" => "(?m)OUT\s+%{TIMESTAMP_ISO8601:timestamp}\s+%{LOGLEVEL:severity}\s+\[%{DATA:service},%{DATA:trace},%{DATA:span},%{DATA:exportable}\]\s+%{DATA:pid}\s+---\s+\[%{DATA:thread}\]\s+%{DATA:class}\s+:\s+%{GREEDYDATA:rest}" }
}
}
使用Logstash进行JSON回溯
通常,您不希望将日志存储在文本文件中,而不是将Logstash可以立即选择的JSON文件中存储。为此,您必须执行以下操作(为了可读性,我们将依赖关系传递给groupId:artifactId:version符号。
依赖关系设置
确保Logback位于类路径(ch.qos.logback:logback-core)
添加Logstash Logback编码 - 版本4.6的示例:net.logstash.logback:logstash-logback-encoder:4.6
回读设置
您可以在下面找到一个Logback配置(名为logback-spring.xml)的示例:
将来自应用程序的信息以JSON格式记录到build/${spring.application.name}.json文件
已经评论了两个额外的追加者 - 控制台和标准日志文件
具有与上一节所述相同的记录模式
value="%clr(%d{yyyy-MM-dd HH:mm:ss.SSS}){faint} %clr(${LOG_LEVEL_PATTERN:-%5p}) %clr(${PID:- }){magenta} %clr(---){faint} %clr([%15.15t]){faint} %clr(%-40.40logger{39}){cyan} %clr(:){faint} %m%n${LOG_EXCEPTION_CONVERSION_WORD:-%wEx}"/>
DEBUG
${CONSOLE_LOG_PATTERN}
utf8
${LOG_FILE}
${LOG_FILE}.%d{yyyy-MM-dd}.gz
7
${CONSOLE_LOG_PATTERN}
utf8
${LOG_FILE}.json
${LOG_FILE}.json.%d{yyyy-MM-dd}.gz
7
UTC
{
"severity": "%level",
"service": "${springAppName:-}",
"trace": "%X{X-B3-TraceId:-}",
"span": "%X{X-B3-SpanId:-}",
"parent": "%X{X-B3-ParentSpanId:-}",
"exportable": "%X{X-Span-Export:-}",
"pid": "${PID:-}",
"thread": "%thread",
"class": "%logger{40}",
"rest": "%message"
}
注意
如果您使用自定义logback-spring.xml,则必须通过bootstrapapplication而不是application属性文件传递spring.application.name。否则您的自定义logback文件将不会正确读取该属性。
传播Span上下文
跨度上下文是必须传播到任何子进程跨越进程边界的状态。Span背景的一部分是行李。跟踪和跨度ID是跨度上下文的必需部分。行李是可选的部分。
行李是一组密钥:存储在范围上下文中的值对。行李与痕迹一起旅行,并附在每一个跨度上。Spring Cloud如果HTTP标头以baggage-为前缀,并且以baggage_开头的消息传递,Sleuth将会明白标题是行李相关的。
重要
行李物品的数量或大小目前没有限制。但是,请记住,太多可能会降低系统吞吐量或增加RPC延迟。在极端情况下,由于超出了传输级消息或报头容量,可能会使应用程序崩溃。
在跨度上设置行李的示例:
Span initialSpan = this.tracer.createSpan("span");
initialSpan.setBaggageItem("foo", "bar");
行李与Span标签
行李随行旅行(即每个孩子跨度都包含其父母的行李)。Zipkin不了解行李,甚至不会收到这些信息。
标签附加到特定的跨度 - 它们仅针对该特定跨度呈现。但是,您可以通过标签搜索查找跟踪,其中存在具有搜索标签值的跨度。
如果您希望能够根据行李查找跨度,则应在根跨度中添加相应的条目作为标签。
@Autowired Tracer tracer;
Span span = tracer.getCurrentSpan();
String baggageKey = "key";
String baggageValue = "foo";
span.setBaggageItem(baggageKey, baggageValue);
tracer.addTag(baggageKey, baggageValue);
添加到项目中
只有Sleuth(对数相关)
如果您只想从Spring Cloud Sleuth中获利,而没有Zipkin集成,只需将spring-cloud-starter-sleuth模块添加到您的项目中即可。
Maven的
(1) org.springframework.cloud spring-cloud-dependencies Camden.RELEASE pom import (2)org.springframework.cloud spring-cloud-starter-sleuth
为了不自己选择版本,如果您通过Spring BOM添加依赖关系管理,会更好
将依赖关系添加到spring-cloud-starter-sleuth
摇篮
dependencyManagement {(1)imports { mavenBom "org.springframework.cloud:spring-cloud-dependencies:Camden.RELEASE" }}dependencies {(2)compile "org.springframework.cloud:spring-cloud-starter-sleuth"}
为了不自己选择版本,如果您通过Spring BOM添加依赖关系管理,会更好
将依赖关系添加到spring-cloud-starter-sleuth
通过HTTP访问Zipkin
如果你想要Sleuth和Zipkin只需添加spring-cloud-starter-zipkin依赖关系。
Maven的
(1) org.springframework.cloud spring-cloud-dependencies Camden.RELEASE pom import (2)org.springframework.cloud spring-cloud-starter-zipkin
为了不自己选择版本,如果您通过Spring BOM添加依赖关系管理,会更好
将依赖关系添加到spring-cloud-starter-zipkin
摇篮
dependencyManagement {(1)imports { mavenBom "org.springframework.cloud:spring-cloud-dependencies:Camden.RELEASE" }}dependencies {(2)compile "org.springframework.cloud:spring-cloud-starter-zipkin"}
为了不自己选择版本,如果您通过Spring BOM添加依赖关系管理,会更好
将依赖关系添加到spring-cloud-starter-zipkin
通过Spring Cloud Stream使用Zipkin的Sleuth
如果你想要Sleuth和Zipkin只需添加spring-cloud-sleuth-stream依赖关系。
Maven的
(1) org.springframework.cloud spring-cloud-dependencies Camden.RELEASE pom import (2)org.springframework.cloud spring-cloud-sleuth-stream (3)org.springframework.cloud spring-cloud-starter-sleuth (4)org.springframework.cloud spring-cloud-stream-binder-rabbit
为了不自己选择版本,如果您通过Spring BOM添加依赖关系管理,会更好
将依赖关系添加到spring-cloud-sleuth-stream
将依赖关系添加到spring-cloud-starter-sleuth中,这样就可以下载依赖关系
添加一个粘合剂(例如Rabbit binder)来告诉Spring Cloud Stream应该绑定什么
摇篮
dependencyManagement {(1)imports { mavenBom "org.springframework.cloud:spring-cloud-dependencies:Camden.RELEASE" }}dependencies { compile "org.springframework.cloud:spring-cloud-sleuth-stream"(2)compile "org.springframework.cloud:spring-cloud-starter-sleuth"(3)// Example for Rabbit binding compile "org.springframework.cloud:spring-cloud-stream-binder-rabbit"(4)}
为了不自己选择版本,如果您通过Spring BOM添加依赖关系管理,会更好
将依赖关系添加到spring-cloud-sleuth-stream
将依赖关系添加到spring-cloud-starter-sleuth中,这样就可以下载所有依赖关系
添加一个粘合剂(例如Rabbit binder)来告诉Spring Cloud Stream应该绑定什么
Spring Cloud Sleuth Stream Zipkin收藏家
如果要启动Spring Cloud Sleuth Stream Zipkin收藏夹,只需添加spring-cloud-sleuth-zipkin-stream依赖关系即可
Maven的
(1) org.springframework.cloud spring-cloud-dependencies Camden.RELEASE pom import (2)org.springframework.cloud spring-cloud-sleuth-zipkin-stream (3)org.springframework.cloud spring-cloud-starter-sleuth (4)org.springframework.cloud spring-cloud-stream-binder-rabbit
为了不自己选择版本,如果您通过Spring BOM添加依赖关系管理,会更好
将依赖关系添加到spring-cloud-sleuth-zipkin-stream
将依赖关系添加到spring-cloud-starter-sleuth- 这样一来,所有的依赖依赖将被下载
添加一个粘合剂(例如Rabbit binder)来告诉Spring Cloud Stream应该绑定什么
摇篮
dependencyManagement {(1)imports { mavenBom "org.springframework.cloud:spring-cloud-dependencies:Camden.RELEASE" }}dependencies { compile "org.springframework.cloud:spring-cloud-sleuth-zipkin-stream"(2)compile "org.springframework.cloud:spring-cloud-starter-sleuth"(3)// Example for Rabbit binding compile "org.springframework.cloud:spring-cloud-stream-binder-rabbit"(4)}
为了不自己选择版本,如果您通过Spring BOM添加依赖关系管理,会更好
将依赖关系添加到spring-cloud-sleuth-zipkin-stream
将依赖关系添加到spring-cloud-starter-sleuth- 这样将依赖关系依赖下载
添加一个粘合剂(例如Rabbit binder)来告诉Spring Cloud Stream应该绑定什么
然后使用@EnableZipkinStreamServer注释注释你的主类:
package example;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.sleuth.zipkin.stream.EnableZipkinStreamServer;
@SpringBootApplication
@EnableZipkinStreamServer
public class ZipkinStreamServerApplication {
public static void main(String[] args) throws Exception {
SpringApplication.run(ZipkinStreamServerApplication.class, args);
}
}
额外的资源
Marcin Grzejszczak谈论Spring Cloud Sleuth和Zipkin
点击此处查看视频
特征
将跟踪和跨度添加到Slf4J MDC,以便您可以从日志聚合器中的给定跟踪或跨度中提取所有日志。示例日志:
2016-02-02 15:30:57.902 INFO [bar,6bfd228dc00d216b,6bfd228dc00d216b,false] 23030 --- [nio-8081-exec-3] ...
2016-02-02 15:30:58.372 ERROR [bar,6bfd228dc00d216b,6bfd228dc00d216b,false] 23030 --- [nio-8081-exec-3] ...
2016-02-02 15:31:01.936 INFO [bar,46ab0d418373cbc9,46ab0d418373cbc9,false] 23030 --- [nio-8081-exec-4] ...
注意MDC中的[appname,traceId,spanId,exportable]条目:
spanId- 发生特定操作的ID
appname- 记录跨度的应用程序的名称
traceId- 包含跨度的延迟图的ID
导出-日志是否应该被导出到Zipkin与否。你什么时候希望跨度不能出口?在这种情况下,你想在Span中包装一些操作,并将它写入日志。
提供对共同分布式跟踪数据模型的抽象:trace,spans(形成DAG),注释,键值注释。松散地基于HTrace,但Zipkin(Dapper)兼容。
Sleuth记录定时信息以辅助延迟分析。使用窃贼,您可以精确定位应用程序中的延迟原因。Sleuth被写入不会记录太多,并且不会导致您的生产应用程序崩溃。
传播有关您的呼叫图表带内的结构数据,其余的是带外。
包括有意见的层次测试,如HTTP
包括采样策略来管理卷
可以向Zipkin系统报告查询和可视化
仪器来自Spring应用程序(servlet过滤器,异步终结点,休息模板,调度操作,消息通道,zuul过滤器,假客户端)的通用入口和出口点。
Sleuth包括在http或消息传递边界上加入跟踪的默认逻辑。例如,http传播通过Zipkin兼容的请求标头工作。该传播逻辑是通过SpanInjector和SpanExtractor实现来定义和定制的。
Sleuth可以在进程之间传播上下文(也称为行李)。这意味着如果您设置了Span行李元素,那么它将通过HTTP或消息传递到其他进程发送到下游。
提供创建/继续spans并通过注释添加标签和日志的方法。
提供接受/删除spans的简单指标。
如果spring-cloud-sleuth-zipkin,则应用程序将生成并收集Zipkin兼容的跟踪。默认情况下,它通过HTTP将其发送到localhost上的Zipkin服务器(端口9411)。使用spring.zipkin.baseUrl配置服务的位置。
如果spring-cloud-sleuth-stream,则该应用将通过Spring Cloud Stream生成和收集跟踪。您的应用程序自动成为通过您的代理商发送的跟踪消息的生产者(例如RabbitMQ,Apache Kafka,Redis))。
重要
如果使用Zipkin或Stream,请使用spring.sleuth.sampler.percentage(默认0.1,即10%)配置spans的百分比。否则你可能认为Sleuth不工作,因为它省略了一些spans。
注意
始终设置SLF4J MDC,并且Logback用户将立即按照上述示例查看日志中的跟踪和跨度ID。其他日志记录系统必须配置自己的格式化程序以获得相同的结果。默认值为logging.pattern.level设置为%5p [${spring.zipkin.service.name:${spring.application.name:-}},%X{X-B3-TraceId:-},%X{X-B3-SpanId:-},%X{X-Span-Export:-}](这是回访用户的Spring Boot功能)。这意味着如果您不使用SLF4J,则不会自动应用此模式。
采样
在分布式跟踪中,数据量可能非常高,因此采样可能很重要(您通常不需要导出所有spans以获得正在发生的情况)。Spring Cloud Sleuth具有Sampler策略,您可以实现该策略来控制采样算法。采样器不会停止生成跨度(相关)ids,但是它们确实阻止了附加和导出的标签和事件。默认情况下,您将获得一个策略,如果跨度已经处于活动状态,则会继续跟踪,但新策略始终被标记为不可导出。如果您的所有应用程序都使用此采样器运行,您将看到日志中的跟踪,但不会在任何远程存储中。对于测试,默认值通常是足够的,如果您仅使用日志(例如使用ELK聚合器),则可能是您需要的。如果要将span数据导出到Zipkin或Spring Cloud Stream,则还有一个AlwaysSampler导出所有内容,并且PercentageBasedSampler对spans的固定分数进行采样。
注意
如果您使用spring-cloud-sleuth-zipkin或spring-cloud-sleuth-stream,则默认为PercentageBasedSampler。您可以使用spring.sleuth.sampler.percentage配置导出。通过的价值需要从0.0到1.0的双倍,所以不是百分比。为了向后兼容性原因,我们不会更改属性名称。
可以通过创建一个bean定义来安装采样器,例如:
@Bean
public Sampler defaultSampler() {
return new AlwaysSampler();
}
小费
您可以将HTTP标头X-B3-Flags设置为1,或者在进行消息传递时,您可以将spanFlags标题设置为1。然后,无论采样决定如何,当前跨度都将被强制输出。
仪表
Spring Cloud Sleuth自动为您的所有Spring应用程序设备,因此您不必执行任何操作即可激活它。根据可用的堆栈,例如对于我们使用Filter的servlet web应用程序,以及Spring Integration我们使用ChannelInterceptors),可以使用各种技术添加仪器。
您可以自定义span标签中使用的键。为了限制跨度数据量,默认情况下,HTTP请求只会被标记为少量的元数据,如状态码,主机和URL。您可以通过配置spring.sleuth.keys.http.headers(头名称列表)来添加请求头。
注意
记住,如果有一个Sampler允许它(默认情况下没有,所以没有意外收集太多数据而没有配置东西的危险),那么只会收集和导出标签。
注意
目前,Spring Cloud Sleuth中的测试仪器是渴望的 - 这意味着我们正在积极地尝试在线程之间传递跟踪上下文。即使在没有将数据导出到跟踪系统的情况下,也会捕获定时事件。这种做法在将来可能会改变为在这件事上懒惰。
Span生命周期
您可以通过org.springframework.cloud.sleuth.Tracer接口在Span上执行以下操作:
开始- 当您启动一个span时,它的名称被分配,并且记录开始时间戳。
关闭- 跨度完成(记录跨度的结束时间),如果跨度可导出,则它将有资格收集到Zipkin。该跨度也从当前线程中移除。
继续- 将创建一个新的跨度实例,而它将是它继续的一个副本。
分离- 跨度不会停止或关闭。它只从当前线程中删除。
使用显式父项创建- 您可以创建一个新的跨度,并为其设置一个显式父级
小费
Spring为您创建了一个Tracer的实例。为了使用它,你需要的只是自动连接它。
创建和关闭spans
您可以使用Tracer界面手动创建spans。
// Start a span. If there was a span present in this thread it will become
// the `newSpan`'s parent.
Span newSpan = this.tracer.createSpan("calculateTax");
try {
// ...
// You can tag a span
this.tracer.addTag("taxValue", taxValue);
// ...
// You can log an event on a span
newSpan.logEvent("taxCalculated");
} finally {
// Once done remember to close the span. This will allow collecting
// the span to send it to Zipkin
this.tracer.close(newSpan);
}
在这个例子中,我们可以看到如何创建一个新的跨度实例。假设这个线程中已经存在跨度,那么它将成为该跨度的父代。
重要
创建跨度后始终清洁!如果要将其发送到Zipkin,请不要忘记关闭跨度。
重要
如果您的span包含的名称大于50个字符,则该名称将被截断为50个字符。你的名字必须是明确而具体的。大名称导致延迟问题,有时甚至引发异常。
继续spans
有时你不想创建一个新的跨度,但你想继续。这种情况的例子可能是(当然这取决于用例):
AOP- 如果在达到方面之前已经创建了一个跨度,则可能不想创建一个新的跨度。
Hystrix- 执行Hystrix命令很可能是当前处理的逻辑部分。实际上,它只是一个技术实现细节,你不一定要反映在跟踪中作为一个单独的存在。
持续的跨度实例等于它继续的范围:
Span continuedSpan = this.tracer.continueSpan(spanToContinue);
assertThat(continuedSpan).isEqualTo(spanToContinue);
要继续跨度,您可以使用Tracer界面。
// let's assume that we're in a thread Y and we've received
// the `initialSpan` from thread X
Span continuedSpan = this.tracer.continueSpan(initialSpan);
try {
// ...
// You can tag a span
this.tracer.addTag("taxValue", taxValue);
// ...
// You can log an event on a span
continuedSpan.logEvent("taxCalculated");
} finally {
// Once done remember to detach the span. That way you'll
// safely remove it from the current thread without closing it
this.tracer.detach(continuedSpan);
}
重要
创建跨度后始终清洁!如果在一个线程(例如线程X)中开始了某些工作,并且正在等待其他线程(例如Y,Z)完成,请不要忘记分离跨距。那么线程Y,Z中的spans在工作结束时应该被分离。当收集结果时,螺纹X中的跨度应该被关闭。
用明确的父代创建spans
您可能想要开始一个新的跨度,并提供该跨度的显式父级。假设跨度的父项在一个线程中,并且要在另一个线程中启动一个新的跨度。Tracer接口的startSpan方法是您要查找的方法。
// let's assume that we're in a thread Y and we've received
// the `initialSpan` from thread X. `initialSpan` will be the parent
// of the `newSpan`
Span newSpan = this.tracer.createSpan("calculateCommission", initialSpan);
try {
// ...
// You can tag a span
this.tracer.addTag("commissionValue", commissionValue);
// ...
// You can log an event on a span
newSpan.logEvent("commissionCalculated");
} finally {
// Once done remember to close the span. This will allow collecting
// the span to send it to Zipkin. The tags and events set on the
// newSpan will not be present on the parent
this.tracer.close(newSpan);
}
重要
创建这样一个跨度后,记得关闭它。否则,您将在您的日志中看到很多警告,其中有一个事实,即您在当前线程中存在一个跨度,而不是您要关闭的线程。更糟糕的是,您的spans不会正确关闭,因此不会收集到Zipkin。
命名spans
选择一个跨度名称不是一件小事。Span名称应该描述一个操作名称。名称应该是低基数(例如不包括标识符)。
由于有很多仪器仪表在一些跨度名称将是人为的:
controller-method-name当控制器以方法名conrollerMethodName接收时
async通过包装Callable和Runnable完成异步操作。
@Scheduled注释方法将返回类的简单名称。
幸运的是,对于异步处理,您可以提供明确的命名。
@SpanName注释
您可以通过@SpanName注释显式指定该跨度。
@SpanName("calculateTax")
class TaxCountingRunnable implements Runnable {
@Override public void run() {
// perform logic
}
}
在这种情况下,以下列方式处理时:
Runnable runnable = new TraceRunnable(tracer, spanNamer, new TaxCountingRunnable());
Future future = executorService.submit(runnable);
// ... some additional logic ...
future.get();
该范围将被命名为calculateTax。
toString()方法
为Runnable或Callable创建单独的课程很少见。通常,创建这些类的匿名实例。如果没有@SpanName注释,我们将检查该类是否具有toString()方法的自定义实现。
所以执行这样的代码:
Runnable runnable = new TraceRunnable(tracer, spanNamer, new Runnable() {
@Override public void run() {
// perform logic
}
@Override public String toString() {
return "calculateTax";
}
});
Future future = executorService.submit(runnable);
// ... some additional logic ...
future.get();
将导致创建一个名为calculateTax的跨度。
管理spans注释
合理
这个功能的主要论据是
api-agnostic意味着与跨度进行合作
使用注释允许用户添加到跨度api没有库依赖的跨度。这允许Sleuth将其核心api的影响改变为对用户代码的影响较小。
减少基础跨度作业的表面积。
没有这个功能,必须使用span api,它具有不正确使用的生命周期命令。通过仅显示范围,标签和日志功能,用户可以协作,而不会意外中断跨度生命周期。
与运行时生成的代码协作
使用诸如Spring Data / Feign的库,在运行时生成接口的实现,从而跨越对象的包装是乏味的。现在,您可以通过这些接口的接口和参数提供注释
创建新的spans
如果您真的不想手动创建本地spans,您可以从@NewSpan注释中获利。此外,我们还提供@SpanTag注释,以自动方式添加标签。
我们来看一些使用的例子。
@NewSpan
void testMethod();
注释没有任何参数的方法将导致创建名称将等于注释方法名称的新跨度。
@NewSpan("customNameOnTestMethod4")
void testMethod4();
如果您在注释中提供值(直接或通过name参数),则创建的范围将具有提供的值的名称。
// method declaration
@NewSpan(name = "customNameOnTestMethod5")
void testMethod5(@SpanTag("testTag") String param);
// and method execution
this.testBean.testMethod5("test");
您可以组合名称和标签。我们来关注后者。在这种情况下,无论注释方法的参数运行时值的值如何 - 这将是标记的值。在我们的示例中,标签密钥将为testTag,标签值为test。
@NewSpan(name = "customNameOnTestMethod3")
@Override
public void testMethod3() {
}
您可以将@NewSpan注释放在类和接口上。如果覆盖接口的方法并提供不同的@NewSpan注释值,则最具体的一个获胜(在这种情况下customNameOnTestMethod3将被设置)。
继续spans
如果您只想添加标签和注释到现有的跨度,就可以使用如下所示的@ContinueSpan注释。请注意,与@NewSpan注释相反,您还可以通过log参数添加日志:
// method declaration
@ContinueSpan(log = "testMethod11")
void testMethod11(@SpanTag("testTag11") String param);
// method execution
this.testBean.testMethod11("test");
这样,跨越将继续下去:
将创建名称为testMethod11.before和testMethod11.after的日志
如果抛出异常,也将创建一个日志testMethod11.afterFailure
将创建密钥testTag11和值test的标签
更高级的标签设置
有三种不同的方法可以将标签添加到跨度。所有这些都由SpanTag注释控制。优先级是:
尝试使用TagValueResolver类型的bean,并提供名称
如果没有提供bean名称,请尝试评估一个表达式。我们正在搜索一个TagValueExpressionResolverbean。默认实现使用SPEL表达式解析。
如果没有提供任何表达式来评估只返回参数的toString()值
自定义提取器
以下方法的标签值将由TagValueResolver接口的实现来计算。其类名必须作为resolver属性的值传递。
有这样一个注释的方法:
@NewSpan
public void getAnnotationForTagValueResolver(@SpanTag(key = "test", resolver = TagValueResolver.class) String test) {
}
和这样一个TagValueResolverbean实现
@Bean(name = "myCustomTagValueResolver")
public TagValueResolver tagValueResolver() {
return parameter -> "Value from myCustomTagValueResolver";
}
将导致标签值的设置等于Value from myCustomTagValueResolver。
解决表达式的价值
有这样一个注释的方法:
@NewSpan
public void getAnnotationForTagValueExpression(@SpanTag(key = "test", expression = "length() + ' characters'") String test) {
}
并且没有自定义的TagValueExpressionResolver实现将导致对SPEL表达式的评估,并且将在span上设置值为4 characters的标签。如果要使用其他表达式解析机制,您可以创建自己的bean实现。
使用toString方法
有这样一个注释的方法:
@NewSpan
public void getAnnotationForArgumentToString(@SpanTag("test") Long param) {
}
如果使用值为15执行,则将导致设置String值为"15"的标记。
自定义
感谢SpanInjector和SpanExtractor,您可以自定义spans的创建和传播方式。
目前有两种在进程之间传递跟踪信息的内置方式:
通过Spring Integration
通过HTTP
Span ids从Zipkin兼容(B3)头(Message或HTTP头)中提取,以启动或加入现有跟踪。跟踪信息被注入到任何出站请求中,所以下一跳可以提取它们。
与以前版本的Sleuth相比,重要的变化是Sleuth正在实施Open Tracing的TextMap概念。在Sleuth,它被称为SpanTextMap。基本上这个想法是通过SpanTextMap可以抽象出任何通信手段(例如消息,http请求等)。这个抽象定义了如何将数据插入到载体中以及如何从那里检索数据。感谢这样,如果您想要使用一个使用FooRequest作为发送HTTP请求的平均值的新HTTP库,那么您必须创建一个SpanTextMap的实现,它将调用委托给FooRequest检索和插入HTTP标头。
Spring Integration
对于Spring Integration,有2个接口负责从Message创建Span。这些是:
MessagingSpanTextMapExtractor
MessagingSpanTextMapInjector
您可以通过提供自己的实现来覆盖它们。
HTTP
对于HTTP,有2个接口负责从Message创建Span。这些是:
HttpSpanExtractor
HttpSpanInjector
您可以通过提供自己的实现来覆盖它们。
例
我们假设,而不是标准的Zipkin兼容的跟踪HTTP头名称
for trace id -correlationId
for span id -mySpanId
这是SpanExtractor的一个例子
static class CustomHttpSpanExtractor implements HttpSpanExtractor {
@Override public Span joinTrace(SpanTextMap carrier) {
Map map = TextMapUtil.asMap(carrier);
long traceId = Span.hexToId(map.get("correlationid"));
long spanId = Span.hexToId(map.get("myspanid"));
// extract all necessary headers
Span.SpanBuilder builder = Span.builder().traceId(traceId).spanId(spanId);
// build rest of the Span
return builder.build();
}
}
static class CustomHttpSpanInjector implements HttpSpanInjector {
@Override
public void inject(Span span, SpanTextMap carrier) {
carrier.put("correlationId", span.traceIdString());
carrier.put("mySpanId", Span.idToHex(span.getSpanId()));
}
}
你可以这样注册:
@Bean
HttpSpanInjector customHttpSpanInjector() {
return new CustomHttpSpanInjector();
}
@Bean
HttpSpanExtractor customHttpSpanExtractor() {
return new CustomHttpSpanExtractor();
}
Spring Cloud为了安全起见,Sleuth不会将跟踪/跨度相关的标头添加到Http响应。如果您需要标题,那么将标题注入Http响应的自定义SpanInjector,并且可以使用以下方式添加一个使用此标签的Servlet过滤器:
static class CustomHttpServletResponseSpanInjector extends ZipkinHttpSpanInjector {
@Override
public void inject(Span span, SpanTextMap carrier) {
super.inject(span, carrier);
carrier.put(Span.TRACE_ID_NAME, span.traceIdString());
carrier.put(Span.SPAN_ID_NAME, Span.idToHex(span.getSpanId()));
}
}
static class HttpResponseInjectingTraceFilter extends GenericFilterBean {
private final Tracer tracer;
private final HttpSpanInjector spanInjector;
public HttpResponseInjectingTraceFilter(Tracer tracer, HttpSpanInjector spanInjector) {
this.tracer = tracer;
this.spanInjector = spanInjector;
}
@Override
public void doFilter(ServletRequest request, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
HttpServletResponse response = (HttpServletResponse) servletResponse;
Span currentSpan = this.tracer.getCurrentSpan();
this.spanInjector.inject(currentSpan, new HttpServletResponseTextMap(response));
filterChain.doFilter(request, response);
}
class HttpServletResponseTextMap implements SpanTextMap {
private final HttpServletResponse delegate;
HttpServletResponseTextMap(HttpServletResponse delegate) {
this.delegate = delegate;
}
@Override
public Iterator> iterator() {
Map map = new HashMap<>();
for (String header : this.delegate.getHeaderNames()) {
map.put(header, this.delegate.getHeader(header));
}
return map.entrySet().iterator();
}
@Override
public void put(String key, String value) {
this.delegate.addHeader(key, value);
}
}
}
你可以这样注册:
@Bean HttpSpanInjector customHttpServletResponseSpanInjector() {
return new CustomHttpServletResponseSpanInjector();
}
@Bean
HttpResponseInjectingTraceFilter responseInjectingTraceFilter(Tracer tracer) {
return new HttpResponseInjectingTraceFilter(tracer, customHttpServletResponseSpanInjector());
}
Zipkin中的自定义SA标签
有时你想创建一个手动Span,将一个电话包裹到一个没有被检测的外部服务。您可以做的是创建一个带有peer.service标签的跨度,其中包含要调用的服务的值。下面你可以看到一个调用Redis的例子,它被包装在这样一个跨度里。
org.springframework.cloud.sleuth.Span newSpan = tracer.createSpan("redis");
try {
newSpan.tag("redis.op", "get");
newSpan.tag("lc", "redis");
newSpan.logEvent(org.springframework.cloud.sleuth.Span.CLIENT_SEND);
// call redis service e.g
// return (SomeObj) redisTemplate.opsForHash().get("MYHASH", someObjKey);
} finally {
newSpan.tag("peer.service", "redisService");
newSpan.tag("peer.ipv4", "1.2.3.4");
newSpan.tag("peer.port", "1234");
newSpan.logEvent(org.springframework.cloud.sleuth.Span.CLIENT_RECV);
tracer.close(newSpan);
}
重要
记住不要添加peer.service标签和SA标签!您只需添加peer.service。
自定义服务名称
默认情况下,Sleuth假设当您将跨度发送到Zipkin时,您希望跨度的服务名称等于spring.application.name值。这并不总是这样。在某些情况下,您希望为您应用程序中的所有spans提供不同的服务名称。要实现这一点,只需将以下属性传递给应用程序即可覆盖该值(foo服务名称的示例):
spring.zipkin.service.name: foo
主机定位器
为了定义与特定跨度对应的主机,我们需要解析主机名和端口。默认方法是从服务器属性中获取它。如果由于某些原因没有设置,那么我们正在尝试从网络接口检索主机名。
如果您启用了发现客户端,并且更愿意从服务注册表中注册的实例检索主机地址,那么您必须设置属性(适用于基于HTTP和Stream的跨度报告)。
spring.zipkin.locator.discovery.enabled: true
Span Data作为消息
您可以通过将spring-cloud-sleuth-streamjar作为依赖关系来累加并发送跨越Spring Cloud Stream的数据,并为RabbitMQ或spring-cloud-starter-stream-kafka添加通道Binder实现(例如spring-cloud-starter-stream-rabbit)为Kafka)。通过将spring-cloud-sleuth-streamjar作为依赖关系,并添加RabbitMQ或spring-cloud-starter-stream-kafka的Binder通道spring-cloud-starter-stream-rabbit来实现{22 /} Stream的累积和发送范围数据。Kafka)。这将自动将您的应用程序转换为有效载荷类型为Spans的邮件的制作者。
Zipkin消费者
有一个特殊的便利注释,用于为Span数据设置消息使用者,并将其推入ZipkinSpanStore。这个应用程序
@SpringBootApplication
@EnableZipkinStreamServer
public class Consumer {
public static void main(String[] args) {
SpringApplication.run(Consumer.class, args);
}
}
将通过Spring Cloud StreamBinder(例如RabbitMQ包含spring-cloud-starter-stream-rabbit)来收听您提供的任何运输的Span数据,Redis和Kafka的类似起始者) 。如果添加以下UI依赖关系
io.zipkin.java
zipkin-autoconfigure-ui
然后,您将有一个Zipkin服务器,您的应用程序在端口9411上承载UI和API。
默认SpanStore是内存中的(适合演示,快速入门)。对于更强大的解决方案,您可以将MySQL和spring-boot-starter-jdbc添加到类路径中,并通过配置启用JDBCSpanStore,例如:
spring:
rabbitmq:
host: ${RABBIT_HOST:localhost}
datasource:
schema: classpath:/mysql.sql
url: jdbc:mysql://${MYSQL_HOST:localhost}/test
username: root
password: root
# Switch this on to create the schema on startup:
initialize: true
continueOnError: true
sleuth:
enabled: false
zipkin:
storage:
type: mysql
注意
@EnableZipkinStreamServer还用@EnableZipkinServer注释,因此该过程还将公开标准的Zipkin服务器端点,以通过HTTP收集spans,并在Zipkin Web UI中进行查询。
定制消费者
也可以使用spring-cloud-sleuth-stream并绑定到SleuthSink来轻松实现自定义消费者。例:
@EnableBinding(SleuthSink.class)
@SpringBootApplication(exclude = SleuthStreamAutoConfiguration.class)
@MessageEndpoint
public class Consumer {
@ServiceActivator(inputChannel = SleuthSink.INPUT)
public void sink(Spans input) throws Exception {
// ... process spans
}
}
注意
上面的示例消费者应用程序明确排除SleuthStreamAutoConfiguration,因此它不会向其自己发送消息,但这是可选的(您可能实际上想要将消息跟踪到消费者应用程序中)。
为了自定义轮询机制,您可以创建名称等于StreamSpanReporter.POLLER的PollerMetadata类型的bean。在这里可以找到这样一个配置的例子。
@Configuration
public static class CustomPollerConfiguration {
@Bean(name = StreamSpanReporter.POLLER)
PollerMetadata customPoller() {
PollerMetadata poller = new PollerMetadata();
poller.setMaxMessagesPerPoll(500);
poller.setTrigger(new PeriodicTrigger(5000L));
return poller;
}
}
度量
目前Spring Cloud Sleuth注册了与spans相关的简单指标。它使用Spring Boot的指标支持来计算接受和删除的数量spans。每次发送到Zipkin时,接受的spans的数量将增加。如果出现错误,那么删除的数字spans将会增加。
集成
可运行和可调用
如果你在Runnable或Callable中包含你的逻辑,就可以将这些类包装在他们的Sleuth代表中。
Runnable的示例:
Runnable runnable = new Runnable() {
@Override
public void run() {
// do some work
}
@Override
public String toString() {
return "spanNameFromToStringMethod";
}
};
// Manual `TraceRunnable` creation with explicit "calculateTax" Span name
Runnable traceRunnable = new TraceRunnable(tracer, spanNamer, runnable, "calculateTax");
// Wrapping `Runnable` with `Tracer`. The Span name will be taken either from the
// `@SpanName` annotation or from `toString` method
Runnable traceRunnableFromTracer = tracer.wrap(runnable);
Callable的示例:
Callable callable = new Callable() {
@Override
public String call() throws Exception {
return someLogic();
}
@Override
public String toString() {
return "spanNameFromToStringMethod";
}
};
// Manual `TraceCallable` creation with explicit "calculateTax" Span name
Callable traceCallable = new TraceCallable<>(tracer, spanNamer, callable, "calculateTax");
// Wrapping `Callable` with `Tracer`. The Span name will be taken either from the
// `@SpanName` annotation or from `toString` method
Callable traceCallableFromTracer = tracer.wrap(callable);
这样,您将确保为每次执行创建并关闭新的Span。
Hystrix
自定义并发策略
我们正在注册HystrixConcurrencyStrategy将所有Callable实例包装到他们的Sleuth代表 -TraceCallable中的定制。该策略是启动或继续跨越,这取决于调用Hystrix命令之前跟踪是否已经进行的事实。要禁用自定义Hystrix并发策略,将spring.sleuth.hystrix.strategy.enabled设置为false。
手动命令设置
假设您有以下HystrixCommand:
HystrixCommand hystrixCommand = new HystrixCommand(setter) {
@Override
protected String run() throws Exception {
return someLogic();
}
};
为了传递跟踪信息,您必须在HystrixCommand的HystrixCommand的Sleuth版本中包装相同的逻辑:
TraceCommand traceCommand = new TraceCommand(tracer, traceKeys, setter) {
@Override
public String doRun() throws Exception {
return someLogic();
}
};
RxJava
我们正在注册RxJavaSchedulersHook将所有Action0实例包装到他们的Sleuth代表 -TraceAction中的定制。钩子起动或继续一个跨度取决于跟踪在Action被安排之前是否已经进行的事实。要禁用自定义RxJavaSchedulersHook,将spring.sleuth.rxjava.schedulers.hook.enabled设置为false。
您可以定义线程名称的正则表达式列表,您不希望创建一个Span。只需在spring.sleuth.rxjava.schedulers.ignoredthreads属性中提供逗号分隔的正则表达式列表。
HTTP集成
可以通过提供值等于false的spring.sleuth.web.enabled属性来禁用此部分的功能。
HTTP过滤器
通过TraceFilter所有采样的进入请求导致创建Span。Span的名称是http:+发送请求的路径。例如,如果请求已发送到/foo/bar,则该名称将为http:/foo/bar。您可以通过spring.sleuth.web.skipPattern属性配置要跳过的URI。如果您在类路径上有ManagementServerProperties,则其值contextPath将附加到提供的跳过模式。
的HandlerInterceptor
由于我们希望跨度名称是精确的,我们使用的TraceHandlerInterceptor包装现有的HandlerInterceptor,或直接添加到现有的HandlerInterceptors列表中。TraceHandlerInterceptor向给定的HttpServletRequest添加了一个特殊请求属性。如果TraceFilter没有看到此属性集,它将创建一个“后备”跨度,这是在服务器端创建的一个额外的跨度,以便在UI中正确显示跟踪。看到最有可能意味着有一个缺失的仪器。在这种情况下,请在Spring Cloud Sleuth中提出问题。
