看了David Silver深度强化学习课程,感觉收获很多呀,第二讲主要讲的是马尔可夫决策过程,借着写文档的机会,对今天所学的知识进行一个复习总结。
1、马尔可夫过程
什么是马尔可夫性,就是在一个状态序列中,下一时刻的状态仅取决于当前时刻的状态,其他所有的历史信息都可以被丢弃。

根据马尔可夫性,我们可以定义一个状态转移概率和状态转移概率矩阵:

有了状态序列和状态转移概率矩阵,我们就可以定义一个马尔可夫过程,它由一个有限状态集合S和状态转移概率矩阵P来定义:

比如有如下的状态集合以及状态转移概率,我们可以得到如下的几个状态序列和状态转移概率矩阵:
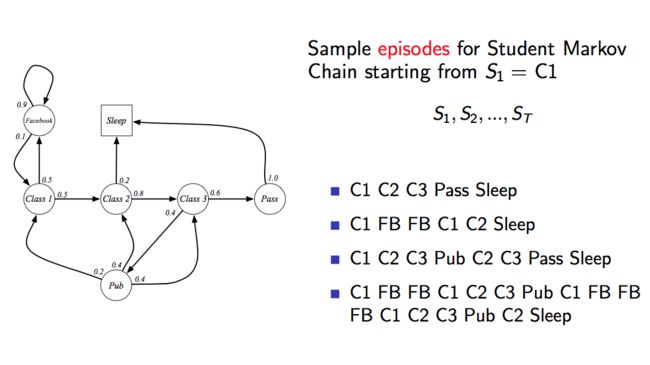
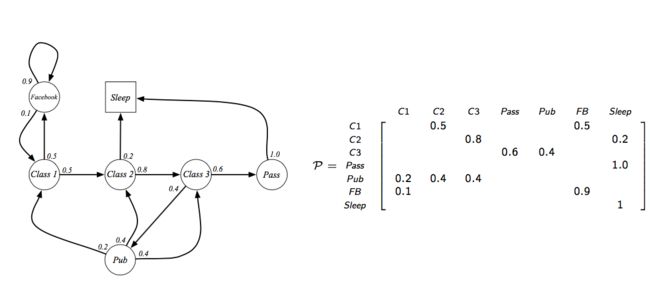
2、马尔可夫奖励过程
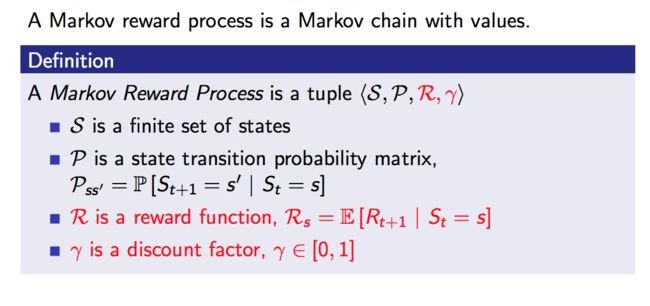
在马尔可夫过程中,我们对每一步的状态转移给予一定的奖励,就变成了马尔可夫奖励过程,与马尔可夫过程相比,这里多了两个参数,一个是奖励方程,一个是折扣因子:
还是刚才的学生上课的例子,我们将其变成一个马尔可夫奖励过程:
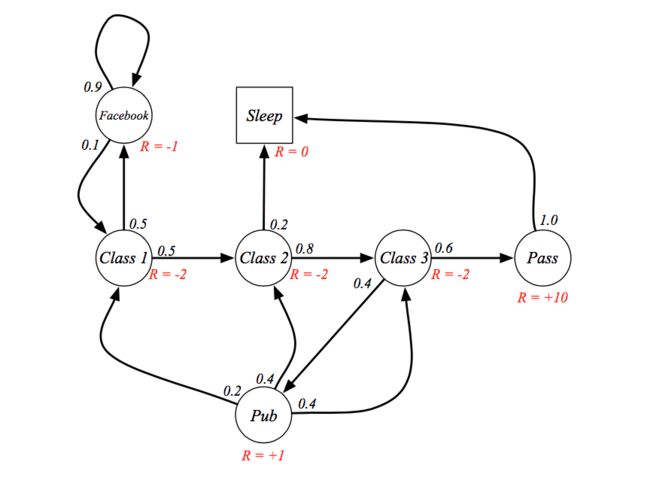
接下来,我们定义Gt为从t时刻开始到最后的一个折扣奖励和,这里的G是状态序列的一个样本,而不是期望的意思:

比如我们拿上边的例子,算一下几个状态序列的Gt如下:

这里为什么有折扣因子呢,我们可以从很多方面考虑,简单的话大家可以考虑股票投资的情景,由于资金有时间价值,未来的钱到现在会有一定的折扣,所以必须有一个折现率对钱进行折现。
那么,所有Gt的一个期望,就得到了我们的奖励方程v(s),即在t时刻状态s的一个期望奖励。对于不同的折扣因子,v(s)的值是不同的。
贝尔曼方程
在马尔可夫奖励过程中,我们就开始引入了最重要的一个公式,即贝尔曼方程,贝尔曼方程告诉我们,奖励方程可以分解为两个部分,即立即获得的奖励Rt+1,和下一时刻的价值方程的折扣值,即:

由于和的期望等于期望的和,所以前面一部分,当前时刻的奖励的期望即定义中的Rs,而由于下一时刻的状态值不确定,所以要涉及到状态转移概率矩阵,所以贝尔曼方程可进一步分解为:
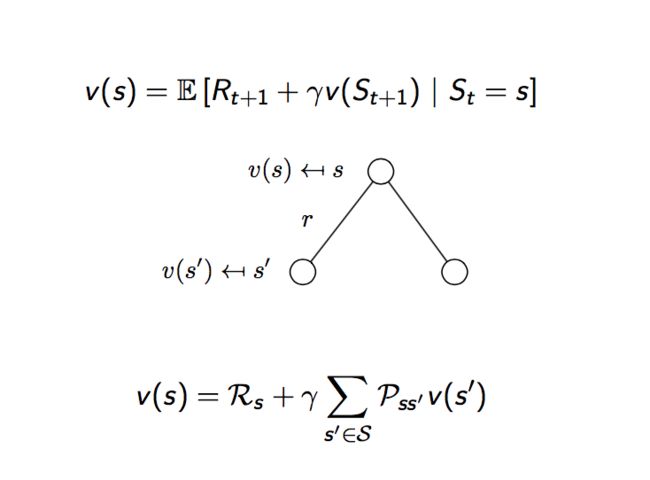
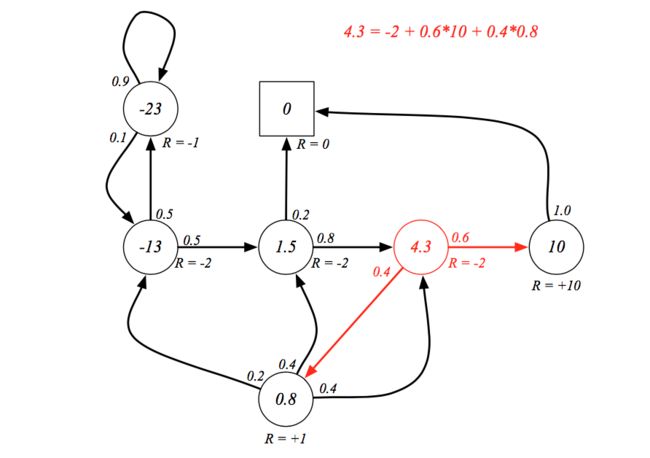
下图给出了验证贝尔曼方程的一个例子:
贝尔曼方程的矩阵形式:

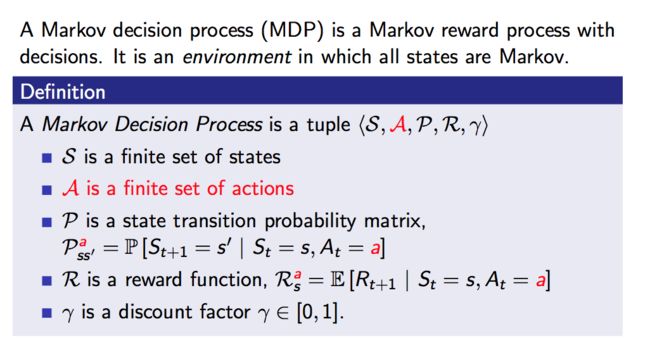
3、马尔可夫决策过程
终于到了终点啦,在马尔可夫奖励过程的基础上,在不同的状态下,我们可以有决策过程从而采取不同的action,采取不同的action可能会有不同的状态转移概率矩阵:
可以看到,在马尔可夫决策过程中,我们增加了行动集合A,我们的状态转移概率矩阵以及期望奖励不仅仅取决于状态s,还取决于所采取的行动a。
在马尔可夫决策过程中,我们可以定义策略,策略是在给定状态下采用不同动作的分布:

这里的策略π是一个给定的policy,对于一个给定的policy,我们可以计算状态转移概率矩阵以及期望奖励,即s到s‘的转移概率为策略π下采取动作a的可能性乘上在采取动作a的情况下s转移到s‘的概率的累加求和,期望奖励变为在策略π:

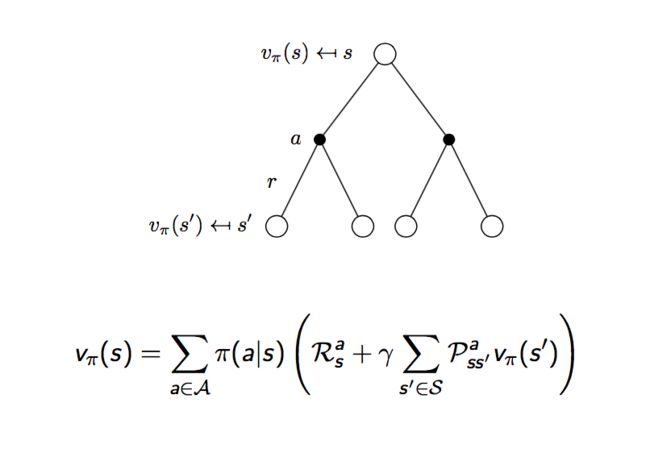
在马尔可夫决策过程中,我们定义了如下两种价值函数:

根据贝尔曼方程,我们可以得到:

如果我们把一个马尔可夫决策过程拆分为如下的过程:在状态s下,采取动作a,得到奖励r的一个过程,我们可以将上面的贝尔曼方程进一步细分。
首先,状态s下,采取动作a,可将v(s)进行如下的计算:
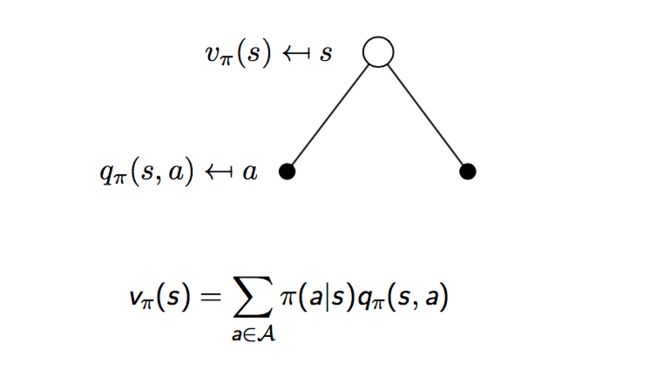
然后,在采取动作a的情况下,我们会得到一个立即的奖励,以及未来奖励的折扣:
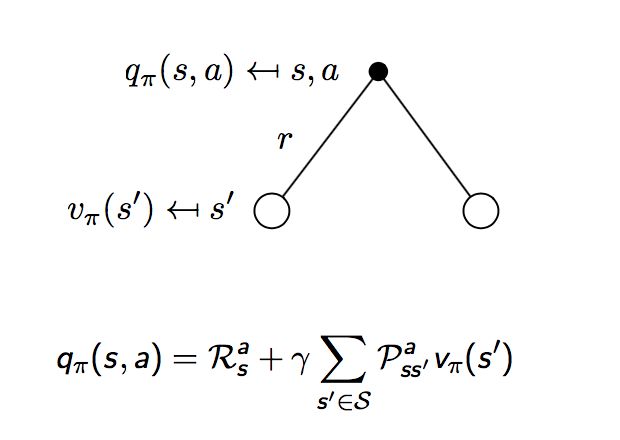
如果把上面两部分结合起来,我们可以得到如下的公式:
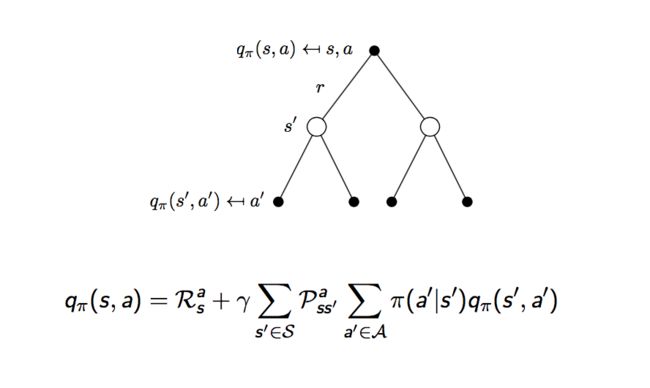
还是用上面的例子来验证一下马尔可夫决策过程中贝尔曼方程的正确性:
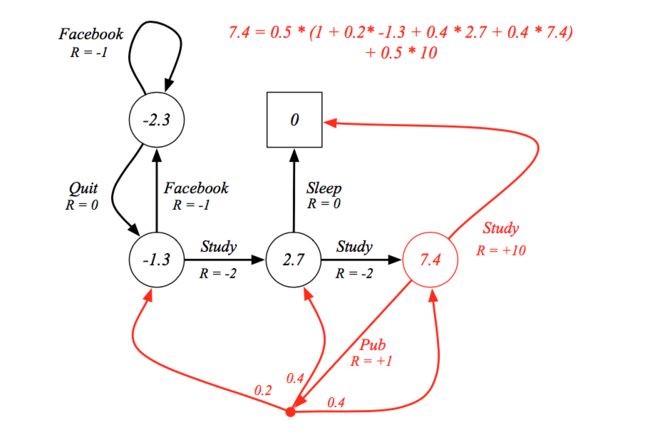
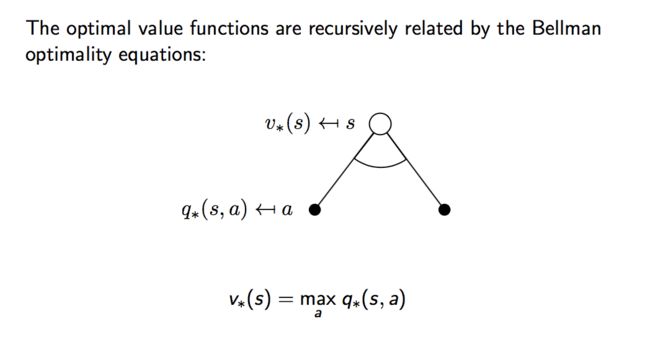
有了贝尔曼方程,我们的马尔可夫决策过程的目标是找到最优的值函数,即找到使s状态下价值最大的决策以及在状态s下采取行动a最大化价值决策。

