简介:Hadoop是一个由Apache基金会所开发的分布式系统基础架构。Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算.本教程将指导如何用苹果macOS系统安装Hadoop。
1:安装Homebrew
类似使用ubuntu系统apt-get的软件安装方式。macOS上也有类似这样的包管理器,利用Homebrew即可。 Homebrew的官方网站
安装Homebrew的方法:
/usr/bin/ruby -e "$(curl -fsSLhttps://raw.githubusercontent.com/Homebrew/install/master/install)"
ps:homebrew常用shell命
# 查看brew的帮助 brew -help
# 安装软件 brew install hadoop
# 卸载软件 brew uninstall hadoop
# 搜索软件 brew search hadoop
# 查看已经安装的软件 brew list
# 更新软件 brew update
# 更新某具体软件 brew upgrade hadoop
ps:环境变量配置
修改profile文件
nano ~/.bash_profile
添加如下内容:
export HADOOP_HOME=/usr/local/Cellar/hadoop/3.0.0/libexecexport PATH=$PATH:$HADOOP_HOME/bin/export JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk1.8.0_121.jdk/Contents/Ho$export ANDROID_HOME=${HOME}/Library/Android/sdkexport PATH=${PATH}:${ANDROID_HOME}/toolsexport PATH=${PATH}:${ANDROID_HOME}/platform-toolsexport JAVA_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
#这行需要注意,在笔者最开始这样配置的时候报过错,最后部分需要改为$HADOOP_INSTALL/lib/native,但后来测试的时候又不需要了。所以如果读者本遇到类似缺库的问题,可以尝试修改这个地方。
export HADOOP_OPTS="-Djava.library.path=HADOOP_INSTALL/lib/native #HADOOP VARIABLES END
顺便在这里配置java路径:
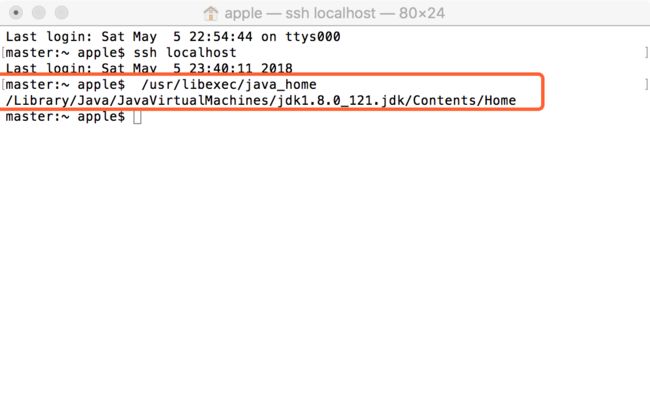
首先输入代码看看你把 Java 装到哪里了 :
/usr/libexec/java_home
输入代码: java -version
如果已经装了Java,你会看到类似酱紫结果:
java version "1.8.0_121"Java(TM) SE Runtime Environment (build 1.8.0_121-b13)Java HotSpot(TM) 64-Bit Server VM (build 25.121-b13, mixed mode)
如果没有 ,用 Homebrew 安装了最新版本 Java:brew install java
2:ssh登录本地
首先在系统里打开远程登录,位置在 System Preference -> Sharing 中,左边勾选 Remote Login,右边选择 All Users。
系统偏好可用快捷键 command+space 中搜索 "System Preference" 打开。
1:首先生成ssh公钥,终端命令代码如下
ssh-keygen -t rsa -P ""
cat HOME/.ssh/authorized_keys
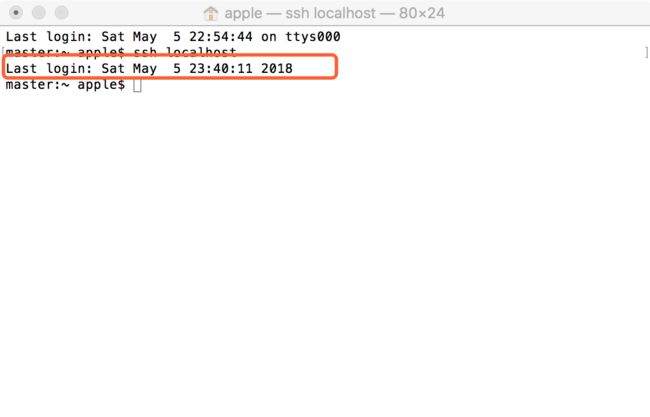
2:接下来进行测试登录本地是否成功,在 Terminal 里输入以下代码查看能不能免密 ssh 到 localhost:
ssh localhost
3:登录成功显示结果如下:
3:安装Hadoop
3.1 : 输入以下代码,自动安装hadoop:
brew install hadoop
安装过程会提示重要的信息,如下:
$JAVA_HOME has been set to be the output of: /usr/libexec/java_home
在macOS中,我们可以终端输入:/usr/libexec/java_home来获取JAVA_HOME的路径 Hadoop的安装需要配置JAVA_HOME,用 brew安装,就已经帮我们配置好了。
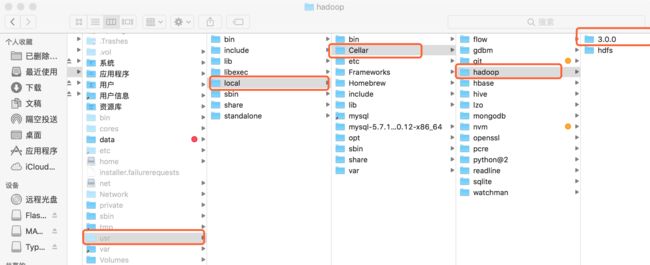
ps:通过Homebrew安装软件后,软件目录一般位于/usr/local/Cellar,并软件目录里面带有版本号. 如图我的hadoop安装目录如下:
4:测试Hadoop是否安装成功
Hadoop有三种安装模式:单机模式,伪分布式模式,分布式模式 分布式模式需要在多台电脑上面测试,这里只测试 伪分布式模式
4.1:测试伪分布式模式
测试为分布模式前,需要修改相关的5个配置文件,把homebrew默认的单机模式修改成伪分布式模式
可以使用nano或者vim进行配置文件的修改,我这里使用sublime文本编辑器修改,方便省事儿。修改路径如图所示:
修改Core-site.xml(位置 etc/hadoop/),改参数如下:

.修改mapred-site.xml (位置 etc/hadoop/),改参数如下:
如果文件后缀是 .xml.example,改为 .xml。

变量mapred.job.tracker 保存了JobTracker的位置,因为只有MapReduce组件需要知道这个位置,所以它出现在mapred-site.xml文件中。
修改hdfs-site.xml(位置 etc/hadoop/),改参数如下:

变量dfs.replication指定了每个HDFS数据库的复制次数。 通常为3, 由于我们只有一台主机和一个伪分布式模式的DataNode,将此值修改为1。
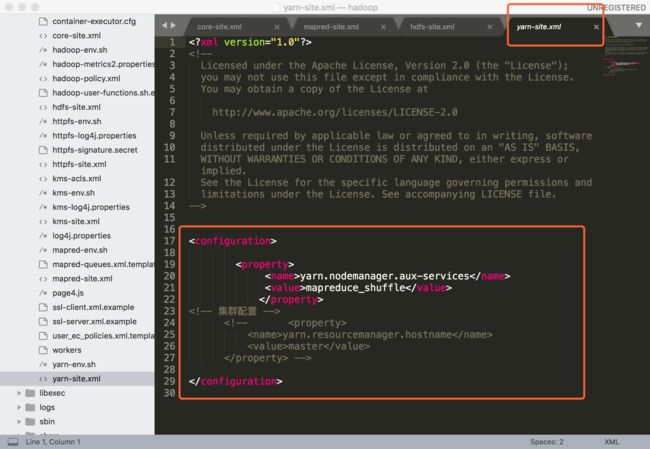
修改yarn-site.xml(位置 etc/hadoop/),改参数如下:
修改hadoop-env.sh(位置 etc/hadoop/),改参数如下:然后开启hadoop-env.sh里的注释


4.2:运行hadoop以及查看远端
进入文件夹(重要重要重要:后续所有操作一定要先进入当前hadoop文件夹)
cd /usr/local/Cellar/hadoop/3.0.0
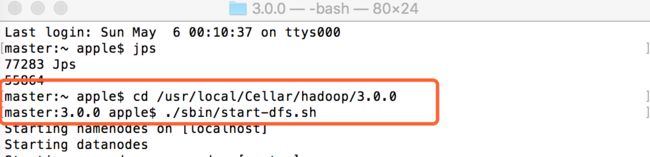
格式化文件系统(是对namenode进行初始化):
./bin/hdfs namenode -format

启动 NameNode 和 DataNode:
$ ./sbin/start-dfs.sh
如果遇到DataNode启动失败,尝试删除tmp文件夹。

关闭伪分布式
./sbin/stop-all.sh
ps:hadoop3.x版本的端口号改变如图:

现在你应该可以在浏览器中打开下面的链接看到亲切的 Overview 界面了:
NameNode - http://localhost:9870
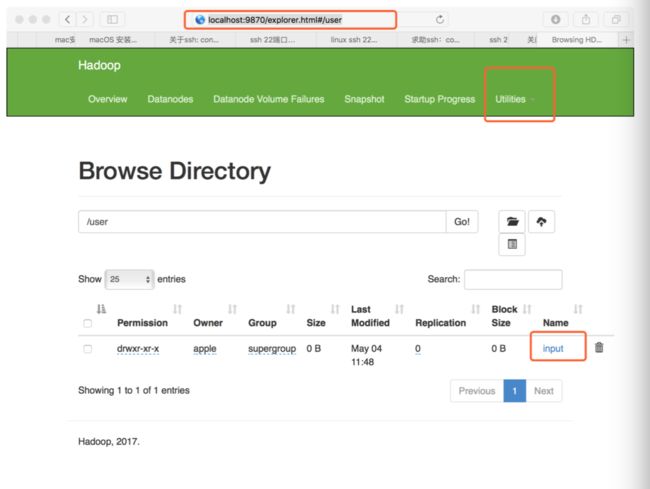
让 HDFS 可以被用来执行 MapReduce jobs:
$ ./bin/hdfs dfs -mkdir /user
$ ./bin/hdfs dfs -mkdir /user/input
把 改成你想要命名的任意子文件夹名字即可,这里我选择命名input.
启动 ResourceManager 和 NodeManager:
$ ./sbin/start-yarn.sh
现在你应该可以在浏览器中打开下面的链接看到亲切的 All Applications 界面了:
ResourceManager - http://localhost:8088