异步Servlet支持
如果您的控制器返回Callable或WebAsyncTaskSpring Cloud,Sleuth将继续现有的跨度,而不是创建一个新的跨度。
HTTP客户端集成
同步休息模板
我们注入一个RestTemplate拦截器,确保所有跟踪信息都传递给请求。每次呼叫都会创建一个新的Span。收到回应后关闭。为了阻止将spring.sleuth.web.client.enabled设置为false的同步RestTemplate功能。
重要
你必须注册RestTemplate作为一个bean,以便拦截器被注入。如果您使用new关键字创建RestTemplate实例,那么该工具将不工作。
异步休息模板
重要
一个AsyncRestTemplatebean的跟踪版本是为您开箱即用的。如果你有自己的bean,你必须用TraceAsyncRestTemplate表示来包装它。最好的解决方案是只定制ClientHttpRequestFactory和/或AsyncClientHttpRequestFactory。如果您有自己的AsyncRestTemplate,并且您不要包装您的电话将不会被追踪。
定制仪器设置为在发送和接收请求时创建和关闭跨度。您可以通过注册您的bean来自定义ClientHttpRequestFactory和AsyncClientHttpRequestFactory。记住使用跟踪兼容的实现(例如,不要忘记在TraceAsyncListenableTaskExecutor中包装ThreadPoolTaskScheduler)。自定义请求工厂示例:
@EnableAutoConfiguration
@Configuration
public static class TestConfiguration {
@Bean
ClientHttpRequestFactory mySyncClientFactory() {
return new MySyncClientHttpRequestFactory();
}
@Bean
AsyncClientHttpRequestFactory myAsyncClientFactory() {
return new MyAsyncClientHttpRequestFactory();
}
}
将AsyncRestTemplate功能集spring.sleuth.web.async.client.enabled阻止为false。禁用TraceAsyncClientHttpRequestFactoryWrapper设置spring.sleuth.web.async.client.factory.enabled设置为false。如果您不想将所有spring.sleuth.web.async.client.template.enabledfalse的AsyncRestClient创建为false。
Feign
默认情况下,Spring Cloud Sleuth通过TraceFeignClientAutoConfiguration提供与feign的集成。您可以通过将spring.sleuth.feign.enabled设置为false来完全禁用它。如果这样做,那么不会发生Feign相关的仪器。
Feign仪器的一部分是通过FeignBeanPostProcessor完成的。您可以通过提供spring.sleuth.feign.processor.enabled等于false来禁用它。如果你这样设置,那么Spring Cloud Sleuth不会调整你的任何自定义Feign组件。然而,所有默认的工具仍然存在。
异步通信
@Async注释方法
在Spring Cloud Sleuth中,我们正在调用异步相关组件,以便跟踪信息在线程之间传递。您可以通过将spring.sleuth.async.enabled的值设置为false来禁用此行为。
如果您使用@Async注释方法,那么我们将自动创建一个具有以下特征的新的Span:
Span名称将是注释方法名称
Span将被该方法的类名称和方法名称标记
@Scheduled注释方法
在Spring Cloud Sleuth中,我们正在调试计划的方法执行,以便跟踪信息在线程之间传递。您可以通过将spring.sleuth.scheduled.enabled的值设置为false来禁用此行为。
如果您使用@Scheduled注释方法,那么我们将自动创建一个具有以下特征的新的Span:
Span名称将是注释方法名称
Span将被该方法的类名称和方法名称标记
如果要跳过某些@Scheduled注释类的Span创建,您可以使用与@Scheduled注释类的完全限定名称匹配的正则表达式来设置spring.sleuth.scheduled.skipPattern。
小费
如果您一起使用spring-cloud-sleuth-stream和spring-cloud-netflix-hystrix-stream,将为每个Hystrix指标创建Span并发送到Zipkin。这可能是恼人的。您可以设置spring.sleuth.scheduled.skipPattern=org.springframework.cloud.netflix.hystrix.stream.HystrixStreamTask
Executor,ExecutorService和ScheduledExecutorService
我们提供LazyTraceExecutor,TraceableExecutorService和TraceableScheduledExecutorService。每次提交,调用或调度新任务时,这些实现都将创建Spans。
在这里,您可以看到使用CompletableFuture使用TraceableExecutorService传递跟踪信息的示例:
CompletableFuture completableFuture = CompletableFuture.supplyAsync(() -> {
// perform some logic
return 1_000_000L;
}, new TraceableExecutorService(executorService,
// 'calculateTax' explicitly names the span - this param is optional
tracer, traceKeys, spanNamer, "calculateTax"));
消息
Spring Cloud Sleuth与Spring Integration集成。它创建spans发布和订阅事件。要禁用Spring Integration检测,请将spring.sleuth.integration.enabled设置为false。
您可以提供spring.sleuth.integration.patterns模式,以明确提供要包括的用于跟踪的通道的名称。默认情况下,所有通道都包含在内。
重要
当使用Executor构建Spring IntegrationIntegrationFlow时,请记住使用Executor的未跟踪版本。用TraceableExecutorService装饰Spring Integration执行者频道将导致spans被关闭。
Zuul
我们正在注册Zuul过滤器来传播跟踪信息(请求标头丰富了跟踪数据)。要禁用Zuul支持,请将spring.sleuth.zuul.enabled属性设置为false。
运行示例
您可以在Pivotal Web Services中找到部署的运行示例。在以下链接中查看它们:
Zipkin表示样品中的应用程序到顶部
Zipkin为啤酒厂在PWS,其Github代码
Spring Cloud Consul
Dalston.RELEASE
该项目通过自动配置并绑定到Spring环境和其他Spring编程模型成语,为Spring Boot应用程序提供Consul集成。通过几个简单的注释,您可以快速启用和配置应用程序中的常见模式,并使用基于Consul的组件构建大型分布式系统。提供的模式包括服务发现,控制总线和配置。智能路由(Zuul)和客户端负载平衡(Ribbon),断路器(Hystrix)通过与Spring Cloud Netflix的集成提供。
安装Consul
请参阅安装文档获取有关如何安装Consul指令。
Consul Agent
所有Spring Cloud Consul应用程序必须可以使用Consul Agent客户端。默认情况下,代理客户端预计位于localhost:8500。有关如何启动代理客户端以及如何连接到Consul Agent服务器集群的详细信息,请参阅代理文档。对于开发,安装领事后,您可以使用以下命令启动Consul Agent:
./src/main/bash/local_run_consul.sh
这将启动端口8500上的服务器模式的代理,其中ui可以在http:// localhost:8500上找到
服务发现与Consul
服务发现是基于微服务架构的关键原则之一。尝试配置每个客户端或某种形式的约定可能非常困难,可以非常脆弱。Consul通过HTTP API和DNS提供服务发现服务。Spring Cloud Consul利用HTTP API进行服务注册和发现。这不会阻止非Spring Cloud应用程序利用DNS界面。Consul代理服务器在通过八卦协议进行通信的集群中运行,并使用Raft协议协议。
如何激活
要激活Consul服务发现,请使用组org.springframework.cloud和artifact idspring-cloud-starter-consul-discovery的启动器。有关使用当前的Spring Cloud发布列表设置构建系统的详细信息,请参阅Spring Cloud项目页面。
注册Consul
当客户端注册Consul时,它提供有关自身的元数据,如主机和端口,ID,名称和标签。默认情况下会创建一个HTTP检查,每隔10秒,Consul命中/health端点。如果健康检查失败,则服务实例被标记为关键。
示例Consul客户端:
@SpringBootApplication
@EnableDiscoveryClient
@RestController
public class Application {
@RequestMapping("/")
public String home() {
return "Hello world";
}
public static void main(String[] args) {
new SpringApplicationBuilder(Application.class).web(true).run(args);
}
}
(即完全正常的Spring Boot应用程序)。如果Consul客户端位于localhost:8500以外的位置,则需要配置来定位客户端。例:
application.yml
spring:
cloud:
consul:
host: localhost
port: 8500
警告
如果您使用Spring Cloud Consul Config,上述值将需要放在bootstrap.yml而不是application.yml中。
来自Environment的默认服务名称,实例ID和端口分别为${spring.application.name},Spring上下文ID和${server.port}。
@EnableDiscoveryClient将应用程序设为Consul“服务”(即注册自己)和“客户端”(即可以查询Consul查找其他服务)。
HTTP健康检查
Consul实例的运行状况检查默认为“/ health”,这是Spring Boot执行器应用程序中有用端点的默认位置。如果您使用非默认上下文路径或servlet路径(例如server.servletPath=/foo)或管理端点路径(例如management.context-path=/admin),则需要更改这些,即使是执行器应用程序。也可以配置Consul用于检查运行状况端点的间隔。“10s”和“1m”分别表示10秒和1分钟。例:
application.yml
spring:
cloud:
consul:
discovery:
healthCheckPath: ${management.context-path}/health
healthCheckInterval: 15s
元数据和Consul标签
Consul尚未支持服务元数据。Spring Cloud的ServiceInstance有一个Map metadata字段。Spring Cloud Consul使用Consul标签来近似元数据,直到Consul正式支持元数据。使用key=value形式的标签将被分割并分别用作Map键和值。标签没有相同的=符号,将被用作键和值两者。
application.yml
spring:
cloud:
consul:
discovery:
tags: foo=bar, baz
上述配置将导致具有foo→bar和baz→baz的映射。
使Consul实例ID唯一
默认情况下,一个领事实体注册了一个等于其Spring应用程序上下文ID的ID。默认情况下,Spring应用程序上下文ID为${spring.application.name}:comma,separated,profiles:${server.port}。在大多数情况下,这将允许一个服务的多个实例在一台机器上运行。如果需要进一步的唯一性,使用Spring Cloud,您可以通过在spring.cloud.consul.discovery.instanceId中提供唯一的标识来覆盖此。例如:
application.yml
spring:
cloud:
consul:
discovery:
instanceId: ${spring.application.name}:${vcap.application.instance_id:${spring.application.instance_id:${random.value}}}
使用这个元数据和在localhost上部署的多个服务实例,随机值将在那里进行,以使实例是唯一的。在Cloudfoundry中,vcap.application.instance_id将在Spring Boot应用程序中自动填充,因此不需要随机值。
使用DiscoveryClient
Spring Cloud支持Feign(REST客户端构建器),SpringRestTemplate使用逻辑服务名称而不是物理URL。
您还可以使用org.springframework.cloud.client.discovery.DiscoveryClient,它为Netflix不特定的发现客户端提供了一个简单的API,例如
@Autowired
private DiscoveryClient discoveryClient;
public String serviceUrl() {
List list = discoveryClient.getInstances("STORES");
if (list != null && list.size() > 0 ) {
return list.get(0).getUri();
}
return null;
}
具有Consul的分布式配置
Consul提供了一个用于存储配置和其他元数据的键/值存储。Spring Cloud Consul Config是Config Server和Client的替代方案。在特殊的“引导”阶段,配置被加载到Spring环境中。默认情况下,配置存储在/config文件夹中。基于应用程序的名称和模拟解析属性的Spring Cloud Config顺序的活动配置文件创建多个PropertySource实例。例如,名为“testApp”的应用程序和“dev”配置文件将创建以下属性源:
config/testApp,dev/
config/testApp/
config/application,dev/
config/application/
最具体的物业来源位于顶部,底部最不具体。Properties是config/application文件夹适用于使用consul进行配置的所有应用程序。config/testApp文件夹中的Properties仅适用于名为“testApp”的服务实例。
配置当前在应用程序启动时被读取。发送HTTP POST到/refresh将导致配置被重新加载。观看关键价值商店(Consul支持))目前不可能,但将来将是此项目的补充。
如何激活
要开始使用Consul配置,请使用组org.springframework.cloud和artifact idspring-cloud-starter-consul-config的启动器。有关使用当前的Spring Cloud发布列表设置构建系统的详细信息,请参阅Spring Cloud项目页面。
这将启用自动配置,将设置Spring Cloud Consul配置。
定制
Consul可以使用以下属性定制配置:
bootstrap.yml
spring:
cloud:
consul:
config:
enabled: true
prefix: configuration
defaultContext: apps
profileSeparator: '::'
enabled将此值设置为“false”禁用Consul配置
prefix设置配置值的基本文件夹
defaultContext设置所有应用程序使用的文件夹名称
profileSeparator设置用于使用配置文件在属性源中分隔配置文件名称的分隔符的值
配置观察
Consul配置观察功能可以利用领事看守钥匙前缀的能力。Config Watch会阻止Consul HTTP API调用,以确定当前应用程序是否有任何相关配置数据发生更改。如果有新的配置数据,则会发布刷新事件。这相当于调用/refresh执行器端点。
要更改Config Watch调用的频率changespring.cloud.consul.config.watch.delay。默认值为1000,以毫秒为单位。
禁用配置观察集spring.cloud.consul.config.watch.enabled=false。
YAML或Properties配置
与单个键/值对相反,可以更方便地将YBL或Properties格式的属性块存储起来。将spring.cloud.consul.config.format属性设置为YAML或PROPERTIES。例如使用YAML:
bootstrap.yml
spring:
cloud:
consul:
config:
format: YAML
YAML必须在合适的data键中设置。使用键上面的默认值将如下所示:
config/testApp,dev/data
config/testApp/data
config/application,dev/data
config/application/data
您可以将YAML文档存储在上述任何键中。
您可以使用spring.cloud.consul.config.data-key更改数据密钥。
git2consul与配置
git2consul是一个Consul社区项目,将文件从git存储库加载到各个密钥到Consul。默认情况下,密钥的名称是文件的名称。YAML和Properties文件分别支持.yml和.properties的文件扩展名。将spring.cloud.consul.config.format属性设置为FILES。例如:
bootstrap.yml
spring:
cloud:
consul:
config:
format: FILES
给定/config中的以下密钥,development配置文件和应用程序名称为foo:
.gitignore
application.yml
bar.properties
foo-development.properties
foo-production.yml
foo.properties
master.ref
将创建以下属性来源:
config/foo-development.properties
config/foo.properties
config/application.yml
每个键的值需要是一个格式正确的YAML或Properties文件。
快速失败
在某些情况下(如本地开发或某些测试场景)可能会方便,如果不能配置领事,则不会失败。在bootstrap.yml中设置spring.cloud.consul.config.failFast=false将导致配置模块记录一个警告而不是抛出异常。这将允许应用程序继续正常启动。
Consul重试
如果您希望您的应用程序启动时可能偶尔无法使用代理商,则可以要求您在发生故障后继续尝试。您需要在您的类路径中添加spring-retry和spring-boot-starter-aop。默认行为是重试6次,初始退避间隔为1000ms,指数乘数为1.1,用于后续退避。您可以使用spring.cloud.consul.retry.*配置属性配置这些属性(和其他)。这适用于Spring Cloud Consul配置和发现注册。
小费
要完全控制重试,请使用id为“consulRetryInterceptor”添加RetryOperationsInterceptor类型的@Bean。Spring重试有一个RetryInterceptorBuilder可以轻松创建一个。
Spring Cloud Bus与Consul
如何激活
要开始使用Consul总线,使用组org.springframework.cloud和工件idspring-cloud-starter-consul-bus的起动器。有关使用当前的Spring Cloud发布列表设置构建系统的详细信息,请参阅Spring Cloud项目页面。
有关可用的执行机构端点以及如何发送自定义消息,请参阅Spring Cloud Bus文档。
断路器与Hystrix
应用程序可以使用Spring Cloud Netflix项目提供的Hystrix断路器将这个启动器包含在项目pom.xml:spring-cloud-starter-hystrix中。Hystrix不依赖于Netflix Discovery Client。@EnableHystrix注释应放置在配置类(通常是主类)上。那么方法可以用@HystrixCommand注释来被断路器保护。有关详细信息,请参阅文档。
使用Turbine和Consul Hystrix指标聚合
Turbine(由Spring Cloud Netflix项目提供))聚合多个实例Hystrix指标流,因此仪表板可以显示聚合视图。Turbine使用DiscoveryClient接口查找相关实例。要将Turbine与Spring Cloud Consul结合使用,请按以下示例配置Turbine应用程序:
的pom.xml
org.springframework.cloud
spring-cloud-netflix-turbine
org.springframework.cloud
spring-cloud-starter-consul-discovery
请注意,Turbine依赖不是起始者。涡轮启动器包括对Netflix Eureka的支持。
application.yml
spring.application.name: turbine
applications: consulhystrixclient
turbine:
aggregator:
clusterConfig: ${applications}
appConfig: ${applications}
clusterConfig和appConfig部分必须匹配,因此将逗号分隔的服务标识列表放在单独的配置属性中是有用的。
Turbine。java的
@EnableTurbine
@EnableDiscoveryClient
@SpringBootApplication
public class Turbine {
public static void main(String[] args) {
SpringApplication.run(DemoturbinecommonsApplication.class, args);
}
}
Spring Cloud Zookeeper
该项目通过自动配置并绑定到Spring环境和其他Spring编程模型成语,为Spring Boot应用程序提供Zookeeper集成。通过几个简单的注释,您可以快速启用和配置应用程序中的常见模式,并使用基于Zookeeper的组件构建大型分布式系统。提供的模式包括服务发现和配置。智能路由(Zuul)和客户端负载平衡(Ribbon),断路器(Hystrix)通过与Spring Cloud Netflix的集成提供。
安装Zookeeper
请参阅安装文档获取有关如何安装Zookeeper指令。
服务发现与Zookeeper
服务发现是基于微服务架构的关键原则之一。尝试配置每个客户端或某种形式的约定可能非常困难,可以非常脆弱。策展人(一个用于Zookeeper的java库)通过服务发现扩展提供服务发现服务。Spring Cloud Zookeeper利用此扩展功能进行服务注册和发现。
如何激活
包括对org.springframework.cloud:spring-cloud-starter-zookeeper-discovery的依赖将启用将设置Spring Cloud Zookeeper发现的自动配置。
注意
您仍然需要包含org.springframework.boot:spring-boot-starter-web的网页功能。
注册Zookeeper
当客户端注册Zookeeper时,它提供有关自身的元数据,如主机和端口,ID和名称。
示例Zookeeper客户端:
@SpringBootApplication
@EnableDiscoveryClient
@RestController
public class Application {
@RequestMapping("/")
public String home() {
return "Hello world";
}
public static void main(String[] args) {
new SpringApplicationBuilder(Application.class).web(true).run(args);
}
}
(即完全正常的Spring Boot应用程序)。如果Zookeeper位于localhost:2181以外的地方,则需要配置来定位服务器。例:
application.yml
spring:
cloud:
zookeeper:
connect-string: localhost:2181
警告
如果您使用Spring Cloud Zookeeper配置,上述值将需要放置在bootstrap.yml而不是application.yml中。
来自Environment的默认服务名称,实例ID和端口分别为${spring.application.name},Spring上下文ID和${server.port}。
@EnableDiscoveryClient将应用程序同时进入Zookeeper“服务”(即注册自己)和“客户端”(即可以查询Zookeeper查找其他服务)。
使用DiscoveryClient
Spring Cloud支持Feign(REST客户端构建器),还支持SpringRestTemplate使用逻辑服务名称而不是物理URL。
您还可以使用org.springframework.cloud.client.discovery.DiscoveryClient,它为Netflix不具体的发现客户端提供简单的API,例如
@Autowired
private DiscoveryClient discoveryClient;
public String serviceUrl() {
List list = discoveryClient.getInstances("STORES");
if (list != null && list.size() > 0 ) {
return list.get(0).getUri().toString();
}
return null;
}
使用Spring Cloud Zookeeper与Spring Cloud Netflix组件
Spring Cloud Netflix提供有用的工具,无论使用哪种DiscoveryClient实现。Feign,Turbine,Ribbon和Zuul均与Spring Cloud Zookeeper合作。
Ribbon与Zookeeper
Spring Cloud Zookeeper提供Ribbon的ServerList的实现。当使用spring-cloud-starter-zookeeper-discovery时,Ribbon默认情况下自动配置为使用ZookeeperServerList。
Spring Cloud Zookeeper和服务注册表
Spring Cloud Zookeeper实现ServiceRegistry接口,允许开发人员以编程方式注册任意服务。
ServiceInstanceRegistration类提供builder()方法来创建可以由ServiceRegistry使用的Registration对象。
@Autowired
private ZookeeperServiceRegistry serviceRegistry;
public void registerThings() {
ZookeeperRegistration registration = ServiceInstanceRegistration.builder()
.defaultUriSpec()
.address("anyUrl")
.port(10)
.name("/a/b/c/d/anotherservice")
.build();
this.serviceRegistry.register(registration);
}
实例状态
Netflix Eureka支持在服务器上注册的实例是OUT_OF_SERVICE,而不是作为活动服务实例返回。这对于诸如蓝色/绿色部署之类的行为非常有用。策展人服务发现配方不支持此行为。利用灵活的有效载荷,让Spring Cloud Zookeeper通过更新一些特定的元数据,然后对RibbonZookeeperServerList中的元数据进行过滤来实现OUT_OF_SERVICE。ZookeeperServerList过滤出不等于UP的所有非空实例状态。如果实例状态字段为空,则向后兼容性被认为是UP。将实例POSTOUT_OF_SERVICE的状态更改为ServiceRegistry实例状态执行器端点。
----
$ echo -n OUT_OF_SERVICE | http POST http://localhost:8081/service-registry/instance-status
----
NOTE: The above example uses the `http` command from https://httpie.org
Zookeeper依赖关系
使用Zookeeper依赖关系
Spring Cloud Zookeeper可以让您提供应用程序的依赖关系作为属性。作为依赖关系,您可以了解Zookeeper中注册的其他应用程序,您可以通过Feign(REST客户端构建器)以及SpringRestTemplate呼叫。
您还可以从Zookeeper依赖关系观察者功能中受益,这些功能可让您控制和监视依赖关系的状态,并决定如何处理。
如何激活Zookeeper依赖关系
包括对org.springframework.cloud:spring-cloud-starter-zookeeper-discovery的依赖将启用将自动配置Spring Cloud Zookeeper依赖关系的自动配置。
如果您必须正确设置spring.cloud.zookeeper.dependencies部分 - 请查看后续部分以获取更多详细信息,然后该功能处于活动状态
即使您在属性中提供依赖关系,也可以关闭依赖关系。只需将属性spring.cloud.zookeeper.dependency.enabled设置为false(默认为true)。
设置Zookeeper依赖关系
我们来仔细看一下依赖关系表示的例子:
application.yml
spring.application.name: yourServiceName
spring.cloud.zookeeper:
dependencies:
newsletter:
path: /path/where/newsletter/has/registered/in/zookeeper
loadBalancerType: ROUND_ROBIN
contentTypeTemplate: application/vnd.newsletter.$version+json
version: v1
headers:
header1:
- value1
header2:
- value2
required: false
stubs: org.springframework:foo:stubs
mailing:
path: /path/where/mailing/has/registered/in/zookeeper
loadBalancerType: ROUND_ROBIN
contentTypeTemplate: application/vnd.mailing.$version+json
version: v1
required: true
现在让我们一个接一个地遍历依赖的每个部分。根属性名称为spring.cloud.zookeeper.dependencies。
别名
在根属性下面,由于Ribbon的限制,必须通过别名来表示每个依赖关系(应用程序ID必须放在URL中,因此您不能传递任何复杂的路径,如/ foo / bar / name )。别名将是您将使用的名称,而不是DiscoveryClient,Feign或RestTemplate的serviceId。
在上述例子中,别名是newsletter和mailing。使用newsletter的Feign使用示例为:
@FeignClient("newsletter")
public interface NewsletterService {
@RequestMapping(method = RequestMethod.GET, value = "/newsletter")
String getNewsletters();
}
路径
代表pathyaml属性。
Path是根据Zookeeper注册依赖关系的路径。像Ribbon之前提交的URL,因此这个路径不符合其要求。这就是为什么Spring Cloud Zookeeper将别名映射到正确的路径。
负载平衡器类型
代表loadBalancerTypeyaml属性。
如果您知道在调用此特定依赖关系时必须应用什么样的负载平衡策略,那么您可以在yaml文件中提供它,并将自动应用。您可以选择以下负载平衡策略之一
STICKY - 一旦选择了该实例将始终被调用
随机 - 随机选择一个实例
ROUND_ROBIN - 一遍又一遍地迭代实例
Content-Type模板和版本
代表contentTypeTemplate和versionyaml属性。
如果您通过Content-Type标题版本您的api,那么您不想将此标头添加到您的每个请求中。另外如果你想调用一个新版本的API,你不想漫游你的代码,以增加API版本。这就是为什么您可以提供contentTypeTemplate特殊$version占位符的原因。该占位符将由versionyaml属性的值填充。我们来看一个例子。
拥有以下contentTypeTemplate:
application/vnd.newsletter.$version+json
和以下version:
v1
将导致为每个请求设置Content-Type标题:
application/vnd.newsletter.v1+json
默认标题
由yaml代表headers映射
有时每次调用依赖关系都需要设置一些默认标头。为了不在代码中这样做,您可以在yaml文件中设置它们。拥有以下headers部分:
headers:
Accept:
- text/html
- application/xhtml+xml
Cache-Control:
- no-cache
结果在您的HTTP请求中添加适当的值列表的Accept和Cache-Control标头。
强制依赖
在yaml中由required属性表示
如果您的一个依赖关系在您的应用程序启动时需要启动并运行,则可以在yaml文件中设置required: true属性。
如果您的应用程序无法在引导期间本地化所需的依赖关系,则会抛出异常,并且Spring上下文将无法设置。换句话说,如果Zookeeper中没有注册所需的依赖关系,则您的应用程序将无法启动。
您可以在以下部分阅读有关Spring Cloud Zookeeper存在检查器的更多信息。
存根
您可以为包含依赖关系的存根的JAR提供冒号分隔路径。例
stubs: org.springframework:foo:stubs
意味着对于特定的依赖关系可以在下面找到:
groupId:org.springframework
artifactId:foo
分类器:stubs- 这是默认值
这实际上等于
stubs: org.springframework:foo
因为stubs是默认分类器。
配置Spring Cloud Zookeeper依赖关系
有一些属性可以设置为启用/禁用Zookeeper依赖关系功能的部分。
spring.cloud.zookeeper.dependencies- 如果您不设置此属性,则不会从Zookeeper依赖关系中受益
spring.cloud.zookeeper.dependency.ribbon.enabled(默认情况下启用) - Ribbon需要显式的全局配置或特定的依赖关系。通过打开此属性,运行时负载平衡策略解决是可能的,您可以从Zookeeper依赖关系的loadBalancerType部分获利。需要此属性的配置具有LoadBalancerClient的实现,委托给下一个子弹中的ILoadBalancer
spring.cloud.zookeeper.dependency.ribbon.loadbalancer(默认情况下启用) - 感谢这个属性,自定义ILoadBalancer知道传递给Ribbon的URI部分实际上可能是必须被解析为Zookeeper。没有此属性,您将无法在嵌套路径下注册应用程序。
spring.cloud.zookeeper.dependency.headers.enabled(默认情况下启用) - 此属性注册这样的一个RibbonClient,它会自动附加适当的头文件和内容类型,其中包含依赖关系配置中显示的版本。没有这两个参数的设置将不会运行。
spring.cloud.zookeeper.dependency.resttemplate.enabled(默认情况下启用) - 启用时将修改@LoadBalanced注释的RestTemplate的请求标头,以便它通过依赖关系配置中设置的版本的标题和内容类型。Wihtout这两个参数的设置将无法运行。
Spring Cloud Zookeeper依赖关系观察者
依赖关系观察器机制允许您将侦听器注册到依赖关系中。功能实际上是Observator模式的实现。当依赖关系改变其状态(UP或DOWN)时,可以应用一些自定义逻辑。
如何激活
Spring Cloud Zookeeper依赖关系功能需要启用从依赖关系观察器机制中获利。
注册听众
为了注册一个监听器,你必须实现一个接口org.springframework.cloud.zookeeper.discovery.watcher.DependencyWatcherListener,并将其注册为一个bean。该界面为您提供了一种方法:
void stateChanged(String dependencyName, DependencyState newState);
如果要为特定的依赖关系注册一个侦听器,那么dependencyName将是具体实现的鉴别器。newState将提供您的依赖关系是否已更改为CONNECTED或DISCONNECTED的信息。
存在检查
绑定与依赖关系观察器是称为存在检查器的功能。它允许您在启动应用程序时提供自定义行为,以根据您的依赖关系的状态作出反应。
抽象org.springframework.cloud.zookeeper.discovery.watcher.presence.DependencyPresenceOnStartupVerifier类的默认实现是org.springframework.cloud.zookeeper.discovery.watcher.presence.DefaultDependencyPresenceOnStartupVerifier,它以以下方式工作。
如果依赖关系标记为我们required,并且不在Zookeeper中,则在引导时,您的应用程序将抛出异常并关闭
如果依赖关系不是required,org.springframework.cloud.zookeeper.discovery.watcher.presence.LogMissingDependencyChecker将在WARN级别上记录该应用程序
功能可以被覆盖,因为只有当没有DependencyPresenceOnStartupVerifier的bean时才会注册DefaultDependencyPresenceOnStartupVerifier。
分布式配置与Zookeeper
Zookeeper提供了一个分层命名空间,允许客户端存储任意数据,如配置数据。Spring Cloud Zookeeper Config是Config Server和Client的替代方案。在特殊的“引导”阶段,配置被加载到Spring环境中。默认情况下,配置存储在/config命名空间中。根据应用程序的名称和模拟解析属性的Spring Cloud Config顺序的活动配置文件,创建多个PropertySource实例。例如,名为“testApp”的应用程序和“dev”配置文件将创建以下属性源:
config/testApp,dev
config/testApp
config/application,dev
config/application
最具体的物业来源位于顶部,底部最不具体。Properties是config/application命名空间适用于使用zookeeper进行配置的所有应用程序。config/testApp命名空间中的Properties仅适用于名为“testApp”的服务实例。
配置当前在应用程序启动时被读取。发送HTTP POST到/refresh将导致重新加载配置。观看配置命名空间(Zookeeper支持))目前尚未实现,但将来将会添加到此项目中。
如何激活
包括对org.springframework.cloud:spring-cloud-starter-zookeeper-config的依赖将启用将配置Spring Cloud Zookeeper配置的自动配置。
定制
Zookeeper可以使用以下属性自定义配置:
bootstrap.yml
spring:
cloud:
zookeeper:
config:
enabled: true
root: configuration
defaultContext: apps
profileSeparator: '::'
enabled将此值设置为“false”将禁用Zookeeper配置
root设置配置值的基本命名空间
defaultContext设置所有应用程序使用的名称
profileSeparator设置用于使用配置文件在属性源中分隔配置文件名称的分隔符的值
spring-cloud.adoc中的未解决的指令 - include :: / Users / sgibb / workspace / spring / spring-cloud-samples / scripts / docs /../ cli / docs / src / main / asciidoc / spring-cloud-cli。 ADOC []
Spring Cloud Security
Spring Cloud Security提供了一组用于构建安全应用程序和服务的原语,最小化。可以从外部(或集中)高度配置的声明式模型适用于通常使用中央契约管理服务的大型合作远程组件系统的实现。在像Cloud Foundry这样的服务平台上也很容易使用。基于Spring Boot和Spring安全性OAuth2,我们可以快速创建实现常见模式的系统,如单点登录,令牌中继和令牌交换。
注意
Spring Cloud根据非限制性Apache 2.0许可证发布。如果您想为文档的这一部分做出贡献,或者发现错误,请在github中找到项目中的源代码和问题跟踪器。
快速开始
OAuth2单一登录
这是一个具有HTTP基本身份验证和单个用户帐户的Spring Cloud“Hello World”应用程序
app.groovy
@Grab('spring-boot-starter-security')
@Controller
class Application {
@RequestMapping('/')
String home() {
'Hello World'
}
}
您可以使用spring run app.groovy运行它,并观察日志的密码(用户名为“用户”)。到目前为止,这只是一个Spring Boot应用程序的默认设置。
这是一个使用OAuth2 SSO的Spring Cloud应用程序:
app.groovy
@Controller
@EnableOAuth2Sso
class Application {
@RequestMapping('/')
String home() {
'Hello World'
}
}
指出不同?这个应用程序的行为实际上与之前的一样,因为它不知道它是OAuth2的信誉。
您可以很容易地在github注册一个应用程序,所以如果你想要一个生产应用程序在你自己的域上尝试。如果您很乐意在localhost:8080上测试,那么请在应用程序配置中设置这些属性:
application.yml
security:
oauth2:
client:
clientId: bd1c0a783ccdd1c9b9e4
clientSecret: 1a9030fbca47a5b2c28e92f19050bb77824b5ad1
accessTokenUri: https://github.com/login/oauth/access_token
userAuthorizationUri: https://github.com/login/oauth/authorize
clientAuthenticationScheme: form
resource:
userInfoUri: https://api.github.com/user
preferTokenInfo: false
运行上面的应用程序,它将重定向到github进行授权。如果您已经登录github,您甚至不会注意到它已经通过身份验证。只有您的应用程序在8080端口上运行,这些凭据才会起作用。
要限制客户端在获取访问令牌时要求的范围,您可以设置security.oauth2.client.scope(逗号分隔或YAML中的数组)。默认情况下,作用域为空,由授权服务器确定默认值是什么,通常取决于客户端注册中的设置。
注意
上面的例子都是Groovy脚本。如果要在Java(或Groovy)中编写相同的代码,则需要将Spring Security OAuth2添加到类路径中(例如,请参阅此处的示例)。
OAuth2受保护资源
您要使用OAuth2令牌保护API资源?这是一个简单的例子(与上面的客户端配对):
app.groovy
@Grab('spring-cloud-starter-security')
@RestController
@EnableResourceServer
class Application {
@RequestMapping('/')
def home() {
[message: 'Hello World']
}
}
和
application.yml
security:
oauth2:
resource:
userInfoUri: https://api.github.com/user
preferTokenInfo: false
更多详情
单点登录
注意
所有OAuth2 SSO和资源服务器功能在版本1.3中移动到Spring Boot。您可以在Spring Boot用户指南中找到文档。
令牌中继
令牌中继是OAuth2消费者充当客户端,并将传入令牌转发到外发资源请求。消费者可以是纯客户端(如SSO应用程序)或资源服务器。
客户端令牌中继
如果您的应用是面向OAuth2客户端的用户(即声明为@EnableOAuth2Sso或@EnableOAuth2Client),那么它的请求范围为spring security的OAuth2ClientContext。您可以从此上下文和自动连线OAuth2ProtectedResourceDetails创建自己的OAuth2RestTemplate,然后上下文将始终向下转发访问令牌,如果过期则自动刷新访问令牌。(这些是Spring安全和Spring Boot的功能。)
注意
如果您使用client_credentials令牌,则Spring Boot(1.4.1)不会自动创建OAuth2ProtectedResourceDetails。在这种情况下,您需要创建自己的ClientCredentialsResourceDetails并使用@ConfigurationProperties("security.oauth2.client")进行配置。
客户端令牌中继在Zuul代理
如果您的应用程式还有Spring Cloud Zuul嵌入式反向代理(使用@EnableZuulProxy),那么您可以要求将OAuth2访问令牌转发到其正在代理的服务。因此,上述的SSO应用程序可以简单地增强:
app.groovy
@Controller
@EnableOAuth2Sso
@EnableZuulProxy
class Application {
}
并且(除了将用户登录并抓取令牌之外)将下载的身份验证令牌传递到/proxy/*服务。如果这些服务是用@EnableResourceServer实现的,那么他们将在正确的标题中获得一个有效的标记。
它是如何工作的?@EnableOAuth2Sso注释引入spring-cloud-starter-security(您可以在传统应用程序中手动执行),而这又会触发一个ZuulFilter的自动配置,该属性本身被激活,因为Zuul在classpath(通过@EnableZuulProxy)。该过滤器仅从当前已认证的用户提取访问令牌,并将其放入下游请求的请求头中。
资源服务器令牌中继
如果您的应用有@EnableResourceServer,您可能希望将传入令牌下载到其他服务。如果您使用RestTemplate联系下游服务,那么这只是如何使用正确的上下文创建模板的问题。
如果您的服务使用UserInfoTokenServices验证传入令牌(即正在使用security.oauth2.user-info-uri配置)),则可以使用自动连线OAuth2ClientContext创建OAuth2RestTemplate(将由身份验证过程之前它遇到后端代码)。相等(使用Spring Boot 1.4),您可以在配置中注入UserInfoRestTemplateFactory并抓取其中的OAuth2RestTemplate。例如:
MyConfiguration.java
@Bean
public OAuth2RestTemplate restTemplate(UserInfoRestTemplateFactory factory) {
return factory.getUserInfoRestTemplate();
}
然后,此休息模板将具有由身份验证过滤器使用的OAuth2ClientContext(请求作用域)相同,因此您可以使用它来发送具有相同访问令牌的请求。
如果您的应用没有使用UserInfoTokenServices,但仍然是客户端(即声明@EnableOAuth2Client或@EnableOAuth2Sso),则使用Spring安全云任何OAuth2RestOperations,用户从@Autowired@OAuth2Context也会转发令牌。此功能默认实现为MVC处理程序拦截器,因此它仅适用于Spring MVC。如果您不使用MVC,可以使用包含AccessTokenContextRelay的自定义过滤器或AOP拦截器来提供相同的功能。
以下是一个基本示例,显示了使用其他地方创建的自动连线休息模板(“foo.com”是一个资源服务器,接受与周围应用程序相同的令牌):
MyController.java
@Autowired
private OAuth2RestOperations restTemplate;
@RequestMapping("/relay")
public String relay() {
ResponseEntity response =
restTemplate.getForEntity("https://foo.com/bar", String.class);
return "Success! (" + response.getBody() + ")";
}
如果您不想转发令牌(这是一个有效的选择,因为您可能希望以自己的身份而不是向您发送令牌的客户端),那么您只需要创建自己的OAuth2Context的自动装配默认值。
Feign客户端也会选择使用OAuth2ClientContext的拦截器,如果它是可用的,那么他们还应该在RestTemplate将要执行的令牌中继。
配置Zuul代理下游的认证
您可以通过proxy.auth.*设置控制@EnableZuulProxy下游的授权行为。例:
application.yml
proxy:
auth:
routes:
customers: oauth2
stores: passthru
recommendations: none
在此示例中,“客户”服务获取OAuth2令牌中继,“存储”服务获取传递(授权头只是通过下游),“建议”服务已删除其授权头。如果有令牌可用,则默认行为是执行令牌中继,否则为passthru。
有关详细信息,请参阅ProxyAuthenticationProperties。
Spring Cloud为Cloud Foundry
Cloudfoundry的Spring Cloud可以轻松地在Cloud Foundry(平台即服务)中运行Spring Cloud应用程序。Cloud Foundry有一个“服务”的概念,它是“绑定”到应用程序的中间件,本质上为其提供包含凭据的环境变量(例如,用于服务的位置和用户名)。
spring-cloud-cloudfoundry-web项目为Cloud Foundry中的webapps的一些增强功能提供基本支持:自动绑定到单点登录服务,并可选择启用粘性路由进行发现。
spring-cloud-cloudfoundry-discovery项目提供Spring Cloud CommonsDiscoveryClient的实施,因此您可以@EnableDiscoveryClient并将您的凭据提供为spring.cloud.cloudfoundry.discovery.[email,password],然后直接或通过LoadBalancerClient使用DiscoveryClient/}(如果您没有连接到Pivotal Web Services,则也为*.url)。
第一次使用它时,发现客户端可能很慢,因为它必须从Cloud Foundry获取访问令牌。
发现
以下是Cloud Foundry发现的Spring Cloud应用程序:
app.groovy
@Grab('org.springframework.cloud:spring-cloud-cloudfoundry')