可以想到,最优的决策是一定存在的,假设有n个状态,每个状态下采用的动作a是有限的,我们只需要分别找到在这n个状态下能达到最大价值的动作a,将这些组合起来,就能得到我们的最优决策。

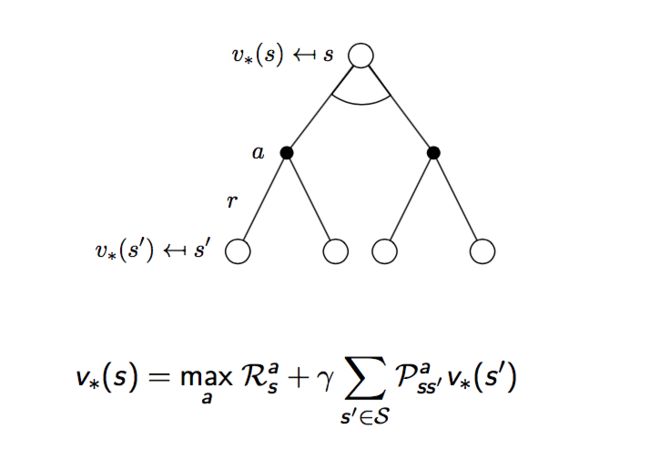
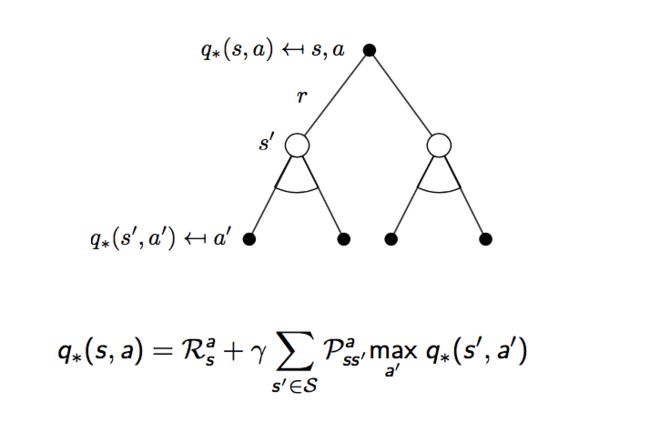
假设最优决策是已知的,那么在任意状态s下所采取的行动a也就是确定的,即:

所以,我们的贝尔曼方程变为如下的形式:
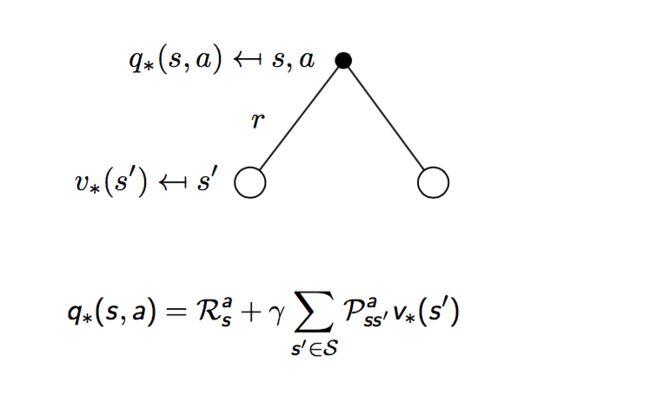
最后,我们只要求解最优条件下的贝尔曼方程,即可得到马尔可夫决策过程的解决方案,有如下的解法,在后面的课程中会接触到:
