成长会是一个面向成长和持续行动的学习行动型社群。成长会论坛是成长会成员行动记录、交流的平台,一人一年就一贴,持续盖楼,行动记录和交流,一年的记录都在一个贴子里。成长会论坛使用的是QQ群论坛。可能因为不是腾讯核心产品的关系,这个论坛不那么好用,还经常“抽风”。
成长会论坛沉淀了大量用户信息(现在社群人数超过1000),个人成长计划和行动记录,以及成员之间的交流讨论。
成长会论坛有这么多数据,自然成了我学习Python爬虫的试验田。学了几天后,我用Python写了以下东西:
- Python爬虫抓取个人信息,行业(职业)、特长爱好,3个月内的目标,进行数据分析。
- 新消息提醒工具。如你关注的成员发表了贴子,可以在微信上收到提醒。或者其他人在你的帖子下留言或回复了你,都可以收到微信的通知消息。
- 自动回贴机器人。可以在程序中发贴,或在其他人成长贴下留言。
一、登录验证问题
在抓取成长会论坛数据之前,测试过简单爬虫代码。不涉及登录的数据抓到,就是拿到网页源代码,然后解析网页拿到数据,用正则或BeautifulSoup或XPath,10多行代码就能抓取到想要的数据,Python真是简单粗暴,非常好用。
如果有登录url,表单对应字段名,做起来也比较简单。所以群论坛登录验证,首先想到是在源代码里查查找表单提交的url,表单的属性字段。通过仔细查找源码,表单属性字段也找到了,但表单提交采用的是js,跳转了几次,实在是找不到登录提交的url。无法登录,论坛中的数据一个也拿不到。
第二个想到的办法是API接口,感觉腾讯应该提供了像第三方登录一样给群论坛使用,到腾讯开放平台上去找,还是没有找到线索,想想也是,QQ群论坛就不是第三方产品。
我以为还是要回到js上来找,后来我看到大榜在看js的书,还看得比较深。我问他能不能帮我在js文件中找找。他一听,就说不要,用Fiddler抓包就可以做,提交和返回的数据都可以拿到,加密数据也可以。他说做过Java爬虫,就给我演示了一下。
在Fiddler中果然看到论坛是经过几次跳转重定向的,下图就是显示的登陆url,headers所传递的参数(用户名和密码)。
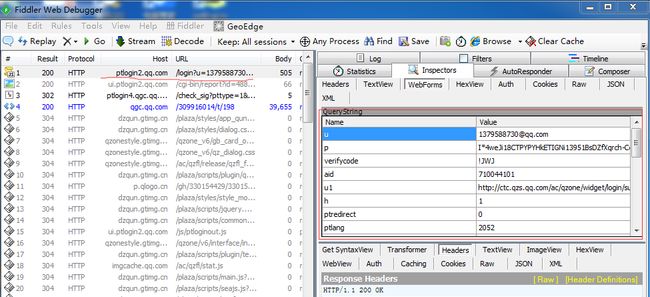
之前我只是看过简单的Python语法和网上的一段爬取贴吧图片的代码,在了解了urllib2, requests传递cookie实现登陆后,我发现,之前的方法对于登陆QQ群论坛来说就是个误区。果断把Fiddler中的这段字符串拷过来,一试就抓取到论坛帖子的列表页,登陆成功!
我一边感叹Fiddler的好用,一边想网络的种种不安全。在很多地方不开启两步验证的话,用户名和密码就形同虚设。
二、成长帖子数据分析
实现了登录验证之后,就开始了我的数据抓取和分析。第一步我关心的是成员的职业(行业)、年龄,兴趣爱好,3个月内的行动和改变计划,以及在成长会论坛打卡记录的情况。
为了方便分析,以上所有的数据爬取下来,写入一个Excel文件。后面也很方便快速进行图形化数据的展现。
QQ群论坛功能还是很简单,看到首页上没有浏览量和发贴的统计排名,我又增加了一个爬虫,在每个人的帖子里,把阅读量和回复数(个人打卡+回访留言)抓取下来,得到成长帖人气TOP10(阅读量前10名),由于回复数是个人打卡记录加上互动留言,另外写了一个函数,抓取每条记录时判断是不是贴主发出来的,并进行统计,得到成长帖子记录打卡TOP10。
这两个数据统计我在QQ群进行了分享,在TOP10的帖子下留言告诉他们Python爬取的数据统计结果。后来我又思考,这个工作Python也可以自动完成,于是做了下面《第六、自动发帖功能》

三、中文分词问题
由于每个人的成长贴,在是word里写好后粘贴过来的。每一次的数据抓取用了BeautifulSoup抓取到第一帖后,就用了字符串匹配的方式,来获取相应的信息,如每个人行业(职业)。
感觉到分词的重要,是因为帮成长会的小朋友抓取了两次数据,如想找到考研,考上外、广外,MTI的同学有哪些,联系方式和考研经过。就需要找出这些词关联的特征词,用户的记录习惯。而我没有这方面的经验,也没有学习过。所以只能根据我的理解,做一些简单的匹配,再经过Excel分类汇总,找出精准数据。其实这个词还好一点,后面也应一个同学要求找有视频编辑处理,平面设计,图片处理能力的同学。这时我在Excel中直接二次查询,快速找到后再进行校验,发现这次搜索的准确率是80%。
但要找到有学习PPT计划或在学习PPT的同学,这个词我就拿不准,因为很多人在记录中有PPT这个词,可能只是工作中写PPT。搜哪些词,特征词是什么就很关键。