@RestController
@EnableDiscoveryClient
class Application {
@Autowired
DiscoveryClient client
@RequestMapping('/')
String home() {
'Hello from ' + client.getLocalServiceInstance()
}
}
如果您运行它没有任何服务绑定:
$ spring jar app.jar app.groovy
$ cf push -p app.jar
它将在主页中显示其应用程序名称。
DiscoveryClient可以根据身份验证的凭据列出空间中的所有应用程序,其中的空间默认为客户端运行的空间(如果有的话)。如果组织和空间都不配置,则它们将根据Cloud Foundry中的用户配置文件进行默认。
单点登录
注意
所有OAuth2 SSO和资源服务器功能在版本1.3中移动到Spring Boot。您可以在Spring Boot用户指南中找到文档。
该项目提供从CloudFoundry服务凭据到Spring Boot功能的自动绑定。如果您有一个称为“sso”的CloudFoundry服务,例如,使用包含“client_id”,“client_secret”和“auth_domain”的凭据,它将自动绑定到您使用@EnableOAuth2Sso启用的Spring OAuth2客户端来自Spring Boot)。可以使用spring.oauth2.sso.serviceId对服务的名称进行参数化。
Spring Cloud Contract
文献作者:Adam Dudczak,MathiasDüsterhöft,Marcin Grzejszczak,Dennis Kieselhorst,JakubKubryński,Karol Lassak,Olga Maciaszek-Sharma,MariuszSmykuła,Dave Syer
Dalston.RELEASE
Spring Cloud Contract
您始终需要的是将新功能推向分布式系统中的新应用程序或服务的信心。该项目为Spring应用程序中的消费者驱动Contracts和服务架构提供支持,涵盖了一系列用于编写测试的选项,将其作为资产发布,声称生产者和消费者保留合同用于HTTP和消息的交互。
Spring Cloud Contract WireMock
模块让您有可能使用WireMock使用嵌入在Spring Boot应用的“环境”服务器不同的服务器。查看样品了解更多详情。
重要
Spring Cloud发布列表BOM导入spring-cloud-contract-dependencies,这反过来又排除了WireMock所需的依赖关系。这可能导致一种情况,即使你不使用Spring Cloud Contract,那么你的依赖将会受到影响。
如果您有一个使用Tomcat作为嵌入式服务器的Spring Boot应用程序(默认为spring-boot-starter-web)),那么您可以简单地将spring-cloud-contract-wiremock添加到类路径中并添加@AutoConfigureWireMock,以便可以在测试中使用Wiremock。Wiremock作为存根服务器运行,您可以使用Java API或通过静态JSON声明来注册存根行为,作为测试的一部分。这是一个简单的例子:
@RunWith(SpringRunner.class)
@SpringBootTest(webEnvironment = WebEnvironment.RANDOM_PORT)
@AutoConfigureWireMock(port = 0)
public class WiremockForDocsTests {
// A service that calls out over HTTP
@Autowired private Service service;
// Using the WireMock APIs in the normal way:
@Test
public void contextLoads() throws Exception {
// Stubbing WireMock
stubFor(get(urlEqualTo("/resource"))
.willReturn(aResponse().withHeader("Content-Type", "text/plain").withBody("Hello World!")));
// We're asserting if WireMock responded properly
assertThat(this.service.go()).isEqualTo("Hello World!");
}
}
要使用@AutoConfigureWireMock(port=9999)(例如)启动不同端口上的存根服务器,并且对于随机端口使用值0.存根服务器端口将在测试应用程序上下文中绑定为“wiremock.server.port”。使用@AutoConfigureWireMock将一个类型为WiremockConfiguration的bean添加到测试应用程序上下文中,它将被缓存在具有相同上下文的方法和类之间,就像一般的Spring集成测试一样。
自动注册存根
如果您使用@AutoConfigureWireMock,则它将从文件系统或类路径注册WireMock JSON存根,默认情况下为file:src/test/resources/mappings。您可以使用注释中的stubs属性自定义位置,这可以是资源模式(ant-style)或目录,在这种情况下,附加*/.json。例:
@RunWith(SpringRunner.class)
@SpringBootTest
@AutoConfigureWireMock(stubs="classpath:/stubs")
public class WiremockImportApplicationTests {
@Autowired
private Service service;
@Test
public void contextLoads() throws Exception {
assertThat(this.service.go()).isEqualTo("Hello World!");
}
}
注意
实际上,WireMock总是从src/test/resources/mappings中加载映射以及stubs属性中的自定义位置。要更改此行为,您还必须如下所述指定文件根。
使用文件指定存根体
WireMock可以从类路径或文件系统上的文件读取响应体。在这种情况下,您将在JSON DSL中看到响应具有“bodyFileName”而不是(文字)“body”。默认情况下,相对于根目录src/test/resources/__files解析文件。要自定义此位置,您可以将@AutoConfigureWireMock注释中的files属性设置为父目录的位置(即,位置__files是子目录)。您可以使用Spring资源符号来引用file:…或classpath:…位置(但不支持通用URL)。可以给出值列表,并且WireMock将在需要查找响应体时解析存在的第一个文件。
注意
当配置files根时,它会影响自动加载存根(它们来自称为“映射”的子目录中的根位置)。files的值对从stubs属性明确加载的存根没有影响。
替代方法:使用JUnit规则
对于更常规的WireMock体验,使用JUnit@Rules启动和停止服务器,只需使用WireMockSpring便利类来获取Options实例:
@RunWith(SpringRunner.class)
@SpringBootTest(webEnvironment = WebEnvironment.RANDOM_PORT)
public class WiremockForDocsClassRuleTests {
// Start WireMock on some dynamic port
// for some reason `dynamicPort()` is not working properly
@ClassRule
public static WireMockClassRule wiremock = new WireMockClassRule(
WireMockSpring.options().dynamicPort());
// A service that calls out over HTTP to localhost:${wiremock.port}
@Autowired
private Service service;
// Using the WireMock APIs in the normal way:
@Test
public void contextLoads() throws Exception {
// Stubbing WireMock
wiremock.stubFor(get(urlEqualTo("/resource"))
.willReturn(aResponse().withHeader("Content-Type", "text/plain").withBody("Hello World!")));
// We're asserting if WireMock responded properly
assertThat(this.service.go()).isEqualTo("Hello World!");
}
}
使用@ClassRule表示服务器将在此类中的所有方法后关闭。
WireMock和Spring MVC模拟器
Spring Cloud Contract提供了一个方便的类,可以将JSON WireMock存根加载到SpringMockRestServiceServer中。以下是一个例子:
@RunWith(SpringRunner.class)
@SpringBootTest(webEnvironment = WebEnvironment.NONE)
public class WiremockForDocsMockServerApplicationTests {
@Autowired
private RestTemplate restTemplate;
@Autowired
private Service service;
@Test
public void contextLoads() throws Exception {
// will read stubs classpath
MockRestServiceServer server = WireMockRestServiceServer.with(this.restTemplate)
.baseUrl("http://example.org").stubs("classpath:/stubs/resource.json")
.build();
// We're asserting if WireMock responded properly
assertThat(this.service.go()).isEqualTo("Hello World");
server.verify();
}
}
baseUrl前面是所有模拟调用,stubs()方法将一个存根路径资源模式作为参数。所以在这个例子中,/stubs/resource.json定义的存根被加载到模拟服务器中,所以如果RestTemplate被要求访问http://example.org/,那么它将得到所声明的响应。可以指定多个存根模式,每个可以是一个目录(对于所有“.json”的递归列表)或一个固定的文件名(如上例所示)或一个蚂蚁样式模式。JSON格式是通常的WireMock格式,您可以在WireMock网站上阅读。
目前,我们支持Tomcat,Jetty和Undertow作为Spring Boot嵌入式服务器,而Wiremock本身对特定版本的Jetty(目前为9.2)具有“本机”支持。要使用本地Jetty,您需要添加本机线程依赖关系,并排除Spring Boot容器(如果有的话)。
使用RestDocs生成存根
Spring RestDocs可用于为具有Spring MockMvc或RestEasy的HTTP API生成文档(例如,asciidoctor格式)。在生成API文档的同时,还可以使用Spring Cloud Contract WireMock生成WireMock存根。只需编写正常的RestDocs测试用例,并使用@AutoConfigureRestDocs在restdocs输出目录中自动存储存根。例如:
@RunWith(SpringRunner.class)
@SpringBootTest
@AutoConfigureRestDocs(outputDir = "target/snippets")
@AutoConfigureMockMvc
public class ApplicationTests {
@Autowired
private MockMvc mockMvc;
@Test
public void contextLoads() throws Exception {
mockMvc.perform(get("/resource"))
.andExpect(content().string("Hello World"))
.andDo(document("resource"));
}
}
从此测试将在“target / snippets / stubs / resource.json”上生成一个WireMock存根。它将所有GET请求与“/ resource”路径相匹配。
没有任何其他配置,这将创建一个存根与HTTP方法的请求匹配器和除“主机”和“内容长度”之外的所有头。为了更准确地匹配请求,例如要匹配POST或PUT的正文,我们需要明确创建一个请求匹配器。这将做两件事情:1)创建一个只匹配您指定的方式的存根,2)断言测试用例中的请求也匹配相同的条件。
主要的入口点是WireMockRestDocs.verify(),可以替代document()便利方法。例如:
@RunWith(SpringRunner.class)
@SpringBootTest
@AutoConfigureRestDocs(outputDir = "target/snippets")
@AutoConfigureMockMvc
public class ApplicationTests {
@Autowired
private MockMvc mockMvc;
@Test
public void contextLoads() throws Exception {
mockMvc.perform(post("/resource")
.content("{\"id\":\"123456\",\"message\":\"Hello World\"}"))
.andExpect(status().isOk())
.andDo(verify().jsonPath("$.id")
.stub("resource"));
}
}
所以这个合同是说:任何有效的POST与“id”字段将得到与本测试相同的响应。您可以将来电链接到.jsonPath()以添加其他匹配器。如果您不熟悉JayWay文档,可以帮助您加快JSON路径的速度。
您也可以使用WireMock API来验证请求是否与创建的存根匹配,而不是使用jsonPath和contentType方法。例:
@Test
public void contextLoads() throws Exception {
mockMvc.perform(post("/resource")
.content("{\"id\":\"123456\",\"message\":\"Hello World\"}"))
.andExpect(status().isOk())
.andDo(verify()
.wiremock(WireMock.post(
urlPathEquals("/resource"))
.withRequestBody(matchingJsonPath("$.id"))
.stub("post-resource"));
}
WireMock API是丰富的 - 您可以通过正则表达式以及json路径来匹配头文件,查询参数和请求正文,因此这可以用于创建具有更广泛参数的存根。上面的例子会生成一个这样的stub:
后resource.json
{
"request" : {
"url" : "/resource",
"method" : "POST",
"bodyPatterns" : [ {
"matchesJsonPath" : "$.id"
}]
},
"response" : {
"status" : 200,
"body" : "Hello World",
"headers" : {
"X-Application-Context" : "application:-1",
"Content-Type" : "text/plain"
}
}
}
注意
您可以使用wiremock()方法或jsonPath()和contentType()方法创建请求匹配器,但不能同时使用两者。
在消费方面,假设上面生成的resource.json可以在类路径中使用,您可以使用WireMock以多种不同的方式创建一个存根,其中包括上述使用@AutoConfigureWireMock(stubs="classpath:resource.json")的描述。
使用RestDocs生成Contracts
可以使用Spring RestDocs生成的另一件事是Spring Cloud Contract DSL文件和文档。如果您将其与Spring Cloud WireMock相结合,那么您将获得合同和存根。
小费
您可能会想知道为什么该功能在WireMock模块中。来想一想,它确实有道理,因为只生成合同并且不生成存根就没有意义。这就是为什么我们建议做这两个。
我们来想象下面的测试:
this.mockMvc.perform(post("/foo")
.accept(MediaType.APPLICATION_PDF)
.accept(MediaType.APPLICATION_JSON)
.contentType(MediaType.APPLICATION_JSON)
.content("{\"foo\": 23 }"))
.andExpect(status().isOk())
.andExpect(content().string("bar"))
// first WireMock
.andDo(WireMockRestDocs.verify()
.jsonPath("$[?(@.foo >= 20)]")
.contentType(MediaType.valueOf("application/json"))
.stub("shouldGrantABeerIfOldEnough"))
// then Contract DSL documentation
.andDo(document("index", SpringCloudContractRestDocs.dslContract()));
这将导致在上一节中介绍的存根的创建,合同将被生成和文档文件。
合同将被称为index.groovy,看起来更像是这样。
import org.springframework.cloud.contract.spec.Contract
Contract.make {
request {
method 'POST'
url 'http://localhost:8080/foo'
body('''
{"foo": 23 }
''')
headers {
header('''Accept''', '''application/json''')
header('''Content-Type''', '''application/json''')
header('''Host''', '''localhost:8080''')
header('''Content-Length''', '''12''')
}
}
response {
status 200
body('''
bar
''')
headers {
header('''Content-Type''', '''application/json;charset=UTF-8''')
header('''Content-Length''', '''3''')
}
testMatchers {
jsonPath('$[?(@.foo >= 20)]', byType())
}
}
}
生成的文档(Asciidoc的示例)将包含格式化的合同(此文件的位置将为index/dsl-contract.adoc)。
Spring Cloud Contract验证者
介绍
重要
1.1.0版中已弃用的Accurest项目的文档可在此处获取。
小费
Accurest项目最初是由Marcin Grzejszczak和Jakub Kubrynski(codearte.io)
只是为了简短说明 - Spring Cloud Contract验证程序是一种能够启用消费者驱动合同(CDC)开发基于JVM的应用程序的工具。它与合同定义语言(DSL)一起提供。合同定义用于生成以下资源:
在客户端代码(客户端测试)上进行集成测试时,WireMock将使用JSON存根定义。测试代码仍然需要手动编写,测试数据由Spring Cloud Contract验证器生成。
消息传递路由,如果你使用一个。我们正在与Spring Integration,Spring Cloud Stream,Spring AMQP和Apache Camel进行整合。然而,您可以设置自己的集成,如果你想
验收测试(在JUnit或Spock中)用于验证API的服务器端实现是否符合合同(服务器测试)。完全测试由Spring Cloud Contract验证器生成。
Spring Cloud Contract验证者将TDD移动到软件体系结构的层次。
Spring Cloud Contract视频
您可以查看华沙JUG关于Spring Cloud Contract的视频:点击此处查看视频
为什么?
让我们假设我们有一个由多个微服务组成的系统:
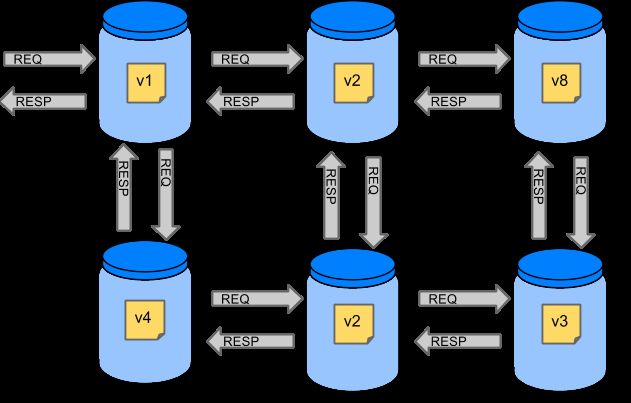
测试问题
如果我们想测试应用程序在左上角,如果它可以与其他服务通信,那么我们可以做两件事之一:
部署所有微服务器并执行端到端测试
模拟其他微型服务单元/集成测试
两者都有其优点,但也有很多缺点。我们来关注后者。
部署所有微服务器并执行端到端测试
优点:
模拟生产
测试服务之间的真实沟通
缺点:
要测试一个微服务器,我们将不得不部署6个微服务器,几个数据库等。
将进行测试的环境将被锁定用于一套测试(即没有人能够在此期间运行测试)。
长跑
非常迟的反馈
非常难调试
模拟其他微型服务单元/集成测试
优点:
非常快的反馈
没有基础架构要求
缺点:
服务的实现者创建存根,因此它们可能与现实无关
您可以通过测试和生产不合格进行生产
为了解决上述问题,Spring Cloud Contract Stub Runner的验证器被创建。他们的主要思想是给你非常快的反馈,而不需要建立整个微服务的世界。

如果您在存根上工作,那么您需要的唯一应用是应用程序直接使用的应用程序。
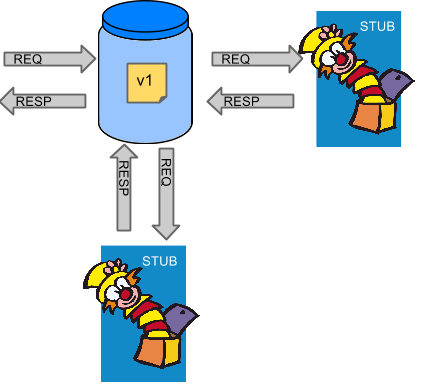
Spring Cloud Contract验证者确定您使用的存根是由您正在调用的服务创建的。此外,如果您可以使用它们,这意味着它们是针对生产者的一方进行测试的。换句话说 - 你可以信任这些存根。
目的
Spring Cloud Contract验证器与Stub Runner的主要目的是:
确保WireMock / Messaging存根(在开发客户端时使用)正在完全实际执行服务器端实现,
推广ATDD方法和微服务架构风格,
提供一种发布双方立即可见的合同变更的方法,
生成服务器端使用的样板测试代码。
重要
Spring Cloud Contract验证者的目的不是开始在合同中编写业务功能。我们假设我们有一个欺诈检查的商业用例。如果一个用户因为100个不同的原因而被欺骗,我们假设你会创建2个合同。一个为正面,一个为负面欺诈案。合同测试用于测试应用程序之间的合同,而不是模拟完整行为。
客户端
在测试期间,您希望启动并运行一个模拟服务Y的WireMock实例/消息传递路由。您希望为该实例提供适当的存根定义。该存根定义将需要有效,并且也应在服务器端可重用。
总结:在这方面,在存根定义中,您可以使用模式进行请求存根,并需要确切的响应值。
服务器端
作为开发您的存根的服务Y,您需要确保它实际上类似于您的具体实现。您不能以某种方式存在您的存根行为,并且您的生产应用程序以不同的方式运行。
这就是为什么会生成提供的存根验收测试,这将确保您的应用程序的行为与您在存根中定义的相同。
总结:在这方面,在存根定义中,您需要精确的值作为请求,并可以使用模式/方法进行响应验证。
逐步向CDC指导
举一个欺诈检测和贷款发行流程的例子。业务情景是这样的,我们想向人们发放贷款,但不希望他们从我们那里偷钱。目前我们的系统实施给大家贷款。
假设Loan Issuance是Fraud Detection服务器的客户端。在目前的冲刺中,我们需要开发一个新的功能 - 如果客户想要借到太多的钱,那么我们将他们标记为欺诈。
技术说明 - 欺诈检测将具有工件IDhttp-server,贷款发行http-client,两者都具有组IDcom.example。
社会声明 - 客户端和服务器开发团队都需要直接沟通,并在整个过程中讨论变更。CDC是关于沟通的。
在服务器端代码可以在这里和这里的客户端代码。
小费
在这种情况下,合同的所有权在生产者方面。这意味着物理上所有的合同都存在于生产者存储库中
技术说明
如果使用SNAPSHOT/里程碑/版本候选版本,请将以下部分添加到您的
Maven的
spring-snapshots
Spring Snapshots
https://repo.spring.io/snapshot
true
spring-milestones
Spring Milestones
https://repo.spring.io/milestone
false
spring-releases
Spring Releases
https://repo.spring.io/release
false
spring-snapshots
Spring Snapshots
https://repo.spring.io/snapshot
true
spring-milestones
Spring Milestones
https://repo.spring.io/milestone
false
spring-releases
Spring Releases
https://repo.spring.io/release
false
摇篮
repositories {
mavenCentral()
mavenLocal()
maven { url "http://repo.spring.io/snapshot" }
maven { url "http://repo.spring.io/milestone" }
maven { url "http://repo.spring.io/release" }
}
消费方(贷款发行)
作为贷款发行服务(欺诈检测服务器的消费者)的开发人员:
通过对您的功能进行测试开始做TDD
@Test
public void shouldBeRejectedDueToAbnormalLoanAmount() {
// given:
LoanApplication application = new LoanApplication(new Client("1234567890"),
99999);
// when:
LoanApplicationResult loanApplication = service.loanApplication(application);
// then:
assertThat(loanApplication.getLoanApplicationStatus())
.isEqualTo(LoanApplicationStatus.LOAN_APPLICATION_REJECTED);
assertThat(loanApplication.getRejectionReason()).isEqualTo("Amount too high");
}
我们刚刚写了一个关于我们新功能的测试。如果收到大额的贷款申请,我们应该拒绝有一些描述的贷款申请。
写入缺少的实现
在某些时间点,您需要向欺诈检测服务发送请求。我们假设我们要发送包含客户端ID和要从我们借款的金额的请求。我们想通过PUT方法将其发送到/fraudcheck网址。
ResponseEntity response =
restTemplate.exchange("http://localhost:" + port + "/fraudcheck", HttpMethod.PUT,
new HttpEntity<>(request, httpHeaders),
FraudServiceResponse.class);
为了简单起见,我们已将8080的欺诈检测服务端口硬编码,我们的应用程序正在8090上运行。
如果我们开始写测试,显然会因为端口8080上没有运行而打断。
在本地克隆欺诈检测服务存储库
我们将开始玩服务器端的合同。这就是为什么我们需要先克隆它。
git clone https://your-git-server.com/server-side.git local-http-server-repo
在欺诈检测服务的回购中本地定义合同
作为消费者,我们需要确定我们想要实现的目标。我们需要制定我们的期望。这就是为什么我们写下面的合同。
重要
我们将合同放在src/test/resources/contract/fraud下。fraud文件夹是重要的,因为我们将在生产者的测试基类中引用该文件夹。
package contracts
org.springframework.cloud.contract.spec.Contract.make {
request { // (1)
method 'PUT' // (2)
url '/fraudcheck' // (3)
body([ // (4)
clientId: $(regex('[0-9]{10}')),
loanAmount: 99999
])
headers { // (5)
contentType('application/vnd.fraud.v1+json')
}
}
response { // (6)
status 200 // (7)
body([ // (8)
fraudCheckStatus: "FRAUD",
rejectionReason: "Amount too high"
])
headers { // (9)
contentType('application/vnd.fraud.v1+json')
}
}
}
/*
Since we don't want to force on the user to hardcode values of fields that are dynamic
(timestamps, database ids etc.), one can parametrize those entries. If you wrap your field's
value in a `$(...)` or `value(...)` and provide a dynamic value of a field then
the concrete value will be generated for you. If you want to be really explicit about
which side gets which value you can do that by using the `value(consumer(...), producer(...))` notation.
That way what's present in the `consumer` section will end up in the produced stub. What's
there in the `producer` will end up in the autogenerated test. If you provide only the
regular expression side without the concrete value then Spring Cloud Contract will generate one for you.
From the Consumer perspective, when shooting a request in the integration test:
(1) - If the consumer sends a request
(2) - With the "PUT" method
(3) - to the URL "/fraudcheck"
(4) - with the JSON body that
* has a field `clientId` that matches a regular expression `[0-9]{10}`
* has a field `loanAmount` that is equal to `99999`
(5) - with header `Content-Type` equal to `application/vnd.fraud.v1+json`
(6) - then the response will be sent with
(7) - status equal `200`
(8) - and JSON body equal to
{ "fraudCheckStatus": "FRAUD", "rejectionReason": "Amount too high" }
(9) - with header `Content-Type` equal to `application/vnd.fraud.v1+json`
From the Producer perspective, in the autogenerated producer-side test:
(1) - A request will be sent to the producer
(2) - With the "PUT" method
(3) - to the URL "/fraudcheck"
(4) - with the JSON body that
* has a field `clientId` that will have a generated value that matches a regular expression `[0-9]{10}`
* has a field `loanAmount` that is equal to `99999`
(5) - with header `Content-Type` equal to `application/vnd.fraud.v1+json`
(6) - then the test will assert if the response has been sent with
(7) - status equal `200`
(8) - and JSON body equal to
{ "fraudCheckStatus": "FRAUD", "rejectionReason": "Amount too high" }
(9) - with header `Content-Type` matching `application/vnd.fraud.v1+json.*`
*/
合同使用静态类型的Groovy DSL编写。你可能想知道这些value(client(…), server(…))部分是什么。通过使用这种符号Spring Cloud Contract,您可以定义动态的JSON / URL /等的部分。在标识符或时间戳的情况下,您不想硬编码一个值。你想允许一些不同的值范围。这就是为什么对于消费者端,您可以设置与这些值匹配的正则表达式。您可以通过地图符号或带插值的String来提供身体。有关更多信息,请参阅文档。我们强烈推荐使用地图符号!
小费
了解地图符号设置合同非常重要。请阅读有关JSON的Groovy文档
上述合同是双方达成的协议:
如果发送了HTTP请求
端点/fraudcheck上的方法PUT
与clientPesel的正则表达式[0-9]{10}和loanAmount等于99999的JSON体
并且标题Content-Type等于application/vnd.fraud.v1+json
那么HTTP响应将被发送给消费者
状态为200
包含JSON体,其中包含值为FRAUD的fraudCheckStatus字段和值为Amount too high的rejectionReason字段
和一个值为application/vnd.fraud.v1+json的Content-Type标头
一旦我们准备好在集成测试中实际检查API,我们需要在本地安装存根
添加Spring Cloud Contract验证程序插件
我们可以添加Maven或Gradle插件 - 在这个例子中,我们将展示如何添加Maven。首先我们需要添加Spring Cloud ContractBOM。
org.springframework.cloud
spring-cloud-dependencies
${spring-cloud-dependencies.version}
pom
import
接下来,Spring Cloud Contract VerifierMaven插件
org.springframework.cloud
spring-cloud-contract-maven-plugin
${spring-cloud-contract.version}
true
com.example.fraud
自添加插件后,我们将从提供的合同中获得Spring Cloud Contract Verifier功能:
生成并运行测试
生产并安装存根
我们不想生成测试,因为我们作为消费者,只想玩短线。这就是为什么我们需要跳过测试生成和执行。当我们执行:
cd local-http-server-repo
./mvnw clean install -DskipTests
在日志中,我们将看到如下:
[INFO] --- spring-cloud-contract-maven-plugin:1.0.0.BUILD-SNAPSHOT:generateStubs (default-generateStubs) @ http-server ---
[INFO] Building jar: /some/path/http-server/target/http-server-0.0.1-SNAPSHOT-stubs.jar
[INFO]
[INFO] --- maven-jar-plugin:2.6:jar (default-jar) @ http-server ---
[INFO] Building jar: /some/path/http-server/target/http-server-0.0.1-SNAPSHOT.jar
[INFO]
[INFO] --- spring-boot-maven-plugin:1.5.0.BUILD-SNAPSHOT:repackage (default) @ http-server ---
[INFO]
[INFO] --- maven-install-plugin:2.5.2:install (default-install) @ http-server ---
[INFO] Installing /some/path/http-server/target/http-server-0.0.1-SNAPSHOT.jar to /path/to/your/.m2/repository/com/example/http-server/0.0.1-SNAPSHOT/http-server-0.0.1-SNAPSHOT.jar
[INFO] Installing /some/path/http-server/pom.xml to /path/to/your/.m2/repository/com/example/http-server/0.0.1-SNAPSHOT/http-server-0.0.1-SNAPSHOT.pom
[INFO] Installing /some/path/http-server/target/http-server-0.0.1-SNAPSHOT-stubs.jar to /path/to/your/.m2/repository/com/example/http-server/0.0.1-SNAPSHOT/http-server-0.0.1-SNAPSHOT-stubs.jar
这条线是非常重要的
[INFO] Installing /some/path/http-server/target/http-server-0.0.1-SNAPSHOT-stubs.jar to /path/to/your/.m2/repository/com/example/http-server/0.0.1-SNAPSHOT/http-server-0.0.1-SNAPSHOT-stubs.jar
确认http-server的存根已安装在本地存储库中。
运行集成测试
为了从自动存根下载的Spring Cloud Contract Stub Runner功能中获利,您必须在我们的消费者端项目(Loan Application service)中执行以下操作。
添加Spring Cloud ContractBOM
org.springframework.cloud
spring-cloud-dependencies
${spring-cloud-dependencies.version}
pom
import
将依赖关系添加到Spring Cloud Contract Stub Runner
org.springframework.cloud
spring-cloud-starter-contract-stub-runner
test
用@AutoConfigureStubRunner标注你的测试课程。在注释中,提供Stub Runner下载协作者存根的组ID和工件ID。离线工作开关还可以离线使用协作者(可选步骤)。
@RunWith(SpringRunner.class)
@SpringBootTest(webEnvironment=WebEnvironment.NONE)
@AutoConfigureStubRunner(ids = {"com.example:http-server-dsl:+:stubs:6565"}, workOffline = true)
@DirtiesContext
public class LoanApplicationServiceTests {
现在如果你运行测试你会看到这样的:
2016-07-19 14:22:25.403 INFO 41050 --- [ main] o.s.c.c.stubrunner.AetherStubDownloader : Desired version is + - will try to resolve the latest version
2016-07-19 14:22:25.438 INFO 41050 --- [ main] o.s.c.c.stubrunner.AetherStubDownloader : Resolved version is 0.0.1-SNAPSHOT
2016-07-19 14:22:25.439 INFO 41050 --- [ main] o.s.c.c.stubrunner.AetherStubDownloader : Resolving artifact com.example:http-server:jar:stubs:0.0.1-SNAPSHOT using remote repositories []
2016-07-19 14:22:25.451 INFO 41050 --- [ main] o.s.c.c.stubrunner.AetherStubDownloader : Resolved artifact com.example:http-server:jar:stubs:0.0.1-SNAPSHOT to /path/to/your/.m2/repository/com/example/http-server/0.0.1-SNAPSHOT/http-server-0.0.1-SNAPSHOT-stubs.jar
2016-07-19 14:22:25.465 INFO 41050 --- [ main] o.s.c.c.stubrunner.AetherStubDownloader : Unpacking stub from JAR [URI: file:/path/to/your/.m2/repository/com/example/http-server/0.0.1-SNAPSHOT/http-server-0.0.1-SNAPSHOT-stubs.jar]
2016-07-19 14:22:25.475 INFO 41050 --- [ main] o.s.c.c.stubrunner.AetherStubDownloader : Unpacked file to [/var/folders/0p/xwq47sq106x1_g3dtv6qfm940000gq/T/contracts100276532569594265]
2016-07-19 14:22:27.737 INFO 41050 --- [ main] o.s.c.c.stubrunner.StubRunnerExecutor : All stubs are now running RunningStubs [namesAndPorts={com.example:http-server:0.0.1-SNAPSHOT:stubs=8080}]
这意味着Stub Runner找到了您的存根,并为具有组ID为com.example,artifact idhttp-server,版本为0.0.1-SNAPSHOT的存根和stubs分类器的端口8080。
档案公关
我们到现在为止是一个迭代的过程。我们可以玩合同,安装在本地,在消费者身边工作,直到我们对合同感到满意。
一旦我们对结果感到满意,测试通过将PR发布到服务器端。目前消费者方面的工作已经完成。
生产者方(欺诈检测服务器)
作为欺诈检测服务器(贷款发行服务的服务器)的开发人员:
初步实施
作为提醒,您可以看到初始实现
@RequestMapping(
value = "/fraudcheck",
method = PUT,
consumes = FRAUD_SERVICE_JSON_VERSION_1,
produces = FRAUD_SERVICE_JSON_VERSION_1)
public FraudCheckResult fraudCheck(@RequestBody FraudCheck fraudCheck) {
return new FraudCheckResult(FraudCheckStatus.OK, NO_REASON);
}
接管公关
git checkout -b contract-change-pr master
git pull https://your-git-server.com/server-side-fork.git contract-change-pr
您必须添加自动生成测试所需的依赖关系
org.springframework.cloud
spring-cloud-starter-contract-verifier
test
在Maven插件的配置中,我们传递了packageWithBaseClasses属性
org.springframework.cloud
spring-cloud-contract-maven-plugin
${spring-cloud-contract.version}
true
com.example.fraud
重要
我们决定使用“约定”命名,方法是设置packageWithBaseClasses属性。这意味着最后的两个包将被组合成基本测试类的名称。在我们这个例子中,这些合约是src/test/resources/contract/fraud。由于我们没有从contracts文件夹开始有2个包,我们只挑选一个是fraud。我们正在添加Base后缀,我们正在大写fraud。这给了我们FraudBase测试类名称。
这是因为所有生成的测试都会扩展该类。在那里你可以设置你的Spring上下文或任何必要的。在我们的例子中,我们使用Rest Assured MVC来启动服务器端FraudDetectionController。
package com.example.fraud;
import org.junit.Before;
import com.jayway.restassured.module.mockmvc.RestAssuredMockMvc;
public class FraudBase {
@Before
public void setup() {
RestAssuredMockMvc.standaloneSetup(new FraudDetectionController(),
new FraudStatsController(stubbedStatsProvider()));
}
private StatsProvider stubbedStatsProvider() {
return fraudType -> {
switch (fraudType) {
case DRUNKS:
return 100;
case ALL:
return 200;
}
return 0;
};
}
public void assertThatRejectionReasonIsNull(Object rejectionReason) {
assert rejectionReason == null;
}
}
现在,如果你运行./mvnw clean install,你会得到这样的sth:
Results :
Tests in error:
ContractVerifierTest.validate_shouldMarkClientAsFraud:32 » IllegalState Parsed...
这是因为您有一个新的合同,从中生成测试,并且由于您尚未实现该功能而失败。自动生成测试将如下所示:
@Test
public void validate_shouldMarkClientAsFraud() throws Exception {
// given:
MockMvcRequestSpecification request = given()
.header("Content-Type", "application/vnd.fraud.v1+json")
.body("{\"clientPesel\":\"1234567890\",\"loanAmount\":99999}");
// when:
ResponseOptions response = given().spec(request)
.put("/fraudcheck");
// then:
assertThat(response.statusCode()).isEqualTo(200);
assertThat(response.header("Content-Type")).matches("application/vnd.fraud.v1.json.*");
// and:
DocumentContext parsedJson = JsonPath.parse(response.getBody().asString());
assertThatJson(parsedJson).field("fraudCheckStatus").matches("[A-Z]{5}");
assertThatJson(parsedJson).field("rejectionReason").isEqualTo("Amount too high");
}
您可以看到value(consumer(…), producer(…))块中存在的所有producer()部分合同注入测试。
重要的是在生产者方面,我们也在做TDD。我们有一个测试形式的期望。此测试正在向我们自己的应用程序拍摄一个在合同中定义的URL,标题和主体的请求。它也期待响应中非常精确地定义的值。换句话说,您是redgreen和refactor的red部分。将red转换为green的时间。
写入缺少的实现
现在,由于我们现在预期的输入和预期的输出是什么,我们来写这个缺少的实现。
@RequestMapping(
value = "/fraudcheck",
method = PUT,
consumes = FRAUD_SERVICE_JSON_VERSION_1,
produces = FRAUD_SERVICE_JSON_VERSION_1)
public FraudCheckResult fraudCheck(@RequestBody FraudCheck fraudCheck) {
if (amountGreaterThanThreshold(fraudCheck)) {
return new FraudCheckResult(FraudCheckStatus.FRAUD, AMOUNT_TOO_HIGH);
}
return new FraudCheckResult(FraudCheckStatus.OK, NO_REASON);
}
如果再次执行./mvnw clean install,测试将通过。由于Spring Cloud Contract Verifier插件将测试添加到generated-test-sources,您可以从IDE中实际运行这些测试。
部署你的应用程序
完成工作后,现在是部署变更的时候了。首先合并分支
git checkout master
git merge --no-ff contract-change-pr
git push origin master
那么我们假设你的CI将像./mvnw clean deploy一样运行,它将发布应用程序和存根工件。
消费方(贷款发行)最后一步
作为贷款发行服务(欺诈检测服务器的消费者)的开发人员:
合并分支到主
git checkout master
git merge --no-ff contract-change-pr
在线工作
现在,您可以禁用Spring Cloud Contract Stub Runner广告的离线工作,以提供存储库与存根的位置。此时,服务器端的存根将自动从Nexus / Artifactory下载。您可以关闭注释中的workOffline参数的值。在下面你可以看到一个通过改变属性实现相同的例子。
stubrunner:
ids: 'com.example:http-server-dsl:+:stubs:8080'
repositoryRoot: http://repo.spring.io/libs-snapshot
就是这样!
依赖
添加依赖关系的最佳方法是使用正确的starter依赖关系。
对于stub-runner使用spring-cloud-starter-stub-runner,当您使用插件时,只需添加spring-cloud-starter-contract-verifier。
附加链接
以下可以找到与Spring Cloud Contract验证器和Stub Runner相关的一些资源。注意,有些可以过时,因为Spring Cloud Contract验证程序项目正在不断发展。
阅读
来自Marcin Grzejszczak关于Accurest的演讲
来自Marcin Grzejszczak的博客的Accurest相关文章
来自Marcin Grzejszczak博客的Spring Cloud Contract相关文章
Groovy关于JSON的文档
样品
在这里可以找到一些样品。
常问问题
为什么使用Spring Cloud Contract验证器而不是X?
目前Spring Cloud Contract验证器是基于JVM的工具。因此,当您已经为JVM创建软件时,可能是您的第一选择。这个项目有很多非常有趣的功能,但特别是其中一些绝对让Spring Cloud Contract Verifier在消费者驱动合同(CDC)工具的“市场”上脱颖而出。许多最有趣的是:
CDC可以通过消息传递
清晰易用,静态DSL
可以将当前的JSON文件粘贴到合同中,并且仅编辑其元素
从定义的合同自动生成测试
Stub Runner功能 - 存根在运行时自动从Nexus / Artifactory下载
Spring Cloud集成 - 集成测试不需要发现服务
这个值是(consumer(),producer())?
与存根相关的最大挑战之一是可重用性。只有如果他们能够被广泛使用,他们是否会服务于他们的目的。通常使得难点是请求/响应元素的硬编码值。例如日期或ids。想象下面的JSON请求
{
"time" : "2016-10-10 20:10:15",
"id" : "9febab1c-6f36-4a0b-88d6-3b6a6d81cd4a",
"body" : "foo"
}
和JSON响应
{
"time" : "2016-10-10 21:10:15",
"id" : "c4231e1f-3ca9-48d3-b7e7-567d55f0d051",
"body" : "bar"
}
想象一下,通过更改系统中的时钟或提供数据提供者的存根实现,设置time字段的正确值(我们假设这个内容是由数据库生成的)所需的痛苦。这同样涉及到称为id的字段。你会创建一个UUID发生器的stubbed实现?没有意义
所以作为一个消费者,你想发送一个匹配任何形式的时间或任何UUID的请求。这样,您的系统将照常工作 - 将生成数据,您不必将任何东西存入。假设在上述JSON的情况下,最重要的部分是body字段。您可以专注于其他领域,并提供匹配。换句话说,你想要的存根是这样工作的:
{
"time" : "SOMETHING THAT MATCHES TIME",
"id" : "SOMETHING THAT MATCHES UUID",
"body" : "foo"
}
就响应作为消费者而言,您需要具有可操作性的具体价值。所以这样的JSON是有效的
{
"time" : "2016-10-10 21:10:15",
"id" : "c4231e1f-3ca9-48d3-b7e7-567d55f0d051",
"body" : "bar"
}
从前面的部分可以看出,我们从合同中产生测试。所以从生产者的角度看,情况看起来差别很大。我们正在解析提供的合同,在测试中我们想向您的端点发送一个真正的请求。因此,对于请求的生产者来说,我们不能进行任何匹配。我们需要具体的价值观,使制片人的后台能够工作。这样的JSON将是一个有效的:
{
"time" : "2016-10-10 20:10:15",
"id" : "9febab1c-6f36-4a0b-88d6-3b6a6d81cd4a",
"body" : "foo"
}
另一方面,从合同的有效性的角度来看,响应不一定必须包含time或id的具体值。假设您在生产者方面产生这些 - 再次,您必须做很多桩,以确保始终返回相同的值。这就是为什么从生产者那边你可能想要的是以下回应:
{
"time" : "SOMETHING THAT MATCHES TIME",
"id" : "SOMETHING THAT MATCHES UUID",
"body" : "bar"
}
那么您如何才能为消费者提供一次匹配,并为生产者提供具体的价值,反之亦然?在Spring Cloud Contract中,我们允许您提供动态值。这意味着通信双方可能有所不同。你可以传递值:
可以通过value方法
value(consumer(...), producer(...))
value(stub(...), test(...))
value(client(...), server(...))
或使用$()方法
$(consumer(...), producer(...))
$(stub(...), test(...))
$(client(...), server(...))
您可以在Contract DSL部分阅读更多信息。
调用value()或$()告诉Spring Cloud Contract您将传递一个动态值。在consumer()方法中,传递消费者端(在生成的存根)中应该使用的值。在producer()方法中,传递应在生产者端使用的值(在生成的测试中)。
小费
如果一方面你已经通过了正则表达式,而你没有通过另一方,那么对方就会自动生成。
大多数情况下,您将使用该方法与regex辅助方法。例如consumer(regex('[0-9]{10}'))。
总而言之,上述情景的合同看起来或多或少是这样的(正则表达式的时间和UUID被简化,很可能是无效的,但是我们希望在这个例子中保持很简单):
org.springframework.cloud.contract.spec.Contract.make {
request {
method 'GET'
url '/someUrl'
body([
time : value(consumer(regex('[0-9]{4}-[0-9]{2}-[0-9]{2} [0-2][0-9]-[0-5][0-9]-[0-5][0-9]')),
id: value(consumer(regex('[0-9a-zA-z]{8}-[0-9a-zA-z]{4}-[0-9a-zA-z]{4}-[0-9a-zA-z]{12}'))
body: "foo"
])
}
response {
status 200
body([
time : value(producer(regex('[0-9]{4}-[0-9]{2}-[0-9]{2} [0-2][0-9]-[0-5][0-9]-[0-5][0-9]')),
id: value([producer(regex('[0-9a-zA-z]{8}-[0-9a-zA-z]{4}-[0-9a-zA-z]{4}-[0-9a-zA-z]{12}'))
body: "bar"
])
}
}
重要
请阅读与JSON相关的Groovy文档,以了解如何正确构建请求/响应实体。
如何做Stubs版本控制?
API版本控制
让我们尝试回答一个真正意义上的版本控制的问题。如果你指的是API版本,那么有不同的方法。
使用超媒体,链接,不要通过任何方式版本您的API
通过标题/网址传递版本
我不会试图回答一个方法更好的问题。无论适合您的需求,并允许您创造商业价值应被挑选。
假设你做你的API版本。在这种情况下,您应该提供与您支持的许多版本一样多的合同。您可以为每个版本创建一个子文件夹,或将其附加到合同名称 - 无论如何适合您。
JAR版本控制
如果通过版本控制是指包含存根的JAR的版本,那么基本上有两种主要方法。
假设您正在进行连续交付/部署,这意味着您每次通过管道生成新版本的jar时,该jar可以随时进行生产。例如你的jar版本看起来像这样(它建立在20.10.2016在20:15:21):
1.0.0.20161020-201521-RELEASE
在这种情况下,您生成的存根jar将看起来像这样。
1.0.0.20161020-201521-RELEASE-stubs.jar
在这种情况下,您应该在application.yml或@AutoConfigureStubRunner内引用存根提供最新版本的存根。您可以通过传递+号来做到这一点。例
@AutoConfigureStubRunner(ids = {"com.example:http-server-dsl:+:stubs:8080"})
如果版本控制是固定的(例如1.0.4.RELEASE或2.1.1),则必须设置jar版本的具体值。示例2.1.1。
@AutoConfigureStubRunner(ids = {"com.example:http-server-dsl:2.1.1:stubs:8080"})
开发者或生产者存根
您可以操作分类器,以针对其他服务的存根或部署到生产的存根的当前开发版本来运行测试。如果您在构建生产部署之后,使用prod-stubs分类器来更改构建部署,那么您可以在一个案例中使用dev stub运行测试,另一个则使用prod stub进行测试。
使用开发版存根的测试示例
@AutoConfigureStubRunner(ids = {"com.example:http-server-dsl:+:stubs:8080"})
使用生产版本的存根的测试示例
@AutoConfigureStubRunner(ids = {"com.example:http-server-dsl:+:prod-stubs:8080"})
您也可以通过部署管道中的属性传递这些值。
共同回购合同
存储合同以外的另一种方法是将它们保存在一个共同的地方。它可能与消费者无法克隆生产者代码的安全问题相关。另外,如果您在一个地方保留合约,那么作为生产者,您将知道有多少消费者,以及您的本地变更会消费哪些消费者。
回购结构
假设我们有一个坐标为com.example:server和3个消费者的生产者:client1,client2,client3。然后在具有常见合同的存储库中,您将具有以下设置(您可以在此处查看:
├── com
│ └── example
│ └── server
│ ├── client1
│ │ └── expectation.groovy
│ ├── client2
│ │ └── expectation.groovy
│ ├── client3
│ │ └── expectation.groovy
│ └── pom.xml
├── mvnw
├── mvnw.cmd
├── pom.xml
└── src
└── assembly
└── contracts.xml
您可以看到下面的斜线分隔的groupid/工件id文件夹(com/example/server),您对3个消费者(client1,client2和client3)有期望。期望是本文档中描述的标准Groovy DSL合同文件。该存储库必须生成一个将一对一映射到回收内容的JAR文件。
server文件夹内的pom.xml示例。
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
4.0.0
com.example
server
0.0.1-SNAPSHOT
Server Stubs
POM used to install locally stubs for consumer side
org.springframework.boot
spring-boot-starter-parent
1.5.0.BUILD-SNAPSHOT
UTF-8
1.8
1.1.0.BUILD-SNAPSHOT
Dalston.BUILD-SNAPSHOT
true
org.springframework.cloud
spring-cloud-dependencies
${spring-cloud-dependencies.version}
pom
import
org.springframework.cloud
spring-cloud-contract-maven-plugin
${spring-cloud-contract.version}
true
${project.basedir}
spring-snapshots
Spring Snapshots
https://repo.spring.io/snapshot
true
spring-milestones
Spring Milestones
https://repo.spring.io/milestone
false
spring-releases
Spring Releases
https://repo.spring.io/release
false
spring-snapshots
Spring Snapshots
https://repo.spring.io/snapshot
true
spring-milestones
Spring Milestones
https://repo.spring.io/milestone
false
spring-releases
Spring Releases
https://repo.spring.io/release
false
你可以看到除了Spring Cloud Contract Maven插件之外没有依赖关系。这些垃圾是消费者运行mvn clean install -DskipTests来本地安装生产者项目的存根的必要条件。
根文件夹中的pom.xml可以如下所示:
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
4.0.0
com.example.standalone
contracts
0.0.1-SNAPSHOT
Contracts
Contains all the Spring Cloud Contracts, well, contracts. JAR used by the producers to generate tests and stubs
UTF-8
org.apache.maven.plugins
maven-assembly-plugin
contracts
prepare-package
single
true
${basedir}/src/assembly/contracts.xml
false
它正在使用程序集插件来构建所有合同的JAR。此类设置的示例如下:
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/plugins/maven-assembly-plugin/assembly/1.1.3 http://maven.apache.org/xsd/assembly-1.1.3.xsd">
project
jar
false
${project.basedir}
/
true
**/${project.build.directory}/**
mvnw
mvnw.cmd
.mvn/**
src/**
工作流程
工作流程将与Step by step guide to CDC中提供的工作流程类似。唯一的区别是生产者不再拥有合同。所以消费者和生产者必须在共同的仓库中处理共同的合同。
消费者
当消费者希望脱机工作,而不是克隆生产者代码时,消费者团队克隆了公用存储库,转到所需的生产者的文件夹(例如com/example/server),并运行mvn clean install -DskipTests在本地安装存根从合同转换。
小费
您需要在本地安装Maven
制片人
作为一个生产者,足以改变Spring Cloud Contract验证器来提供包含合同的URL和依赖关系:
org.springframework.cloud
spring-cloud-contract-maven-plugin
http://link/to/your/nexus/or/artifactory/or/sth
com.example.standalone
contracts
使用此设置,将从http://link/to/your/nexus/or/artifactory/or/sth下载具有groupidcom.example.standalone和artifactidcontracts的JAR。然后将在本地临时文件夹中解压缩,并将com/example/server下的合同作为用于生成测试和存根的选择。由于这个惯例,生产者团队将会知道当一些不兼容的更改完成时,哪些消费者团队将被破坏。
其余的流程看起来是一样的。
我可以有多个基类进行测试吗?
是!查看Gradle或Maven插件的合同部分的不同基类。
如何调试生成的测试客户端发送的请求/响应?
生成的测试都以某种形式或时尚的方式依赖于Apache HttpClient进行RestAssured。HttpClient有一个名为wire logging的工具,它将整个请求和响应记录到HttpClient。Spring Boot有一个日志记录通用应用程序属性来做这种事情,只需将其添加到应用程序属性中即可
logging.level.org.apache.http.wire=DEBUG
可以从响应中引用请求吗?
是!使用版本1.1.0,我们添加了这样一种可能性。在HTTP存根服务器端,我们正在为WireMock提供支持。在其他HTTP服务器存根的情况下,您必须自己实现该方法。
Spring Cloud Contract验证者HTTP
毕业项目
先决条件
为了在WireMock中使用Spring Cloud Contract验证器,您必须使用Gradle或Maven插件。
警告
如果您想在项目中使用Spock,则必须单独添加spock-core和spock-spring模块。检查Spock文档以获取更多信息
添加具有依赖关系的渐变插件
buildscript {
repositories {
mavenCentral()
}
dependencies {
classpath "org.springframework.boot:spring-boot-gradle-plugin:${springboot_version}"
classpath "org.springframework.cloud:spring-cloud-contract-gradle-plugin:${verifier_version}"
}
}
apply plugin: 'groovy'
apply plugin: 'spring-cloud-contract'
dependencyManagement {
imports {
mavenBom "org.springframework.cloud:spring-cloud-contract-dependencies:${verifier_version}"
}
}
dependencies {
testCompile 'org.codehaus.groovy:groovy-all:2.4.6'
// example with adding Spock core and Spock Spring
testCompile 'org.spockframework:spock-core:1.0-groovy-2.4'
testCompile 'org.spockframework:spock-spring:1.0-groovy-2.4'
testCompile 'org.springframework.cloud:spring-cloud-starter-contract-verifier'
}
Gradle的快照版本
将其他快照存储库添加到您的build.gradle以使用快照版本,每次成功构建后都会自动上传:
buildscript {
repositories {
mavenCentral()
mavenLocal()
maven { url "http://repo.spring.io/snapshot" }
maven { url "http://repo.spring.io/milestone" }
maven { url "http://repo.spring.io/release" }
}
}
添加存根
默认情况下Spring Cloud Contract验证器正在src/test/resources/contracts目录中查找存根。
包含存根定义的目录被视为一个类名称,每个存根定义被视为单个测试。我们假设它至少包含一个用作测试类名称的目录。如果有多个级别的嵌套目录,除了最后一个级别将被用作包名称。所以具有以下结构
src/test/resources/contracts/myservice/shouldCreateUser.groovy
src/test/resources/contracts/myservice/shouldReturnUser.groovy
Spring Cloud Contract验证程序将使用两种方法创建测试类defaultBasePackage.MyService
shouldCreateUser()
shouldReturnUser()
运行插件
插件注册自己在check任务之前被调用。只要您希望它成为构建过程的一部分,您就无所事事。如果您只想生成测试,请调用generateContractTests任务。
默认设置
默认的Gradle插件设置创建了以下Gradle部分的构建(它是一个伪代码)
contracts {
targetFramework = 'JUNIT'
testMode = 'MockMvc'
generatedTestSourcesDir = project.file("${project.buildDir}/generated-test-sources/contracts")
contractsDslDir = "${project.rootDir}/src/test/resources/contracts"
basePackageForTests = 'org.springframework.cloud.verifier.tests'
stubsOutputDir = project.file("${project.buildDir}/stubs")
// the following properties are used when you want to provide where the JAR with contract lays
contractDependency {
stringNotation = ''
}
contractsPath = ''
contractsWorkOffline = false
}
tasks.create(type: Jar, name: 'verifierStubsJar', dependsOn: 'generateClientStubs') {
baseName = project.name
classifier = contracts.stubsSuffix
from contractVerifier.stubsOutputDir
}
project.artifacts {
archives task
}
tasks.create(type: Copy, name: 'copyContracts') {
from contracts.contractsDslDir
into contracts.stubsOutputDir
}
verifierStubsJar.dependsOn 'copyContracts'
publishing {
publications {
stubs(MavenPublication) {
artifactId project.name
artifact verifierStubsJar
}
}
}
配置插件
要更改默认配置,只需在您的Gradle配置中添加contracts代码段即可
contracts {
testMode = 'MockMvc'
baseClassForTests = 'org.mycompany.tests'
generatedTestSourcesDir = project.file('src/generatedContract')
}
配置选项
testMode- 定义接受测试的模式。默认的基于Spring的MockMvc的MockMvc。也可以将其更改为JaxRsClient或显式为真实的HTTP调用。
导入- 应包含在生成的测试中的导入的数组(例如['org.myorg.Matchers'])。默认为空数组[]
staticImports- 应该包含在生成的测试中的静态导入的数组(例如['org.myorg.Matchers。*'])。默认为空数组[]
basePackageForTests- 为所有生成的测试指定基础包。默认设置为org.springframework.cloud.verifier.tests
baseClassForTests- 所有生成的测试的基类。如果使用Spock测试,默认为spock.lang.Specification。
packageWithBaseClasses- 而不是为基类提供固定值,您可以提供一个所有基类放置的包。优先于baseClassForTests。
baseClassMappings- 明确地将合约包映射到基类的FQN。优先于packageWithBaseClasses和baseClassForTests。
ruleClassForTests- 指定应该添加到生成的测试类的规则。
ignoredFiles- Ant匹配器,允许定义要跳过哪些处理的存根文件。默认为空数组[]
contractsDslDir- 包含使用GroovyDSL编写的合同的目录。默认$rootDir/src/test/resources/contracts
generatedTestSourcesDir- 应该放置从Groovy DSL生成测试的测试源目录。默认$buildDir/generated-test-sources/contractVerifier
stubsOutputDir- 应该放置从Groovy DSL生成的WireMock存根的目录
targetFramework- 要使用的目标测试框架;JUnit作为默认框架,目前支持Spock和JUnit
当您希望提供合同所在JAR的位置时,将使用以下属性
contractDependency- 提供groupid:artifactid:version:classifier坐标的依赖关系。您可以使用contractDependency关闭来设置它
contractPath- 如果下载合同部分将默认为groupid/artifactid,其中groupid将被分隔。否则将扫描提供的目录下的合同
contractsWorkOffline- 为了不下载依赖关系,每次下载一次,然后离线工作(重用本地Maven repo)
所有测试的单一基类
在默认的MockMvc中使用Spring Cloud Contract验证器时,您需要为所有生成的验收测试创建一个基本规范。在这个类中,您需要指向应验证的端点。
abstract class BaseMockMvcSpec extends Specification {
def setup() {
RestAssuredMockMvc.standaloneSetup(new PairIdController())
}
void isProperCorrelationId(Integer correlationId) {
assert correlationId == 123456
}
void isEmpty(String value) {
assert value == null
}
}
在使用Explicit模式的情况下,您可以像普通集成测试一样使用基类来初始化整个测试的应用程序。在JAXRSCLIENT模式的情况下,这个基类也应该包含protected WebTarget webTarget字段,现在测试JAX-RS API的唯一选项是启动Web服务器。
不同的基础类别的合同
如果您的基类在合同之间不同,您可以告诉Spring Cloud Contract插件哪个类应该由自动生成测试扩展。你有两个选择:
遵循约定,提供packageWithBaseClasses
通过baseClassMappings提供显式映射
惯例
约定是这样的,如果你有合同,例如src/test/resources/contract/foo/bar/baz/,并将packageWithBaseClasses属性的值提供给com.example.base,那么我们将假设com.example.base下有一个BarBazBase类包。换句话说,如果它们存在并且形成具有Base后缀的类,那么我们将使用最后两个包的部分。优先于baseClassForTests。contracts关闭中的使用示例:
packageWithBaseClasses = 'com.example.base'
制图
您可以手动将合同包的正则表达式映射为匹配合同的基类的完全限定名称。我们来看看下面的例子:
baseClassForTests = "com.example.FooBase"
baseClassMappings {
baseClassMapping('.*/com/.*', 'com.example.ComBase')
baseClassMapping('.*/bar/.*':'com.example.BarBase')
}
我们假设你有合同 -src/test/resources/contract/com/-src/test/resources/contract/foo/
通过提供baseClassForTests,我们有一个后备案例,如果映射没有成功(您也可以提供packageWithBaseClasses作为备用)。这样,从src/test/resources/contract/com/合同产生的测试将扩展com.example.ComBase,而其余的测试将扩展com.example.FooBase。
调用生成的测试
为确保提供方对定义的合同进行投诉,您需要调用:
./gradlew generateContractTests test
Spring Cloud Contract消费者验证者
在消费者服务中,您需要以与提供商相同的方式配置Spring Cloud Contract验证器插件。如果您不想使用Stub Runner,则需要复制存储在src/test/resources/contracts中的合同,并使用以下命令生成WireMock json存根:
./gradlew generateClientStubs
请注意,必须为存根生成设置stubsOutputDir选项才能正常工作。
当存在时,json存根可用于消费者自动测试。
@ContextConfiguration(loader == SpringApplicationContextLoader, classes == Application)
class LoanApplicationServiceSpec extends Specification {
@ClassRule
@Shared
WireMockClassRule wireMockRule == new WireMockClassRule()
@Autowired
LoanApplicationService sut
def 'should successfully apply for loan'() {
given:
LoanApplication application =
new LoanApplication(client: new Client(clientPesel: '12345678901'), amount: 123.123)
when:
LoanApplicationResult loanApplication == sut.loanApplication(application)
then:
loanApplication.loanApplicationStatus == LoanApplicationStatus.LOAN_APPLIED
loanApplication.rejectionReason == null
}
}
在LoanApplication下面调用FraudDetection服务。此请求由使用由Spring Cloud Contract验证器生成的存根配置的WireMock服务器处理。
在您的Maven项目中使用
添加maven插件
添加Spring Cloud Contract BOM
org.springframework.cloud
spring-cloud-dependencies
${spring-cloud-dependencies.version}
pom
import
接下来,Spring Cloud Contract VerifierMaven插件
org.springframework.cloud
spring-cloud-contract-maven-plugin
${spring-cloud-contract.version}
true
com.example.fraud
您可以在Spring Cloud Contract Maven插件文档中阅读更多内容
Maven的快照版本
对于快照/里程碑版本,您必须将以下部分添加到您的pom.xml
spring-snapshots
Spring Snapshots
https://repo.spring.io/snapshot
true
spring-milestones
Spring Milestones
https://repo.spring.io/milestone
false
spring-releases
Spring Releases
https://repo.spring.io/release
false
spring-snapshots
Spring Snapshots
https://repo.spring.io/snapshot
true
spring-milestones
Spring Milestones
https://repo.spring.io/milestone
false
spring-releases
Spring Releases
https://repo.spring.io/release
false
添加存根
默认情况下Spring Cloud Contract验证器正在src/test/resources/contracts目录中查找存根。包含存根定义的目录被视为一个类名称,每个存根定义被视为单个测试。我们假设它至少包含一个用作测试类名称的目录。如果有多个级别的嵌套目录,除了最后一个级别将被用作包名称。所以具有以下结构
src/test/resources/contracts/myservice/shouldCreateUser.groovy
src/test/resources/contracts/myservice/shouldReturnUser.groovy
Spring Cloud Contract验证者将使用两种方法创建测试类defaultBasePackage.MyService-shouldCreateUser()-shouldReturnUser()
运行插件
插件目标generateTests被分配为阶段generate-test-sources。只要您希望它成为构建过程的一部分,您就无所事事。如果您只想生成测试,请调用generateTests目标。
配置插件
要更改默认配置,只需将configuration部分添加到插件定义或execution定义。
org.springframework.cloud
spring-cloud-contract-maven-plugin
convert
generateStubs
generateTests
org.springframework.cloud.verifier.twitter.place
org.springframework.cloud.verifier.twitter.place.BaseMockMvcSpec
重要配置选项
testMode- 定义接受测试的模式。默认MockMvc,它基于Spring的MockMvc。对于真正的HTTP呼叫,它也可以更改为JaxRsClient或Explicit。
basePackageForTests- 为所有生成的测试指定基础包。默认设置为org.springframework.cloud.verifier.tests。
ruleClassForTests- 指定应该添加到生成的测试类的规则。
baseClassForTests- 生成测试的基类。如果使用Spock测试,默认为spock.lang.Specification。
contractDir- 包含使用GroovyDSL编写的合同的目录。默认/src/test/resources/contracts。
testFramework- 要使用的目标测试框架;JUnit作为默认框架,目前支持Spock和JUnit
packageWithBaseClasses- 而不是为基类提供固定值,您可以提供一个所有基类放置的包。约定是这样的,如果你有合同src/test/resources/contract/foo/bar/baz/,并提供这个属性的值到com.example.base,那么我们将假设com.example.base包含com.example.base类。优先于baseClassForTests
baseClassMappings- 您必须提供contractPackageRegex的基类映射列表,该列表根据合同所在的包进行检查,并且baseClassFQN映射到匹配合同的基类的完全限定名称。如果您有合同src/test/resources/contract/foo/bar/baz/并映射了属性.*→com.example.base.BaseClass,则从这些合同生成的测试类将扩展com.example.base.BaseClass。优先于packageWithBaseClasses和baseClassForTests。
如果要从Maven存储库中下载合同定义,可以使用
contractsRepositoryUrl- 具有合同的工件的repo的URL(如果没有提供)应使用当前的Maven
contractDependency- 包含所有打包合同的合同依赖关系
contractPath- 通过打包合同在JAR中具体合同的路径。默认为groupid/artifactid,其中gropuid被斜杠分隔。
contractWorkOffline- 如果依赖关系应该被下载,或者本地Maven只能被重用
有关完整信息,请参阅插件文档
所有测试的单一基类
在默认的MockMvc中使用Spring Cloud Contract验证器时,您需要为所有生成的验收测试创建一个基本规范。在这个类中,您需要指向应验证的端点。
package org.mycompany.tests
import org.mycompany.ExampleSpringController
import com.jayway.restassured.module.mockmvc.RestAssuredMockMvc
import spock.lang.Specification
class MvcSpec extends Specification {
def setup() {
RestAssuredMockMvc.standaloneSetup(new ExampleSpringController())
}
}
在使用Explicit模式的情况下,您可以像常规集成测试一样使用基类来初始化整个测试的应用程序。在JAXRSCLIENT模式的情况下,这个基类也应该包含protected WebTarget webTarget字段,现在测试JAX-RS API的唯一选项是启动Web服务器。
不同的基础类别的合同
如果您的基类在合同之间不同,您可以告诉Spring Cloud Contract插件哪个类应该由自动生成测试扩展。你有两个选择:
遵循约定,提供packageWithBaseClasses
通过baseClassMappings提供显式映射
惯例
约定是这样的,如果你有合同,例如src/test/resources/contract/hello/v1/,并将packageWithBaseClasses属性的值提供给hello,那么我们将假设在hello下有一个HelloV1Base类包。换句话说,如果它们存在并且形成具有Base后缀的类,那么我们将使用最后两个包的部分。优先于baseClassForTests。使用示例:
org.springframework.cloud
spring-cloud-contract-maven-plugin
hello
制图
您可以手动将合同包的正则表达式映射为匹配合同的基类的完全限定名称。您必须提供baseClassMappingsbaseClassMapping的contractPackageRegex列表contractPackageRegex到baseClassFQN映射。我们来看看下面的例子:
org.springframework.cloud
spring-cloud-contract-maven-plugin
com.example.FooBase
.*com.*
com.example.TestBase
我们假设你有合同 -src/test/resources/contract/com/-src/test/resources/contract/foo/
通过提供baseClassForTests,我们有一个后备程序,如果映射没有成功(你也可以提供packageWithBaseClasses作为备用)。这样,从src/test/resources/contract/com/合同生成的测试将扩展com.example.ComBase,而其余的测试将扩展com.example.FooBase。
调用生成的测试
Spring Cloud Contract Maven插件将验证码生成到目录/generated-test-sources/contractVerifier中,并将此目录附加到testCompile目标。
对于Groovy Spock代码使用:
org.codehaus.gmavenplus
gmavenplus-plugin
1.5
testCompile
${project.basedir}/src/test/groovy
**/*.groovy
${project.build.directory}/generated-test-sources/contractVerifier
**/*.groovy
为了确保提供方对定义的合同进行投诉,您需要调用mvn generateTest test
Maven插件常见问题
Maven插件和STS
如果在使用STS时看到以下异常

当您点击标记时,您应该看到这样的sth
plugin:1.1.0.M1:convert:default-convert:process-test-resources) org.apache.maven.plugin.PluginExecutionException: Execution default-convert of goal org.springframework.cloud:spring-
cloud-contract-maven-plugin:1.1.0.M1:convert failed. at org.apache.maven.plugin.DefaultBuildPluginManager.executeMojo(DefaultBuildPluginManager.java:145) at
org.eclipse.m2e.core.internal.embedder.MavenImpl.execute(MavenImpl.java:331) at org.eclipse.m2e.core.internal.embedder.MavenImpl$11.call(MavenImpl.java:1362) at
...
org.eclipse.core.internal.jobs.Worker.run(Worker.java:55) Caused by: java.lang.NullPointerException at
org.eclipse.m2e.core.internal.builder.plexusbuildapi.EclipseIncrementalBuildContext.hasDelta(EclipseIncrementalBuildContext.java:53) at
org.sonatype.plexus.build.incremental.ThreadBuildContext.hasDelta(ThreadBuildContext.java:59) at
为了解决这个问题,请在pom.xml中提供以下部分
only. It has no influence on the Maven build itself. -->
org.eclipse.m2e
lifecycle-mapping
1.0.0
org.springframework.cloud
spring-cloud-contract-maven-plugin
[1.0,)
convert
Spring Cloud Contract消费者验证者
您实际上也可以为消费者使用Spring Cloud Contract验证器!您可以使用插件,以便只转换合同并生成存根。要实现这一点,您需要以与提供程序相同的方式配置Spring Cloud Contract验证程序插件。您需要复制存储在src/test/resources/contracts中的合同,并使用以下命令生成WireMock json存根:mvn generateStubs命令。默认生成的WireMock映射存储在目录target/mappings中。您的项目应该从此生成的映射创建附加工件与分类器stubs,以便轻松部署到maven存储库。
样品配置:
org.springframework.cloud
spring-cloud-contract-maven-plugin
${verifier-plugin.version}
convert
generateStubs
当存在时,json存根可用于消费者自动测试。
@RunWith(SpringTestRunner.class)
@SpringBootTest
@AutoConfigureStubRunner
public class LoanApplicationServiceTests {
@Autowired
LoanApplicationService service;
@Test
public void shouldSuccessfullyApplyForLoan() {
//given:
LoanApplication application =
new LoanApplication(new Client("12345678901"), 123.123);
//when:
LoanApplicationResult loanApplication = service.loanApplication(application);
// then:
assertThat(loanApplication.loanApplicationStatus).isEqualTo(LoanApplicationStatus.LOAN_APPLIED);
assertThat(loanApplication.rejectionReason).isNull();
}
}
LoanApplication下方致电FraudDetection服务。此请求由使用Spring Cloud Contract验证器生成的存根配置的WireMock服务器进行处理。
方案
可以使用Spring Cloud Contract验证程序处理场景。所有您需要做的是在创建合同时坚持正确的命名约定。公约要求包括后面是下划线的订单号。
my_contracts_dir\
scenario1\
1_login.groovy
2_showCart.groovy
3_logout.groovy
这样的树将导致Spring Cloud Contract验证器生成名为scenario1的WireMock场景和三个步骤:
登录标记为Started,指向:
showCart标记为Step1指向:
注销标记为Step2,这将关闭场景。
有关WireMock场景的更多详细信息,请参见http://wiremock.org/stateful-behaviour.html
Spring Cloud Contract验证者还将生成具有保证执行顺序的测试。
存根和传递依赖
我们创建的Maven和Gradle插件是为您添加创建存根jar的任务。可能有问题的是,当重用存根时,您可以错误地导入所有这些存根依赖关系!即使你有几个不同的罐子,建造一个Maven的工件,他们都有一个pom:
├── github-webhook-0.0.1.BUILD-20160903.075506-1-stubs.jar
├── github-webhook-0.0.1.BUILD-20160903.075506-1-stubs.jar.sha1
├── github-webhook-0.0.1.BUILD-20160903.075655-2-stubs.jar
├── github-webhook-0.0.1.BUILD-20160903.075655-2-stubs.jar.sha1
├── github-webhook-0.0.1.BUILD-SNAPSHOT.jar
├── github-webhook-0.0.1.BUILD-SNAPSHOT.pom
├── github-webhook-0.0.1.BUILD-SNAPSHOT-stubs.jar
├── ...
└── ...
使用这些依赖关系有三种可能性,以便不会对传递依赖性产生任何问题。
将所有应用程序依赖项标记为可选
如果在github-webhook应用程序中,我们将所有的依赖项标记为可选的,当您将github-webhook存根包含在另一个应用程序中(或者当依赖关系由Stub Runner下载)时,因为所有的依赖关系是可选的,它们不会被下载。
为存根创建一个单独的artifactid
如果你创建一个单独的artifactid,那么你可以设置任何你想要的方式。例如通过没有依赖关系。
排除消费者方面的依赖关系
作为消费者,如果将stub依赖关系添加到类路径中,则可以显式排除不需要的依赖关系。
Spring Cloud Contract验证器消息
Spring Cloud Contract验证器允许您验证使用消息传递作为通信方式的应用程序。我们所有的集成都使用Spring,但您也可以自己创建并使用它。
集成
您可以使用四种集成配置之一:
Apache Camel
Spring Integration
Spring Cloud Stream
Spring AMQP
由于我们使用Spring Boot,因此如果您已经将上述的一个库添加到类路径中,那么将自动设置所有的消息传递配置。
重要
记住将@AutoConfigureMessageVerifier放在生成的测试的基类上。否则Spring Cloud Contract验证器的消息传递部分将无法正常工作。
手动集成测试
测试使用的主界面是org.springframework.cloud.contract.verifier.messaging.MessageVerifier。它定义了如何发送和接收消息。您可以创建自己的实现来实现相同的目标。
在测试中,您可以注册ContractVerifierMessageExchange发送和接收遵循合同的消息。然后将@AutoConfigureMessageVerifier添加到您的测试中,例如
@RunWith(SpringTestRunner.class)
@SpringBootTest
@AutoConfigureMessageVerifier
public static class MessagingContractTests {
@Autowired
private MessageVerifier verifier;
...