四、分页数据抓取
要爬取用户所有的帖子,就需要分页爬完用户所有的分页数据,一开始我的想法是一个循环,从第一页往后,直到抓到的页面中没有用户信息为止。但是看到第一页上有页数的信息,改变了一下做法,爬取第一页信息时,顺便把用户总页数拿到。应该还可能优化成递归调用。
五、Ajax数据抓取
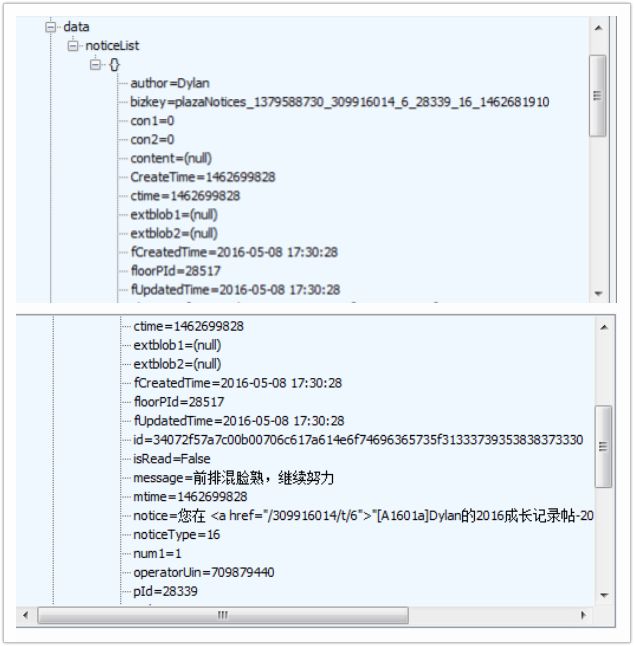
论坛的消息提醒,是Ajax数据,从爬取的网页源代码里看不到新消息。如果拿到新消息,再结合发送邮件(《七、发送邮件问题》)就可以做一个论坛消息提醒助手,在收到回复,或留言时,在微信中就能收到一个推送消息。
同样是通过Fiddler找到请求新消息的URL,顺利拿到返回的json数据,解析到消息来源和内容。QQ群论坛如果收到新消息,是从title上看到提示的。如果做一个简单的消息提醒工具就非常简单。
六、自动发贴功能
自动回复机器人,论贴发贴机器人,一直是我想实现的功能。不只是能发广(la)告(ji),还能做出一些好玩的东西,如对于成长贴记录没有更新的同学,可以发留言提醒;跟踪成长计划的实施情况,给一些有趣的提醒;定期发布成长贴的人气,更新情况。如果结合邮件发送,用户会收到更及时的消息。如果用户绑定了微信,就会收到微信的推送。
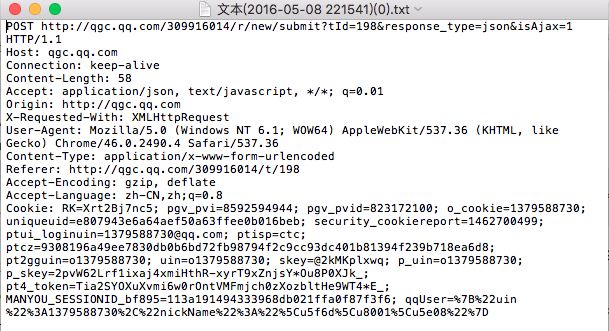
在实现自动发贴功能时,遇到的最大问题,也是登录!Fiddler抓取到了发贴提交的地址,使用了cookie,还是发不了,返回的json字符串是“登录后再操作”。还想到这一的方法,先访问一下论坛页面,然后继续使用这个request再提交表单,然并卵。
再次回到思路上,发现提交表单时,是在headers中提交cookie的,在Fiddler中抓取了headers,对的,就这么长长的一段,构造了一个header。发贴成功了!接下来,利用这个修改一个参数,在别人的帖子下留言也可以。
接下来作中文乱码的测试,通过。但是遇到一个怪异的问题,有时候能发送,有时候服务器请求出现timeout, 猜测是请求headers里的某个关键数据没有掌握,经过多次发贴测试,把Content-Length基本弄清楚,Content-Length如果存在并且有效的话,则必须和消息内容的传输长度完全一致(如果过短则会截断,过长则会导致超时。)。
七、发送邮件功能
这个功能关乎到微信上能不能收到推送消息。基本没有什么难度,10分钟搞定!
#coding=utf-8
import smtplib
from email.mime.text import MIMEText
import os
import sys
import exceptions
reload(sys)
sys.setdefaultencoding('utf-8')
#发送邮件的列表
mailto_list=['[email protected]','[email protected]']
mail_host="smtp.126.com" #设置服务器
mail_user="ppy2790" #用户名
mail_pass="1234567" #口令
mail_postfix="126.com" #发件箱的后缀
def send_mail(to_list,sub,content):
me="成长贴小助手"+"<"+mail_user+"@"+mail_postfix+">"
msg = MIMEText(content,_subtype='plain',_charset='utf-8')
msg['Subject'] = sub
msg['From'] = me
msg['To'] = ";".join(to_list)
try:
server = smtplib.SMTP()
server.connect(mail_host)
server.login(mail_user,mail_pass)
server.sendmail(me, to_list, msg.as_string())
server.close()
return True
except Exception, e:
print str(e)
return False
结语
在成长会论坛上爬取数据,是从一段下载图片的Demo开始,拿过来就修改、测试,再进行分析,快速编写代码,再找解决方案,目标驱动学习,是我学习Python的经验。
附:论坛爬取的数据分析在:《成长会不完全大数据-Python爬虫案例》