}
注意
如果您的测试也需要存根,则@AutoConfigureStubRunner包括消息传递配置,因此您只需要一个注释。
发行人端测试一代
在您的DSL中拥有input或outputMessage部分将导致在发布商方面创建测试。默认情况下,将创建JUnit测试,但是也可以创建Spock测试。
我们应该考虑三个主要场景:
情况1:没有输入消息产生输出消息。输出消息由应用程序内部的组件触发(例如调度程序)
情况2:输入消息触发输出消息
方案3:输入消息被消耗,没有输出消息
情景1(无输入讯息)
对于给定的合同:
def contractDsl = Contract.make {
label 'some_label'
input {
triggeredBy('bookReturnedTriggered()')
}
outputMessage {
sentTo('activemq:output')
body('''{ "bookName" : "foo" }''')
headers {
header('BOOK-NAME', 'foo')
}
}
}
将创建以下JUnit测试:
'''
// when:
bookReturnedTriggered();
// then:
ContractVerifierMessage response = contractVerifierMessaging.receive("activemq:output");
assertThat(response).isNotNull();
assertThat(response.getHeader("BOOK-NAME")).isEqualTo("foo");
// and:
DocumentContext parsedJson = JsonPath.parse(contractVerifierObjectMapper.writeValueAsString(response.getPayload()));
assertThatJson(parsedJson).field("bookName").isEqualTo("foo");
'''
并且将创建以下Spock测试:
'''
when:
bookReturnedTriggered()
then:
ContractVerifierMessage response = contractVerifierMessaging.receive('activemq:output')
assert response != null
response.getHeader('BOOK-NAME') == 'foo'
and:
DocumentContext parsedJson = JsonPath.parse(contractVerifierObjectMapper.writeValueAsString(response.payload))
assertThatJson(parsedJson).field("bookName").isEqualTo("foo")
'''
情景2(输入触发输出)
对于给定的合同:
def contractDsl = Contract.make {
label 'some_label'
input {
messageFrom('jms:input')
messageBody([
bookName: 'foo'
])
messageHeaders {
header('sample', 'header')
}
}
outputMessage {
sentTo('jms:output')
body([
bookName: 'foo'
])
headers {
header('BOOK-NAME', 'foo')
}
}
}
将创建以下JUnit测试:
'''
// given:
ContractVerifierMessage inputMessage = contractVerifierMessaging.create(
"{\\"bookName\\":\\"foo\\"}"
, headers()
.header("sample", "header"));
// when:
contractVerifierMessaging.send(inputMessage, "jms:input");
// then:
ContractVerifierMessage response = contractVerifierMessaging.receive("jms:output");
assertThat(response).isNotNull();
assertThat(response.getHeader("BOOK-NAME")).isEqualTo("foo");
// and:
DocumentContext parsedJson = JsonPath.parse(contractVerifierObjectMapper.writeValueAsString(response.getPayload()));
assertThatJson(parsedJson).field("bookName").isEqualTo("foo");
'''
并且将创建以下Spock测试:
"""\
given:
ContractVerifierMessage inputMessage = contractVerifierMessaging.create(
'''{"bookName":"foo"}''',
['sample': 'header']
)
when:
contractVerifierMessaging.send(inputMessage, 'jms:input')
then:
ContractVerifierMessage response = contractVerifierMessaging.receive('jms:output')
assert response !- null
response.getHeader('BOOK-NAME') == 'foo'
and:
DocumentContext parsedJson = JsonPath.parse(contractVerifierObjectMapper.writeValueAsString(response.payload))
assertThatJson(parsedJson).field("bookName").isEqualTo("foo")
"""
情景3(无输出讯息)
对于给定的合同:
def contractDsl = Contract.make {
label 'some_label'
input {
messageFrom('jms:delete')
messageBody([
bookName: 'foo'
])
messageHeaders {
header('sample', 'header')
}
assertThat('bookWasDeleted()')
}
}
将创建以下JUnit测试:
'''
// given:
ContractVerifierMessage inputMessage = contractVerifierMessaging.create(
"{\\"bookName\\":\\"foo\\"}"
, headers()
.header("sample", "header"));
// when:
contractVerifierMessaging.send(inputMessage, "jms:delete");
// then:
bookWasDeleted();
'''
并且将创建以下Spock测试:
'''
given:
ContractVerifierMessage inputMessage = contractVerifierMessaging.create(
\'\'\'{"bookName":"foo"}\'\'\',
['sample': 'header']
)
when:
contractVerifierMessaging.send(inputMessage, 'jms:delete')
then:
noExceptionThrown()
bookWasDeleted()
'''
消费者存根侧代
与HTTP部分不同 - 在消息传递中,我们需要使用存根发布JAR中的Groovy DSL。然后在消费者端进行解析,创建适当的stubbed路由。
有关更多信息,请参阅Stub Runner消息部分。
Maven的
org.springframework.cloud
spring-cloud-starter-stream-rabbit
org.springframework.cloud
spring-cloud-starter-contract-stub-runner
test
org.springframework.cloud
spring-cloud-stream-test-support
test
org.springframework.cloud
spring-cloud-dependencies
Dalston.BUILD-SNAPSHOT
pom
import
摇篮
ext {
contractsDir = file("mappings")
stubsOutputDirRoot = file("${project.buildDir}/production/${project.name}-stubs/")
}
// Automatically added by plugin:
// copyContracts - copies contracts to the output folder from which JAR will be created
// verifierStubsJar - JAR with a provided stub suffix
// the presented publication is also added by the plugin but you can modify it as you wish
publishing {
publications {
stubs(MavenPublication) {
artifactId "${project.name}-stubs"
artifact verifierStubsJar
}
}
}
Spring Cloud Contract Stub Runner
使用Spring Cloud Contract验证程序时可能遇到的一个问题是将生成的WireMock JSON存根从服务器端传递到客户端(或各种客户端)。在消息传递的客户端生成方面也是如此。
复制JSON文件/手动设置客户端进行消息传递是不成问题的。
这就是为什么我们会介绍可以为您自动下载和运行存根的Spring Cloud Contract Stub Runner。
快照版本
将其他快照存储库添加到您的build.gradle以使用快照版本,每次成功构建后都会自动上传:
Maven的
spring-snapshots
Spring Snapshots
https://repo.spring.io/snapshot
true
spring-milestones
Spring Milestones
https://repo.spring.io/milestone
false
spring-releases
Spring Releases
https://repo.spring.io/release
false
spring-snapshots
Spring Snapshots
https://repo.spring.io/snapshot
true
spring-milestones
Spring Milestones
https://repo.spring.io/milestone
false
spring-releases
Spring Releases
https://repo.spring.io/release
false
摇篮
buildscript {
repositories {
mavenCentral()
mavenLocal()
maven { url "http://repo.spring.io/snapshot" }
maven { url "http://repo.spring.io/milestone" }
maven { url "http://repo.spring.io/release" }
}
将存根发布为JAR
最简单的方法是集中保留存根的方式。例如,您可以将它们作为JAR存储在Maven存储库中。
小费
对于Maven和Gradle来说,安装程序都是开箱即用的。但是如果你想要的话可以自定义它。
Maven的
true
org.apache.maven.plugins
maven-assembly-plugin
stub
prepare-package
single
false
true
$/Users/sgibb/workspace/spring/spring-cloud-samples/scripts/docs/../src/assembly/stub.xml
xmlns="http://maven.apache.org/plugins/maven-assembly-plugin/assembly/1.1.3"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/plugins/maven-assembly-plugin/assembly/1.1.3 http://maven.apache.org/xsd/assembly-1.1.3.xsd">
stubs
jar
false
src/main/java
/
**com/example/model/*.*
${project.build.directory}/classes
/
**com/example/model/*.*
${project.build.directory}/snippets/stubs
META-INF/${project.groupId}/${project.artifactId}/${project.version}/mappings
**/*
$/Users/sgibb/workspace/spring/spring-cloud-samples/scripts/docs/../src/test/resources/contracts
META-INF/${project.groupId}/${project.artifactId}/${project.version}/contracts
**/*.groovy
摇篮
ext {
contractsDir = file("mappings")
stubsOutputDirRoot = file("${project.buildDir}/production/${project.name}-stubs/")
}
// Automatically added by plugin:
// copyContracts - copies contracts to the output folder from which JAR will be created
// verifierStubsJar - JAR with a provided stub suffix
// the presented publication is also added by the plugin but you can modify it as you wish
publishing {
publications {
stubs(MavenPublication) {
artifactId "${project.name}-stubs"
artifact verifierStubsJar
}
}
}
模块
Stub Runner核心
为服务合作者运行存根。作为服务合同处理存根允许使用stub-runner作为Consumer Driven Contracts的实现。
Stub Runner允许您自动下载提供的依赖项的存根,为其启动WireMock服务器,并为其提供适当的存根定义。对于消息传递,定义了特殊的存根路由。
运行存根
限制
重要
StubRunner可能会在测试之间关闭端口时出现问题。您可能会遇到您遇到端口冲突的情况。只要您在测试中使用相同的上下文,一切正常。但是当上下文不同(例如不同的存根或不同的配置文件)时,您必须使用@DirtiesContext关闭存根服务器,否则在每个测试的不同端口上运行它们。
运行使用主应用程序
您可以将以下选项设置为主类:
-c, --classifier Suffix for the jar containing stubs (e.
g. 'stubs' if the stub jar would
have a 'stubs' classifier for stubs:
foobar-stubs ). Defaults to 'stubs'
(default: stubs)
--maxPort, --maxp Maximum port value to be assigned to
the WireMock instance. Defaults to
15000 (default: 15000)
--minPort, --minp Minimum port value to be assigned to
the WireMock instance. Defaults to
10000 (default: 10000)
-p, --password Password to user when connecting to
repository
--phost, --proxyHost Proxy host to use for repository
requests
--pport, --proxyPort [Integer] Proxy port to use for repository
requests
-r, --root Location of a Jar containing server
where you keep your stubs (e.g. http:
//nexus.
net/content/repositories/repository)
-s, --stubs Comma separated list of Ivy
representation of jars with stubs.
Eg. groupid:artifactid1,groupid2:
artifactid2:classifier
-u, --username Username to user when connecting to
repository
--wo, --workOffline Switch to work offline. Defaults to
'false'
HTTP存根
存根在JSON文档中定义,其语法在WireMock文档中定义
例:
{
"request": {
"method": "GET",
"url": "/ping"
},
"response": {
"status": 200,
"body": "pong",
"headers": {
"Content-Type": "text/plain"
}
}
}
查看注册的映射
每个stubbed协作者公开__/admin/端点下定义的映射列表。
消息存根
根据提供的Stub Runner依赖关系和DSL,消息路由将自动设置。
Stub Runner JUnit规则
Stub Runner附带一个JUnit规则,感谢您可以轻松地下载和运行给定组和工件ID的存根:
@ClassRule public static StubRunnerRule rule = new StubRunnerRule()
.repoRoot(repoRoot())
.downloadStub("org.springframework.cloud.contract.verifier.stubs", "loanIssuance")
.downloadStub("org.springframework.cloud.contract.verifier.stubs:fraudDetectionServer");
该规则执行后Stub Runner连接到您的Maven存储库,给定的依赖关系列表尝试:
下载它们
在本地缓存
将它们解压缩到临时文件夹
从提供的端口/提供的端口范围的随机端口上为每个Maven依赖关系启动WireMock服务器
为WireMock服务器提供所有具有有效WireMock定义的JSON文件
Stub Runner使用Eclipse Aether机制下载Maven依赖关系。查看他们的文档了解更多信息。
由于StubRunnerRule实现了StubFinder,它允许您找到已启动的存根:
package org.springframework.cloud.contract.stubrunner;
import java.net.URL;
import java.util.Collection;
import java.util.Map;
import org.springframework.cloud.contract.spec.Contract;
public interface StubFinder extends StubTrigger {
/**
* For the given groupId and artifactId tries to find the matching
* URL of the running stub.
*
* @param groupId - might be null. In that case a search only via artifactId takes place
* @return URL of a running stub or throws exception if not found
*/
URL findStubUrl(String groupId, String artifactId) throws StubNotFoundException;
/**
* For the given Ivy notation {@code [groupId]:artifactId:[version]:[classifier]} tries to
* find the matching URL of the running stub. You can also pass only {@code artifactId}.
*
* @param ivyNotation - Ivy representation of the Maven artifact
* @return URL of a running stub or throws exception if not found
*/
URL findStubUrl(String ivyNotation) throws StubNotFoundException;
/**
* Returns all running stubs
*/
RunningStubs findAllRunningStubs();
/**
* Returns the list of Contracts
*/
Map> getContracts();
}
Spock测试中使用示例:
@ClassRule @Shared StubRunnerRule rule = new StubRunnerRule()
.repoRoot(StubRunnerRuleSpec.getResource("/m2repo/repository").toURI().toString())
.downloadStub("org.springframework.cloud.contract.verifier.stubs", "loanIssuance")
.downloadStub("org.springframework.cloud.contract.verifier.stubs:fraudDetectionServer")
def 'should start WireMock servers'() {
expect: 'WireMocks are running'
rule.findStubUrl('org.springframework.cloud.contract.verifier.stubs', 'loanIssuance') != null
rule.findStubUrl('loanIssuance') != null
rule.findStubUrl('loanIssuance') == rule.findStubUrl('org.springframework.cloud.contract.verifier.stubs', 'loanIssuance')
rule.findStubUrl('org.springframework.cloud.contract.verifier.stubs:fraudDetectionServer') != null
and:
rule.findAllRunningStubs().isPresent('loanIssuance')
rule.findAllRunningStubs().isPresent('org.springframework.cloud.contract.verifier.stubs', 'fraudDetectionServer')
rule.findAllRunningStubs().isPresent('org.springframework.cloud.contract.verifier.stubs:fraudDetectionServer')
and: 'Stubs were registered'
"${rule.findStubUrl('loanIssuance').toString()}/name".toURL().text == 'loanIssuance'
"${rule.findStubUrl('fraudDetectionServer').toString()}/name".toURL().text == 'fraudDetectionServer'
}
JUnit测试中的使用示例:
@Test
public void should_start_wiremock_servers() throws Exception {
// expect: 'WireMocks are running'
then(rule.findStubUrl("org.springframework.cloud.contract.verifier.stubs", "loanIssuance")).isNotNull();
then(rule.findStubUrl("loanIssuance")).isNotNull();
then(rule.findStubUrl("loanIssuance")).isEqualTo(rule.findStubUrl("org.springframework.cloud.contract.verifier.stubs", "loanIssuance"));
then(rule.findStubUrl("org.springframework.cloud.contract.verifier.stubs:fraudDetectionServer")).isNotNull();
// and:
then(rule.findAllRunningStubs().isPresent("loanIssuance")).isTrue();
then(rule.findAllRunningStubs().isPresent("org.springframework.cloud.contract.verifier.stubs", "fraudDetectionServer")).isTrue();
then(rule.findAllRunningStubs().isPresent("org.springframework.cloud.contract.verifier.stubs:fraudDetectionServer")).isTrue();
// and: 'Stubs were registered'
then(httpGet(rule.findStubUrl("loanIssuance").toString() + "/name")).isEqualTo("loanIssuance");
then(httpGet(rule.findStubUrl("fraudDetectionServer").toString() + "/name")).isEqualTo("fraudDetectionServer");
}
有关如何应用Stub Runner的全局配置的更多信息,请查看JUnit和Spring的公共属性。
Maven设置
存根下载器为不同的本地存储库文件夹授予Maven设置。目前没有考虑存储库和配置文件的身份验证详细信息,因此您需要使用上述属性进行指定。
提供固定端口
您还可以在固定端口上运行您的存根。你可以通过两种不同的方法来实现。一个是在属性中传递它,另一个是通过JUnit规则的流畅API。
流畅的API
使用StubRunnerRule时,您可以添加一个存根下载,然后通过上次下载的存根的端口。
@ClassRule public static StubRunnerRule rule = new StubRunnerRule()
.repoRoot(repoRoot())
.downloadStub("org.springframework.cloud.contract.verifier.stubs", "loanIssuance")
.withPort(12345)
.downloadStub("org.springframework.cloud.contract.verifier.stubs:fraudDetectionServer:12346");
您可以看到,对于此示例,以下测试是有效的:
then(rule.findStubUrl("loanIssuance")).isEqualTo(URI.create("http://localhost:12345").toURL());
then(rule.findStubUrl("fraudDetectionServer")).isEqualTo(URI.create("http://localhost:12346").toURL());
Stub Runner与Spring
设置Stub Runner项目的Spring配置。
通过在配置文件中提供存根列表,Stub Runner自动下载并注册WireMock中所选择的存根。
如果要查找stubbed依赖关系的URL,您可以自动连接StubFinder接口并使用其方法,如下所示:
@ContextConfiguration(classes = Config, loader = SpringBootContextLoader)
@SpringBootTest(properties = [" stubrunner.cloud.enabled=false",
"stubrunner.camel.enabled=false",
'foo=${stubrunner.runningstubs.fraudDetectionServer.port}'])
@AutoConfigureStubRunner
@DirtiesContext
@ActiveProfiles("test")
class StubRunnerConfigurationSpec extends Specification {
@Autowired StubFinder stubFinder
@Autowired Environment environment
@Value('${foo}') Integer foo
@BeforeClass
@AfterClass
void setupProps() {
System.clearProperty("stubrunner.repository.root")
System.clearProperty("stubrunner.classifier")
}
def 'should start WireMock servers'() {
expect: 'WireMocks are running'
stubFinder.findStubUrl('org.springframework.cloud.contract.verifier.stubs', 'loanIssuance') != null
stubFinder.findStubUrl('loanIssuance') != null
stubFinder.findStubUrl('loanIssuance') == stubFinder.findStubUrl('org.springframework.cloud.contract.verifier.stubs', 'loanIssuance')
stubFinder.findStubUrl('loanIssuance') == stubFinder.findStubUrl('org.springframework.cloud.contract.verifier.stubs:loanIssuance')
stubFinder.findStubUrl('org.springframework.cloud.contract.verifier.stubs:loanIssuance:0.0.1-SNAPSHOT') == stubFinder.findStubUrl('org.springframework.cloud.contract.verifier.stubs:loanIssuance:0.0.1-SNAPSHOT:stubs')
stubFinder.findStubUrl('org.springframework.cloud.contract.verifier.stubs:fraudDetectionServer') != null
and:
stubFinder.findAllRunningStubs().isPresent('loanIssuance')
stubFinder.findAllRunningStubs().isPresent('org.springframework.cloud.contract.verifier.stubs', 'fraudDetectionServer')
stubFinder.findAllRunningStubs().isPresent('org.springframework.cloud.contract.verifier.stubs:fraudDetectionServer')
and: 'Stubs were registered'
"${stubFinder.findStubUrl('loanIssuance').toString()}/name".toURL().text == 'loanIssuance'
"${stubFinder.findStubUrl('fraudDetectionServer').toString()}/name".toURL().text == 'fraudDetectionServer'
}
def 'should throw an exception when stub is not found'() {
when:
stubFinder.findStubUrl('nonExistingService')
then:
thrown(StubNotFoundException)
when:
stubFinder.findStubUrl('nonExistingGroupId', 'nonExistingArtifactId')
then:
thrown(StubNotFoundException)
}
def 'should register started servers as environment variables'() {
expect:
environment.getProperty("stubrunner.runningstubs.loanIssuance.port") != null
stubFinder.findAllRunningStubs().getPort("loanIssuance") == (environment.getProperty("stubrunner.runningstubs.loanIssuance.port") as Integer)
and:
environment.getProperty("stubrunner.runningstubs.fraudDetectionServer.port") != null
stubFinder.findAllRunningStubs().getPort("fraudDetectionServer") == (environment.getProperty("stubrunner.runningstubs.fraudDetectionServer.port") as Integer)
}
def 'should be able to interpolate a running stub in the passed test property'() {
given:
int fraudPort = stubFinder.findAllRunningStubs().getPort("fraudDetectionServer")
expect:
fraudPort > 0
environment.getProperty("foo", Integer) == fraudPort
foo == fraudPort
}
@Configuration
@EnableAutoConfiguration
static class Config {}
}
对于以下配置文件:
stubrunner:
repositoryRoot: classpath:m2repo/repository/
ids:
- org.springframework.cloud.contract.verifier.stubs:loanIssuance
- org.springframework.cloud.contract.verifier.stubs:fraudDetectionServer
- org.springframework.cloud.contract.verifier.stubs:bootService
cloud:
enabled: false
camel:
enabled: false
spring.cloud:
consul.enabled: false
service-registry.enabled: false
您也可以使用@AutoConfigureStubRunner内的属性代替使用属性。下面您可以通过设置注释的值来找到实现相同结果的示例。
@AutoConfigureStubRunner(
ids = ["org.springframework.cloud.contract.verifier.stubs:loanIssuance",
"org.springframework.cloud.contract.verifier.stubs:fraudDetectionServer",
"org.springframework.cloud.contract.verifier.stubs:bootService"],
repositoryRoot = "classpath:m2repo/repository/")
Stub Runner Spring为每个注册的WireMock服务器以以下方式注册环境变量。Stub Runner idscom.example:foo,com.example:bar的示例。
stubrunner.runningstubs.foo.port
stubrunner.runningstubs.bar.port
你可以在你的代码中引用它。
Stub Runner Spring Cloud
Stub Runner可以与Spring Cloud整合。
对于现实生活中的例子,你可以检查
制作人应用程式样本
消费者应用程序样本
Stubbing服务发现
Stub Runner Spring Cloud的最重要的特征就是它的存在
DiscoveryClient
RibbonServerList
这意味着无论您是否使用Zookeeper,Consul,Eureka或其他任何事情,您都不需要在测试中。我们正在启动您的依赖项的WireMock实例,只要您直接使用Feign,负载平衡RestTemplate或DiscoveryClient,我们会告诉您的应用程序来调用这些stubbed服务器,而不是调用真实的服务发现工具。
例如这个测试将通过
def 'should make service discovery work'() {
expect: 'WireMocks are running'
"${stubFinder.findStubUrl('loanIssuance').toString()}/name".toURL().text == 'loanIssuance'
"${stubFinder.findStubUrl('fraudDetectionServer').toString()}/name".toURL().text == 'fraudDetectionServer'
and: 'Stubs can be reached via load service discovery'
restTemplate.getForObject('http://loanIssuance/name', String) == 'loanIssuance'
restTemplate.getForObject('http://someNameThatShouldMapFraudDetectionServer/name', String) == 'fraudDetectionServer'
}
对于以下配置文件
spring.cloud:
zookeeper.enabled: false
consul.enabled: false
eureka.client.enabled: false
stubrunner:
camel.enabled: false
idsToServiceIds:
ivyNotation: someValueInsideYourCode
fraudDetectionServer: someNameThatShouldMapFraudDetectionServer
测试配置文件和服务发现
在集成测试中,您通常不想既不调用发现服务(例如Eureka)或调用服务器。这就是为什么你创建一个额外的测试配置,你要禁用这些功能。
由于spring-cloud-commons实现这一点的某些限制,您可以通过下面的静态块来禁用这些属性(例如Eureka)
//Hack to work around https://github.com/spring-cloud/spring-cloud-commons/issues/156
static {
System.setProperty("eureka.client.enabled", "false");
System.setProperty("spring.cloud.config.failFast", "false");
}
附加配置
您可以使用stubrunner.idsToServiceIds:地图将存根的artifactId与应用程序的名称进行匹配。提供:stubrunner.cloud.ribbon.enabled等于false,您可以禁用Stub Runner Ribbon支持。您可以通过提供stubrunner.cloud.enabled等于false来禁用Stub Runner支持
小费
默认情况下,所有服务发现都将被删除。这意味着不管事实如果你有一个现有的DiscoveryClient,它的结果将被忽略。但是,如果要重用它,只需将stubrunner.cloud.delegate.enabled设置为true,然后将现有的DiscoveryClient结果与已存在的结果合并。
Stub Runner启动应用程序
Spring Cloud Contract验证者Stub Runner Boot是一个Spring Boot应用程序,它暴露了REST端点来触发邮件标签并访问启动的WireMock服务器。
其中一个用例是在部署的应用程序上运行一些烟雾(端到端)测试。您可以在Too Much Coding博客的“Microservice部署”文章中阅读更多信息。
如何使用它?
只需添加
compile "org.springframework.cloud:spring-cloud-starter-stub-runner"
用@EnableStubRunnerServer注释一个课程,建一个胖子,你准备好了!
对于属性,请检查Stub Runner Spring部分。
端点
HTTP
GET/stubs- 返回ivy:integer表示法中所有运行存根的列表
GET/stubs/{ivy}- 返回给定的ivy符号的端口(当调用端点ivy也可以是artifactId)
消息
消息传递
GET/triggers- 返回ivy : [ label1, label2 …]表示法中所有正在运行的标签的列表
POST/triggers/{label}- 执行label的触发器
POST/triggers/{ivy}/{label}- 对于给定的ivy符号(当调用端点ivy也可以是artifactId)时,执行具有label的触发器)
例
@ContextConfiguration(classes = StubRunnerBoot, loader = SpringBootContextLoader)
@SpringBootTest(properties = "spring.cloud.zookeeper.enabled=false")
@ActiveProfiles("test")
class StubRunnerBootSpec extends Specification {
@Autowired StubRunning stubRunning
def setup() {
RestAssuredMockMvc.standaloneSetup(new HttpStubsController(stubRunning),
new TriggerController(stubRunning))
}
def 'should return a list of running stub servers in "full ivy:port" notation'() {
when:
String response = RestAssuredMockMvc.get('/stubs').body.asString()
then:
def root = new JsonSlurper().parseText(response)
root.'org.springframework.cloud.contract.verifier.stubs:bootService:0.0.1-SNAPSHOT:stubs' instanceof Integer
}
def 'should return a port on which a [#stubId] stub is running'() {
when:
def response = RestAssuredMockMvc.get("/stubs/${stubId}")
then:
response.statusCode == 200
response.body.as(Integer) > 0
where:
stubId << ['org.springframework.cloud.contract.verifier.stubs:bootService:+:stubs',
'org.springframework.cloud.contract.verifier.stubs:bootService:0.0.1-SNAPSHOT:stubs',
'org.springframework.cloud.contract.verifier.stubs:bootService:+',
'org.springframework.cloud.contract.verifier.stubs:bootService',
'bootService']
}
def 'should return 404 when missing stub was called'() {
when:
def response = RestAssuredMockMvc.get("/stubs/a:b:c:d")
then:
response.statusCode == 404
}
def 'should return a list of messaging labels that can be triggered when version and classifier are passed'() {
when:
String response = RestAssuredMockMvc.get('/triggers').body.asString()
then:
def root = new JsonSlurper().parseText(response)
root.'org.springframework.cloud.contract.verifier.stubs:bootService:0.0.1-SNAPSHOT:stubs'?.containsAll(["delete_book","return_book_1","return_book_2"])
}
def 'should trigger a messaging label'() {
given:
StubRunning stubRunning = Mock()
RestAssuredMockMvc.standaloneSetup(new HttpStubsController(stubRunning), new TriggerController(stubRunning))
when:
def response = RestAssuredMockMvc.post("/triggers/delete_book")
then:
response.statusCode == 200
and:
1 * stubRunning.trigger('delete_book')
}
def 'should trigger a messaging label for a stub with [#stubId] ivy notation'() {
given:
StubRunning stubRunning = Mock()
RestAssuredMockMvc.standaloneSetup(new HttpStubsController(stubRunning), new TriggerController(stubRunning))
when:
def response = RestAssuredMockMvc.post("/triggers/$stubId/delete_book")
then:
response.statusCode == 200
and:
1 * stubRunning.trigger(stubId, 'delete_book')
where:
stubId << ['org.springframework.cloud.contract.verifier.stubs:bootService:stubs', 'org.springframework.cloud.contract.verifier.stubs:bootService', 'bootService']
}
def 'should throw exception when trigger is missing'() {
when:
RestAssuredMockMvc.post("/triggers/missing_label")
then:
Exception e = thrown(Exception)
e.message.contains("Exception occurred while trying to return [missing_label] label.")
e.message.contains("Available labels are")
e.message.contains("org.springframework.cloud.contract.verifier.stubs:loanIssuance:0.0.1-SNAPSHOT:stubs=[]")
e.message.contains("org.springframework.cloud.contract.verifier.stubs:bootService:0.0.1-SNAPSHOT:stubs=")
}
}
Stub Runner启动服务发现
使用Stub Runner Boot的可能性之一就是将其用作“烟雾测试”的存根。这是什么意思?假设您不想将50个微服务部署到测试环境中,以检查您的应用程序是否正常工作。您在构建过程中已经执行了一系列测试,但您也希望确保应用程序的打包正常。您可以做的是将应用程序部署到环境中,启动并运行一些测试,以确定它是否正常工作。我们可以将这些测试称为烟雾测试,因为他们的想法只是检查一些测试场景。
这种方法的问题是,如果您正在执行微服务,则很可能您正在使用服务发现工具。Stub Runner引导允许您通过启动所需的存根并将其注册到服务发现工具中来解决此问题。让我们来看看一个这样一个设置的例子Eureka。假设Eureka已经在运行。
@SpringBootApplication
@EnableStubRunnerServer
@EnableEurekaClient
@AutoConfigureStubRunner
public class StubRunnerBootEurekaExample {
public static void main(String[] args) {
SpringApplication.run(StubRunnerBootEurekaExample.class, args);
}
}
如您所见,我们希望启动一个Stub Runner引导服务器@EnableStubRunnerServer,启用Eureka客户端@EnableEurekaClient,并且我们想要使存根转移功能打开@AutoConfigureStubRunner。
现在我们假设我们要启动这个应用程序,以便自动注册存根。我们可以通过运行应用程序java -jar ${SYSTEM_PROPS} stub-runner-boot-eureka-example.jar来执行此操作,其中${SYSTEM_PROPS}将包含以下属性列表
-Dstubrunner.repositoryRoot=http://repo.spring.io/snapshots (1)
-Dstubrunner.cloud.stubbed.discovery.enabled=false (2)
-Dstubrunner.ids=org.springframework.cloud.contract.verifier.stubs:loanIssuance,org.springframework.cloud.contract.verifier.stubs:fraudDetectionServer,org.springframework.cloud.contract.verifier.stubs:bootService (3)
-Dstubrunner.idsToServiceIds.fraudDetectionServer=someNameThatShouldMapFraudDetectionServer (4)
(1) - we tell Stub Runner where all the stubs reside
(2) - we don't want the default behaviour where the discovery service is stubbed. That's why the stub registration will be picked
(3) - we provide a list of stubs to download
(4) - we provide a list of artifactId to serviceId mapping
这样您的部署应用程序可以通过服务发现将请求发送到启动的WireMock服务器。默认情况下,application.yml可能会设置1-3,因为它们不太可能改变。这样,只要您启动Stub Runner引导,您只能提供要下载的存根列表。
JUnit和Spring的常用属性
可以使用系统属性或配置属性(对于Spring)设置重复的某些属性。以下是他们的名称及其默认值:
物业名称默认值描述
stubrunner.minPort
10000
具有存根的起始WireMock端口的最小值
stubrunner.maxPort
15000
具有存根的起始WireMock端口的最小值
stubrunner.repositoryRoot
Maven repo网址如果空白,那么将调用本地的maven repo
stubrunner.classifier
stubs
stub工件的默认分类器
stubrunner.workOffline
false
如果为true,则不会联系任何远程存储库以下载存根
stubrunner.ids
数组的常春藤符号存根下载
stubrunner.username
可选的用户名访问使用存根存储JAR的工具
stubrunner.password
访问使用存根存储JAR的工具的可选密码
存根运动员短桩ids
您可以通过stubrunner.ids系统属性提供存根下载。他们遵循以下模式:
groupId:artifactId:version:classifier:port
version,classifier和port是可选的。
如果您不提供port,则会选择一个随机的
如果您不提供classifier,那么将采用默认值。(注意,你可以传递这样一个空的分类器groupId:artifactId:version:)
如果您不提供version,则将通过+,最新的将被下载
其中port表示WireMock服务器的端口。
重要
从版本1.0.4开始,您可以提供一系列您希望Stub Runner考虑的版本。您可以在这里阅读有关Aether版本控制范围的更多信息。
取自Aether文件:
该方案接受任何形式的版本,将版本解释为数字和字母段的序列。字符' - ','_'和'。'以及从数字到字母的转换,反之亦然分隔版本段。分隔符被视为等同物。
数字段在数学上进行比较,字母段被字典和区分大小写比较。但是,以下限定字符串被特别识别和处理:“alpha”=“a”<“beta”=“b”<“milestone”=“m”<“cr”=“rc”<“snapshot”<“final “=”ga“<”sp“。所有这些知名的限定词被认为比其他字符串更小/更老。空的段/字符串等于0。
除了上述限定符之外,令牌“min”和“max”可以用作最终版本段,以表示具有给定前缀的最小/最大版本。例如,“1.2.min”表示1.2行中的最小版本,“1.2.max”表示1.2行中最大的版本。形式“[MN *]”的版本范围是“[MNmin,MNmax]”的缩写。
数字和字符串被认为是无法比拟的。在不同类型的版本段会相互冲突的情况下,比较将假定以前的段分别以0或“ga”段的形式进行填充,直到种类不一致被解决为止,例如“1-alpha”=“1.0.0-alpha “<”1.0.1-ga“=”1.0.1“。
Stub Runner用于消息传递
Stub Runner具有在内存中运行已发布存根的功能。它可以与开箱即用的以下框架集成
Spring Integration
Spring Cloud Stream
Apache Camel
Spring AMQP
它还提供了与市场上任何其他解决方案集成的入口点。
存根触发
要触发消息,只需使用StubTrigger接口即可:
package org.springframework.cloud.contract.stubrunner;
import java.util.Collection;
import java.util.Map;
public interface StubTrigger {
/**
* Triggers an event by a given label for a given {@code groupid:artifactid} notation. You can use only {@code artifactId} too.
*
* Feature related to messaging.
*
* @return true - if managed to run a trigger
*/
boolean trigger(String ivyNotation, String labelName);
/**
* Triggers an event by a given label.
*
* Feature related to messaging.
*
* @return true - if managed to run a trigger
*/
boolean trigger(String labelName);
/**
* Triggers all possible events.
*
* Feature related to messaging.
*
* @return true - if managed to run a trigger
*/
boolean trigger();
/**
* Returns a mapping of ivy notation of a dependency to all the labels it has.
*
* Feature related to messaging.
*/
Map> labels();
}
为了方便起见,StubFinder接口扩展了StubTrigger,所以只需要在你的测试中使用一个。
StubTrigger提供以下选项来触发邮件:
按标签触发
stubFinder.trigger('return_book_1')
按组和人工制品ids触发
stubFinder.trigger('org.springframework.cloud.contract.verifier.stubs:camelService', 'return_book_1')
通过人工制品ids触发
stubFinder.trigger('camelService', 'return_book_1')
触发所有消息
stubFinder.trigger()
Stub Runner Camel
Spring Cloud Contract验证器Stub Runner的消息传递模块为您提供了与Apache Camel集成的简单方法。对于提供的工件,它将自动下载存根并注册所需的路由。
将其添加到项目中
在类路径上同时拥有Apache Camel和Spring Cloud Contract Stub Runner就足够了。记住使用@AutoConfigureMessageVerifier注释你的测试类。
例子
桩结构
让我们假设我们拥有以下Maven资源库,并为camelService应用程序配置了一个存根。
└── .m2
└── repository
└── io
└── codearte
└── accurest
└── stubs
└── camelService
├── 0.0.1-SNAPSHOT
│ ├── camelService-0.0.1-SNAPSHOT.pom
│ ├── camelService-0.0.1-SNAPSHOT-stubs.jar
│ └── maven-metadata-local.xml
└── maven-metadata-local.xml
并且存根包含以下结构:
├── META-INF
│ └── MANIFEST.MF
└── repository
├── accurest
│ ├── bookDeleted.groovy
│ ├── bookReturned1.groovy
│ └── bookReturned2.groovy
└── mappings
让我们考虑以下合同(让我们用1来表示):
Contract.make {
label 'return_book_1'
input {
triggeredBy('bookReturnedTriggered()')
}
outputMessage {
sentTo('jms:output')
body('''{ "bookName" : "foo" }''')
headers {
header('BOOK-NAME', 'foo')
}
}
}
和2号
Contract.make {
label 'return_book_2'
input {
messageFrom('jms:input')
messageBody([
bookName: 'foo'
])
messageHeaders {
header('sample', 'header')
}
}
outputMessage {
sentTo('jms:output')
body([
bookName: 'foo'
])
headers {
header('BOOK-NAME', 'foo')
}
}
}
情景1(无输入讯息)
为了通过return_book_1标签触发消息,我们将使用StubTigger接口,如下所示
stubFinder.trigger('return_book_1')
接下来,我们将要收听发送到jms:output的消息的输出
Exchange receivedMessage = camelContext.createConsumerTemplate().receive('jms:output', 5000)
接收到的消息将通过以下断言
receivedMessage != null
assertThatBodyContainsBookNameFoo(receivedMessage.in.body)
receivedMessage.in.headers.get('BOOK-NAME') == 'foo'
情景2(输入触发输出)
由于路由是为您设置的,只需向jms:output目的地发送消息即可。
camelContext.createProducerTemplate().sendBodyAndHeaders('jms:input', new BookReturned('foo'), [sample: 'header'])
接下来我们将要收听发送到jms:output的消息的输出
Exchange receivedMessage = camelContext.createConsumerTemplate().receive('jms:output', 5000)
接收到的消息将通过以下断言
receivedMessage != null
assertThatBodyContainsBookNameFoo(receivedMessage.in.body)
receivedMessage.in.headers.get('BOOK-NAME') == 'foo'
情景3(无输出输入)
由于路由是为您设置的,只需向jms:output目的地发送消息即可。
camelContext.createProducerTemplate().sendBodyAndHeaders('jms:delete', new BookReturned('foo'), [sample: 'header'])
Stub Runner整合
Spring Cloud Contract验证器Stub Runner的消息传递模块为您提供了一种简单的与Spring Integration集成的方法。对于提供的工件,它将自动下载存根并注册所需的路由。
将其添加到项目中
在类路径上同时拥有Apache Camel和Spring Cloud Contract Stub Runner就足够了。记住使用@AutoConfigureMessageVerifier注释测试类。
例子
桩结构
让我们假设我们拥有以下Maven仓库,并为integrationService应用程序配置了一个存根。
└── .m2
└── repository
└── io
└── codearte
└── accurest
└── stubs
└── integrationService
├── 0.0.1-SNAPSHOT
│ ├── integrationService-0.0.1-SNAPSHOT.pom
│ ├── integrationService-0.0.1-SNAPSHOT-stubs.jar
│ └── maven-metadata-local.xml
└── maven-metadata-local.xml
并且存根包含以下结构:
├── META-INF
│ └── MANIFEST.MF
└── repository
├── accurest
│ ├── bookDeleted.groovy
│ ├── bookReturned1.groovy
│ └── bookReturned2.groovy
└── mappings
让我们考虑以下合同(让我们用1来表示):
Contract.make {
label 'return_book_1'
input {
triggeredBy('bookReturnedTriggered()')
}
outputMessage {
sentTo('output')
body('''{ "bookName" : "foo" }''')
headers {
header('BOOK-NAME', 'foo')
}
}
}
和2号
Contract.make {
label 'return_book_2'
input {
messageFrom('input')
messageBody([
bookName: 'foo'
])
messageHeaders {
header('sample', 'header')
}
}
outputMessage {
sentTo('output')
body([
bookName: 'foo'
])
headers {
header('BOOK-NAME', 'foo')
}
}
}
和以下Spring Integration路由:
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:beans="http://www.springframework.org/schema/beans"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/integration
http://www.springframework.org/schema/integration/spring-integration.xsd">
output-channel="outputTest"/>
情景1(无输入讯息)
为了通过return_book_1标签触发一条消息,我们将使用StubTigger接口,如下所示
stubFinder.trigger('return_book_1')
接下来我们将要收听发送到output的消息的输出
Message receivedMessage = messaging.receive('outputTest')
接收到的消息将通过以下断言
receivedMessage != null
assertJsons(receivedMessage.payload)
receivedMessage.headers.get('BOOK-NAME') == 'foo'
情景2(输入触发输出)
由于路由是为您设置的,只需向output目的地发送一条消息即可。
messaging.send(new BookReturned('foo'), [sample: 'header'], 'input')
接下来,我们将要收听发送到output的消息的输出
Message receivedMessage = messaging.receive('outputTest')
接收到的消息将通过以下断言
receivedMessage != null
assertJsons(receivedMessage.payload)
receivedMessage.headers.get('BOOK-NAME') == 'foo'
情景3(无输出输入)
由于路由是为您设置的,只需向input目的地发送消息即可。
messaging.send(new BookReturned('foo'), [sample: 'header'], 'delete')
Stub Runner流
Spring Cloud Contract验证器Stub Runner的消息传递模块为您提供了与Spring Stream集成的简单方式。对于提供的工件,它将自动下载存根并注册所需的路由。
警告
在Stub Runner与Stream的集成中,messageFrom或sentTo字符串首先被解析为一个destination的频道,然后如果没有这样的destination,它被解析为频道名称。
将其添加到项目中
在类路径上同时拥有Apache Camel和Spring Cloud Contract Stub Runner就足够了。记住用@AutoConfigureMessageVerifier注释你的测试类。
例子
桩结构
让我们假设我们拥有以下Maven仓库,并为streamService应用程序配置了一个存根。
└── .m2
└── repository
└── io
└── codearte
└── accurest
└── stubs
└── streamService
├── 0.0.1-SNAPSHOT
│ ├── streamService-0.0.1-SNAPSHOT.pom
│ ├── streamService-0.0.1-SNAPSHOT-stubs.jar
│ └── maven-metadata-local.xml
└── maven-metadata-local.xml
并且存根包含以下结构:
├── META-INF
│ └── MANIFEST.MF
└── repository
├── accurest
│ ├── bookDeleted.groovy
│ ├── bookReturned1.groovy
│ └── bookReturned2.groovy
└── mappings
让我们考虑以下合同(让我们用1来表示):
Contract.make {
label 'return_book_1'
input { triggeredBy('bookReturnedTriggered()') }
outputMessage {
sentTo('returnBook')
body('''{ "bookName" : "foo" }''')
headers { header('BOOK-NAME', 'foo') }
}
}
和2号
Contract.make {
label 'return_book_2'
input {
messageFrom('bookStorage')
messageBody([
bookName: 'foo'
])
messageHeaders { header('sample', 'header') }
}
outputMessage {
sentTo('returnBook')
body([
bookName: 'foo'
])
headers { header('BOOK-NAME', 'foo') }
}
}
和以下Spring配置:
stubrunner.repositoryRoot: classpath:m2repo/repository/
stubrunner.ids: org.springframework.cloud.contract.verifier.stubs:streamService:0.0.1-SNAPSHOT:stubs
spring:
cloud:
stream:
bindings:
output:
destination: returnBook
input:
destination: bookStorage
server:
port: 0
debug: true
情景1(无输入讯息)
为了通过return_book_1标签触发一条消息,我们将使用StubTrigger接口,如下所示
stubFinder.trigger('return_book_1')
接下来,我们将要收听发送到destination为returnBook的频道的消息的输出
Message receivedMessage = messaging.receive('returnBook')
接收到的消息将通过以下断言
receivedMessage != null
assertJsons(receivedMessage.payload)
receivedMessage.headers.get('BOOK-NAME') == 'foo'
情景2(输入触发输出)
由于路由是为您设置的,只需向bookStoragedestination发送消息即可。
messaging.send(new BookReturned('foo'), [sample: 'header'], 'bookStorage')
接下来我们将要收听发送到returnBook的消息的输出
Message receivedMessage = messaging.receive('returnBook')
接收到的消息将通过以下断言
receivedMessage != null
assertJsons(receivedMessage.payload)
receivedMessage.headers.get('BOOK-NAME') == 'foo'
情景3(无输出输入)
由于路由是为您设置的,只需向output目的地发送消息即可。
messaging.send(new BookReturned('foo'), [sample: 'header'], 'delete')
Stub Runner Spring AMQP
Spring Cloud Contract验证器Stub Runner的消息传递模块提供了一种简单的方法来与Spring AMQP的Rabbit模板集成。对于提供的工件,它将自动下载存根并注册所需的路由。
集成尝试独立运行,即不与运行的RabbitMQ消息代理交互。它期望在应用程序上下文中使用RabbitTemplate,并将其用作spring boot测试@SpyBean。因此,它可以使用mockito间谍功能来验证和内省应用程序发送的消息。
在消费消费者方面,它考虑了所有@RabbitListener注释端点以及应用程序上下文中的所有“SimpleMessageListenerContainer”。
由于消息通常发送到AMQP中的交换机,消息合同中包含交换机名称作为目标。另一方的消息侦听器绑定到队列。绑定将交换机连接到队列。如果触发消息合约,Spring AMQP存根转移器集成将在与该交换机匹配的应用程序上下文中查找绑定。然后它从Spring交换机收集队列,并尝试查找绑定到这些队列的消息侦听器。消息被触发到所有匹配的消息监听器。
将其添加到项目中
在类路径上同时拥有Spring AMQP和Spring Cloud Contract Stub Runner就足够了,并设置属性stubrunner.amqp.enabled=true。记住用@AutoConfigureMessageVerifier注释你的测试类。
例子
桩结构
让我们假设我们拥有以下Maven资源库,并为spring-cloud-contract-amqp-test应用程序配置了一个存根。
└── .m2
└── repository
└── com
└── example
└── spring-cloud-contract-amqp-test
├── 0.4.0-SNAPSHOT
│ ├── spring-cloud-contract-amqp-test-0.4.0-SNAPSHOT.pom
│ ├── spring-cloud-contract-amqp-test-0.4.0-SNAPSHOT-stubs.jar
│ └── maven-metadata-local.xml
└── maven-metadata-local.xml
并且存根包含以下结构:
├── META-INF
│ └── MANIFEST.MF
└── contracts
└── shouldProduceValidPersonData.groovy
让我们考虑下列合约:
Contract.make {
// Human readable description
description 'Should produce valid person data'
// Label by means of which the output message can be triggered
label 'contract-test.person.created.event'
// input to the contract
input {
// the contract will be triggered by a method
triggeredBy('createPerson()')
}
// output message of the contract
outputMessage {
// destination to which the output message will be sent
sentTo 'contract-test.exchange'
headers {
header('contentType': 'application/json')
header('__TypeId__': 'org.springframework.cloud.contract.stubrunner.messaging.amqp.Person')
}
// the body of the output message
body ([
id: $(consumer(9), producer(regex("[0-9]+"))),
name: "me"
])
}
}
和以下Spring配置:
stubrunner:
repositoryRoot: classpath:m2repo/repository/
ids: org.springframework.cloud.contract.verifier.stubs.amqp:spring-cloud-contract-amqp-test:0.4.0-SNAPSHOT:stubs
amqp:
enabled: true
server:
port: 0
触发消息
因此,为了触发使用上述合同的消息,我们将使用StubTrigger界面如下。
stubTrigger.trigger("contract-test.person.created.event")
消息的目的地为contract-test.exchange,所以Spring AMQP存根转移器集成查找与此交换相关的绑定。
@Bean
public Binding binding() {
return BindingBuilder.bind(new Queue("test.queue")).to(new DirectExchange("contract-test.exchange")).with("#");
}
绑定定义绑定队列test.queue。因此,以下监听器定义是一个匹配,并使用合同消息进行调用。
@Bean
public SimpleMessageListenerContainer simpleMessageListenerContainer(ConnectionFactory connectionFactory,
MessageListenerAdapter listenerAdapter) {
SimpleMessageListenerContainer container = new SimpleMessageListenerContainer();
container.setConnectionFactory(connectionFactory);
container.setQueueNames("test.queue");
container.setMessageListener(listenerAdapter);
return container;
}
此外,以下注释的监听器表示一个匹配并将被调用。
@RabbitListener(bindings = @QueueBinding(
value = @Queue(value = "test.queue"),
exchange = @Exchange(value = "contract-test.exchange", ignoreDeclarationExceptions = "true")))
public void handlePerson(Person person) {
this.person = person;
}
注意
该消息直接交给MessageListener与SimpleMessageListenerContainer匹配的MessageListener方法。
Spring AMQP测试配置
为了避免Spring AMQP在测试期间尝试连接到运行的代理,我们配置了一个模拟ConnectionFactory。
要禁用嘲弄的ConnectionFactory设置属性stubrunner.amqp.mockConnection=false
stubrunner:
amqp:
mockConnection: false
Contract DSL
重要
请记住,在合同文件中,您必须向Contract类和make静态导入ieorg.springframework.cloud.spec.Contract.make { … }提供完全限定名称。您还可以向Contract类import org.springframework.cloud.spec.Contract提供导入,然后调用Contract.make { … }
Contract DSL是用Groovy写的,但是如果以前没有使用Groovy,不要惊慌。语言的知识并不是真正需要的,因为我们的DSL只使用它的一小部分(即文字,方法调用和闭包)。DSL还被设计为程序员可读,而不需要DSL本身的知识 - 它是静态类型的。
小费
Spring Cloud Contract支持在单个文件中定义多个合同!
合同存在于Spring Cloud Contract验证器存储库的spring-cloud-contract-spec模块中。
我们来看一下合同定义的完整例子。
org.springframework.cloud.contract.spec.Contract.make {
request {
method 'PUT'
url '/api/12'
headers {
header 'Content-Type': 'application/vnd.org.springframework.cloud.contract.verifier.twitter-places-analyzer.v1+json'
}
body '''\
[{
"created_at": "Sat Jul 26 09:38:57 +0000 2014",
"id": 492967299297845248,
"id_str": "492967299297845248",
"text": "Gonna see you at Warsaw",
"place":
{
"attributes":{},
"bounding_box":
{
"coordinates":
[[
[-77.119759,38.791645],
[-76.909393,38.791645],
[-76.909393,38.995548],
[-77.119759,38.995548]
]],
"type":"Polygon"
},
"country":"United States",
"country_code":"US",
"full_name":"Washington, DC",
"id":"01fbe706f872cb32",
"name":"Washington",
"place_type":"city",
"url": "http://api.twitter.com/1/geo/id/01fbe706f872cb32.json"
}
}]
'''
}
response {
status 200
}
}
不是DSL的所有功能都在上面的例子中使用。如果您找不到您想要的内容,请查看本页下面的段落。
您可以使用独立的maven命令mvn org.springframework.cloud:spring-cloud-contract-maven-plugin:convert轻松地将Contracts编译为WireMock存根映射。
限制
警告
Spring Cloud Contract验证器不正确支持XML。请使用JSON或帮助我们实现此功能。
警告
对JSON数组的大小的验证的支持是实验性的。如果要打开它,请提供等于true的系统属性spring.cloud.contract.verifier.assert.size的值。默认情况下,此功能设置为false。您还可以在插件配置中提供assertJsonSize属性。
警告
由于JSON结构可以有任何形式,因此在GString中使用时使用value(consumer(…), producer(…))符号时,有时无法正确解析它。这就是为什么我们强烈推荐使用Groovy Map符号。
常见的顶级元素
描述
您可以添加一个description到您的合同,除了一个任意的文本。例:
org.springframework.cloud.contract.spec.Contract.make {
description('''
given:
An input
when:
Sth happens
then:
Output
''')
}
名称
您可以提供您的合同名称。假设您提供了一个名称should register a user。如果这样做,则自动生成测试的名称将等于validate_should_register_a_user。如果是WireMock存根,存根的名称也将为should_register_a_user.json。
重要
请确保该名称不包含任何会使生成的测试无法编译的字符。还要记住,如果您为多个合同提供相同的名称,那么您的自动生成测试将无法编译,并且生成的存根将会相互覆盖。
忽略合同
如果您想忽略合同,您可以在插件配置中设置忽略合同的值,或者仅在合同本身设置ignored属性:
org.springframework.cloud.contract.spec.Contract.make {
ignored()
}
HTTP顶级元素
可以在合同定义的顶层关闭中调用以下方法。请求和响应是强制性的,优先级是可选的。
org.springframework.cloud.contract.spec.Contract.make {
// Definition of HTTP request part of the contract
// (this can be a valid request or invalid depending
// on type of contract being specified).
request {
//...
}
// Definition of HTTP response part of the contract
// (a service implementing this contract should respond
// with following response after receiving request
// specified in "request" part above).
response {
//...
}
// Contract priority, which can be used for overriding
// contracts (1 is highest). Priority is optional.
priority 1
}
请求
HTTP协议只需要在请求中指定方法和地址。在合同的请求定义中,相同的信息是强制性的。
org.springframework.cloud.contract.spec.Contract.make {
request {
// HTTP request method (GET/POST/PUT/DELETE).
method 'GET'
// Path component of request URL is specified as follows.
urlPath('/users')
}
response {
//...
}
}
可以指定整个url而不是路径,但是urlPath是测试与主机无关的推荐方法。
org.springframework.cloud.contract.spec.Contract.make {
request {
method 'GET'
// Specifying `url` and `urlPath` in one contract is illegal.
url('http://localhost:8888/users')
}
response {
//...
}
}
请求可能包含查询参数,这些参数在嵌套在urlPath或url的调用中的闭包中指定。
org.springframework.cloud.contract.spec.Contract.make {
request {
//...
urlPath('/users') {
// Each parameter is specified in form
// `'paramName' : paramValue` where parameter value
// may be a simple literal or one of matcher functions,
// all of which are used in this example.
queryParameters {
// If a simple literal is used as value
// default matcher function is used (equalTo)
parameter 'limit': 100
// `equalTo` function simply compares passed value
// using identity operator (==).
parameter 'filter': equalTo("email")
// `containing` function matches strings
// that contains passed substring.
parameter 'gender': value(consumer(containing("[mf]")), producer('mf'))
// `matching` function tests parameter
// against passed regular expression.
parameter 'offset': value(consumer(matching("[0-9]+")), producer(123))
// `notMatching` functions tests if parameter
// does not match passed regular expression.
parameter 'loginStartsWith': value(consumer(notMatching(".{0,2}")), producer(3))
}
}
//...
}
response {
//...
}
}
它可能包含其他请求标头...
org.springframework.cloud.contract.spec.Contract.make {
request {
//...
// Each header is added in form `'Header-Name' : 'Header-Value'`.
// there are also some helper methods
headers {
header 'key': 'value'
contentType(applicationJson())
}
//...
}
response {
//...
}
}
...和请求机构。
org.springframework.cloud.contract.spec.Contract.make {
request {
//...
// Currently only JSON format of request body is supported.
// Format will be determined from a header or body's content.
body '''{ "login" : "john", "name": "John The Contract" }'''
}
response {
//...
}
}
响应
最小响应必须包含HTTP状态代码。
org.springframework.cloud.contract.spec.Contract.make {
request {
//...
}
response {
// Status code sent by the server
// in response to request specified above.
status 200
}
}
除了状态响应可能包含标头和正文之外,它们与请求中的方式相同(参见前一段)。
动态属性
合同可以包含一些动态属性 - 时间戳/ ids等。您不想强制使用者将其时钟保留为始终返回相同的时间值,以便与存根匹配。这就是为什么我们允许您以两种方式在合同中提供动态部分。一个是将它们直接传递到体内,一个将它们设置在另一部分,称为testMatchers和stubMatchers。
体内动态属性
您可以通过value方法设置体内的属性
value(consumer(...), producer(...))
value(c(...), p(...))
value(stub(...), test(...))
value(client(...), server(...))
或者如果您正在使用Groovy地图符号,您可以使用$()方法
$(consumer(...), producer(...))
$(c(...), p(...))
$(stub(...), test(...))
$(client(...), server(...))
所有上述方法都是相同的。这意味着stub和client方法是consumer方法的别名。我们来仔细看看我们可以在后续章节中对这些值做些什么。
正则表达式
您可以使用正则表达式在Contract DSL中写入请求。当您想要指出给定的响应应该被提供给遵循给定模式的请求时,这是特别有用的。此外,当您需要使用模式,而不是测试和服务器端测试时,您可以使用它。
请看下面的例子:
org.springframework.cloud.contract.spec.Contract.make {
request {
method('GET')
url $(consumer(~/\/[0-9]{2}/), producer('/12'))
}
response {
status 200
body(
id: $(anyNumber()),
surname: $(
consumer('Kowalsky'),
producer(regex('[a-zA-Z]+'))
),
name: 'Jan',
created: $(consumer('2014-02-02 12:23:43'), producer(execute('currentDate(it)'))),
correlationId: value(consumer('5d1f9fef-e0dc-4f3d-a7e4-72d2220dd827'),
producer(regex('[a-fA-F0-9]{8}-[a-fA-F0-9]{4}-[a-fA-F0-9]{4}-[a-fA-F0-9]{4}-[a-fA-F0-9]{12}'))
)
)
headers {
header 'Content-Type': 'text/plain'
}
}
}
您还可以使用正则表达式仅提供通信的一方。如果这样做,那么我们将自动提供与提供的正则表达式匹配的生成的字符串。例如:
org.springframework.cloud.contract.spec.Contract.make {
request {
method 'PUT'
url value(consumer(regex('/foo/[0-9]{5}')))
body([
requestElement: $(consumer(regex('[0-9]{5}')))
])
headers {
header('header', $(consumer(regex('application\\/vnd\\.fraud\\.v1\\+json;.*'))))
}
}
response {
status 200
body([
responseElement: $(producer(regex('[0-9]{7}')))
])
headers {
contentType("application/vnd.fraud.v1+json")
}
}
}
在该示例中,对于请求和响应,通信的相对侧将具有生成的相应数据。
Spring Cloud Contract附带一系列预定义的正则表达式,您可以在合同中使用。
protected static final Pattern TRUE_OR_FALSE = Pattern.compile(/(true|false)/)
protected static final Pattern ONLY_ALPHA_UNICODE = Pattern.compile(/[\p{L}]*/)
protected static final Pattern NUMBER = Pattern.compile('-?\\d*(\\.\\d+)?')
protected static final Pattern IP_ADDRESS = Pattern.compile('([01]?\\d\\d?|2[0-4]\\d|25[0-5])\\.([01]?\\d\\d?|2[0-4]\\d|25[0-5])\\.([01]?\\d\\d?|2[0-4]\\d|25[0-5])\\.([01]?\\d\\d?|2[0-4]\\d|25[0-5])')
protected static final Pattern HOSTNAME_PATTERN = Pattern.compile('((http[s]?|ftp):\\/)\\/?([^:\\/\\s]+)(:[0-9]{1,5})?')
protected static final Pattern EMAIL = Pattern.compile('[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\\.[a-zA-Z]{2,4}');
protected static final Pattern URL = Pattern.compile('((www\\.|(http|https|ftp|news|file)+\\:\\/\\/)[_.a-z0-9-]+\\.[a-z0-9\\/_:@=.+?,##%&~-]*[^.|\\\'|\\# |!|\\(|?|,| |>|<|;|\\)])')
protected static final Pattern UUID = Pattern.compile('[a-z0-9]{8}-[a-z0-9]{4}-[a-z0-9]{4}-[a-z0-9]{4}-[a-z0-9]{12}')
protected static final Pattern ANY_DATE = Pattern.compile('(\\d\\d\\d\\d)-(0[1-9]|1[012])-(0[1-9]|[12][0-9]|3[01])')
protected static final Pattern ANY_DATE_TIME = Pattern.compile('([0-9]{4})-(1[0-2]|0[1-9])-(3[01]|0[1-9]|[12][0-9])T(2[0-3]|[01][0-9]):([0-5][0-9]):([0-5][0-9])')
protected static final Pattern ANY_TIME = Pattern.compile('(2[0-3]|[01][0-9]):([0-5][0-9]):([0-5][0-9])')
protected static final Pattern NON_EMPTY = Pattern.compile(/.+/)
protected static final Pattern NON_BLANK = Pattern.compile(/.*(\S+|\R).*|!^\R*$/)
protected static final Pattern ISO8601_WITH_OFFSET = Pattern.compile(/([0-9]{4})-(1[0-2]|0[1-9])-(3[01]|0[1-9]|[12][0-9])T(2[0-3]|[01][0-9]):([0-5][0-9]):([0-5][0-9])(\.\d{3})?(Z|[+-][01]\d:[0-5]\d)/)
protected static Pattern anyOf(String... values){
return Pattern.compile(values.collect({"^$it\$"}).join("|"))
}
String onlyAlphaUnicode() {
return ONLY_ALPHA_UNICODE.pattern()
}
String number() {
return NUMBER.pattern()
}
String anyBoolean() {
return TRUE_OR_FALSE.pattern()
}
String ipAddress() {
return IP_ADDRESS.pattern()
}
String hostname() {
return HOSTNAME_PATTERN.pattern()
}
String email() {
return EMAIL.pattern()
}
String url() {
return URL.pattern()
}
String uuid(){
return UUID.pattern()
}
String isoDate() {
return ANY_DATE.pattern()
}
String isoDateTime() {
return ANY_DATE_TIME.pattern()
}
String isoTime() {
return ANY_TIME.pattern()
}
String iso8601WithOffset() {
return ISO8601_WITH_OFFSET.pattern()
}
String nonEmpty() {
return NON_EMPTY.pattern()
}
String nonBlank() {
return NON_BLANK.pattern()
}
所以在你的合同中你可以这样使用它
Contract dslWithOptionalsInString = Contract.make {
priority 1
request {
method POST()
url '/users/password'
headers {
contentType(applicationJson())
}
body(
email: $(consumer(optional(regex(email()))), producer('[email protected]')),
callback_url: $(consumer(regex(hostname())), producer('http://partners.com'))
)
}
response {
status 404
headers {
contentType(applicationJson())
}
body(
code: value(consumer("123123"), producer(optional("123123"))),
message: "User not found by email = [${value(producer(regex(email())), consumer('[email protected]'))}]"
)
}
}
传递可选参数
可以在您的合同中提供可选参数。只能有可选参数:
STUB侧请求
响应的TEST侧
例:
org.springframework.cloud.contract.spec.Contract.make {
priority 1
request {
method 'POST'
url '/users/password'
headers {
contentType(applicationJson())
}
body(
email: $(consumer(optional(regex(email()))), producer('[email protected]')),
callback_url: $(consumer(regex(hostname())), producer('http://partners.com'))
)
}
response {
status 404
headers {
header 'Content-Type': 'application/json'
}
body(
code: value(consumer("123123"), producer(optional("123123")))
)
}
}
通过使用optional()方法包装身体的一部分,您实际上正在创建一个应该存在0次或更多次的正则表达式。
如果您选择Spock,那么上述示例将会生成以下测试:
"""
given:
def request = given()
.header("Content-Type", "application/json")
.body('''{"email":"[email protected]","callback_url":"http://partners.com"}''')
when:
def response = given().spec(request)
.post("/users/password")
then:
response.statusCode == 404
response.header('Content-Type') == 'application/json'
and:
DocumentContext parsedJson = JsonPath.parse(response.body.asString())
assertThatJson(parsedJson).field("code").matches("(123123)?")
"""
和以下存根:
'''
{
"request" : {
"url" : "/users/password",
"method" : "POST",
"bodyPatterns" : [ {
"matchesJsonPath" : "$[?(@.email =~ /([a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\\\\.[a-zA-Z]{2,4})?/)]"
}, {
"matchesJsonPath" : "$[?(@.callback_url =~ /((http[s]?|ftp):\\\\/)\\\\/?([^:\\\\/\\\\s]+)(:[0-9]{1,5})?/)]"
} ],
"headers" : {
"Content-Type" : {
"equalTo" : "application/json"
}
}
},
"response" : {
"status" : 404,
"body" : "{\\"code\\":\\"123123\\",\\"message\\":\\"User not found by email == [[email protected]]\\"}",
"headers" : {
"Content-Type" : "application/json"
}
},
"priority" : 1
}
'''
在服务器端执行自定义方法
也可以在测试期间定义要在服务器端执行的方法调用。这样的方法可以添加到在配置中定义为“baseClassForTests”的类中。例:
合同
org.springframework.cloud.contract.spec.Contract.make {
request {
method 'PUT'
url $(consumer(regex('^/api/[0-9]{2}$')), producer('/api/12'))
headers {
header 'Content-Type': 'application/json'
}
body '''\
[{
"text": "Gonna see you at Warsaw"
}]
'''
}
response {
body (
path: $(consumer('/api/12'), producer(regex('^/api/[0-9]{2}$'))),
correlationId: $(consumer('1223456'), producer(execute('isProperCorrelationId($it)')))
)
status 200
}
}
基础班
abstract class BaseMockMvcSpec extends Specification {
def setup() {
RestAssuredMockMvc.standaloneSetup(new PairIdController())
}
void isProperCorrelationId(Integer correlationId) {
assert correlationId == 123456
}
void isEmpty(String value) {
assert value == null
}
}
重要
您不能同时使用String和execute来执行连接。例如呼叫header('Authorization', 'Bearer ' + execute('authToken()'))将导致不正确的结果。要使此工作只需调用header('Authorization', execute('authToken()')),并确保authToken()方法返回您需要的所有内容。
从响应引用请求
最好的情况是提供固定值,但有时您需要在响应中引用请求。为了做到这一点,您可以从fromRequest()方法中获利,从而允许您从HTTP请求中引用一堆元素。您可以使用以下选项:
fromRequest().url()- 返回请求URL
fromRequest().query(String key)- 返回具有给定名称的第一个查询参数
fromRequest().query(String key, int index)- 返回具有给定名称的第n个查询参数
fromRequest().header(String key)- 返回具有给定名称的第一个标题
fromRequest().header(String key, int index)- 返回具有给定名称的第n个标题
fromRequest().body()- 返回完整的请求体
fromRequest().body(String jsonPath)- 从与JSON路径匹配的请求中返回元素
我们来看看下面的合同
Contract contractDsl = Contract.make {
request {
method 'GET'
url('/api/v1/xxxx') {
queryParameters {
parameter("foo", "bar")
parameter("foo", "bar2")
}
}
headers {
header(authorization(), "secret")
header(authorization(), "secret2")
}
body(foo: "bar", baz: 5)
}
response {
status 200
headers {
header(authorization(), "foo ${fromRequest().header(authorization())} bar")
}
body(
url: fromRequest().url(),
param: fromRequest().query("foo"),
paramIndex: fromRequest().query("foo", 1),
authorization: fromRequest().header("Authorization"),
authorization2: fromRequest().header("Authorization", 1),
fullBody: fromRequest().body(),
responseFoo: fromRequest().body('$.foo'),
responseBaz: fromRequest().body('$.baz'),
responseBaz2: "Bla bla ${fromRequest().body('$.foo')} bla bla"
)
}
}
运行JUnit测试代码将导致创建一个或多或少这样的测试
// given:
MockMvcRequestSpecification request = given()
.header("Authorization", "secret")
.header("Authorization", "secret2")
.body("{\"foo\":\"bar\",\"baz\":5}");
// when:
ResponseOptions response = given().spec(request)
.queryParam("foo","bar")
.queryParam("foo","bar2")
.get("/api/v1/xxxx");
// then:
assertThat(response.statusCode()).isEqualTo(200);
assertThat(response.header("Authorization")).isEqualTo("foo secret bar");
// and:
DocumentContext parsedJson = JsonPath.parse(response.getBody().asString());
assertThatJson(parsedJson).field("url").isEqualTo("/api/v1/xxxx");
assertThatJson(parsedJson).field("fullBody").isEqualTo("{\"foo\":\"bar\",\"baz\":5}");
assertThatJson(parsedJson).field("paramIndex").isEqualTo("bar2");
assertThatJson(parsedJson).field("responseFoo").isEqualTo("bar");
assertThatJson(parsedJson).field("authorization2").isEqualTo("secret2");
assertThatJson(parsedJson).field("responseBaz").isEqualTo(5);
assertThatJson(parsedJson).field("responseBaz2").isEqualTo("Bla bla bar bla bla");
assertThatJson(parsedJson).field("param").isEqualTo("bar");
assertThatJson(parsedJson).field("authorization").isEqualTo("secret");
您可以看到请求中的元素在响应中已被正确引用。
生成的WireMock存根将看起来或多或少是这样的:
{
"request" : {
"urlPath" : "/api/v1/xxxx",
"method" : "POST",
"headers" : {
"Authorization" : {
"equalTo" : "secret2"
}
},
"queryParameters" : {
"foo" : {
"equalTo" : "bar2"
}
},
"bodyPatterns" : [ {
"matchesJsonPath" : "$[?(@.baz == 5)]"
}, {
"matchesJsonPath" : "$[?(@.foo == 'bar')]"
} ]
},
"response" : {
"status" : 200,
"body" : "{\"url\":\"{{{request.url}}}\",\"param\":\"{{{request.query.foo.[0]}}}\",\"paramIndex\":\"{{{request.query.foo.[1]}}}\",\"authorization\":\"{{{request.headers.Authorization.[0]}}}\",\"authorization2\":\"{{{request.headers.Authorization.[1]}}}\",\"fullBody\":\"{{{escapejsonbody}}}\",\"responseFoo\":\"{{{jsonpath this '$.foo'}}}\",\"responseBaz\":{{{jsonpath this '$.baz'}}} ,\"responseBaz2\":\"Bla bla {{{jsonpath this '$.foo'}}} bla bla\"}",
"headers" : {
"Authorization" : "{{{request.headers.Authorization.[0]}}}"
},
"transformers" : [ "response-template" ]
}
}
因此,发送请求作为合同request部分提出的请求将导致发送以下响应主体
{
"url" : "/api/v1/xxxx?foo=bar&foo=bar2",
"param" : "bar",
"paramIndex" : "bar2",
"authorization" : "secret",
"authorization2" : "secret2",
"fullBody" : "{\"foo\":\"bar\",\"baz\":5}",
"responseFoo" : "bar",
"responseBaz" : 5,
"responseBaz2" : "Bla bla bar bla bla"
}
重要
此功能仅适用于版本大于或等于2.5.1的WireMock。我们正在使用WireMock的response-template响应变压器。它使用Handlebars将Mustache{{{ }}}模板转换成正确的值。另外我们正在注册2个帮助函数。escapejsonbody- 以可嵌入JSON的格式转义请求正文。另一个是jsonpath对于给定的参数知道如何在请求体中查找对象。
匹配部分的动态属性
如果您一直在使用Pact,这似乎很熟悉。很多用户习惯于在身体和设定合约的动态部分之间进行分隔。
这就是为什么你可以从两个不同的部分获利。一个称为stubMatchers,您可以在其中定义应该存在于存根中的动态值。您可以在合同的request或inputMessage部分设置。另一个称为testMatchers,它存在于合同的response或outputMessage方面。
目前,我们仅支持具有以下匹配可能性的基于JSON路径的匹配器。对于stubMatchers:
byEquality()- 通过提供的JSON路径从响应中获取的值需要等于合同中提供的值
byRegex(…)- 通过提供的JSON路径从响应中获取的值需要与正则表达式匹配
byDate()- 通过提供的JSON路径从响应中获取的值需要与ISO Date的正则表达式匹配
byTimestamp()- 通过提供的JSON路径从响应中获取的值需要与ISO DateTime的正则表达式匹配
byTime()- 通过提供的JSON路径从响应中获取的值需要匹配ISO时间的正则表达式
对于testMatchers:
byEquality()- 通过提供的JSON路径从响应中获取的值需要等于合同中提供的值
byRegex(…)- 通过提供的JSON路径从响应中获取的值需要与正则表达式匹配
byDate()- 通过提供的JSON路径从响应中获取的值需要与ISO Date的正则表达式匹配
byTimestamp()- 通过提供的JSON路径从响应中获取的值需要匹配ISO DateTime的正则表达式
byTime()- 通过提供的JSON路径从响应中获取的值需要匹配ISO时间的正则表达式
byType()- 通过提供的JSON路径从响应中获取的值需要与合同中的响应正文中定义的类型相同。byType可以关闭,您可以设置minOccurrence和maxOccurrence。这样你可以断定集合的大小。
byCommand(…)- 通过提供的JSON路径从响应中获取的值将作为您提供的自定义方法的输入传递。例如byCommand('foo($it)')将导致调用匹配JSON路径的值将被通过的foo方法。
我们来看看下面的例子:
Contract contractDsl = Contract.make {
request {
method 'GET'
urlPath '/get'
body([
duck: 123,
alpha: "abc",
number: 123,
aBoolean: true,
date: "2017-01-01",
dateTime: "2017-01-01T01:23:45",
time: "01:02:34",
valueWithoutAMatcher: "foo",
valueWithTypeMatch: "string"
])
stubMatchers {
jsonPath('$.duck', byRegex("[0-9]{3}"))
jsonPath('$.duck', byEquality())
jsonPath('$.alpha', byRegex(onlyAlphaUnicode()))
jsonPath('$.alpha', byEquality())
jsonPath('$.number', byRegex(number()))
jsonPath('$.aBoolean', byRegex(anyBoolean()))
jsonPath('$.date', byDate())
jsonPath('$.dateTime', byTimestamp())
jsonPath('$.time', byTime())
}
headers {
contentType(applicationJson())
}
}
response {
status 200
body([
duck: 123,
alpha: "abc",
number: 123,
aBoolean: true,
date: "2017-01-01",
dateTime: "2017-01-01T01:23:45",
time: "01:02:34",
valueWithoutAMatcher: "foo",
valueWithTypeMatch: "string",
valueWithMin: [
1,2,3
],
valueWithMax: [
1,2,3
],
valueWithMinMax: [
1,2,3
],
valueWithMinEmpty: [],
valueWithMaxEmpty: [],
])
testMatchers {
// asserts the jsonpath value against manual regex
jsonPath('$.duck', byRegex("[0-9]{3}"))
// asserts the jsonpath value against the provided value
jsonPath('$.duck', byEquality())
// asserts the jsonpath value against some default regex
jsonPath('$.alpha', byRegex(onlyAlphaUnicode()))
jsonPath('$.alpha', byEquality())
jsonPath('$.number', byRegex(number()))
jsonPath('$.aBoolean', byRegex(anyBoolean()))
// asserts vs inbuilt time related regex
jsonPath('$.date', byDate())
jsonPath('$.dateTime', byTimestamp())
jsonPath('$.time', byTime())
// asserts that the resulting type is the same as in response body
jsonPath('$.valueWithTypeMatch', byType())
jsonPath('$.valueWithMin', byType {
// results in verification of size of array (min 1)
minOccurrence(1)
})
jsonPath('$.valueWithMax', byType {
// results in verification of size of array (max 3)
maxOccurrence(3)
})
jsonPath('$.valueWithMinMax', byType {
// results in verification of size of array (min 1 & max 3)
minOccurrence(1)
maxOccurrence(3)
})
jsonPath('$.valueWithMinEmpty', byType {
// results in verification of size of array (min 0)
minOccurrence(0)
})
jsonPath('$.valueWithMaxEmpty', byType {
// results in verification of size of array (max 0)
maxOccurrence(0)
})
// will execute a method `assertThatValueIsANumber`
jsonPath('$.duck', byCommand('assertThatValueIsANumber($it)'))
}
headers {
contentType(applicationJson())
}
}
}
在这个例子中,我们在匹配器部分提供合同的动态部分。对于请求部分,您可以看到对于所有字段,但是valueWithoutAMatcher我们正在明确地设置我们希望存根包含的正则表达式的值。对于valueWithoutAMatcher,验证将以与不使用匹配器相同的方式进行 - 在这种情况下,测试将执行相等检查。
对于testMatchers部分的响应方面,我们以类似的方式定义所有的动态部分。唯一的区别是我们也有byType匹配器。在这种情况下,我们正在检查4个字段,我们正在验证测试的响应是否具有一个值,其JSON路径与给定字段匹配的类型与响应主体中定义的相同,
对于$.valueWithTypeMatch- 我们只是检查类型是否相同
对于$.valueWithMin- 我们正在检查类型,并声明大小是否大于或等于最小出现次数
对于$.valueWithMax- 我们正在检查类型,并声明大小是否小于或等于最大值
对于$.valueWithMinMax- 我们正在检查类型,并确定大小是否在最小和最大值之间
所得到的测试或多或少会看起来像这样(请注意,我们将自动生成的断言与匹配器与and部分分开):
// given:
MockMvcRequestSpecification request = given()
.header("Content-Type", "application/json")
.body("{\"duck\":123,\"alpha\":\"abc\",\"number\":123,\"aBoolean\":true,\"date\":\"2017-01-01\",\"dateTime\":\"2017-01-01T01:23:45\",\"time\":\"01:02:34\",\"valueWithoutAMatcher\":\"foo\",\"valueWithTypeMatch\":\"string\"}");
// when:
ResponseOptions response = given().spec(request)
.get("/get");
// then:
assertThat(response.statusCode()).isEqualTo(200);
assertThat(response.header("Content-Type")).matches("application/json.*");
// and:
DocumentContext parsedJson = JsonPath.parse(response.getBody().asString());
assertThatJson(parsedJson).field("valueWithoutAMatcher").isEqualTo("foo");
// and:
assertThat(parsedJson.read("$.duck", String.class)).matches("[0-9]{3}");
assertThat(parsedJson.read("$.duck", Integer.class)).isEqualTo(123);
assertThat(parsedJson.read("$.alpha", String.class)).matches("[\\p{L}]*");
assertThat(parsedJson.read("$.alpha", String.class)).isEqualTo("abc");
assertThat(parsedJson.read("$.number", String.class)).matches("-?\\d*(\\.\\d+)?");
assertThat(parsedJson.read("$.aBoolean", String.class)).matches("(true|false)");
assertThat(parsedJson.read("$.date", String.class)).matches("(\\d\\d\\d\\d)-(0[1-9]|1[012])-(0[1-9]|[12][0-9]|3[01])");
assertThat(parsedJson.read("$.dateTime", String.class)).matches("([0-9]{4})-(1[0-2]|0[1-9])-(3[01]|0[1-9]|[12][0-9])T(2[0-3]|[01][0-9]):([0-5][0-9]):([0-5][0-9])");
assertThat(parsedJson.read("$.time", String.class)).matches("(2[0-3]|[01][0-9]):([0-5][0-9]):([0-5][0-9])");
assertThat((Object) parsedJson.read("$.valueWithTypeMatch")).isInstanceOf(java.lang.String.class);
assertThat((Object) parsedJson.read("$.valueWithMin")).isInstanceOf(java.util.List.class);
assertThat(parsedJson.read("$.valueWithMin", java.util.Collection.class)).hasSizeGreaterThanOrEqualTo(1);
assertThat((Object) parsedJson.read("$.valueWithMax")).isInstanceOf(java.util.List.class);
assertThat(parsedJson.read("$.valueWithMax", java.util.Collection.class)).hasSizeLessThanOrEqualTo(3);
assertThat((Object) parsedJson.read("$.valueWithMinMax")).isInstanceOf(java.util.List.class);
assertThat(parsedJson.read("$.valueWithMinMax", java.util.Collection.class)).hasSizeBetween(1, 3);
assertThat((Object) parsedJson.read("$.valueWithMinEmpty")).isInstanceOf(java.util.List.class);
assertThat(parsedJson.read("$.valueWithMinEmpty", java.util.Collection.class)).hasSizeGreaterThanOrEqualTo(0);
assertThat((Object) parsedJson.read("$.valueWithMaxEmpty")).isInstanceOf(java.util.List.class);
assertThat(parsedJson.read("$.valueWithMaxEmpty", java.util.Collection.class)).hasSizeLessThanOrEqualTo(0);
assertThatValueIsANumber(parsedJson.read("$.duck"));
和WireMock这样的stub:
'''
{
"request" : {
"urlPath" : "/get",
"method" : "GET",
"headers" : {
"Content-Type" : {
"matches" : "application/json.*"
}
},
"bodyPatterns" : [ {
"matchesJsonPath" : "$[?(@.valueWithoutAMatcher == 'foo')]"
}, {
"matchesJsonPath" : "$[?(@.valueWithTypeMatch == 'string')]"
}, {
"matchesJsonPath" : "$.list.some.nested[?(@.anothervalue == 4)]"
}, {
"matchesJsonPath" : "$.list.someother.nested[?(@.anothervalue == 4)]"
}, {
"matchesJsonPath" : "$.list.someother.nested[?(@.json == 'with value')]"
}, {
"matchesJsonPath" : "$[?(@.duck =~ /([0-9]{3})/)]"
}, {
"matchesJsonPath" : "$[?(@.duck == 123)]"
}, {
"matchesJsonPath" : "$[?(@.alpha =~ /([\\\\p{L}]*)/)]"
}, {
"matchesJsonPath" : "$[?(@.alpha == 'abc')]"
}, {
"matchesJsonPath" : "$[?(@.number =~ /(-?\\\\d*(\\\\.\\\\d+)?)/)]"
}, {
"matchesJsonPath" : "$[?(@.aBoolean =~ /((true|false))/)]"
}, {
"matchesJsonPath" : "$[?(@.date =~ /((\\\\d\\\\d\\\\d\\\\d)-(0[1-9]|1[012])-(0[1-9]|[12][0-9]|3[01]))/)]"
}, {
"matchesJsonPath" : "$[?(@.dateTime =~ /(([0-9]{4})-(1[0-2]|0[1-9])-(3[01]|0[1-9]|[12][0-9])T(2[0-3]|[01][0-9]):([0-5][0-9]):([0-5][0-9]))/)]"
}, {
"matchesJsonPath" : "$[?(@.time =~ /((2[0-3]|[01][0-9]):([0-5][0-9]):([0-5][0-9]))/)]"
}, {
"matchesJsonPath" : "$.list.some.nested[?(@.json =~ /(.*)/)]"
} ]
},
"response" : {
"status" : 200,
"body" : "{\\"duck\\":123,\\"alpha\\":\\"abc\\",\\"number\\":123,\\"aBoolean\\":true,\\"date\\":\\"2017-01-01\\",\\"dateTime\\":\\"2017-01-01T01:23:45\\",\\"time\\":\\"01:02:34\\",\\"valueWithoutAMatcher\\":\\"foo\\",\\"valueWithTypeMatch\\":\\"string\\",\\"valueWithMin\\":[1,2,3],\\"valueWithMax\\":[1,2,3],\\"valueWithMinMax\\":[1,2,3]}",
"headers" : {
"Content-Type" : "application/json"
}
}
}
'''
JAX-RS支持
我们支持JAX-RS 2 Client API。基类需要定义protected WebTarget webTarget和服务器初始化,现在唯一的选择如何测试JAX-RS API是启动一个Web服务器。
使用身体的请求需要设置内容类型,否则将使用application/octet-stream。
为了使用JAX-RS模式,请使用以下设置:
testMode === 'JAXRSCLIENT'
生成测试API的示例:
'''
// when:
Response response = webTarget
.path("/users")
.queryParam("limit", "10")
.queryParam("offset", "20")
.queryParam("filter", "email")
.queryParam("sort", "name")
.queryParam("search", "55")
.queryParam("age", "99")
.queryParam("name", "Denis.Stepanov")
.queryParam("email", "[email protected]")
.request()
.method("GET");
String responseAsString = response.readEntity(String.class);
// then:
assertThat(response.getStatus()).isEqualTo(200);
// and:
DocumentContext parsedJson = JsonPath.parse(responseAsString);
assertThatJson(parsedJson).field("property1").isEqualTo("a");
'''
异步支持
如果您在服务器端使用异步通信(您的控制器正在返回Callable,DeferredResult等等,然后在合同中您必须在response部分中提供async()方法。 :
org.springframework.cloud.contract.spec.Contract.make {
request {
method GET()
url '/get'
}
response {
status 200
body 'Passed'
async()
}
}
使用上下文路径
Spring Cloud Contract支持上下文路径。
重要
为了完全支持上下文路径,唯一改变的是在PRODUCER端的切换。自动生成测试需要使用EXPLICIT模式。
消费者方面保持不变,为了让生成的测试通过,您必须切换EXPLICIT模式。
Maven的
org.springframework.cloud
spring-cloud-contract-maven-plugin
${spring-cloud-contract.version}
true
EXPLICIT
摇篮
contracts {
testMode = 'EXPLICIT'
}
这样就可以生成不使用MockMvc的测试。这意味着您正在生成真实的请求,您需要设置生成的测试的基类以在真正的套接字上工作。
让我们想象下面的合同:
org.springframework.cloud.contract.spec.Contract.make {
request {
method 'GET'
url '/my-context-path/url'
}
response {
status 200
}
}
以下是一个如何设置基类和Rest Assured的示例,以使所有操作都正常工作。
import com.jayway.restassured.RestAssured;
import org.junit.Before;
import org.springframework.boot.context.embedded.LocalServerPort;
import org.springframework.boot.test.context.SpringBootTest;
@SpringBootTest(classes = ContextPathTestingBaseClass.class, webEnvironment = SpringBootTest.WebEnvironment.RANDOM_PORT)
class ContextPathTestingBaseClass {
@LocalServerPort int port;
@Before
public void setup() {
RestAssured.baseURI = "http://localhost";
RestAssured.port = this.port;
}
}
这样一来:
您自动生成测试中的所有请求都将发送到包含上下文路径的实际端点(例如/my-context-path/url)
您的合同反映出您具有上下文路径,因此您生成的存根也将具有该信息(例如,在存根中您将看到您也调用了/my-context-path/url)
消息传递顶级元素
消息传递的DSL与重点在HTTP上的DSL有点不同。
由方法触发的输出
可以通过调用方法来触发输出消息(例如,调度程序启动并发送消息)
def dsl = Contract.make {
// Human readable description
description 'Some description'
// Label by means of which the output message can be triggered
label 'some_label'
// input to the contract
input {
// the contract will be triggered by a method
triggeredBy('bookReturnedTriggered()')
}
// output message of the contract
outputMessage {
// destination to which the output message will be sent
sentTo('output')
// the body of the output message
body('''{ "bookName" : "foo" }''')
// the headers of the output message
headers {
header('BOOK-NAME', 'foo')
}
}
}
在这种情况下,如果将执行一个称为bookReturnedTriggered的方法,输出消息将被发送到output。在消息发布者的一方,我们将生成一个测试,该测试将调用该方法来触发该消息。在消费者端,您可以使用some_label触发消息。
由消息触发的输出
可以通过接收消息来触发输出消息。
def dsl = Contract.make {
description 'Some Description'
label 'some_label'
// input is a message
input {
// the message was received from this destination
messageFrom('input')
// has the following body
messageBody([
bookName: 'foo'
])
// and the following headers
messageHeaders {
header('sample', 'header')
}
}
outputMessage {
sentTo('output')
body([
bookName: 'foo'
])
headers {
header('BOOK-NAME', 'foo')
}
}
}
在这种情况下,如果input目的地收到正确的消息,则输出消息将被发送到output。在消息发布者的一方,我们将生成一个测试,它将输入消息发送到定义的目的地。在消费者端,您可以向输入目的地发送消息,也可以使用some_label触发消息。
消费者/生产者
在HTTP中,您有一个概念client/stub and `server/test符号。您也可以在消息中使用它们,但是我们还提供了下面提供的consumer和produer方法(请注意,您可以使用$或value方法来提供consumer和producer部分)
Contract.make {
label 'some_label'
input {
messageFrom value(consumer('jms:output'), producer('jms:input'))
messageBody([
bookName: 'foo'
])
messageHeaders {
header('sample', 'header')
}
}
outputMessage {
sentTo $(consumer('jms:input'), producer('jms:output'))
body([
bookName: 'foo'
])
}
}
一个文件中的多个合同
可以在一个文件中定义多个合同。这样的合同的例子可以这样看
import org.springframework.cloud.contract.spec.Contract
[
Contract.make {
name("should post a user")
request {
method 'POST'
url('/users/1')
}
response {
status 200
}
},
Contract.make {
request {
method 'POST'
url('/users/2')
}
response {
status 200
}
}
]
在这个例子中,一个合同有name字段,另一个没有。这将导致生成两个或多或少这样的测试:
package org.springframework.cloud.contract.verifier.tests.com.hello;
import com.example.TestBase;
import com.jayway.jsonpath.DocumentContext;
import com.jayway.jsonpath.JsonPath;
import com.jayway.restassured.module.mockmvc.specification.MockMvcRequestSpecification;
import com.jayway.restassured.response.ResponseOptions;
import org.junit.Test;
import static com.jayway.restassured.module.mockmvc.RestAssuredMockMvc.*;
import static com.toomuchcoding.jsonassert.JsonAssertion.assertThatJson;
import static org.assertj.core.api.Assertions.assertThat;
public class V1Test extends TestBase {
@Test
public void validate_should_post_a_user() throws Exception {
// given:
MockMvcRequestSpecification request = given();
// when:
ResponseOptions response = given().spec(request)
.post("/users/1");
// then:
assertThat(response.statusCode()).isEqualTo(200);
}
@Test
public void validate_withList_1() throws Exception {
// given:
MockMvcRequestSpecification request = given();
// when:
ResponseOptions response = given().spec(request)
.post("/users/2");
// then:
assertThat(response.statusCode()).isEqualTo(200);
}
}
请注意,对于具有name字段的合同,生成的测试方法名为validate_should_post_a_user。对于没有名称的人validate_withList_1。它对应于文件WithList.groovy的名称和列表中的合同索引。
生成的存根将看起来像这样
should post a user.json
1_WithList.json
您可以看到第一个文件从合同中获取了name参数。第二个获得了以索引为前缀的合同文件WithList.groovy的名称(在这种情况下,合同在文件中的合同列表中具有索引1)。
小费
正如你可以看到,如果您的合同名称更好,那么您的测试更有意义。
定制
扩展DSL
可以向DSL提供自己的功能。此功能的关键要求是保持静态兼容性。下面你可以看到一个例子:
创建具有可重用类的JAR
在DSL中引用这些类
这里可以找到完整的例子。
普通JAR
下面你可以找到我们将在DSL中重用的三个类。
PatternUtils包含消费者和制作者使用的功能。
package com.example;
import java.util.regex.Pattern;
/**
* If you want to use {@link Pattern} directly in your tests
* then you can create a class resembling this one. It can
* contain all the {@link Pattern} you want to use in the DSL.
*
*
* {@code
* request {
* body(
* [ age: $(c(PatternUtils.oldEnough()))]
* )
* }
*
*
* Notice that we're using both {@code $()} for dynamic values
* and {@code c()} for the consumer side.
*
* @author Marcin Grzejszczak
*/
public class PatternUtils {
public static String tooYoung() {
return "[0-1][0-9]";
}
public static Pattern oldEnough() {
return Pattern.compile("[2-9][0-9]");
}
public static Pattern anyName() {
return Pattern.compile("[a-zA-Z]+");
}
/**
* Makes little sense but it's just an example ;)
*/
public static Pattern ok() {
return Pattern.compile("OK");
}
}
ConsumerUtils包含由使用功能的消费者。
package com.example;
import org.springframework.cloud.contract.spec.internal.ClientDslProperty;
import org.springframework.cloud.contract.spec.internal.DslProperty;
/**
* DSL Properties passed to the DSL from the consumer's perspective.
* That means that on the input side {@code Request} for HTTP
* or {@code Input} for messaging you can have a regular expression.
* On the {@code Response} for HTTP or {@code Output} for messaging
* you have to have a concrete value.
*
* @author Marcin Grzejszczak
*/
public class ConsumerUtils {
/**
* Consumer side property. By using the {@link ClientDslProperty}
* you can omit most of boilerplate code from the perspective
* of dynamic values. Example
*
*
* {@code
* request {
* body(
* [ age: $(ConsumerUtils.oldEnough())]
* )
* }
*
*
* That way the consumer side value of age field will be
* a regular expression and the producer side will be generated.
*
* @author Marcin Grzejszczak
*/
public static ClientDslProperty oldEnough() {
return new ClientDslProperty(PatternUtils.oldEnough());
}
/**
* Consumer side property. By using the {@link ClientDslProperty}
* you can omit most of boilerplate code from the perspective
* of dynamic values. Example
*
*
* {@code
* request {
* body(
* [ name: $(ConsumerUtils.anyName())]
* )
* }
*
*
* That way the consumer will be a regular expression and the
* producer side value will be equal to {@code marcin}
*/
public static DslProperty anyName() {
return new DslProperty<>(PatternUtils.anyName(), "marcin");
}
}
ProducerUtils包含由使用的功能制片人。
package com.example;
import org.springframework.cloud.contract.spec.internal.ServerDslProperty;
/**
* DSL Properties passed to the DSL from the producer's perspective.
* That means that on the input side {@code Request} for HTTP
* or {@code Input} for messaging you have to have a concrete value.
* On the {@code Response} for HTTP or {@code Output} for messaging
* you can have a regular expression.
*
* @author Marcin Grzejszczak
*/
public class ProducerUtils {
/**
* Producer side property. By using the {@link ProducerUtils}
* you can omit most of boilerplate code from the perspective
* of dynamic values. Example
*
*
* {@code
* response {
* body(
* [ status: $(ProducerUtils.ok())]
* )
* }
*
*
* That way the producer side value of age field will be
* a regular expression and the consumer side will be generated.
*/
public static ServerDslProperty ok() {
return new ServerDslProperty(PatternUtils.ok());
}
}
将依赖项添加到项目中
为了使插件和IDE能够引用常见的JAR类,您需要将依赖关系传递给您的项目。
测试依赖项目的依赖关系
首先将常见的jar依赖项添加为测试依赖关系。这样,由于您的合同文件在测试资源路径中可用,所以公用的jar类将自动显示在您的Groovy文件中。
Maven的
com.example
beer-common
${project.version}
test
摇篮
testCompile("com.example:beer-common:0.0.1-SNAPSHOT")
测试插件依赖关系
现在你必须添加插件的依赖关系,以便在运行时重用。
Maven的
org.springframework.cloud
spring-cloud-contract-maven-plugin
${spring-cloud-contract.version}
true
com.example
org.springframework.cloud
spring-cloud-contract-verifier
${spring-cloud-contract.version}
com.example
beer-common
${project.version}
compile
摇篮
classpath "com.example:beer-common:0.0.1-SNAPSHOT"
在DSL中引用类
现在您可以参考DSL中的课程。例:
package contracts.beer.rest
import org.springframework.cloud.contract.spec.Contract
import static com.example.ConsumerUtils.oldEnough
import static com.example.ProducerUtils.ok
Contract.make {
request {
description("""
Represents a successful scenario of getting a beer
given:
client is old enough
when:
he applies for a beer
then:
we'll grant him the beer
""")
method 'POST'
url '/check'
body(
age: $(oldEnough())
)
headers {
contentType(applicationJson())
}
}
response {
status 200
body("""
{
"status": "${value(ok())}"
}
""")
headers {
contentType(applicationJson())
}
}
}
可插拔架构
在某些情况下,您将合同定义为其他格式,如YAML,RAML或PACT。另一方面,您希望从测试和存根生成中获利。添加自己的任何一个实现是很容易的。此外,您还可以自定义测试生成的方式(例如,您可以为其他语言生成测试),并且可以对存根生成执行相同操作(可为其他存根http服务器实现生成存根)。
定制合同转换器
我们假设您的合同是用YAML文件写成的:
request:
url: /foo
method: PUT
headers:
foo: bar
body:
foo: bar
response:
status: 200
headers:
foo2: bar
body:
foo2: bar
感谢界面
package org.springframework.cloud.contract.spec
/**
* Converter to be used to convert FROM {@link File} TO {@link Contract}
* and from {@link Contract} to {@code T}
*
* @param - type to which we want to convert the contract
*
* @author Marcin Grzejszczak
* @since 1.1.0
*/
interface ContractConverter {
/**
* Should this file be accepted by the converter. Can use the file extension
* to check if the conversion is possible.
*
* @param file - file to be considered for conversion
* @return - {@code true} if the given implementation can convert the file
*/
boolean isAccepted(File file)
/**
* Converts the given {@link File} to its {@link Contract} representation
*
* @param file - file to convert
* @return - {@link Contract} representation of the file
*/
Collection convertFrom(File file)
/**
* Converts the given {@link Contract} to a {@link T} representation
*
* @param contract - the parsed contract
* @return - {@link T} the type to which we do the conversion
*/
T convertTo(Collection contract)
}
您可以注册自己的合同结构转换器的实现。您的实现需要说明开始转换的条件。此外,您必须定义如何以两种方式执行转换。
重要
创建实施后,您必须创建一个/META-INF/spring.factories文件,您可以在其中提供实施的完全限定名称。
spring.factories文件的示例
# Converters
org.springframework.cloud.contract.spec.ContractConverter=\
org.springframework.cloud.contract.verifier.converter.YamlContractConverter
和YAML实现
package org.springframework.cloud.contract.verifier.converter
import groovy.transform.CompileStatic
import org.springframework.cloud.contract.spec.Contract
import org.springframework.cloud.contract.spec.ContractConverter
import org.springframework.cloud.contract.spec.internal.Headers
import org.yaml.snakeyaml.Yaml
/**
* Simple converter from and to a {@link YamlContract} to a collection of {@link Contract}
*/
@CompileStatic
class YamlContractConverter implements ContractConverter> {
@Override
public boolean isAccepted(File file) {
String name = file.getName()
return name.endsWith(".yml") || name.endsWith(".yaml")
}
@Override
public Collection convertFrom(File file) {
try {
YamlContract yamlContract = new Yaml().loadAs(new FileInputStream(file), YamlContract.class)
return [Contract.make {
request {
method(yamlContract?.request?.method)
url(yamlContract?.request?.url)
headers {
yamlContract?.request?.headers?.each { String key, Object value ->
header(key, value)
}
}
body(yamlContract?.request?.body)
}
response {
status(yamlContract?.response?.status)
headers {
yamlContract?.response?.headers?.each { String key, Object value ->
header(key, value)
}
}
body(yamlContract?.response?.body)
}
}]
}
catch (FileNotFoundException e) {
throw new IllegalStateException(e)
}
}
@Override
public List convertTo(Collection contracts) {
return contracts.collect { Contract contract ->
YamlContract yamlContract = new YamlContract()
yamlContract.request.with {
method = contract?.request?.method?.clientValue
url = contract?.request?.url?.clientValue
headers = (contract?.request?.headers as Headers)?.asStubSideMap()
body = contract?.request?.body?.clientValue as Map
}
yamlContract.response.with {
status = contract?.response?.status?.clientValue as Integer
headers = (contract?.response?.headers as Headers)?.asStubSideMap()
body = contract?.response?.body?.clientValue as Map
}
return yamlContract
}
}
}
契约转换器
Spring Cloud Contract提供了协议代表合同的开箱即用支持。换句话说,而不是使用Groovy DSL,您可以使用Pact文件。在本节中,我们将介绍如何为您的项目添加此类支持。
契约契约
我们将在下面的一个契约契约的例子中工作。我们将此文件放在src/test/resources/contracts文件夹下。
{
"provider": {
"name": "Provider"
},
"consumer": {
"name": "Consumer"
},
"interactions": [
{
"description": "",
"request": {
"method": "PUT",
"path": "/fraudcheck",
"headers": {
"Content-Type": "application/vnd.fraud.v1+json"
},
"body": {
"clientId": "1234567890",
"loanAmount": 99999
},
"matchingRules": {
"$.body.clientId": {
"match": "regex",
"regex": "[0-9]{10}"
}
}
},
"response": {
"status": 200,
"headers": {
"Content-Type": "application/vnd.fraud.v1+json;charset=UTF-8"
},
"body": {
"fraudCheckStatus": "FRAUD",
"rejectionReason": "Amount too high"
},
"matchingRules": {
"$.body.fraudCheckStatus": {
"match": "regex",
"regex": "FRAUD"
}
}
}
}
],
"metadata": {
"pact-specification": {
"version": "2.0.0"
},
"pact-jvm": {
"version": "2.4.18"
}
}
}
生产者契约
在生产者方面,您可以添加两个附加依赖关系的插件配置。一个是Spring Cloud Contract Pact支持,另一个表示您正在使用的当前Pact版本。
Maven的
org.springframework.cloud
spring-cloud-contract-maven-plugin
${spring-cloud-contract.version}
true
com.example.fraud
org.springframework.cloud
spring-cloud-contract-spec-pact
${spring-cloud-contract.version}
au.com.dius
pact-jvm-model
2.4.18
摇篮
classpath "org.springframework.cloud:spring-cloud-contract-spec-pact:${findProperty('verifierVersion') ?: verifierVersion}"
classpath 'au.com.dius:pact-jvm-model:2.4.18'
当您执行应用程序的构建时,将会产生一个或多或少的这样的测试
@Test
public void validate_shouldMarkClientAsFraud() throws Exception {
// given:
MockMvcRequestSpecification request = given()
.header("Content-Type", "application/vnd.fraud.v1+json")
.body("{\"clientId\":\"1234567890\",\"loanAmount\":99999}");
// when:
ResponseOptions response = given().spec(request)
.put("/fraudcheck");
// then:
assertThat(response.statusCode()).isEqualTo(200);
assertThat(response.header("Content-Type")).isEqualTo("application/vnd.fraud.v1+json;charset=UTF-8");
// and:
DocumentContext parsedJson = JsonPath.parse(response.getBody().asString());
assertThatJson(parsedJson).field("rejectionReason").isEqualTo("Amount too high");
// and:
assertThat(parsedJson.read("$.fraudCheckStatus", String.class)).matches("FRAUD");
}
并且这样的存根看起来像这样
{
"uuid" : "996ae5ae-6834-4db6-8fac-358ca187ab62",
"request" : {
"url" : "/fraudcheck",
"method" : "PUT",
"headers" : {
"Content-Type" : {
"equalTo" : "application/vnd.fraud.v1+json"
}
},
"bodyPatterns" : [ {
"matchesJsonPath" : "$[?(@.loanAmount == 99999)]"
}, {
"matchesJsonPath" : "$[?(@.clientId =~ /([0-9]{10})/)]"
} ]
},
"response" : {
"status" : 200,
"body" : "{\"fraudCheckStatus\":\"FRAUD\",\"rejectionReason\":\"Amount too high\"}",
"headers" : {
"Content-Type" : "application/vnd.fraud.v1+json;charset=UTF-8"
}
}
}
消费者契约
在生产者方面,您可以添加项目依赖关系两个附加依赖关系。一个是Spring Cloud Contract Pact支持,另一个表示您正在使用的当前Pact版本。
Maven的
org.springframework.cloud
spring-cloud-contract-spec-pact
test
au.com.dius
pact-jvm-model
2.4.18
test
摇篮
testCompile "org.springframework.cloud:spring-cloud-contract-spec-pact"
testCompile 'au.com.dius:pact-jvm-model:2.4.18'
定制测试发生器
如果您想为Java生成不同语言的测试,或者您不满意我们为您建立Java测试的方式,那么您可以注册自己的实现来做到这一点。
感谢界面
package org.springframework.cloud.contract.verifier.builder
import org.springframework.cloud.contract.verifier.config.ContractVerifierConfigProperties
import org.springframework.cloud.contract.verifier.file.ContractMetadata
/**
* Builds a single test.
*
* @since 1.1.0
*/
interface SingleTestGenerator {
/**
* Creates contents of a single test class in which all test scenarios from
* the contract metadata should be placed.
*
* @param properties - properties passed to the plugin
* @param listOfFiles - list of parsed contracts with additional metadata
* @param className - the name of the generated test class
* @param classPackage - the name of the package in which the test class should be stored
* @param includedDirectoryRelativePath - relative path to the included directory
* @return contents of a single test class
*/
String buildClass(ContractVerifierConfigProperties properties, Collection listOfFiles,
String className, String classPackage, String includedDirectoryRelativePath)
/**
* Extension that should be appended to the generated test class. E.g. {@code .java} or {@code .php}
*
* @param properties - properties passed to the plugin
*/
String fileExtension(ContractVerifierConfigProperties properties)
}
您可以注册自己的生成测试的实现。再次提供一个合适的spring.factories文件就足够了。例:
org.springframework.cloud.contract.verifier.builder.SingleTestGenerator=/
com.example.MyGenerator
自定义存根发生器
如果要为WireMock生成其他存根服务器的存根,就可以插入您自己的此接口的实现:
package org.springframework.cloud.contract.verifier.converter
import groovy.transform.CompileStatic
import org.springframework.cloud.contract.spec.Contract
import org.springframework.cloud.contract.verifier.file.ContractMetadata
/**
* Converts contracts into their stub representation.
*
* @since 1.1.0
*/
@CompileStatic
interface StubGenerator {
/**
* Returns {@code true} if the converter can handle the file to convert it into a stub.
*/
boolean canHandleFileName(String fileName)
/**
* Returns the collection of converted contracts into stubs. One contract can
* result in multiple stubs.
*/
Map convertContents(String rootName, ContractMetadata content)
/**
* Returns the name of the converted stub file. If you have multiple contracts
* in a single file then a prefix will be added to the generated file. If you
* provide the {@link Contract#name} field then that field will override the
* generated file name.
*
* Example: name of file with 2 contracts is {@code foo.groovy}, it will be
* converted by the implementation to {@code foo.json}. The recursive file
* converter will create two files {@code 0_foo.json} and {@code 1_foo.json}
*/
String generateOutputFileNameForInput(String inputFileName)
}
您可以注册自己的生成存根的实现。再次提供一个合适的spring.factories文件就足够了。例:
# Stub converters
org.springframework.cloud.contract.verifier.converter.StubGenerator=\
org.springframework.cloud.contract.verifier.wiremock.DslToWireMockClientConverter
默认实现是WireMock存根生成。
小费
您可以提供多个存根生成器实现。这样,例如从单个DSL作为输入,您可以例如生成WireMock存根和Pact文件!
自定义Stub Runner
如果您决定使用自定义存根生成器,则还需要使用不同的存根提供程序来运行存根的自定义方式。
让我们假设您正在使用Moco来构建您的存根。你写了一个正确的存根生成器,你的存根被放在一个JAR文件中。
为了Stub Runner知道如何运行存根,您必须定义一个自定义的HTTP Stub服务器实现。它可以看起来像这样:
package org.springframework.cloud.contract.stubrunner.provider.moco
import com.github.dreamhead.moco.bootstrap.arg.HttpArgs
import com.github.dreamhead.moco.runner.JsonRunner
import org.springframework.cloud.contract.stubrunner.HttpServerStub
import org.springframework.util.SocketUtils
class MocoHttpServerStub implements HttpServerStub {
private boolean started
private JsonRunner runner
private int port
@Override
int port() {
if (!isRunning()) {
return -1
}
return port
}
@Override
boolean isRunning() {
return started
}
@Override
HttpServerStub start() {
return start(SocketUtils.findAvailableTcpPort())
}
@Override
HttpServerStub start(int port) {
this.port = port
return this
}
@Override
HttpServerStub stop() {
if (!isRunning()) {
return this
}
this.runner.stop()
return this
}
@Override
HttpServerStub registerMappings(Collection stubFiles) {
List streams = stubFiles.collect { it.newInputStream() }
this.runner = JsonRunner.newJsonRunnerWithStreams(streams,
HttpArgs.httpArgs().withPort(this.port).build())
this.runner.run()
this.started = true
return this
}
@Override
boolean isAccepted(File file) {
return file.name.endsWith(".json")
}
}
并将其注册到您的spring.factories文件中
# Example of a custom HTTP Server Stub
org.springframework.cloud.contract.stubrunner.HttpServerStub=\
org.springframework.cloud.contract.stubrunner.provider.moco.MocoHttpServerStub
这样你就可以使用Moco来运行存根。
重要
如果您不提供任何实现,那么将选择默认的 - 基于WireMock的。如果您提供多个,那么列表中的第一个将被选中。
自定义存根下载器
您可以自定义存根的下载方式。如果您不想以默认方式从Nexus / Artifactory下载JAR,您可以设置自己的实现。下面您可以找到一个Stub Downloader Provider示例,它从classpath的测试资源获取json文件,将它们复制到临时文件,然后将该临时文件夹作为存根的根传递。
package org.springframework.cloud.contract.stubrunner.provider.moco
import org.springframework.cloud.contract.stubrunner.StubConfiguration
import org.springframework.cloud.contract.stubrunner.StubDownloader
import org.springframework.cloud.contract.stubrunner.StubDownloaderBuilder
import org.springframework.cloud.contract.stubrunner.StubRunnerOptions
import org.springframework.core.io.DefaultResourceLoader
import org.springframework.core.io.Resource
import org.springframework.core.io.support.PathMatchingResourcePatternResolver
import java.nio.file.Files
/**
* Poor man's version of taking stubs from classpath. It needs much more
* love and attention to go to the main sources.
*
* @author Marcin Grzejszczak
*/
class ClasspathStubProvider implements StubDownloaderBuilder {
private static final int TEMP_DIR_ATTEMPTS = 10000
@Override
public StubDownloader build(StubRunnerOptions stubRunnerOptions) {
final StubConfiguration configuration = stubRunnerOptions.getDependencies().first()
PathMatchingResourcePatternResolver resolver = new PathMatchingResourcePatternResolver(
new DefaultResourceLoader())
try {
String rootFolder = repoRoot(stubRunnerOptions) ?: "**/" + separatedArtifact(configuration) + "/**/*.json"
Resource[] resources = resolver.getResources(rootFolder)
final File tmp = createTempDir()
tmp.deleteOnExit()
// you'd have to write an impl to maintain the folder structure
// this is just for demo
resources.each { Resource resource ->
Files.copy(resource.getInputStream(), new File(tmp, resource.getFile().getName()).toPath())
}
return new StubDownloader() {
@Override
public Map.Entry downloadAndUnpackStubJar(
StubConfiguration stubConfiguration) {
return new AbstractMap.SimpleEntry(configuration, tmp)
}
}
} catch (IOException e) {
throw new IllegalStateException(e)
}
}
private String repoRoot(StubRunnerOptions stubRunnerOptions) {
switch (stubRunnerOptions.stubRepositoryRoot) {
case { !it }:
return ""
case { String root -> root.endsWith("**/*.json") }:
return stubRunnerOptions.stubRepositoryRoot
default:
return stubRunnerOptions.stubRepositoryRoot + "/**/*.json"
}
}
private String separatedArtifact(StubConfiguration configuration) {
return configuration.getGroupId().replace(".", File.separator) +
File.separator + configuration.getArtifactId()
}
// Taken from Guava
private File createTempDir() {
File baseDir = new File(System.getProperty("java.io.tmpdir"))
String baseName = System.currentTimeMillis() + "-"
for (int counter = 0; counter < TEMP_DIR_ATTEMPTS; counter++) {
File tempDir = new File(baseDir, baseName + counter)
if (tempDir.mkdir()) {
return tempDir
}
}
throw new IllegalStateException(
"Failed to create directory within " + TEMP_DIR_ATTEMPTS + " attempts (tried " + baseName + "0 to " + baseName + (
TEMP_DIR_ATTEMPTS - 1) + ")")
}
}
并将其注册到您的spring.factories文件中
# Example of a custom Stub Downloader Provider
org.springframework.cloud.contract.stubrunner.StubDownloaderBuilder=\
org.springframework.cloud.contract.stubrunner.provider.moco.ClasspathStubProvider
这样你就可以选择一个文件夹与你的存根的来源。
重要
如果您没有提供任何实现,那么将选择从远程备份中下载存根的默认Aether。如果您提供多个,那么列表中的第一个将被选中。
链接
在这里,您可以找到有关Spring Cloud Contract验证器的有趣链接:
Spring Cloud Contract Github Repository
Spring Cloud Contract样本
Spring Cloud Contract文档
Accurest遗产文件
Spring Cloud Contract Stub Runner文档
Spring Cloud Contract Stub Runner消息传递文档
Spring Cloud Contract Gitter
Spring Cloud Contract Maven插件
附录:配置纲要Properties
名称默认描述
encrypt.fail-on-error
true
标记说,如果存在加密或解密错误,进程将失败。
encrypt.key
对称密钥。作为一个更强大的替代方案,考虑使用密钥库。
encrypt.key-store.alias
商店中的钥匙别名
encrypt.key-store.location
密钥存储文件的位置,例如classpath:/keystore.jks。
encrypt.key-store.password
锁定密钥库的密码。
encrypt.key-store.secret
秘密保护密钥(默认为密码相同)。
encrypt.rsa.algorithm
使用RSA算法(DEFAULT或OEAP)。一旦设置不改变它(或现有的密码将不可解密)。
encrypt.rsa.salt
deadbeef
Salt用于加密密文的随机秘密。一旦设置不改变它(或现有的密码将不可解密)。
encrypt.rsa.strong
false
标志表示应该在内部使用“强”AES加密。如果为真,则将GCM算法应用于AES加密字节。默认值为false(在这种情况下使用“标准”CBC代替)。一旦设置不改变它(或现有的密码将不可解密)。
endpoints.bus.enabled
endpoints.bus.id
endpoints.bus.sensitive
endpoints.consul.enabled
endpoints.consul.id
endpoints.consul.sensitive
endpoints.env.post.enabled
true
通过POST将环境更改为/ env。
endpoints.features.enabled
endpoints.features.id
endpoints.features.sensitive
endpoints.pause.enabled
true
启用/暂停端点(发送Lifecycle.stop())。
endpoints.pause.id
endpoints.pause.sensitive
endpoints.refresh.enabled
true
启用/ refresh端点刷新配置并重新初始化刷新作用域bean。
endpoints.refresh.id
endpoints.refresh.sensitive
endpoints.restart.enabled
true
启用/ restart端点重新启动应用程序上下文。
endpoints.restart.id
endpoints.restart.pause-endpoint.enabled
endpoints.restart.pause-endpoint.id
endpoints.restart.pause-endpoint.sensitive
endpoints.restart.resume-endpoint.enabled
endpoints.restart.resume-endpoint.id
endpoints.restart.resume-endpoint.sensitive
endpoints.restart.sensitive
endpoints.restart.timeout
0
endpoints.resume.enabled
true
启用/ resume端点(发送Lifecycle.start())。
endpoints.resume.id
endpoints.resume.sensitive
endpoints.zookeeper.enabled
true
启用/ zookeeper端点来检查zookeeper的状态。
eureka.client.allow-redirects
false
指示服务器是否可以将客户端请求重定向到备份服务器/集群。如果设置为false,服务器将直接处理请求,如果设置为true,则可能会向客户端发送HTTP重定向,并具有新的服务器位置。
eureka.client.availability-zones
获取此实例所在区域的可用性区域列表(用于AWS数据中心)。
更改在运行时在registryFetchIntervalSeconds指定的下一个注册表提取周期中有效。
eureka.client.backup-registry-impl
获取执行BackupRegistry的实现的名称,以便仅在eureka客户端启动时首次将注册表信息作为回退选项提取。
对于需要额外的弹性的注册表信息的应用程序可能需要这一点,而无法运行它们。
eureka.client.cache-refresh-executor-exponential-back-off-bound
10
缓存刷新执行者指数退出相关属性。在发生超时序列的情况下,它是重试延迟的最大乘数值。
eureka.client.cache-refresh-executor-thread-pool-size
2
cacheRefreshExecutor初始化的线程池大小
eureka.client.client-data-accept
EurekaAccept客户端数据接受名称
eureka.client.decoder-name
这是一个瞬态配置,一旦最新的编解码器稳定,可以删除(因为只有一个)
eureka.client.disable-delta
false
指示eureka客户端是否应该禁用提取delta,而应该诉诸于获取完整的注册表信息。
请注意,增量获取可以极大地减少流量,因为尤利卡服务器的更改速率通常远低于提取速率。
更改在运行时在registryFetchIntervalSeconds指定的下一个注册表提取周期中有效
eureka.client.dollar-replacement
_-
在eureka服务器的序列化/反序列化信息期间,获取Dollar符号 $ 的替换字符串。
eureka.client.enabled
true
标记以指示启用Eureka客户端。
eureka.client.encoder-name
这是一个瞬态配置,一旦最新的编解码器稳定,可以删除(因为只有一个)
eureka.client.escape-char-replacement
__
在eureka服务器的序列化/反序列化信息期间获取下划线符号 _ 的替换字符串。
eureka.client.eureka-connection-idle-timeout-seconds
30
表示到eureka服务器的HTTP连接可以在关闭之前保持空闲状态的时间(以秒为单位)。
在AWS环境中,建议值为30秒或更短,因为防火墙在几分钟内清除连接信息,将连接挂在空中
eureka.client.eureka-server-connect-timeout-seconds
5
指示在连接到eureka服务器需要超时之前等待(以秒为单位)的时间。请注意,客户端中的连接由org.apache.http.client.HttpClient汇集,此设置会影响实际的连接创建以及从池中获取连接的等待时间。
eureka.client.eureka-server-d-n-s-name
获取要查询的DNS名称以获取eureka服务器的列表。如果合同通过实现serviceUrls返回服务URL,则不需要此信息。
当useDnsForFetchingServiceUrls设置为true时,使用DNS机制,而eureka客户端希望DNS以某种方式配置,以便可以动态获取更改的eureka服务器。
更改在运行时有效。
eureka.client.eureka-server-port
获取用于构建服务url的端口,以在eureka服务器列表来自DNS时联系eureka服务器。如果合同返回服务url eurekaServerServiceUrls(String),则不需要此信息。
当useDnsForFetchingServiceUrls设置为true时,使用DNS机制,而eureka客户端希望DNS以某种方式配置,以便可以动态获取更改的eureka服务器。
更改在运行时有效。
eureka.client.eureka-server-read-timeout-seconds
8
指示从eureka服务器读取之前需要等待(秒)多久才能超时。
eureka.client.eureka-server-total-connections
200
获取从eureka客户端到所有eureka服务器允许的总连接数。
eureka.client.eureka-server-total-connections-per-host
50
获取从eureka客户端到eureka服务器主机允许的总连接数。
eureka.client.eureka-server-u-r-l-context
获取用于构建服务网址的URL上下文,以便在eureka服务器列表来自DNS时联系eureka服务器。如果合同从eurekaServerServiceUrls返回服务网址,则不需要此信息。
当useDnsForFetchingServiceUrls设置为true时,使用DNS机制,而eureka客户端希望DNS以某种方式配置,以便可以动态获取更改的eureka服务器。更改在运行时有效。
eureka.client.eureka-service-url-poll-interval-seconds
0
表示轮询对eureka服务器信息进行更改的频率(以秒为单位)。可以添加或删除Eureka服务器,此设置控制eureka客户端应该知道的时间。
eureka.client.fetch-registry
true
指示该客户端是否应从eureka服务器获取eureka注册表信息。
eureka.client.fetch-remote-regions-registry
逗号分隔将获取eureka注册表信息的区域列表。必须为availabilityZones返回的每个区域定义可用性区域。否则,将导致发现客户端启动失败。
eureka.client.filter-only-up-instances
true
指示是否在仅具有InstanceStatus UP状态的实例的过滤应用程序之后获取应用程序。
eureka.client.g-zip-content
true
指示从服务器支持时,是否必须压缩从eureka服务器提取的内容。来自eureka服务器的注册表信息被压缩以获得最佳的网络流量。
eureka.client.heartbeat-executor-exponential-back-off-bound
10
心跳执行者指数回撤相关财产。在发生超时序列的情况下,它是重试延迟的最大乘数值。
eureka.client.heartbeat-executor-thread-pool-size
2
heartbeat执行器初始化的线程池大小
eureka.client.initial-instance-info-replication-interval-seconds
40
指示将实例信息复制到eureka服务器的开始时间(以秒为单位)
eureka.client.instance-info-replication-interval-seconds
30
指示复制要复制到eureka服务器的实例更改的频率(以秒为单位)。
eureka.client.log-delta-diff
false
指示在注册表信息方面是否记录eureka服务器和eureka客户端之间的差异。
Eureka客户端尝试仅从欧莱雅服务器检索增量更改以最小化网络流量。收到三角形后,eureka客户端将从服务器的信息进行协调,以验证它是否已经没有漏掉一些信息。当客户端发生网络问题与服务器通信时,可能会发生调解失败。如果对帐失败,eureka客户端将获得完整的注册表信息。
在获取完整的注册表信息的同时,eureka客户端可以记录客户端和服务器之间的差异,并且此设置控制它。
更改在运行时在registryFetchIntervalSecondsr指定的下一个注册表提取周期中有效
eureka.client.on-demand-update-status-change
true
如果设置为true,则通过ApplicationInfoManager进行的本地状态更新将触发对远程eureka服务器的按需(但限速)注册/更新
eureka.client.prefer-same-zone-eureka
true
指示此实例是否应尝试在同一区域中使用尤里卡服务器延迟和/或其他原因。
理想情况下,eureka客户端配置为与同一区域中的服务器通信
更改在运行时在registryFetchIntervalSeconds指定的下一个注册表提取周期中有效
eureka.client.property-resolver
eureka.client.proxy-host
获取代理主机到eureka服务器(如果有的话)。
eureka.client.proxy-password
获取代理密码(如果有)。
eureka.client.proxy-port
获取代理端口到eureka服务器(如果有的话)。
eureka.client.proxy-user-name
获取代理用户名(如果有)。
eureka.client.region
us-east-1
获取此实例所在的区域(用于AWS数据中心)。
eureka.client.register-with-eureka
true
指示此实例是否应将其信息注册到eureka服务器以供其他人发现。
在某些情况下,您不希望发现实例,而您只想发现其他实例。
eureka.client.registry-fetch-interval-seconds
30
指示从eureka服务器获取注册表信息的频率(以秒为单位)。
eureka.client.registry-refresh-single-vip-address
指示客户端是否只对单个VIP的注册表信息感兴趣。
eureka.client.service-url
可用性区域映射到与eureka服务器通信的完全限定URL的列表。每个值可以是单个URL或逗号分隔的替代位置列表。
通常,尤里卡服务器URL携带协议,主机,端口,上下文和版本信息(如果有的话)。示例:http://ec2-256-156-243-129.compute-1.amazonaws.com:7001/eureka/
更改在运行时在eurekaServiceUrlPollIntervalSeconds指定的下一个服务网址刷新周期中有效。
eureka.client.transport
eureka.client.use-dns-for-fetching-service-urls
false
指示eureka客户端是否应该使用DNS机制来获取要与之通信的eureka服务器列表。当DNS名称更新为具有其他服务器时,该信息将在eureka客户端轮询该eurkaServiceUrlPollIntervalSeconds中指定的信息之后立即使用。
或者,服务urls可以返回serviceUrls,但用户应该实现自己的机制来返回更新的列表,以防发生更改。
更改在运行时有效。
eureka.dashboard.enabled
true
标志以启用Eureka仪表板。默认值为true。
eureka.dashboard.path
/
到Eureka仪表板(相对于servlet路径)的路径。默认为“/”。
eureka.instance.a-s-g-name
获取与此实例关联的AWS自动缩放组名称。该信息在AWS环境中专门用于在实例启动后自动将实例停止运行,并且已将其禁用。
eureka.instance.app-group-name
获取要在eureka中注册的应用程序组的名称。
eureka.instance.appname
unknown
获取要在eureka注册的应用程序的名称。
eureka.instance.data-center-info
返回此实例部署的数据中心。如果实例部署在AWS中,则此信息用于获取一些AWS特定实例信息。
eureka.instance.default-address-resolution-order
[]
eureka.instance.environment
eureka.instance.health-check-url
获取此实例的绝对运行状况检查页面URL。如果运行状况检查页面驻留在与eureka通话的同一个实例中,用户可以提供healthCheckUrlPath,否则在实例是其他服务器的代理的情况下,用户可以提供完整的URL。如果提供完整的URL,则优先。
它通常用于根据实例的健康状况做出有根据的决策 - 例如,它可用于确定是否继续部署到整个场,或者停止部署而不会造成进一步的损坏。完整的URL应遵循格式http:// $ {eureka.hostname}:7001 /其中值$ {eureka.hostname}在运行时被替换。
eureka.instance.health-check-url-path
/health
获取此实例的相对运行状况检查URL路径。然后,健康检查页面URL由主机名和通信类型构建,如securePort和nonSecurePort中指定的安全或不安全。
它通常用于根据实例的健康状况做出有根据的决策 - 例如,它可用于确定是否继续部署到整个场,或者停止部署而不会造成进一步的损坏。
eureka.instance.home-page-url
获取此实例的绝对主页URL。如果主页位于与eureka通话的同一个实例中,用户可以提供homePageUrlPath,否则在实例是其他服务器的代理的情况下,用户可以提供完整的URL。如果提供完整的URL,则优先。
它通常用于其他服务的信息目的,以将其用作着陆页。完整的URL应遵循格式http:// $ {eureka.hostname}:7001 /其中值$ {eureka.hostname}在运行时被替换。
eureka.instance.home-page-url-path
/
获取此实例的相对主页URL路径。然后,主页URL由hostName和通信类型构建 - 安全或不安全。
它通常用于其他服务的信息目的,以将其用作着陆页。
eureka.instance.host-info
eureka.instance.hostname
如果可以在配置时确定主机名(否则将从操作系统原语中猜出)。
eureka.instance.inet-utils
eureka.instance.initial-status
使用rmeote Eureka服务器注册的初始状态。
eureka.instance.instance-enabled-onit
false
指示在eureka注册后,实例是否应该启用流量。有时候,应用程序可能需要做一些预处理,才能准备好交通。
eureka.instance.instance-id
获取要在eureka注册的此实例的唯一ID(在appName的范围内)。
eureka.instance.ip-address
获取实例的IPAdress。此信息仅用于学术目的,因为来自其他实例的通信主要发生在使用{@link #getHostName(boolean)}中提供的信息。
eureka.instance.lease-expiration-duration-in-seconds
90
指示eureka服务器在接收到最后一个心跳之后等待的时间(秒),然后才能从此视图中删除此实例,并禁止此实例的流量。
将此值设置得太长可能意味着流量可以路由到实例,即使实例不存在。设置此值太小可能意味着,由于临时网络故障,实例可能会被取消流量。此值将设置为至少高于leaseRenewalIntervalInSeconds中指定的值。
eureka.instance.lease-renewal-interval-in-seconds
30
指示eureka客户端需要向eureka服务器发送心跳以指示它仍然存在的频率(以秒为单位)。如果在leaseExpirationDurationInSeconds中指定的时间段内未收到心跳线,则eureka服务器将从其视图中删除该实例,因此不允许此实例的流量。
请注意,如果该实例实现HealthCheckCallback,然后决定使其本身不可用,则该实例仍然可能无法访问流量。
eureka.instance.metadata-map
获取与此实例关联的元数据名称/值对。该信息发送到eureka服务器,可以被其他实例使用。
eureka.instance.namespace
eureka
获取用于查找属性的命名空间。忽略Spring Cloud。
eureka.instance.non-secure-port
80
获取实例应该接收流量的非安全端口。
eureka.instance.non-secure-port-enabled
true
指示是否应启用非安全端口的流量。
eureka.instance.prefer-ip-address
false
标示说,当猜测主机名时,服务器的IP地址应该在操作系统报告的主机名中使用。
eureka.instance.registry.default-open-for-traffic-count
1
用于确定租赁期间取消的价值,独立时默认为1。应该为对等复制的eurekas设置为0
eureka.instance.registry.expected-number-of-renews-per-min
1
eureka.instance.secure-health-check-url
获取此实例的绝对安全运行状况检查页面URL。如果健康检查页面驻留在与eureka通话的同一个实例中,用户可以提供secureHealthCheckUrl,否则在实例是其他服务器的代理的情况下,用户可以提供完整的URL。如果提供完整的URL,则优先。
它通常用于根据实例的健康状况做出有根据的决策 - 例如,它可用于确定是否继续部署到整个场,或者停止部署而不会造成进一步的损坏。完整的URL应遵循格式http:// $ {eureka.hostname}:7001 /其中值$ {eureka.hostname}在运行时被替换。
eureka.instance.secure-port
443
获取实例应该接收流量的安全端口。
eureka.instance.secure-port-enabled
false
指示安全端口是否应启用流量。
eureka.instance.secure-virtual-host-name
unknown
获取为此实例定义的安全虚拟主机名。
这通常是其他实例通过使用安全虚拟主机名找到此实例的方式。这与完全限定域名相似,您的服务的用户将需要找到此实例。
eureka.instance.status-page-url
获取此实例的绝对状态页面URL路径。如果状态页面驻留在与eureka通话的同一个实例中,用户可以提供statusPageUrlPath,否则在实例是其他服务器的代理的情况下,用户可以提供完整的URL。如果提供完整的URL,则优先。
它通常用于其他服务的信息目的,以查找此实例的状态。用户可以提供一个简单的HTML来指示实例的当前状态。
eureka.instance.status-page-url-path
/info
获取此实例的相对状态页面URL路径。然后,状态页面URL由安全端口和非安全端口中指定的hostName和通信类型构建 - 安全或不安全。
它通常用于其他服务的信息目的,以查找此实例的状态。用户可以提供一个简单的HTML来指示实例的当前状态。
eureka.instance.virtual-host-name
unknown
获取为此实例定义的虚拟主机名。
这通常是其他实例通过使用虚拟主机名找到此实例的方式。这与完全限定域名相似,您的服务的用户将需要找到此实例。
eureka.server.a-s-g-cache-expiry-timeout-ms
0
eureka.server.a-s-g-query-timeout-ms
300
eureka.server.a-s-g-update-interval-ms
0
eureka.server.a-w-s-access-id
eureka.server.a-w-s-secret-key
eureka.server.batch-replication
false
eureka.server.binding-strategy
eureka.server.delta-retention-timer-interval-in-ms
0
eureka.server.disable-delta
false
eureka.server.disable-delta-for-remote-regions
false
eureka.server.disable-transparent-fallback-to-other-region
false
eureka.server.e-i-p-bind-rebind-retries
3
eureka.server.e-i-p-binding-retry-interval-ms
0
eureka.server.e-i-p-binding-retry-interval-ms-when-unbound
0
eureka.server.enable-replicated-request-compression
false
eureka.server.enable-self-preservation
true
eureka.server.eviction-interval-timer-in-ms
0
eureka.server.g-zip-content-from-remote-region
true
eureka.server.json-codec-name
eureka.server.list-auto-scaling-groups-role-name
ListAutoScalingGroups
eureka.server.log-identity-headers
true
eureka.server.max-elements-in-peer-replication-pool
10000
eureka.server.max-elements-in-status-replication-pool
10000
eureka.server.max-idle-thread-age-in-minutes-for-peer-replication
15
eureka.server.max-idle-thread-in-minutes-age-for-status-replication
10
eureka.server.max-threads-for-peer-replication
20
eureka.server.max-threads-for-status-replication
1
eureka.server.max-time-for-replication
30000
eureka.server.min-threads-for-peer-replication
5
eureka.server.min-threads-for-status-replication
1
eureka.server.number-of-replication-retries
5
eureka.server.peer-eureka-nodes-update-interval-ms
0
eureka.server.peer-eureka-status-refresh-time-interval-ms
0
eureka.server.peer-node-connect-timeout-ms
200
eureka.server.peer-node-connection-idle-timeout-seconds
30
eureka.server.peer-node-read-timeout-ms
200
eureka.server.peer-node-total-connections
1000
eureka.server.peer-node-total-connections-per-host
500
eureka.server.prime-aws-replica-connections
true
eureka.server.property-resolver
eureka.server.rate-limiter-burst-size
10
eureka.server.rate-limiter-enabled
false
eureka.server.rate-limiter-full-fetch-average-rate
100
eureka.server.rate-limiter-privileged-clients
eureka.server.rate-limiter-registry-fetch-average-rate
500
eureka.server.rate-limiter-throttle-standard-clients
false
eureka.server.registry-sync-retries
0
eureka.server.registry-sync-retry-wait-ms
0
eureka.server.remote-region-app-whitelist
eureka.server.remote-region-connect-timeout-ms
1000
eureka.server.remote-region-connection-idle-timeout-seconds
30
eureka.server.remote-region-fetch-thread-pool-size
20
eureka.server.remote-region-read-timeout-ms
1000
eureka.server.remote-region-registry-fetch-interval
30
eureka.server.remote-region-total-connections
1000
eureka.server.remote-region-total-connections-per-host
500
eureka.server.remote-region-trust-store
eureka.server.remote-region-trust-store-password
changeit
eureka.server.remote-region-urls
eureka.server.remote-region-urls-with-name
eureka.server.renewal-percent-threshold
0.85
eureka.server.renewal-threshold-update-interval-ms
0
eureka.server.response-cache-auto-expiration-in-seconds
180
eureka.server.response-cache-update-interval-ms
0
eureka.server.retention-time-in-m-s-in-delta-queue
0
eureka.server.route53-bind-rebind-retries
3
eureka.server.route53-binding-retry-interval-ms
0
eureka.server.route53-domain-t-t-l
30
eureka.server.sync-when-timestamp-differs
true
eureka.server.use-read-only-response-cache
true
eureka.server.wait-time-in-ms-when-sync-empty
0
eureka.server.xml-codec-name
feign.compression.request.mime-types
[text/xml, application/xml, application/json]
支持的MIME类型列表。
feign.compression.request.min-request-size
2048
最小阈值内容大小。
health.config.enabled
false
标记以指示应安装配置服务器运行状况指示器。
health.config.time-to-live
0
生成缓存结果的时间,以毫秒为单位。默认300000(5分钟)。
hystrix.metrics.enabled
true
启用Hystrix指标轮询。默认为true。
hystrix.metrics.polling-interval-ms
2000
后续轮询度量之间的间隔。默认为2000 ms。
management.health.refresh.enabled
true
启用刷新范围的运行状况端点。
management.health.zookeeper.enabled
true
启用zookeeper的健康端点。
netflix.atlas.batch-size
10000
netflix.atlas.enabled
true
netflix.atlas.uri
netflix.metrics.servo.cache-warning-threshold
1000
当ServoMonitorCache达到这个大小时,会记录一个警告。如果您在RestTemplate url中使用字符串连接,这将非常有用。
netflix.metrics.servo.registry-class
com.netflix.servo.BasicMonitorRegistry
Servo使用的监视器注册表的完全限定类名。
proxy.auth.load-balanced
proxy.auth.routes
每个路由的认证策略。
spring.cloud.bus.ack.destination-service
想要听ack的服务。默认为null(表示所有服务)。
spring.cloud.bus.ack.enabled
true
标志关闭acks(默认打开)。
spring.cloud.bus.destination
springCloudBus
名称Spring Cloud消息的流目的地。
spring.cloud.bus.enabled
true
标志表示总线已启用。
spring.cloud.bus.env.enabled
true
标志关闭环境变化事件(默认为开)。
spring.cloud.bus.refresh.enabled
true
关闭刷新事件的标志(默认为开)。
spring.cloud.bus.trace.enabled
false
打开acks跟踪的标志(默认关闭)。
spring.cloud.cloudfoundry.discovery.enabled
true
标记以指示启用发现。
spring.cloud.cloudfoundry.discovery.heartbeat-frequency
5000
心跳次数以毫秒为单位的频率。客户端将轮询该频率并广播服务ID列表。
spring.cloud.cloudfoundry.discovery.org
要进行身份验证的组织名称(默认为用户默认值)。
spring.cloud.cloudfoundry.discovery.password
用户验证和获取令牌的密码。
spring.cloud.cloudfoundry.discovery.space
要进行身份验证的空间名称(默认为用户默认值)。
spring.cloud.cloudfoundry.discovery.url
https://api.run.pivotal.io
Cloud Foundry API(云控制器)的URL。
spring.cloud.cloudfoundry.discovery.username
验证用户名(通常是电子邮件地址)。
spring.cloud.config.allow-override
true
标记以指示可以使用{@link #isSystemPropertiesOverride()systemPropertiesOverride}。设置为false以防止用户意外更改默认值。默认值为true。
spring.cloud.config.authorization
客户端使用的授权令牌连接到服务器。
spring.cloud.config.discovery.enabled
false
标记以指示启用配置服务器发现(配置服务器URL将通过发现查找)。
spring.cloud.config.discovery.service-id
configserver
服务ID来定位配置服务器。
spring.cloud.config.enabled
true
标记说远程配置启用。默认为true;
spring.cloud.config.fail-fast
false
标记表示无法连接到服务器是致命的(默认为false)。
spring.cloud.config.label
用于拉取远程配置属性的标签名称。默认设置在服务器上(通常是基于git的服务器的“主”)。
spring.cloud.config.name
用于获取远程属性的应用程序名称。
spring.cloud.config.override-none
false
标志表示当{@link #setAllowOverride(boolean)allowOverride}为true时,外部属性应该采用最低优先级,并且不覆盖任何现有的属性源(包括本地配置文件)。默认为false。
spring.cloud.config.override-system-properties
true
标记以指示外部属性应覆盖系统属性。默认值为true。
spring.cloud.config.password
联系远程服务器时使用的密码(HTTP Basic)。
spring.cloud.config.profile
default
获取远程配置时使用的默认配置文件(逗号分隔)。默认为“默认”。
spring.cloud.config.retry.initial-interval
1000
初始重试间隔(以毫秒为单位)。
spring.cloud.config.retry.max-attempts
6
最大尝试次数。
spring.cloud.config.retry.max-interval
2000
退避的最大间隔
spring.cloud.config.retry.multiplier
1.1
下一个间隔的乘数。
spring.cloud.config.server.bootstrap
false
表示配置服务器应使用远程存储库中的属性初始化其自己的环境。默认情况下关闭,因为它会延迟启动,但在将服务器嵌入到另一个应用程序中时很有用。
spring.cloud.config.server.default-application-name
application
传入请求没有特定的默认应用程序名称。
spring.cloud.config.server.default-label
传入请求没有特定标签时的默认存储库标签。
spring.cloud.config.server.default-profile
default
传入请求没有特定的默认应用程序配置文件时。
spring.cloud.config.server.encrypt.enabled
true
在发送给客户端之前启用对环境属性的解密。
spring.cloud.config.server.git.basedir
库的本地工作副本的基本目录。
spring.cloud.config.server.git.clone-on-start
标记以表明应该在启动时克隆存储库(不是按需)。通常会导致启动速度较慢,但第一次查询更快。
spring.cloud.config.server.git.default-label
spring.cloud.config.server.git.environment
spring.cloud.config.server.git.force-pull
标记表示存储库应该强制拉。如果真的丢弃任何本地更改并从远程存储库获取。
spring.cloud.config.server.git.git-factory
spring.cloud.config.server.git.password
使用远程存储库验证密码。
spring.cloud.config.server.git.repos
存储库标识符映射到位置和其他属性。
spring.cloud.config.server.git.search-paths
在本地工作副本中使用的搜索路径。默认情况下只搜索根。
spring.cloud.config.server.git.timeout
用于获取HTTP或SSH连接的超时(以秒为单位)(如果适用)。默认5秒。
spring.cloud.config.server.git.uri
远程存储库的URI。
spring.cloud.config.server.git.username
用于远程存储库的身份验证用户名。
spring.cloud.config.server.health.repositories
spring.cloud.config.server.native.fail-on-error
false
标识以确定在解密期间如何处理异常(默认为false)。
spring.cloud.config.server.native.search-locations
[]
搜索配置文件的位置。默认与Spring Boot应用程序相同,因此[classpath:/,classpath:/ config /,file:./,file:./ config /]。
spring.cloud.config.server.native.version
为本地存储库报告的版本字符串
spring.cloud.config.server.overrides
无条件发送给所有客户的资源的额外地图。
spring.cloud.config.server.prefix
配置资源路径的前缀(默认为空)。当您不想更改上下文路径或servlet路径时嵌入其他应用程序时很有用。
spring.cloud.config.server.strip-document-from-yaml
true
标记为指示作为文本或集合(而不是映射)的YAML文档应以“本机”形式返回。
spring.cloud.config.server.svn.basedir
库的本地工作副本的基本目录。
spring.cloud.config.server.svn.default-label
trunk
用于环境属性请求的默认标签。
spring.cloud.config.server.svn.environment
spring.cloud.config.server.svn.password
使用远程存储库验证密码。
spring.cloud.config.server.svn.search-paths
在本地工作副本中使用的搜索路径。默认情况下只搜索根。
spring.cloud.config.server.svn.uri
远程存储库的URI。
spring.cloud.config.server.svn.username
用于远程存储库的身份验证用户名。
spring.cloud.config.token
安全令牌通过到底层环境库。
spring.cloud.config.uri
http://localhost:8888
远程服务器的URI(默认http:// localhost:8888)。
spring.cloud.config.username
联系远程服务器时使用的用户名(HTTP Basic)。
spring.cloud.consul.config.acl-token
spring.cloud.consul.config.data-key
data
如果格式为Format.PROPERTIES或Format.YAML,则使用以下字段来查找协调配置。
spring.cloud.consul.config.default-context
application
spring.cloud.consul.config.enabled
true
spring.cloud.consul.config.fail-fast
true
在配置查找期间抛出异常,如果为true,否则为日志警告。
spring.cloud.consul.config.format
spring.cloud.consul.config.prefix
config
spring.cloud.consul.config.profile-separator
,
spring.cloud.consul.config.watch.delay
1000
手表的固定延迟的价值在毫秒。默认为1000。
spring.cloud.consul.config.watch.enabled
true
如果手表启用默认为true。
spring.cloud.consul.config.watch.wait-time
55
等待(或阻止)观看查询的秒数,默认为55.需要小于默认的ConsulClient(默认为60)。要增加ConsulClient超时,使用自定义的HttpClient创建一个带有自定义ConsulRawClient的ConsulClient bean。
spring.cloud.consul.discovery.acl-token
spring.cloud.consul.discovery.catalog-services-watch-delay
10
spring.cloud.consul.discovery.catalog-services-watch-timeout
2
spring.cloud.consul.discovery.default-query-tag
如果没有在serverListQueryTags中列出,请在服务列表中查询标签。
spring.cloud.consul.discovery.default-zone-metadata-name
zone
服务实例区域来自元数据。这允许更改元数据标签名称。
spring.cloud.consul.discovery.enabled
true
是否启用服务发现?
spring.cloud.consul.discovery.fail-fast
true
在服务注册期间抛出异常,如果为true,否则,记录警告(默认为true)。
spring.cloud.consul.discovery.health-check-interval
10s
执行健康检查的频率(例如10s)
spring.cloud.consul.discovery.health-check-path
/health
调用健康检查的备用服务器路径
spring.cloud.consul.discovery.health-check-timeout
健康检查超时(例如10s)
spring.cloud.consul.discovery.health-check-url
自定义健康检查网址覆盖默认值
spring.cloud.consul.discovery.heartbeat.enabled
false
spring.cloud.consul.discovery.heartbeat.heartbeat-interval
spring.cloud.consul.discovery.heartbeat.interval-ratio
spring.cloud.consul.discovery.heartbeat.ttl-unit
s
spring.cloud.consul.discovery.heartbeat.ttl-value
30
spring.cloud.consul.discovery.host-info
spring.cloud.consul.discovery.hostname
访问服务器时使用的主机名
spring.cloud.consul.discovery.instance-id
唯一的服务实例ID
spring.cloud.consul.discovery.instance-zone
服务实例区
spring.cloud.consul.discovery.ip-address
访问服务时使用的IP地址(还必须设置preferIpAddress才能使用)
spring.cloud.consul.discovery.lifecycle.enabled
true
spring.cloud.consul.discovery.management-port
端口注册管理服务(默认为管理端口)
spring.cloud.consul.discovery.management-suffix
management
注册管理服务时使用后缀
spring.cloud.consul.discovery.management-tags
注册管理服务时使用的标签
spring.cloud.consul.discovery.port
端口注册服务(默认为侦听端口)
spring.cloud.consul.discovery.prefer-agent-address
false
我们将如何确定使用地址的来源
spring.cloud.consul.discovery.prefer-ip-address
false
在注册时使用ip地址而不是主机名
spring.cloud.consul.discovery.query-passing
false
将“pass”参数添加到/ v1 / health / service / serviceName。这会将健康检查推送到服务器。
spring.cloud.consul.discovery.register
true
注册为领事服务。
spring.cloud.consul.discovery.register-health-check
true
注册领事健康检查。在开发服务期间有用。
spring.cloud.consul.discovery.scheme
http
是否注册http或https服务
spring.cloud.consul.discovery.server-list-query-tags
服务器列表中要查询的serviceId的→标签的映射。这允许通过单个标签过滤服务。
spring.cloud.consul.discovery.service-name
服务名称
spring.cloud.consul.discovery.tags
注册服务时使用的标签
spring.cloud.consul.enabled
true
启用了spring cloud consul
spring.cloud.consul.host
localhost
Consul代理主机名。默认为“localhost”。
spring.cloud.consul.port
8500
Consul代理端口。默认为'8500'。
spring.cloud.consul.retry.initial-interval
1000
初始重试间隔(以毫秒为单位)。
spring.cloud.consul.retry.max-attempts
6
最大尝试次数。
spring.cloud.consul.retry.max-interval
2000
退避的最大间隔
spring.cloud.consul.retry.multiplier
1.1
下一个间隔的乘数。
spring.cloud.hypermedia.refresh.fixed-delay
5000
spring.cloud.hypermedia.refresh.initial-delay
10000
spring.cloud.inetutils.default-hostname
localhost
默认主机名。用于发生错误的情况。
spring.cloud.inetutils.default-ip-address
127.0.0.1
默认ipaddress。用于发生错误的情况。
spring.cloud.inetutils.ignored-interfaces
将被忽略的网络接口的Java正则表达式列表。
spring.cloud.inetutils.preferred-networks
将被忽略的网络地址的Java正则表达式列表。
spring.cloud.inetutils.timeout-seconds
1
计算主机名的超时秒数。
spring.cloud.inetutils.use-only-site-local-interfaces
false
仅使用与站点本地地址的接口。有关详细信息,请参阅{@link InetAddress#isSiteLocalAddress()}。
spring.cloud.loadbalancer.retry.enabled
false
spring.cloud.stream.binders
spring.cloud.stream.bindings
spring.cloud.stream.consul.binder.event-timeout
5
spring.cloud.stream.consumer-defaults
spring.cloud.stream.default-binder
spring.cloud.stream.dynamic-destinations
[]
spring.cloud.stream.ignore-unknown-properties
true
spring.cloud.stream.instance-count
1
spring.cloud.stream.instance-index
0
spring.cloud.stream.producer-defaults
spring.cloud.stream.rabbit.binder.admin-adresses
[]
spring.cloud.stream.rabbit.binder.compression-level
0
spring.cloud.stream.rabbit.binder.nodes
[]
spring.cloud.stream.rabbit.bindings
spring.cloud.zookeeper.base-sleep-time-ms
50
重试之间等待的初始时间
spring.cloud.zookeeper.block-until-connected-unit
与Zookeeper连接时阻止的时间单位
spring.cloud.zookeeper.block-until-connected-wait
10
等待时间阻止连接到Zookeeper
spring.cloud.zookeeper.connect-string
localhost:2181
连接字符串到Zookeeper集群
spring.cloud.zookeeper.default-health-endpoint
将检查以验证依赖关系是否存在的默认运行状况端点
spring.cloud.zookeeper.dependencies
将别名映射到ZookeeperDependency。从Ribbon的角度看,别名实际上是serviceID,因为Ribbon不能接受serviceID中的嵌套结构
spring.cloud.zookeeper.dependency-configurations
spring.cloud.zookeeper.dependency-names
spring.cloud.zookeeper.discovery.enabled
true
spring.cloud.zookeeper.discovery.instance-host
预定义的主机可以在Zookeeper中注册自己的服务。对应于URI规范中的{code address}。
spring.cloud.zookeeper.discovery.instance-port
端口注册服务(默认为侦听端口)
spring.cloud.zookeeper.discovery.metadata
获取与此实例关联的元数据名称/值对。该信息被发送到动物管理员,可以被其他实例使用。
spring.cloud.zookeeper.discovery.register
true
在动物园管理员中注册为服务。
spring.cloud.zookeeper.discovery.root
/services
所有实例都被注册的根Zookeeper文件夹
spring.cloud.zookeeper.discovery.uri-spec
{scheme}://{address}:{port}
在Zookeeper服务注册期间解决的URI规范
spring.cloud.zookeeper.enabled
true
启用了Zookeeper
spring.cloud.zookeeper.max-retries
10
最多重试次数
spring.cloud.zookeeper.max-sleep-ms
500
每次重试最多可以以ms为单位睡眠
spring.cloud.zookeeper.prefix
将应用于所有Zookeeper依赖关系的路径的公共前缀
spring.integration.poller.fixed-delay
1000
修复默认轮询器的延迟。
spring.integration.poller.max-messages-per-poll
1
默认轮询器每轮询的最大消息。
spring.sleuth.integration.enabled
true
启用Spring Integration侦察器。
spring.sleuth.integration.patterns
*
一组简单的模式,通道名称将与之匹配。默认值为*(所有通道)。请参阅org.springframework.util.PatternMatchUtils.simpleMatch(String,String)。
spring.sleuth.keys.async.class-name-key
class
具有使用{@code @Async}注释的方法的类的简单名称,从异步进程开始
@see org.springframework.scheduling.annotation.Async
spring.sleuth.keys.async.method-name-key
method
使用{@code @Async}注释的方法的名称
@see org.springframework.scheduling.annotation.Async
spring.sleuth.keys.async.prefix
如果标题名称被添加为标签,则使用前缀。
spring.sleuth.keys.async.thread-name-key
thread
执行异步方法的线程的名称
@see org.springframework.scheduling.annotation.Async
spring.sleuth.keys.http.headers
额外的标题应该作为标签添加,如果它们存在。如果头值是多值的,则标签值将是逗号分隔的单引号列表。
spring.sleuth.keys.http.host
http.host
URL或主机头的域部分。示例:“mybucket.s3.amazonaws.com”。用于过滤主机而不是ip地址。
spring.sleuth.keys.http.method
http.method
HTTP方法或动词,如“GET”或“POST”。用于过滤http路由。
spring.sleuth.keys.http.path
http.path
绝对的http路径,没有任何查询参数。示例:“/ objects / abcd-ff”。用于过滤http路由,可以与zipkin v1一起移植。在zipkin v1中,只支持等于过滤器。删除查询参数使不同URI的数量减少。例如,无论查询行中编码的签名参数如何,都可以查询相同的资源。这不会降低HTTP单路由的基数。例如,通常将路由表示为http URI模板,如“/ resource / {resource_id}”。在只有等量查询可用的系统中,如果实际请求是“/ resource / abcd-ff”,则搜索{@code http.uri = / resource}将不匹配。历史记录:这通常在拉链中被表示为“http.uri”,但最常见的只是一条路。
spring.sleuth.keys.http.prefix
http.
如果标题名称被添加为标签,则使用前缀。
spring.sleuth.keys.http.request-size
http.request.size
非空HTTP请求体的大小(以字节为单位)。防爆。"16384"
大上传可能会超出限制或直接影响延迟。
spring.sleuth.keys.http.response-size
http.response.size
非空HTTP响应体的大小(以字节为单位)。防爆。"16384"
大量下载可能会超出限制或直接影响延迟。
spring.sleuth.keys.http.status-code
http.status_code
当HTTP响应代码不在2xx范围内。防爆。“503”用于过滤错误状态。2xx范围不会被记录,因为成功代码对延迟故障排除不那么有趣。省略节省每个跨度至少20个字节。
spring.sleuth.keys.http.url
http.url
整个URL,包括方案,主机和查询参数(如果可用)。防爆。“https://mybucket.s3.amazonaws.com/objects/abcd-ff?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Algorithm=AWS4-HMAC-SHA256...”结合{@link #method },您可以了解完全限定的请求行。这是可选的,因为它可能包括私人数据或相当长的长度。
spring.sleuth.keys.hystrix.command-group
commandGroup
命令组的名称Hystrix使用命令组密钥将诸如报告,警报,仪表板或团队/库所有权的命令分组在一起。
@see com.netflix.hystrix.HystrixCommandGroupKey
spring.sleuth.keys.hystrix.command-key
commandKey
命令键的名称描述给定命令的名称。代表用于监视,断路器,指标发布,缓存和其他此类用途的{@link com.netflix.hystrix.HystrixCommand}的关键。
@see com.netflix.hystrix.HystrixCommandKey
spring.sleuth.keys.hystrix.prefix
如果标题名称被添加为标签,则使用前缀。
spring.sleuth.keys.hystrix.thread-pool-key
threadPoolKey
线程池密钥的名称。线程池密钥表示用于监视,指标发布,缓存和其他此类用途的{@link com.netflix.hystrix.HystrixThreadPool}。甲{@link com.netflix.hystrix.HystrixCommand}与单个相关的{@link com.netflix.hystrix.HystrixThreadPool}如由检索{@link com.netflix.hystrix.HystrixThreadPoolKey}注入它,或者它的默认值使用{@link com.netflix.hystrix.HystrixCommandGroupKey}创建的创建它。
@see com.netflix.hystrix.HystrixThreadPoolKey
spring.sleuth.keys.message.headers
额外的标题应该作为标签添加,如果它们存在。如果头值不是String,它将使用其toString()方法转换为String。
spring.sleuth.keys.message.payload.size
message/payload-size
估计有效载荷的大小(如果有的话)。
spring.sleuth.keys.message.payload.type
message/payload-type
有效载荷的类型。
spring.sleuth.keys.message.prefix
message/
如果标题名称被添加为标签,则使用前缀。
spring.sleuth.keys.mvc.controller-class
mvc.controller.class
小写,连字符分隔处理请求的类的名称。防爆。名为“BookController”的类将导致“book-controller”标签值。
spring.sleuth.keys.mvc.controller-method
mvc.controller.method
小写,连字符分隔处理请求的类的名称。防爆。名为“listOfBooks”的方法将导致“list-of-books”标签值。
spring.sleuth.metric.span.accepted-name
counter.span.accepted
spring.sleuth.metric.span.dropped-name
counter.span.dropped
spring.sleuth.sampler.percentage
0.1
应采样的请求百分比。例如1.0 - 100%的请求应该被抽样。精度仅为全数(即不支持0.1%的痕迹)。
spring.sleuth.trace-id128
false
如果为true,则生成128位跟踪ID,而不是64位跟踪ID。
zuul.add-host-header
false
标识以确定代理是否转发主机头。
zuul.add-proxy-headers
true
标识以确定代理是否添加X-Forwarded- *标头。
zuul.host.max-per-route-connections
20
单个路由可以使用的最大连接数。
zuul.host.max-total-connections
200
代理可以容纳到后端的总连接数。
zuul.ignore-local-service
true
zuul.ignore-security-headers
true
标记说,如果spring security在类路径上,则将SECURITY_HEADERS添加到忽略的标头。通过将ignoreSecurityHeaders设置为false,我们可以关闭此默认行为。这应该与禁用默认的spring security标头一起使用,请参见https://docs.spring.io/spring-security/site/docs/current/reference/html/headers.html#default-security-headers
zuul.ignored-headers
HTTP标头的名称完全忽略(即将其从下游请求中删除,并将其从下游响应中删除)。
zuul.ignored-patterns
zuul.ignored-services
一组服务名称不考虑代理自动。默认情况下,发现客户端中的所有服务都将被代理。
zuul.prefix
所有路由的公共前缀。
zuul.remove-semicolon-content
true
标记说,可以删除超过第一个分号的路径元素。
zuul.retryable
默认情况下是否支持重试的标志(假设路由本身支持)。
zuul.ribbon-isolation-strategy
zuul.routes
将路线名称映射到属性。
zuul.s-e-c-u-r-i-t-y-h-e-a-d-e-r-s
一般预期由Spring安全性添加的标头,因此如果代理和后端使用Spring保护,则通常会重复。默认情况下,如果存在Spring安全性,并且ignoreSecurityHeaders = true,它们将被添加到忽略的标头。
zuul.semaphore.max-semaphores
100
Hystrix的总信号量的最大数量。
zuul.sensitive-headers
不传递到下游请求的敏感标头列表。默认为通常包含用户凭据的“安全”标题集。如果下游服务是与代理相同的系统的一部分,那么从列表中删除它们是正确的,所以他们正在共享认证数据。如果在您自己的域之外使用物理URL,那么一般来说泄漏用户凭据将是一个坏主意。
zuul.servlet-path
/zuul
安装Zuul作为servlet的路径(不是Spring MVC的一部分)。对于具有大型机构的请求,例如文件上传,servlet对于更高的内存效率更高。
zuul.ssl-hostname-validation-enabled
true
标记以说明是否应验证ssl连接的主机名。默认值为true。这只应用于测试设置!
zuul.strip-prefix
true
在转发之前标记是否从路径中删除前缀。
zuul.trace-request-body
true
标记说可以跟踪请求机构。